SPSS神经网络模型
实验目的
学会使用SPSS的简单操作,掌握神经网络模型。
实验要求
使用SPSS。
实验内容
(1)创建多层感知器网络,使用多层感知器评估信用风险,银行信贷员需要能够找到预示有可能拖欠贷款的人的特征来识别信用风险的高低。
(2)实现神经网络预测模型,使用径向基函数分类电信客户。
实验步骤
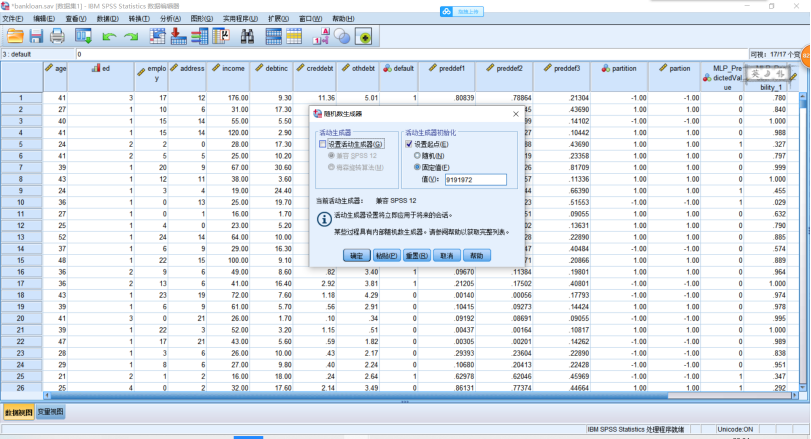
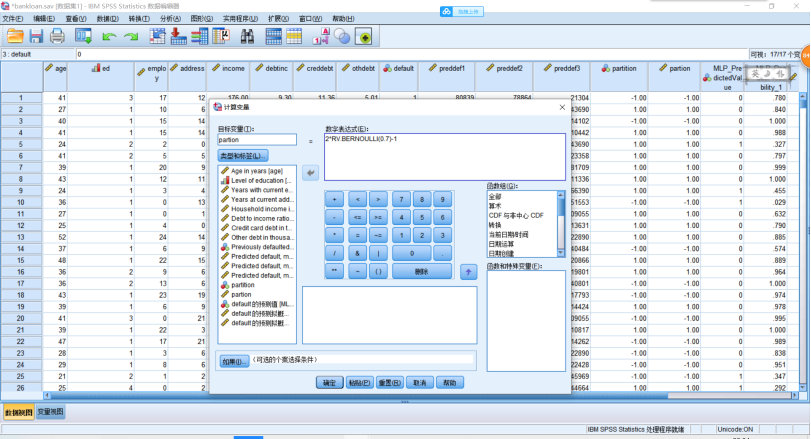
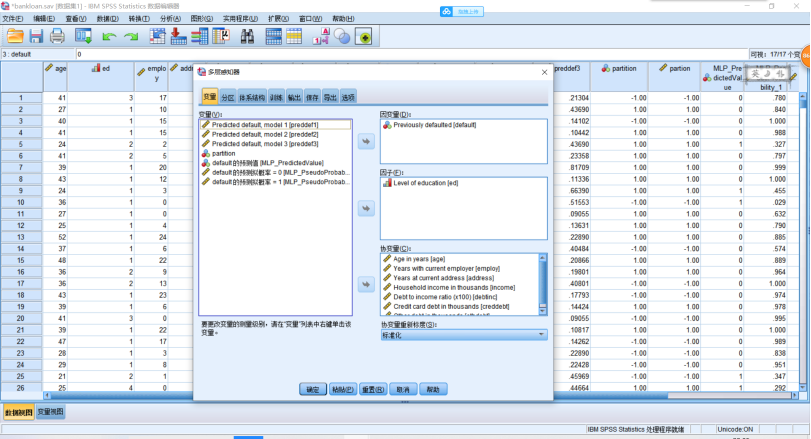
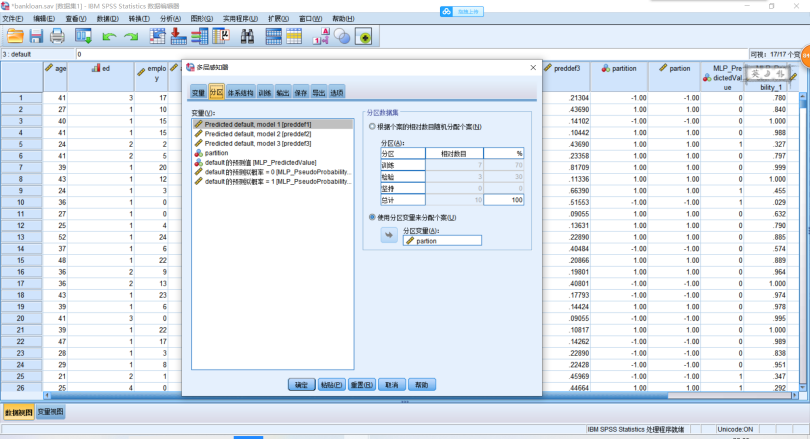
(1)创建多层感知器网络,分析示例——使用多层感知器评估信用风险,银行信贷员需要能够找到预示有可能拖欠贷款的人的特征来识别信用风险的高低。详细见bankloan.sav文件。SPSS操作,点击【转换】→【随机数生成器】,在打开的对话框中,勾选【设置起点】,点击【估计值】,值设为“9191972”,单击【确定】。【转换】→【计算变量】,在打开的对话框中,把“partion”输入【目标变量】。在【数字表达式】中输入表达式(2*RV.BERNOULLI(0.7)-1),单击【确定】。点击【分析】→【神经网络】→【多层感知器】,在打开的对话框中,把如图示的变量选入相应的地方。【分区】,点击【使用分区变量来分配个案】,并把“partion”选入【分区变量】中。点击【输出】,勾选想要输出的图表,点击【保存】,单击【确定】。
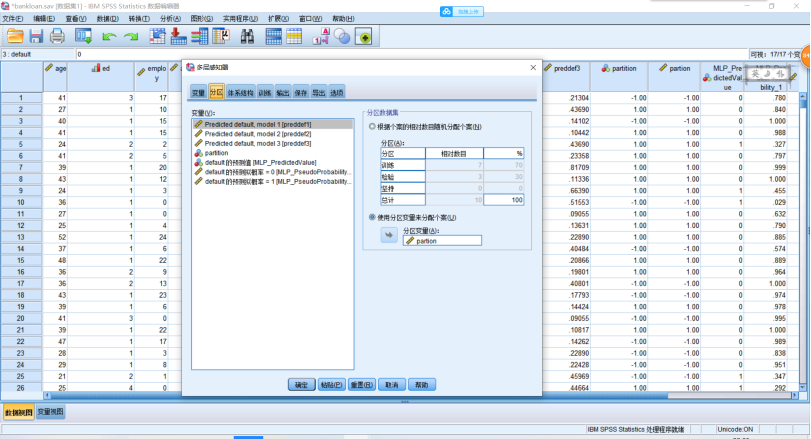




