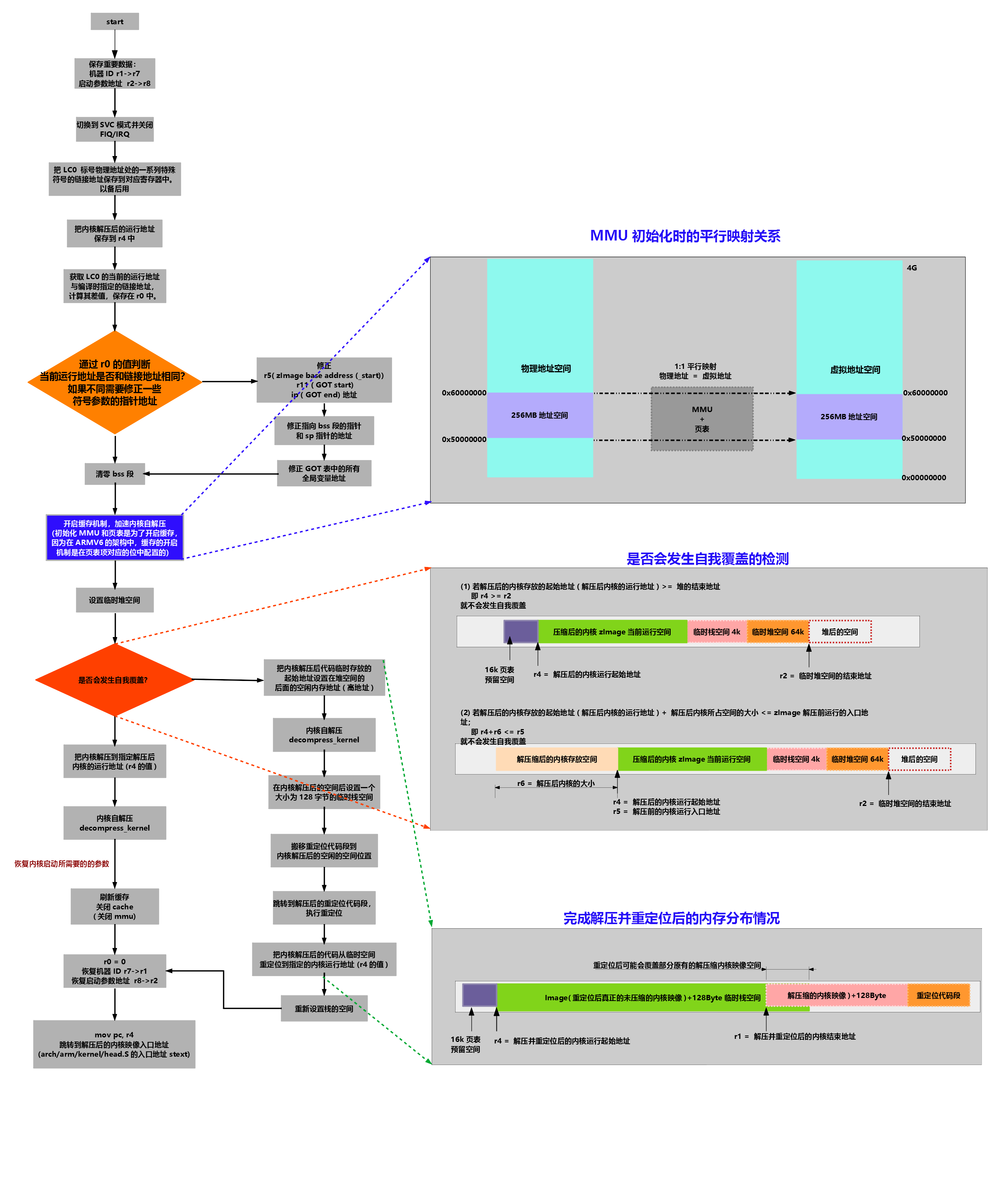
内核启动流程 --- 自解压(一)
文章目录
- 一. 前言
- 二. bootloder准备阶段
- 三. 内核自解压阶段
- 3.1 保存机器ID和启动参数地址到r7和r8寄存器
- 3.2 切换到SVC模式并关闭FIQ/IRQ
- 3.3 把指定标号的链接地址加载到对应的寄存器中
- 3.4 计算r0和r1的差值,判断当前运行地址是否与链接地址相同
- 3.5 修正r2/r3/r5/r11/ip/sp的值
- 3.6 清0 bss段
- 3.7 打开cache
- 3.8 设置堆空间
- 3.9 判断解压后的内核是否会覆盖当前运行代码
- 3.10 自解压的过程
- 3.11 在解压内核后面空间预留128字节的栈空间
- 3.12 搬移重定位代码段
- 3.13 跳转到搬移后的重定位代码段继续执行
- 3.14 设置内核代码被重定位的起始地址
- 3.15 开始重定位
- 3.16 加载真正的内核Image
- 四. 总结 --- 流程图
一. 前言
由于之前手里只有一块mini6410的开发板,本专题主要围绕它的对应内核linux2.6.38进行讲解。后续会在新的专题继续更新基于最新armv8架构多核cpu内核的启动流程分析(开发板选型中,力求更多的常用外设接口,后续会继续更新各种常用总线的驱动)。
二. bootloder准备阶段
在内核启动前,bootloader(uboot)做如下准备工作:
|--- 设置SVC模式
|--- 关闭cache和MMU
|--- 关闭看门狗
|--- 外设基地址初始化
|--- 设置时钟
|--- 内存初始化
|--- 拷贝代码到内存(代码重定位)
|--- 设置栈(栈初始化后才能使用c函数)
|--- 清零BSS段
|--- 串口初始化
|--- 设置全局变量gd
| |--- gd->bd->bi_arch_number = MACH_TYPE ;6410的MACH_TYPE = 2520
| |--- gd->bd->bi_boot_params = 0x50000000 + 0x100 ;tag存放的起始地址偏移内存起始地址0x100
| |--- gd->bd->bi_dram[0].start = 0x50000000 ;内存起始地址
| |--- gd->bd->bi_dram[0].size = 0x10000000 ;板载内存大小256MB
|
|--- 执行自己定义的main函数
| |--- 把内核镜像zImage从Nandflash读到内存0x50008000处
| |--- 设置启动参数(tag)
| |--- bd_t *bd = gd->bd
| |--- 设置起始tag :setup_start_tag(bd)
| |--- 设置内存tag :setup_memory_tags(bd)
| |--- 设置命令行tag:setup_commandline_tag(bd, CONFIG_BOOTCOMMAND);
| |--- 设置结束tag :setup_end_tag(bd);
|
|--- 跳转启动内核
| |--- theKernel = (void(*)(int, int, unsigned int))CFG_SDRAM_KERNEL_BASE
