
1.1 Logistics Regression模型
1.1.1 二分类问题
- 数据分作两类
- 广义线性模型的一种,属于线性的分类模型。
- problem1:如果不仅仅是分成两类呢?,一条直线怎么能够做到?
- 把数据集分为两类的那条直线,称为超平面,可用线性函数表示:
- \(Wx+b=0\)
- 其中W为权重,b为偏置。使用阈值函数把数据映射到不同类别中,常见的阈值函数有
Sigmoid函数形式: - \(f(x)=\frac{1}{1+e^{-x}}\)
import numpy as np def sig(x): ''' input : x(mat):feature * w output : sigmoid(x)(mat) : Sigmoid值 ''' return 1.0/(1+np.exp(-x)) Sigmoid函数对于输入向量X,其属于正例的概率为:-
\[P(y=1|X,W,b)=\sigma(WX+b)=\frac{1}{1+e^{-(WX+b)}} \]
-
- 而属于负例的概率为
-
\[P(y=0|X,W,b)=1-P(y=1|X,W,b)=1-\sigma(WX+b)=\frac{e^{-(WX+b)}}{1+e^{-(WX+b)}} \]
-
- 为了求解W,b这些参数,需要定义损失函数。
- 损失函数:对于上述的算法,其属于类别y的概率为:
-
\[P(y|X,W,b)=\sigma(WX+b)^y(1-\sigma(WX+b))^{1-y} \]
-
- 要求W和b,可以使用极大似然函数对其进行估计。假设训练数据集有m个训练样本\(\{(X^{(1)},y^{(1)}),(X^{(2)},y^{(2)}),\cdots,(X^{(m)},y^{(m)})\}\),则其似然函数为
-
\[L_{W,b}=\prod_{i=1}^{m}[h_{W,b}(X^{(i)})^{y^{(i)}}(1-h_{W,b}(X^{(i)}))^{1-y^{(i)}}] \]
-
- 其中,假设函数\(h_{W,b}(X^{(i)})\)为:\(h_{W,b}(X^{(i)})=\sigma(WX^{(i)}+b)\),对于似然函数的极大值的求解,通常使用Log似然函数,在Logistics Regression算法中,通常是将负的Log似然函数作为其损失函数,及
the negative log-likelihood(NLL)作为损失函数,此时,需要计算的是NLL的极小值。损失函数\(l_{W,b}\)为-
\[l_{W,b}=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}\log(h_{W,b}(X^{(i)}))+(1-y^{(i)})\log(1-h_{W,b}(X^{(i)}))] \]
-
- 此时,我们需要求解的问题为:\(\min_{W,b}l_{W,b}\),为了求得损失函数\(l_{W,b}\)的最小值,可以使用基于梯度的方法进行求解。
- __梯度下降法__是一种迭代型的优化算法,根据初始点在每一次迭代过程中选择下降法方向,进而改变需要修改的参数,对于优化问题\(\min f(w)\),梯度下降法的详细描述过程如下:
- 随机选择一个初始点\(w_0\)
- 重复以下过程
- 决定梯度下降的方向:\(d_i=-\frac{\partial}{\partial w}f(w)|_{w_i}\)
- 选择步长\(\alpha\)
- 更新:\(w_{i+1}=w_{i}+\alpha\cdot d_i\)
- 直到满足终止条件
- 凸优化与非凸优化 ,简单地讲,凸优化问题是指存在一个最优解的优化问题,及任何一个局部最优解及全局最优解。而非凸优化是指解空间存在多个局部最优解是其中的某一个局部最优解。最小二乘(Least Squares)、岭回归(Ridge Regression)和Logistics回归的损失函数都是凸优化问题。
- 利用梯度下降法训练Logistics Regression模型 :对于上述算法的损失函数可以通过梯度下降法对其进行求解,其梯度为:
-
\[\bigtriangledown_{w_j}(l_{W,b})=-\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}-h_{W,b}(X^{(i)}))x_j^{(i)} \]
-
\[\bigtriangledown_{b}(l_{W,b})=-\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}-h_{W,b}(X^{(i)})) \]
- 其中,\(x_j^{(i)}\)表示的是样本\(X^{(i)}\)的第j个分量。取\(w_0=b\),且将偏置项的变量\(x_0\)设置为1,则可以将上述的剃度合并为:
-
\[\bigtriangledown_{w_j}(l_{W,b})=-\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}-h_{W,b}(X^{(i)}))x_j^{(i)} \]
- 根据梯度下降法,得到如下的更新公式:\(W_j=W_j+\alpha\bigtriangledown_{w_j}(l_{W,b})\),对于一维的更新规则:\(w_{i+1}=w_i-\alpha_i\frac{df}{dw}|_{w=w_i}\)。步长的选择不能太小,否则收敛速度会变慢;但是也不能太大,否则的话会出现震荡的现象。
-
- 代码清单:
- 训练模型