运行结果,
|
个案处理摘要 |
|||
|
|
个案数 |
百分比 |
|
|
样本 |
训练 |
499 |
71.3% |
|
坚持 |
201 |
28.7% |
|
|
有效 |
700 |
100.0% |
|
|
排除 |
150 |
|
|
|
总计 |
850 |
||
|
网络信息 |
|||
|
输入层 |
因子 |
1 |
Level of education |
|
协变量 |
1 |
Age in years |
|
|
2 |
Years with current employer |
||
|
3 |
Years at current address |
||
|
4 |
Household income in thousands |
||
|
5 |
Debt to income ratio (x100) |
||
|
6 |
Credit card debt in thousands |
||
|
7 |
Other debt in thousands |
||
|
单元数a |
12 |
||
|
协变量的重新标度方法 |
标准化 |
||
|
隐藏层 |
隐藏层数 |
1 |
|
|
隐藏层 1 中的单元数a |
4 |
||
|
激活函数 |
双曲正切 |
||
|
输出层 |
因变量 |
1 |
Previously defaulted |
|
单元数 |
2 |
||
|
激活函数 |
Softmax |
||
|
误差函数 |
交叉熵 |
||
|
a. 排除偏差单元 |
|||

|
模型摘要 |
||
|
训练 |
交叉熵误差 |
156.605 |
|
不正确预测百分比 |
15.6% |
|
|
使用的中止规则 |
超出最大时程数 (100) |
|
|
训练时间 |
0:00:00.25 |
|
|
坚持 |
不正确预测百分比 |
25.4% |
|
因变量:Previously defaulted |
||
|
分类 |
||||
|
样本 |
实测 |
预测 |
||
|
No |
Yes |
正确百分比 |
||
|
训练 |
No |
347 |
28 |
92.5% |
|
Yes |
50 |
74 |
59.7% |
|
|
总体百分比 |
79.6% |
20.4% |
84.4% |
|
|
坚持 |
No |
123 |
19 |
86.6% |
|
Yes |
32 |
27 |
45.8% |
|
|
总体百分比 |
77.1% |
22.9% |
74.6% |
|
|
因变量:Previously defaulted |
||||
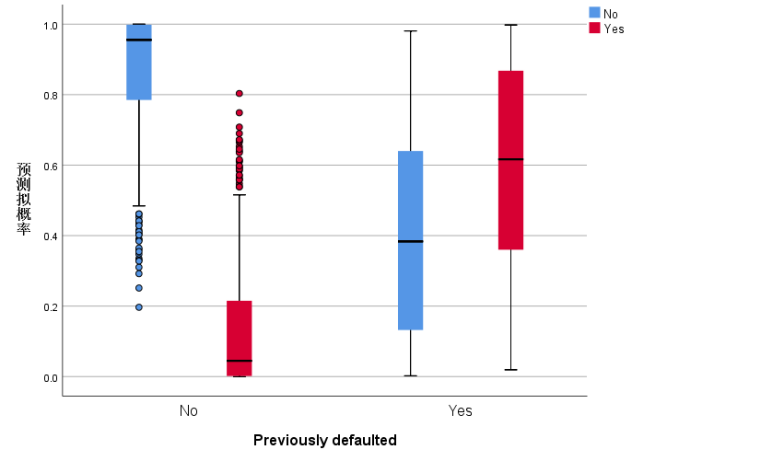
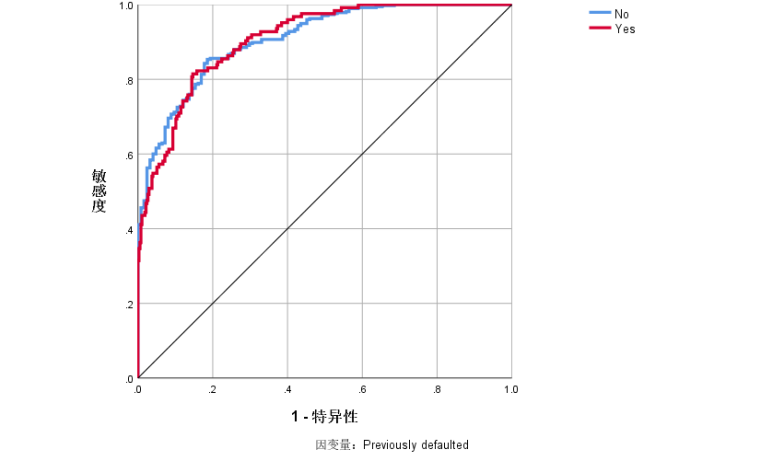
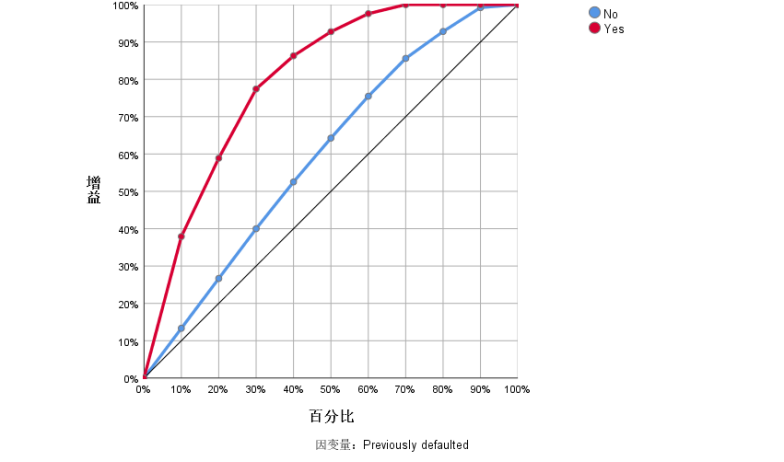
|
曲线下方的区域 |
||
|
|
区域 |
|
|
Previously defaulted |
No |
.907 |
|
Yes |
.907 |
|
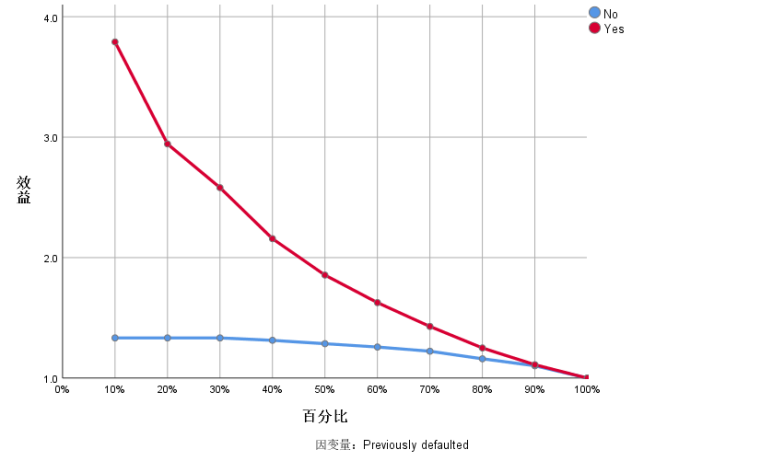
代码:


1 COMPUTE partion=2*RV.BERNOULLI(0.7)-1. 2 EXECUTE. 3 *Multilayer Perceptron Network. 4 MLP default (MLEVEL=N) BY ed WITH age employ address income debtinc creddebt othdebt 5 /RESCALE COVARIATE=STANDARDIZED 6 /PARTITION VARIABLE=partion 7 /ARCHITECTURE AUTOMATIC=YES (MINUNITS=1 MAXUNITS=50) 8 /CRITERIA TRAINING=BATCH OPTIMIZATION=SCALEDCONJUGATE LAMBDAINITIAL=0.0000005 9 SIGMAINITIAL=0.00005 INTERVALCENTER=0 INTERVALOFFSET=0.5 MEMSIZE=1000 10 /PRINT CPS NETWORKINFO SUMMARY CLASSIFICATION 11 /PLOT NETWORK ROC GAIN LIFT PREDICTED 12 /SAVE PREDVAL PSEUDOPROB 13 /STOPPINGRULES ERRORSTEPS= 1 (DATA=AUTO) TRAININGTIMER=ON (MAXTIME=15) MAXEPOCHS=AUTO 14 ERRORCHANGE=1.0E-4 ERRORRATIO=0.001 15 /MISSING USERMISSING=EXCLUDE .