| |--- theKernel(0,MACH_TYPE,0x50000100) ;传入三个参数,r0=0,r1=2520,r2=0x50000100指定tag的起始地址
|
三. 内核自解压阶段
3.1 保存机器ID和启动参数地址到r7和r8寄存器
.section ".start", #alloc, #execinstr
/*
* sort out different calling conventions
*/
.align
.arm @ Always enter in ARM state
start:
.type start,#function
THUMB( adr r12, BSYM(1f) )
THUMB( bx r12 )
THUMB( .rept 6 )
ARM( .rept 8 ) //只关注arm的
mov r0, r0
.endr
b 1f //向forward方向的标号1跳转,即往下
.word 0x016f2818 @ Magic numbers to help the loader
.word start @ absolute load/run zImage address
.word _edata @ zImage end address
THUMB( .thumb )
1: mov r7, r1 @ save architecture ID 重点关注
mov r8, r2 @ save atags pointer 重点关注
使用.type标号来指明start的符号类型是函数类型,然后重复执行.rept到.endr之间的指令8次,这是用来存放ARM的异常向量表。最后向后跳转到标号为1处执行。
(1).type 用来指定一个符号的类型是函数类型或者对象类型,对象类型一般指数据,格式如下:
.type 符号,类型描述符 [function,object]
(2)THUMB宏定义参见linux-2.6.38\arch\arm\include\asm\unified.h
由宏定义可知,内核在GCC版本大于4.0后,可通过配置宏CONFIG_THUMB2_KERNEL来选择编译成THUMB指令集内核或ARM指令集内核。在编译成ARM指令集内核时,THUMB宏定义的代码行是不可见的。同理编译成THUMB指令集内核时,ARM宏定义的代码行无效。BSYM宏是为在THUMB指令集时访问标号处理而定义的宏。这里主要是为了兼容,解读的时候默认屏蔽THUMB即可 。
(3)0x016f2818 是bootloder和在Image之间规定好的一个幻数,用于判断bootloader跳转执行的地址是否是zImge映像。
(4)start 是由链接脚本arch/arm/boot/compressed/vmlinux.lds决定的,start=0,_edata为zImgae的结束地址。
3.2 切换到SVC模式并关闭FIQ/IRQ
/*
* Booting from Angel - need to enter SVC mode and disable
* FIQs/IRQs (numeric definitions from angel arm.h source).
* We only do this if we were in user mode on entry.