# coding:UTF-8 import numpy as np def load_data(file_name): '''导入训练数据 input: file_name(string)训练数据的位置 output: feature_data(mat)特征 label_data(mat)标签 ''' f = open(file_name) # 打开文件 feature_data = [] label_data = [] for line in f.readlines(): feature_tmp = [] lable_tmp = [] lines = line.strip().split("\t") feature_tmp.append(1) # 偏置项 for i in range(len(lines) - 1): feature_tmp.append(float(lines[i])) lable_tmp.append(float(lines[-1])) feature_data.append(feature_tmp) label_data.append(lable_tmp) f.close() # 关闭文件 return np.mat(feature_data), np.mat(label_data) def sig(x): '''Sigmoid函数 input: x(mat):feature * w output: sigmoid(x)(mat):Sigmoid值 ''' return 1.0 / (1 + np.exp(-x)) def lr_train_bgd(feature, label, maxCycle, alpha): '''利用梯度下降法训练LR模型 input: feature(mat)特征 label(mat)标签 maxCycle(int)最大迭代次数 alpha(float)学习率 output: w(mat):权重 ''' n = np.shape(feature)[1] # 特征个数 w = np.mat(np.ones((n, 1))) # 初始化权重 i = 0 while i <= maxCycle: # 在最大迭代次数的范围内 i += 1 # 当前的迭代次数 h = sig(feature * w) # 计算Sigmoid值 err = label - h if i % 100 == 0: print("\t---------iter=" + str(i) + \ " , train error rate= " + str(error_rate(h, label))) w = w + alpha * feature.T * err # 权重修正 return w def error_rate(h, label): '''计算当前的损失函数值 input: h(mat):预测值 label(mat):实际值 output: err/m(float):错误率 ''' m = np.shape(h)[0] sum_err = 0.0 for i in range(m): if h[i, 0] > 0 and (1 - h[i, 0]) > 0: sum_err -= (label[i,0] * np.log(h[i,0]) + \ (1-label[i,0]) * np.log(1-h[i,0])) else: sum_err -= 0 return sum_err / m def save_model(file_name, w): '''保存最终的模型 input: file_name(string):模型保存的文件名 w(mat):LR模型的权重 ''' m = np.shape(w)[0] f_w = open(file_name, "w") w_array = [] for i in range(m): w_array.append(str(w[i, 0])) f_w.write("\t".join(w_array)) f_w.close() if __name__ == "__main__": # 1、导入训练数据 print("---------- 1.load data ------------") feature, label = load_data("data.txt") # 2、训练LR模型 print("---------- 2.training ------------") w = lr_train_bgd(feature, label, 1000, 0.01) # 3、保存最终的模型 print("---------- 3.save model ------------") save_model("weights", w) - 测试函数
# coding:UTF-8 import numpy as np from Logistics.lr_train import sig def load_weight(w): '''导入LR模型 input: w(string)权重所在的文件位置 output: np.mat(w)(mat)权重的矩阵 ''' f = open(w) w = [] for line in f.readlines(): lines = line.strip().split("\t") w_tmp = [] for x in lines: w_tmp.append(float(x)) w.append(w_tmp) f.close() return np.mat(w) def load_data(file_name, n): '''导入测试数据 input: file_name(string)测试集的位置 n(int)特征的个数 output: np.mat(feature_data)(mat)测试集的特征 ''' f = open(file_name) feature_data = [] for line in f.readlines(): feature_tmp = [] lines = line.strip().split("\t") # print lines[2] if len(lines) != n - 1: continue feature_tmp.append(1) for x in lines: # print x feature_tmp.append(float(x)) feature_data.append(feature_tmp) f.close() return np.mat(feature_data) def predict(data, w): '''对测试数据进行预测 input: data(mat)测试数据的特征 w(mat)模型的参数 output: h(mat)最终的预测结果 ''' h = sig(data * w.T)#sig m = np.shape(h)[0] for i in range(m): if h[i, 0] < 0.5: h[i, 0] = 0.0 else: h[i, 0] = 1.0 return h def save_result(file_name, result): '''保存最终的预测结果 input: file_name(string):预测结果保存的文件名 result(mat):预测的结果 ''' m = np.shape(result)[0] #输出预测结果到文件 tmp = [] for i in range(m): tmp.append(str(result[i, 0])) f_result = open(file_name, "w") f_result.write("\t".join(tmp)) f_result.close() if __name__ == "__main__": # 1、导入LR模型 print("---------- 1.load model ------------") w = load_weight("weights") n = np.shape(w)[1] # 2、导入测试数据 print("---------- 2.load data ------------") testData = load_data("test_data", n) # 3、对测试数据进行预测 print("---------- 3.get prediction ------------") h = predict(testData, w)#进行预测 # 4、保存最终的预测结果 print("---------- 4.save prediction ------------") save_result("result", h)
- 训练模型
- 运行结果:
weight : 1.3941777508748265 4.527177129107415 -4.793981623770908;
result : 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0。 - 问题:
- 问题1:为什么权值是3个的?
- 问题2:超平面怎么画?
- 原始数据图:
# coding:UTF-8 ''' Date:20210114 @author: zlc ''' import matplotlib.pyplot as plt import numpy as np def load_data(file_name): f = open(file_name) # 打开文件 feature_data = [] for line in f.readlines(): feature_tmp = [] lines = line.strip().split("\t") for i in range(len(lines)): feature_tmp.append(float(lines[i])) feature_data.append(feature_tmp) f.close() # 关闭文件 return feature_data if __name__ == "__main__": # 1、导入训练数据 print("---------- 1.load data ------------") data = load_data("data.txt") # xx = np.arange(0, 10, 0.1) # w = [1.3941777508748265,4.527177129107415,-4.793981623770908] x = [i[0] for i in data] y = [i[1] for i in data] # w = np.polyfit(x, y, 1) # print(w) # yy=[] # for i in range(len(xx)): # yy.append(w[0]*xx[i]+w[1]+w[2]) # 2、画图 print("---------- 2.draw ------------") color = ['b', 'orange'] z=[color[int(i[2])] for i in data] fig=plt.figure() plt.scatter(x,y,c=z) # 散点图 # plt.plot(xx,yy,color='g') plt.show()
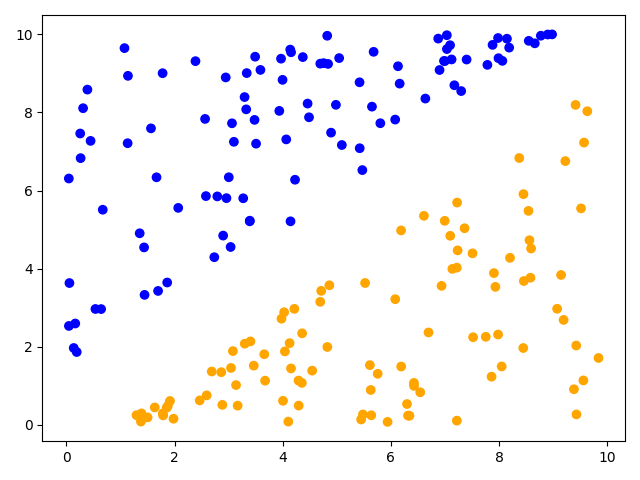
- 原始数据图:
【zlc】