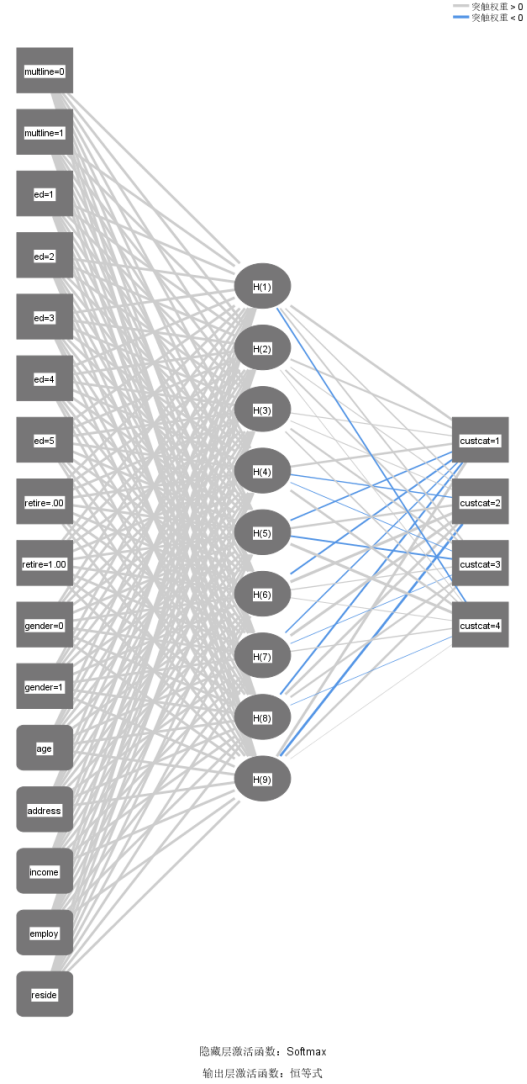
(1)实现神经网络预测模型,分析示例——使用径向基函数分类电信客户,具体见telco.sav。SPSS操作,【转换】→【随机生成数】→【设置起点】为“9191972”,单击【确定】。点击【分析】→【神经网络】→【径向基函数】,设置相关步骤见图。
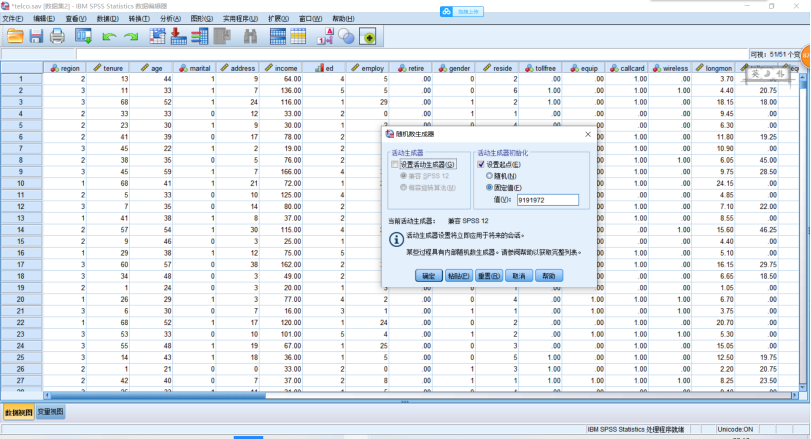
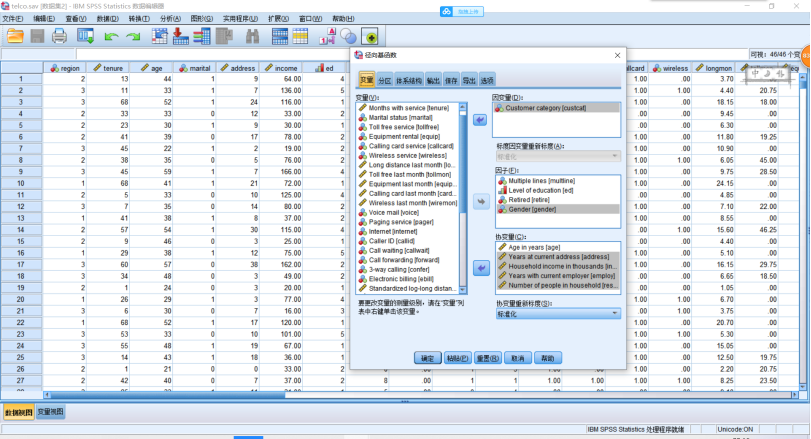
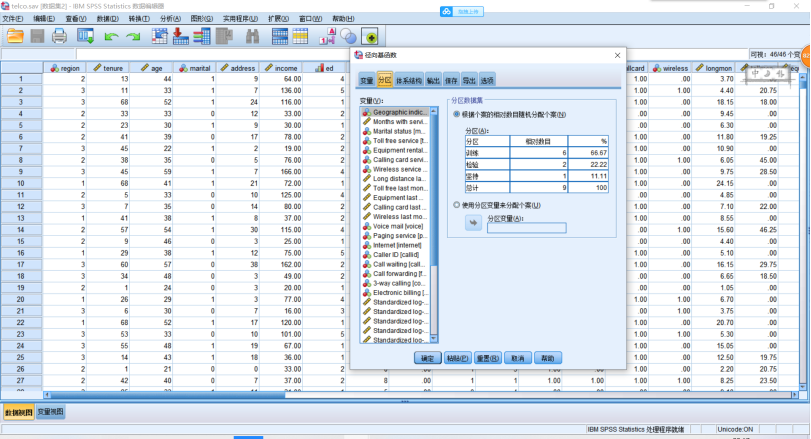

输出结果:
|
个案处理摘要 |
|||
|
|
个案数 |
百分比 |
|
|
样本 |
训练 |
665 |
66.5% |
|
检验 |
224 |
22.4% |
|
|
坚持 |
111 |
11.1% |
|
|
有效 |
1000 |
100.0% |
|
|
排除 |
0 |
|
|
|
总计 |
1000 |
||
|
网络信息 |
|||
|
输入层 |
因子 |
1 |
Multiple lines |
|
2 |
Level of education |
||
|
3 |
Retired |
||
|
4 |
Gender |
||
|
协变量 |
1 |
Age in years |
|
|
2 |
Years at current address |
||
|
3 |
Household income in thousands |
||
|
4 |
Years with current employer |
||
|
5 |
Number of people in household |
||
|
单元数 |
16 |
||
|
协变量的重新标度方法 |
标准化 |
||
|
隐藏层 |
单元数 |
9a |
|
|
激活函数 |
Softmax |
||
|
输出层 |
因变量 |
1 |
Customer category |
|
单元数 |
4 |
||
|
激活函数 |
恒等式 |
||
|
误差函数 |
平方和 |
||
|
a. 由检验数据准则确定:隐藏单元的“最佳”数目是指在检验数据中产生误差最小的数目。 |