*/
mrs r2, cpsr @ get current mode
tst r2, #3 @ not user?
bne not_angel
mov r0, #0x17 @ angel_SWIreason_EnterSVC
ARM( swi 0x123456 ) @ angel_SWI_ARM
THUMB( svc 0xab ) @ angel_SWI_THUMB
not_angel: //走的这个分支
mrs r2, cpsr @ turn off interrupts to
orr r2, r2, #0xc0 @ prevent angel from running 关闭中断
msr cpsr_c, r2
我使用的Mini6410开发板是通过uboot来引导内核的,在启动内核之前已经把ARM设设置为SVC模式,因此这里只需要关掉FIQ/IRQ中断即可。一般会分为以下两种情形:
(1) 如果从Angel启动:需要进入SVC模式并禁用FIQ/IRQ。我们只有在进入时处于用户模式才会这样做。切换的方式是使用swi指令,产生软中断异常,软中断异常一旦发生自动切到svc模式。
(2)如果从SVC模式启动:禁用FIQ/IRQ。(我采用的方式)
3.3 把指定标号的链接地址加载到对应的寄存器中
/*
* Note that some cache flushing and other stuff may
* be needed here - is there an Angel SWI call for this?
*/
/*
* some architecture specific code can be inserted
* by the linker here, but it should preserve r7, r8, and r9.
*/
.text
adr r0, LC0 //把LC0标号物理地址赋值给r0
ldmia r0, {r1, r2, r3, r5, r6, r11, ip}
ldr sp, [r0, #28]
ldr r4, =zreladdr
...
.align 2
.type LC0, #object
LC0: .word LC0 @ r1
.word __bss_start @ r2
.word _end @ r3
.word _start @ r5
.word _image_size @ r6
.word _got_start @ r11
.word _got_end @ ip
.word user_stack_end @ sp
3.3.1 获取标号LC0的物理地址并保存到r0中
adr r0, LC0
adr指令是采用相对地址,因此这里r0装的实际上是标号LC0对应的当前运行地址,因为未开启mmu,也是物理地址 。
可以通过反汇编arch/arm/boot/compressed/vmlinux来解析这段代码的含义:
/* adr r0, LC0 */
60: e28f00d8 add r0, pc, #216 ; 0xd8
/* LC0: .word LC0 @ r1 */
00000140 <LC0>:
140: 00000140 andeq r0, r0, r0, asr #2
由于zImage是加载到内存0x50008000这个地址开始运行的,所以当前pc值为:
- pc = 0x50008000 + 0x60 + 8 = 0x50008068
- r0 = pc +0xd8 = 0x50008140
3.3.2 把r0指向的内存地址中的数据依次加载到对应寄存器中
ldmia r0, {r1, r2, r3, r5, r6, r11, ip}
ldr sp, [r0, #28]
代码中的注释已经说的很明白。注意r0指向的地址中第一个32位数据是LC0的运行地址,这个值是链接后的地址即0x140。此时r1 =0x140 。
3.3.3 把zreladdr的地址加载到寄存器r4中
ldr r4, =zreladdr
在编译内核的时候也许你已注意到有如下的打印:
arm-linux-ld -EL --defsym zreladdr=0x50008000 -p --no-undefined -X -T
arch/arm/boot/compressed/vmlinux.lds arch/arm/boot/compressed/head.o
arch/arm/boot/compressed/piggy.gzip.o arch/arm/boot/compressed/misc.o
arch/arm/boot/compressed/decompress.o arch/arm/boot/compressed/lib1funcs.o -o
arch/arm/boot/compressed/vmlinux
其中zreladdr的值最由arch/arm/$(MACHINE)/Makefile.boot决定,我这里使用的6410,对应arch/arm/mach-s3c64xx/Makefile.boot
zreladdr-y := 0x50008000
params_phys-y := 0x50000100
因此 r4 = 0x50008000 。
3.4 计算r0和r1的差值,判断当前运行地址是否与链接地址相同
subs r0, r0, r1 @ calculate the delta offset
beq not_relocated @ if delta is zero, we are running at the address we were linked at.
如果当前未运行在链接地址,r0是不等于r1的;反之r0 等于r1 。通常情况下通过uboot引导内核时,r0都是不等于r1的。从前面的分析也可以知道r0 = 0x50008140, r1 =0x140,两者是不相等的。
此时 r0 = 0x50008140 -0x140 = 0x50008000 。
3.5 修正r2/r3/r5/r11/ip/sp的值
/*
* We're running at a different address. We need to fix
* up various pointers:
* r5 - zImage base address (_start)
* r6 - size of decompressed image
* r11 - GOT start
* ip - GOT end
*/
add r5, r5, r0
add r11, r11, r0
add ip, ip, r0
#ifndef CONFIG_ZBOOT_ROM //从内存中启动,不是在ROM中启动
/*
* If we're running fully PIC === CONFIG_ZBOOT_ROM = n,
* we need to fix up pointers into the BSS region.
* r2 - BSS start
* r3 - BSS end
* sp - stack pointer
*/
add r2, r2, r0
add r3, r3, r0
add sp, sp, r0
/*
* Relocate all entries in the GOT table.
*/
1: ldr r1, [r11, #0] @ relocate entries in the GOT table. This fixes up the
add r1, r1, r0
str r1, [r11], #4 @ C references.
cmp r11, ip
blo 1b
#else
...