|||
|
模型摘要 |
||
|
训练 |
平方和误差 |
199.956 |
|
不正确预测百分比 |
49.0% |
|
|
训练时间 |
0:00:01.05 |
|
|
检验 |
平方和误差 |
66.887a |
|
不正确预测百分比 |
47.8% |
|
|
坚持 |
不正确预测百分比 |
54.1% |
|
因变量:Customer category |
||
|
a. 隐藏单元数由检验数据准则确定:隐藏单元的“最佳”数目是指在检验数据中产生误差最小的数目。 |
||
|
分类 |
||||||
|
样本 |
实测 |
预测 |
||||
|
Basic service |
E-service |
Plus service |
Total service |
正确百分比 |
||
|
训练 |
Basic service |
149 |
1 |
25 |
0 |
85.1% |
|
E-service |
0 |
105 |
17 |
19 |
74.5% |
|
|
Plus service |
85 |
35 |
63 |
2 |
34.1% |
|
|
Total service |
42 |
70 |
30 |
22 |
13.4% |
|
|
总体百分比 |
41.5% |
31.7% |
20.3% |
6.5% |
51.0% |
|
|
检验 |
Basic service |
51 |
0 |
8 |
0 |
86.4% |
|
E-service |
0 |
33 |
5 |
15 |
62.3% |
|
|
Plus service |
30 |
12 |
20 |
3 |
30.8% |
|
|
Total service |
9 |
14 |
11 |
13 |
27.7% |
|
|
总体百分比 |
40.2% |
26.3% |
19.6% |
13.8% |
52.2% |
|
|
坚持 |
Basic service |
27 |
0 |
5 |
0 |
84.4% |
|
E-service |
0 |
15 |
4 |
4 |
65.2% |
|
|
Plus service |
14 |
7 |
8 |
2 |
25.8% |
|
|
Total service |
10 |
11 |
3 |
1 |
4.0% |
|
|
总体百分比 |
45.9% |
29.7% |
18.0% |
6.3% |
45.9% |
|
|
因变量:Customer category |
||||||
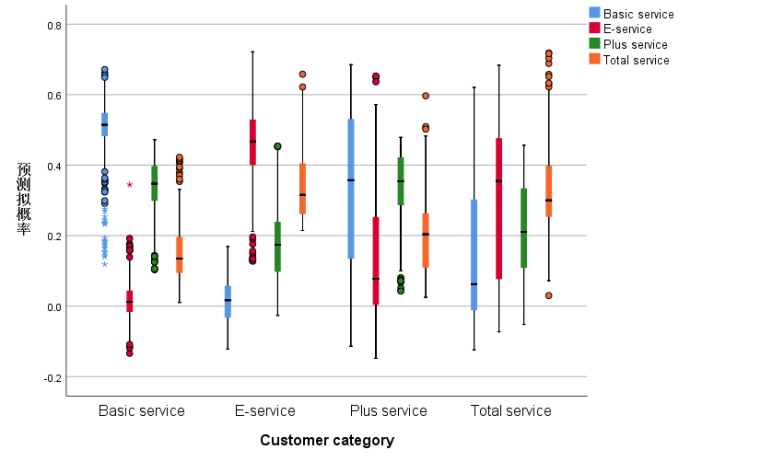
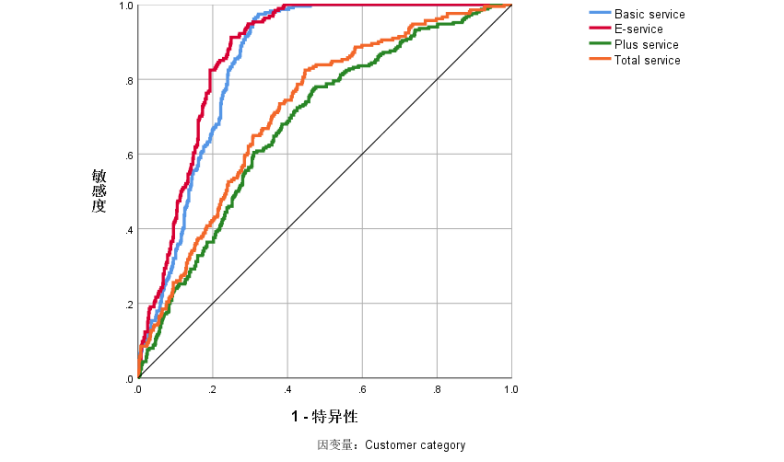
|
曲线下方的区域 |
||
|
|
区域 |
|
|
Customer category |
Basic service |
.848 |
|
E-service |
.869 |
|
|
Plus service |
.681 |
|
|
Total service |
.717 |
|
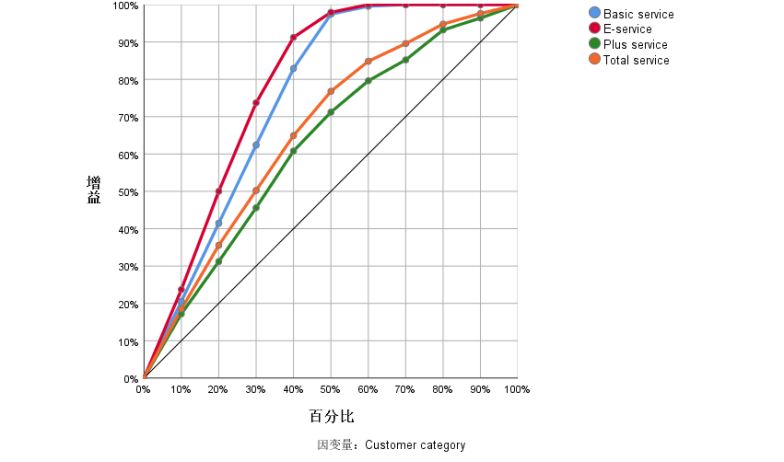

代码:
1 SET SEED=9191972. 2 *Radial Basis Function Network. 3 RBF custcat (MLEVEL=N) BY multline ed retire gender WITH age address income employ reside 4 /RESCALE COVARIATE=STANDARDIZED 5 /PARTITION TRAINING=6 TESTING=2 HOLDOUT=1 6 /ARCHITECTURE MINUNITS=AUTO MAXUNITS=AUTO HIDDENFUNCTION=NRBF 7 /CRITERIA OVERLAP=AUTO 8 /PRINT CPS NETWORKINFO SUMMARY CLASSIFICATION 9 /PLOT NETWORK ROC GAIN LIFT PREDICTED 10 /SAVE PREDVAL PSEUDOPROB 11 /MISSING USERMISSING=EXCLUDE .
小结
使用神经网络模型进行预测或分类,有必要对参数的调试下点功夫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号