#endif
3.5.1 为什么要修正这些寄存器的值
编译器在链接的时候,需要指定代码段的运行地址(链接地址),正常情况下只要把生成的可执行文件加载到指定的运行地址就可以顺利执行了,但是很多时候代码的当前运行地址和指定的链接地址并不相同,例如uboot的第一阶段,内核自解压阶段等。对于运行地址和链接地址不同的情景:寄存器里保存的值都是链接后的地址,如果不修正,程序去加载这些链接地址时,链接地址处的内容往往并不是我们期望的值(未重定位的情况除外),程序就无法正常运行 。
3.5.2 如何修正寄存器的值
上一节通过计算当前运行地址和链接地址的差值并保存在r0寄存器中;修正时,只需加上这个偏移值即可。
3.5.3 .got段
对全局变量的读写分为以下两种情况:
(1)使用位置有关的代码(无got段)
首先获取全局变量的绝对地址,然后读写。但是在可执行文件中,全局变量的地址在链接的时候就已经确定了。也就是说这个全局变量被链接到什么地址,就必须去这个链接地址去访问它,这就要求这个可执行程序必须从链接地址加载运行;如果从其它位置加载,就不能在指定的地址找到这个全局变量。
(2)编译代码时加上“-fpic”产生位置无关代码(有got段)
“got” 是“globle offset table”的意思,这个段中存放的都是全局变量的地址。访问全局变量的过程如下:
- 获取got段的首地址
- 获取要访问的全局变量在got段中的偏移值
- 根据首地址和偏移值计算出全局变量的地址
- 根据计算后的地址去访问这个全局变量
3.6 清0 bss段
not_relocated: mov r0, #0
1: str r0, [r2], #4 @ clear bss
str r0, [r2], #4
str r0, [r2], #4
str r0, [r2], #4
cmp r2, r3
blo 1b
r2保存的是bss的起始地址,r3保存的是bss的结束地址。lo是无符号小于的意思,1b是向前跳转的意思(back)。
3.7 打开cache
打开cache主要是为了加速内核的解压。为了打开缓存, 我们需要设置一些临时用的页表(mmu),因为I/D cache 在设置页表的时候通过设置相应的位才可以开启。
3.7.1 跳转到真正实现打开缓存的函数call_cache_fn
bl cache_on
.........//省略
/*
* Turn on the cache. We need to setup some page tables so that we
* can have both the I and D caches on.
*
* We place the page tables 16k down from the kernel execution address,
* and we hope that nothing else is using it. If we're using it, we
* will go pop!
*
* On entry,
* r4 = kernel execution address
* r7 = architecture number
* r8 = atags pointer
* On exit,
* r0, r1, r2, r3, r9, r10, r12 corrupted
* This routine must preserve:
* r4, r5, r6, r7, r8
*/
.align 5
cache_on: mov r3, #8 @ cache_on function
b call_cache_fn
.........//省略
/*
* Here follow the relocatable cache support functions for the
* various processors. This is a generic hook for locating an
* entry and jumping to an instruction at the specified offset
* from the start of the block. Please note this is all position
* independent code.
*
* r1 = corrupted
* r2 = corrupted
* r3 = block offset
* r9 = corrupted
* r12 = corrupted
*/
call_cache_fn: adr r12, proc_types
mrc p15, 0, r9, c0, c0 @ get processor ID
1: ldr r1, [r12, #0] @ get value //把r12+0地址处的值赋值给r1 = 对应架构的cpu_val
ldr r2, [r12, #4] @ get mask //把r12+4地址处的值赋值给r2 = 对应架构的cpu_mask
eor r1, r1, r9 @ (real ^ match)//eor位异或
tst r1, r2 @ & mask //比较
ARM(addeq pc, r12, r3 ) @ call cache function //addeqs这条指令在前面比较指令中r1 =r2的前提下才执行
add r12, r12, #4*5 //让r12指向下一个架构的proc_type起始地址
b 1b
上面代码执行逻辑如下:
(1)把proc_types的物理地址赋值给r12
(2)通过协处理器寄存器cp15获取处理器 ID
(3)把 r12+0 地址处的值赋值给r1 — 对应架构的cpu_val
(4)把 r12+4 地址处的值赋值给r2 — 对应架构的cpu_mask
(5)对 r1 和 r9 进行位异或计算,把计算后的值赋值给r1
(6)比较r1和r2的值
(7)根据比较结果,做不同的选择
- 如果r1和r2的值相同,表明找到了对应架构的proc_type,调用对应的cache function(函数放在r12+8地址处);
- 如果r1和r2的值不同,表明未找到了对应架构的proc_type,让r12 = r12+4*5,此时r12指向下一个proc_type的起始地址,向前跳转到标号;1,继续查找比较,直到找到目标架构的proc_type。
3.7.2 proc_types定义的内容
/*
* Table for cache operations. This is basically:
* - CPU ID match
* - CPU ID mask
* - 'cache on' method instruction
* - 'cache off' method instruction
* - 'cache flush' method instruction
*
* We match an entry using: ((real_id ^ match) & mask) == 0
*
* Writethrough caches generally only need 'on' and 'off'
* methods. Writeback caches _must_ have the flush method
* defined.
*/
.align 2
.type proc_types,#object
proc_types:
........//省略无关的架构proc_type
.word 0x0007b000 @ ARMv6 /* mini6410采用的是armv6架构 */
.word 0x000ff000
W(b) __armv4_mmu_cache_on
W(b) __armv4_mmu_cache_off
W(b) __armv6_mmu_cache_flush
........//省略无关的架构proc_type
.word 0 @ unrecognised type
.word 0
mov pc, lr
THUMB( nop )
mov pc, lr
THUMB( nop )
mov pc, lr
THUMB( nop )
.size proc_types, . - proc_types
从代码可以到看,每一种结构对应5个32位的数值(这也是为什么每次寻找下一个结构相关的proc_type时,r12 = r12+4*5的原因),按顺序依次为 CPU ID match、CPU ID mask、‘cache on’ method instruction、‘cache off’ method instruction、‘cache flush’ method instruction。由于mini6410使用的是armv6的结构,因此__armv4_mmu_cache_on是打开cache的函数。
3.7.3 打开mmu、buffer、cache,设置平行映射
__armv4_mmu_cache_on:
mov r12, lr
bl __setup_mmu
mov r0, #0
mcr p15, 0, r0, c7, c10, 4 @ drain write buffer
mcr p15, 0, r0, c8, c7, 0 @ flush I,D TLBs
mrc p15, 0, r0, c1, c0, 0 @ read control reg
orr r0, r0, #0x5000 @ I-cache enable, RR cache replacement
orr r0, r0, #0x0030
bl __common_mmu_cache_on
mov r0, #0
mcr p15, 0, r0, c8, c7, 0 @ flush I,D TLBs
mov pc, r12
__setup_mmu:
/*
* 这里r4中存放着内核执行地址,将16K的一级页表放在这个内核执行地址下面的16K空间里,
* 下面通过 sub r3, r4, #16384 获得16K空间后,又将页表的起始地址进行16K对齐放在r3中。
* 即ttb的低14位清零。
*/
sub r3, r4, #16384 @ Page directory size //r3 = r4 -0x4000 = 0x50004000
bic r3, r3, #0xff @ Align the pointer
bic r3, r3, #0x3f00
/*
* Initialise the page tables, turning on the cacheable and bufferable
* bits for the RAM area only.
* 下面这几行把一级页表的起始地址保存在r0中,并通过r0获得一个ram起始地址(256K对齐),
* 并从这个起始地址开始的256M ram空间对应的描述符的C和B位均置”1”,
* r9和r10中存放了这段内存的起始地址和结束地址。
*/
mov r0, r3 //r0 = 0x50004000页表项的起始地址
mov r9, r0, lsr #18 //r9 = 0x5000
mov r9, r9, lsl #18 @ start of RAM//r9 = 0x50000000,先>>18,后<<18,就是256K对齐
add r10, r9, #0x10000000 @ a reasonable RAM size//r10 = 0x60000000,0x10000000==256M
/*
* 一级描述符的bit[1:0]为10,表示这是一个section(1MB)描述符。
* bit[4]为1,默认值
* bit[8:5]均为0,选择了D0域
*/
mov r1, #0x12 //0001 0010
/*
* 一级描述符的AP(access permission bits) bit[11:10]为11,即可读可写
* bit[31:20]为physical address,为0
*/
orr r1, r1, #3 << 10 //AP=11,r1 = 0xC12
/*
* 一级描述符表(页表)的结束地址存放在r2中。
*/
add r2, r3, #16384 //r2 = 0x50008000
/* 此时
* r1 = 0xC12
* r2 = 0x50008000 以级描述符表(页表)的结束地址
* r9 = 0x50000000 内存起始地址
* r10 = 0x60000000 内存结束地址
*/
1: cmp r1, r9 @ if virt > start of RAM
orrhs r1, r1, #0x0c @ set cacheable, bufferable //r1>r9才执行,我们这里不满足
cmp r1, r10 @ if virt > end of RAM
bichs r1, r1, #0x0c @ clear cacheable, bufferable//r1>r10才执行,我们这里不满足
str r1, [r0], #4 @ 1:1 mapping //执行后r0+4,执向下一个页表项
add r1, r1, #1048576
teq r0, r2
bne 1b
/* 简化后
* 1: cmp r1, r9 @ if virt > start of RAM r1 = 0xC12,r9 = 0x50000000
cmp r1, r10 @ if virt > end of RAM r1 = 0xC12,r10 = 0x60000000
str r1, [r0], #4 @ 1:1 mapping 执行后r0+4,执向下一个页表项
add r1, r1, #1048576 @r1 = r1+0x100000 = r1 +1MB
teq r0, r2
bne 1b
* 上面这段就是对一级页表的初始化流程
* 将描述符写入一个一级页表的入口,并将一级页表入口地址加4,而指向下一个1MB的section的基地址。
* 如果页表入口未初始化完,则继续初始化。
* 一级描述符结构如下:
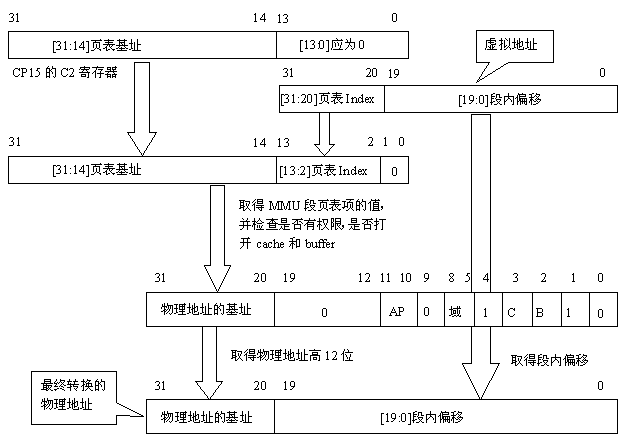
* ------------------------------------------------------------------------
* |31 20 | 19 12 | 11 10 | 9 | 8 5 | 4 | 3 | 2 | 1 |0 |
* -----------------------------------------------------------------------
* |物理地址的基址高12位 | 0 | AP | 0 | domain | 1 | C | B | 1 |0 |
* -----------------------------------------------------------------------
*
* 这是一个1:1映射
* ------------------------------------------------------
* 页表项序号 | 映射后的空间
* ------------------------------------------------------
* 0 | 0M --- (1M-1)
* 1 | 1M --- (2M-1)
* 2 | 2M --- (3M-1)
* ..... | .....
* 4095 | 4G-1M --- (4G-1)
* ------------------------------------------------------
*
* 一级描述符表(页表)的高12位是每个setcion对应的物理基地址。
* 一级页表大小为16K,每个页表项-即描述符占4字节,刚好可以容纳4096(4k)个描述符,
* 所以这里一共映射了4096*1M = 4G的空间。
*
*/
/* 可以不关注,因为对于ram,只是重复了上面的一部分操作
* If ever we are running from Flash, then we surely want the cache
* to be enabled also for our execution instance... We map 2MB of it
* so there is no map overlap problem for up to 1 MB compressed kernel.
* If the execution is in RAM then we would only be duplicating the above.
*/
mov r1, #0x1e @确保B和C位被置1
orr r1, r1, #3 << 10 @设置AP域为可读可写
/*
* 将当前地址1M对齐,并与r1中的内容结合成一个描述当前指令所在section的描述符。
*/
mov r2, pc
mov r2, r2, lsr #20
orr r1, r1, r2, lsl #20
add r0, r3, r2, lsl #2
str r1, [r0], #4
add r1, r1, #1048576 @r1 = r1+0x100000 = r1 +1MB
str r1, [r0]
mov pc, lr
ENDPROC(__setup_mmu)
MMU的段页表的虚拟地址与物理地址的转换过程如下:
3.7.4 刷新寄存器,使cache生效
__common_mmu_cache_on:
orr r0, r0, #0x000d @ Write buffer, mmu
mov r1, #-1
mcr p15, 0, r3, c2, c0, 0 @ load page table pointer
mcr p15, 0, r1, c3, c0, 0 @ load domain access control
b 1f
.align 5 @ cache line aligned
1: mcr p15, 0, r0, c1, c0, 0 @ load control register
mrc p15, 0, r0, c1, c0, 0 @ and read it back to
sub pc, lr, r0, lsr #32 @ properly flush pipeline
3.8 设置堆空间
mov r1, sp @ malloc space above stack
add r2, sp, #0x10000 @ 64k max
r1为堆的起始地址,r2为堆的结束地址。
3.9 判断解压后的内核是否会覆盖当前运行代码
/*
* Check to see if we will overwrite ourselves.
* r4 = final kernel address
* r5 = start of this image
* r6 = size of decompressed image
* r2 = end of malloc space (and therefore this image)
* We basically want:
* r4 >= r2 -> OK
* r4 + image length <= r5 -> OK
*/
cmp r4, r2
bhs wont_overwrite //hs 无符号大于等于
add r0, r4, r6
cmp r0, r5
bls wont_overwrite //hs 无符号小于等于
当前步骤中各个寄存值含义如下:
- r2 为堆的结束地址:r2 = 0x50008000 + xxx + 0x10000
- r4 为zImage解压后的指定运行地址:r4 = 0x50008000
- r5 为zImage解压前的起始(入口)地址:r5 = 0x50008000
- r6 为解压后内核占用空间的大小: _image_size = (_etext - _text) * 4 。计算规则从arch/arm/boot/compressed/vmlinux.lds中可以看到。
| |
|----------------|<------- r2堆的结束地址
| 堆空间64k |
| |
|----------------|
| 栈空间4k |
| |
|----------------|
| |
| 压缩后的内核 |
| zImage |
| 当前运行空间 |
| |
|----------------| 0x50008000 zImage的解压后运行地址 r4/解压前运行的入口地址 r5
| uImage字节头 |
|----------------|
| |
从上面的空间分布可以知道,如果在解压内核时,不覆盖当前的运行代码,必须满足以下两种条件之一:
- 解压后的内核存放的起始地址(解压后内核的运行地址) >= 堆的结束地址;即r4 >= r2
- 解压后的内核存放的起始地址(解压后内核的运行地址) + 解压后内核所占空间的大小<= zImage解压前运行的入口地址;即r4+r6 <= r5
从分析可以看到,上述的两个条件都不满足。所以内核解压时会覆盖当前运行的代码。因此需要先把内核解压到其它空闲的内存地址,然后再重定位到指定的地址中运行。
3.10 自解压的过程
mov r5, r2 @ decompress after malloc space //把堆的结束地址赋值给r5
mov r0, r5 //把堆的结束地址赋值给r0
mov r3, r7 //把处理器ID赋值给r3
bl decompress_kernel
经过赋值计算后当前各个寄存值含义如下:
- r0 为堆的结束地址
- r1 为堆的起始地址
- r2 为堆的结束地址
- r3 为机器ID
- r5 为堆的结束地址
其中decompress_kernel定义在\arch\arm\boot\compressed\misc.c中:
unsigned long decompress_kernel(unsigned long output_start, unsigned long free_mem_ptr_p,
unsigned long free_mem_ptr_end_p,
int arch_id)
{
unsigned char *tmp;
output_data = (unsigned char *)output_start; /* 解压后的内核临时存放地址,在堆之后 */
free_mem_ptr = free_mem_ptr_p; /* 解压后的内核临时存放地址,在堆之后 */
free_mem_end_ptr = free_mem_ptr_end_p; /* 堆的结束地址 */
__machine_arch_type = arch_id; /* 机器ID */
arch_decomp_setup();
tmp = (unsigned char *) (((unsigned long)input_data_end) - 4);
output_ptr = get_unaligned_le32(tmp);
/* 提示开始自解压*/
putstr("Uncompressing Linux...");
/* 解压 */
do_decompress(input_data, input_data_end - input_data,output_data, error);
/* 提示自解压结束 */
putstr(" done, booting the kernel.\n");
/* 返回内核解压后的长度 */
return output_ptr;
}
可以看到内核最终被解压在堆空间结束地址以上的地址处。(仅针对会覆盖的情况)
3.11 在解压内核后面空间预留128字节的栈空间
add r0, r0, #127 + 128 @ alignment + stack
bic r0, r0, #127 @ align the kernel length
r0为decompress_kernel()函数的返回值,即内核解压后的长度。
- 第一条指令:在解压后的内核后面预留128字节的栈空间
- 第二条指令:r0的值128字节对齐
| |
|--------------- |-----------
| 【128字节】 | |
| + | |
| | |
| 解压后的内核 | r0,128字节对齐
| | |
| | |
|----------------|<------- r5
| 堆空间64k |
| |
|----------------|
| 栈空间4k |
| |
|----------------|
| |
| 压缩后的内核 |
| zImage |
| 当前运行空间 |
| |
|----------------| 0x50008000 zImage的解压后运行地址r4
| uImage字节头 |
|----------------|
| |
3.12 搬移重定位代码段
/*
* r0 = decompressed kernel length
* r1-r3 = unused
* r4 = kernel execution address
* r5 = decompressed kernel start
* r7 = architecture ID
* r8 = atags pointer
* r9-r12,r14 = corrupted
*/
add r1, r5, r0 @ end of decompressed kernel
adr r2, reloc_start
ldr r3, LC1
add r3, r2, r3
1: ldmia r2!, {r9 - r12, r14} @ copy relocation code 开始重定位
stmia r1!, {r9 - r12, r14} /* 把r9-r12的值保存到r1指向的存储单元(!是r1运算和自动加1)*/
ldmia r2!, {r9 - r12, r14} /* 把r2指向的存储单元的值依次读到r9-r12中(!是r2运算和自动加1)*/
stmia r1!, {r9 - r12, r14}
cmp r2, r3
blo 1b
.......
LC1: .word reloc_end - reloc_start /* 需要重定位代码段的大小 */
各个寄存值含义如下:
- r1 = r5 +r0 = 解压后内核存放的起始地址 + 解压后内核大大小
- r2 = reloc_start标号所在的物理地址,即重定位代码段所在的起始物理地址
- r3 = *LC1(标号地址处的内容) = 需要重定位代码段的大小 (第一步)
- r3 = r2 + r3 = 重定位代码段的结束地址 (第二步)
|--------------- |<------- 搬移完成后的r1
| |
| 重定位代码段 |
| |
|--------------- |<------- 开始搬移重定位代码段时的r1
| 【128字节】 | |
| + | |
| | |
| 解压后的内核 | r0,128字节对齐
| | |
| | |
|----------------|<------- r5
| 堆空间64k |
| |
|----------------|
| 栈空间4k |
| |
|----------------|
| |
| 压缩后的内核 |
| zImage |
| 当前运行空间 |
| |
|----------------| 0x50008000 zImage的解压后运行地址r4
| uImage字节头 |
|----------------|
| |
为什么要搬移重定位代码段?
重定位代码段的主要功能是实现把解压后的内核搬移到指定的地址运行,搬移的过程中可能把重定位所需要的代码段覆盖,所以安全的做法就是将重定位代码段先搬移到一个空闲的内存地址,然后跳转到这个地址执行这段重定位代码,将解压后的内核搬移到指定的运行地址。
3.13 跳转到搬移后的重定位代码段继续执行
mov sp, r1
add sp, sp, #128 @ relocate the stack /*设置临时的栈,空间大小为128字节 */
bl cache_clean_flush
ARM( add pc, r5, r0 ) @ call relocation code /* 执行搬移后的重定位代码 */
THUMB( add r12, r5, r0 )
THUMB( mov pc, r12 ) @ call relocation code
|--------------- |<------- sp
| 临时栈空间 | 128字节
|--------------- |<------- r1
| |
| 重定位代码段 |
| |
|--------------- |<------- pc
| 【128字节】 | |
| + | |
| | |
| 解压后的内核 | r0,128字节对齐
| | |
| | |
|----------------|<------- r5
| 堆空间64k |
| |
|----------------|
| 栈空间4k |
| |
|----------------|
| |
| 压缩后的内核 |
| zImage |
| 当前运行空间 |
| |
|----------------| 0x50008000 zImage的解压后运行地址r4
| uImage字节头 |
|----------------|
| |
3.14 设置内核代码被重定位的起始地址
/*
* All code following this line is relocatable. It is relocated by
* the above code to the end of the decompressed kernel image and
* executed there. During this time, we have no stacks.
*
* r0 = decompressed kernel length
* r1-r3 = unused
* r4 = kernel execution address
* r5 = decompressed kernel start
* r7 = architecture ID
* r8 = atags pointer
* r9-r12,r14 = corrupted
*/
.align 5
reloc_start: add r9, r5, r0
sub r9, r9, #128 @ do not copy the stack
debug_reloc_start
mov r1, r4
|--------------- |<------- sp
| 临时栈空间 | 128字节
|--------------- |--------
| |
| 重定位代码段 |
| |
|--------------- |--------
| 【128字节】 | |
| + |<-----|---r9
| | |
| 解压后的内核 | r0,128字节对齐
| | |
| | |
|----------------|<------- r5
| 堆空间64k |
| |
|----------------|
| 栈空间4k |
| |
|----------------|
| |
| 压缩后的内核 |
| zImage |
| 当前运行空间 |
| |
|----------------| 0x50008000 zImage的解压后运行地址r4
| uImage字节头 |
|----------------|
| |
3.15 开始重定位
1:
.rept 4
ldmia r5!, {r0, r2, r3, r10 - r12, r14} @ relocate kernel
stmia r1!, {r0, r2, r3, r10 - r12, r14}
.endr
cmp r5, r9
blo 1b
|--------------- |<------- sp
| 临时栈空间 | 128字节
|--------------- |-------
| |<------- pc
| 重定位代码段 |
| |
|--------------- |
| |
| |<------- r1
| |
| 解压后的内核 |
| |
| |
|----------------| 0x50008000 zImage的解压后运行地址 r4
| uImage字节头 |
|----------------|
| |
3.16 加载真正的内核Image
mov sp, r1
add sp, sp, #128 @ relocate the stack
debug_reloc_end
call_kernel: bl cache_clean_flush
bl cache_off
mov r0, #0 @ must be zero
mov r1, r7 @ restore architecture number
mov r2, r8 @ restore atags pointer
mov pc, r4 @ call kernel
清除并关闭cache,清零r0,恢复内核启动所需要的的参数:将machine ID存入r1,将atags指针存入r1,再跳转到0x50008000执行真正的内核Image。
|--------------- |--------
| 临时栈空间 | 128字节
|--------------- |-------
| |
| 重定位代码段 |
| |
|----------------|
| |
| |
|--------------- |<------- sp
| 临时栈空间 | 128字节
|--------------- |--------
| |
| 解压后的内核 |
| |
| |
|----------------| 0x50008000 zImage的解压后运行地址 r4 ,pc
| uImage字节头 |
|----------------|
| |
四. 总结 — 流程图
图形太大,可以下载后放大看
本文来自博客园,作者:BSP-路人甲,转载请注明原文链接:https://www.cnblogs.com/jianhua1992/p/16852791.html,并保留此段声明,否则保留追究法律责任的权利。


