网络流量分类技术总结
以下内容主要参考西安电子科技大学的硕士论文《基于SDN和机器学习的QoS保障技术研究》的相关描述。
网络流量定义
根据互联网通信标准文件RFC3917中的有关定义,一条网络流量是指在一段特定的时间间隔之内,通过网络中某一个观测点的所有具有相同五元组(源IP地址、目的IP地址、传输层协议、源端口和口的端口)的分组的集合。此外,根据TCP和UDP传输的双端特性,网络流也可以分为单向流和双向流。其中,将具有相同五元组数据的一条网络流认为是单向流,而双向流的源IP和口的IP以及源端口和目的端口可以同时互换。基于不同的研究目的,研究者可以选择按照单向流或者双向流的定义进行网络流量相关的研究,本文将基于双向流的定义对网络流展开流量分类以及QoS保障的相关研究。
网络流量分类概念
网络流量分类是指,利用某种算法构造一个分类模型,并用该分类模型对收集到的各种应用程序的网络流数据进行分类识别,分类识别的结果是某种应用程序或者应用层协议,又或者是根据QoS要求划分的某种业务类型。影响分类准确率的主要是分类模型,在不同的时代和不同的应用场景下不同分类技术构造的分类模型的分类效果也不一样。
最早的网络流量分类方法是使用传输层协议UDP或TCP端口号进行分类,该方法易于实现,而且算法时间复杂度低,因此在只需要分类出某些指定端口的应用时经常被使用。但是,随着应用程序及协议的多元化以及端口跳变和端口伪装技术]的出现,导致基于端口识别的流量分类方法的准确度越来越低,该方法不再可靠,只能作为流量分类的辅助手段。Madhukar[14]等人在实验测试中证实有接近70%的网络流量都无法使用单独的基于端口识别方法来正确地分类。
研究人员发现数据包的有效载荷部分包含着很多特殊的信息,因此深度包检测(Deep Packet Inspection, DPI)技术逐渐受到关注。DPI技术主要是通过分析网络流中数据包的有效载荷,如果该有效载荷部分和口前己知应用程序或协议在某些特征字上能够匹配,那么就可以大概率地认为这条网络流是该己知应用程序或协议。由于DPI技术不需要用到数据包的端口,因此不受端口伪装和跳变等技术的影响,相比基于端口的流量分类,其准确率有很大提升。但是,因为数据加密和隐私安全问题,使得利用该技术对网络流量进行分类也不再是一个好的选择。
近年来,利用网络流量的统计特征和机器学习算法进行流量分类的技术受到了众多研究人员的关注。其中,Moore等人[16]的研究是具有开创性的,研究者们提出了一种基于朴素贝叶斯原理的分类方法,该分类方法研究了网络流量的特征集与网络类别之间的概率关系,并利用贝叶斯原理构建计算模型,最终得到的分类准确率达到65 %。虽然他们的分类器准确率不够理想,但是收集的包含248个特征并打上分类标签的Moore流量数据集,成为了很多研究人员的实验数据,248种流量特征也为其他研究者在特征选取上提供了指导意义。由于Moore数据集中大部分特征是需要收集整条网络流的信息后才可以进行分类,因此在需要在线实时分类的场合不适用。在实时网络流量分类方面,Bernaille等人[17]利用TCP流量前五个数据包特征信息,使用不同的机器学习算法得到的整体分类准确率都在90%以上。此外,文献[18]表明利用网络流量的前几个数据包特征能够用于机器学习实时流量分类。在各种机器学习算法对流量的分类准确率方面,Williams等人将朴素贝叶斯、最近邻、决策树和支持向量机等最常用的机器学习算法用于流量分类技术中,实验结果表明在这些算法中分类效果最好的是决策树。此外,文献[21]的研究也表明决策树算法在实时流量分类中具有很好的效果。也有部分学者将深度学习用于流量分类[[23],虽然准确性很高但是由于要收集过多的流量特征信息,实时性并不理想。
基于上述对机器学习分类研究现状的讨论,结合本文为区分服务QOS模型提供实时网络流量分类的口的,本文选择基于决策树算法进行实时流量分类,然而使用前多少个有效数据包的特征才能达到更高的分类准确率和实时性还值得进一步研究。
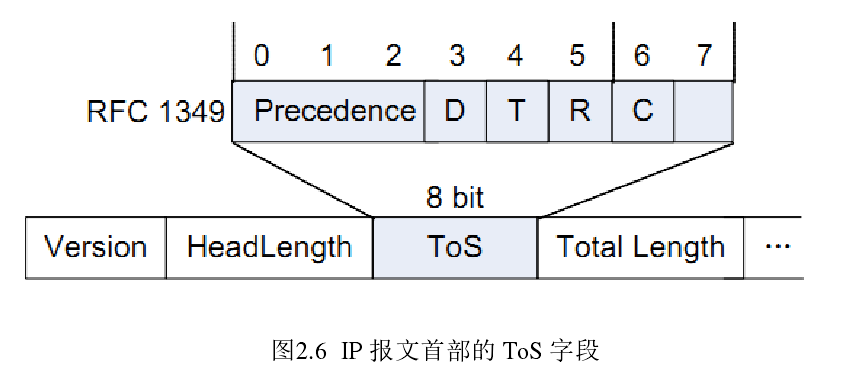
在区分服务QoS模型中根据网络流量的服务优先级定义了8种流量类别,如图2.6所示,RFC 1349将ToS字段中前3个比特定义为报文在网络中传输的8个优先级,数值越大优先级越高,此报文优先级一般对应到报文在转发设备中的服务等级,从高到低为CS7, CS6, EF, AF4, AF3, AF2, AF1, BE,同时这也是逐跳行为(Per-Hop Behavior, PHB ),来表示为不同优先级的业务提供不同的资源分配、队列调度和分组丢弃等服务。其中,EF类型流量需要加急转发((Expedited Forwarding), AF类型流量需要确保转发(Assured Forwarding), BE类型流量只需要尽力转发(Best Effort) 。
基于端口识别和基于深度包检测的流量分类技术,它们的本质都是通过解析数据包的固有成分来达到分类的目的,因此除了前述两种流量分类技术自有的各种不同的缺点之外,它们还有一种相同的缺点一一两者都不能智能地对流量分类识别,而是只能根据人为规定的匹配规则来做流量分类。针对当前流量分类技术无法实现智能化的缺陷,使用智能的机器学习方法无疑是一个很值得研究的方向。与前述两种分类技术不同的是,机器学习方法不是只通过解析数据包的局部固有成分,而是通过流量的宏观特征以及各种统计行为特征来为流量分类。基于机器学习的流量分类技术能够适应网络流量的宏观行为及特征的变化,在流量分类识别的过程中更具智能化,相比于前两种流量分类技术有明显的优势。网络中通信的流量也存在很多的数据统计特征,不同的应用程序或协议产生的流量数据统计特征的差异性使得运用机器学习进行流量分类成为可能。因此,目前利用机器学习进行流量分类的技术也受到了众多研究人员的关注。

基于机器学习技术对网络流量完成分类识别任务的完整流程如图2.7所示。基于机器学习的流量分类技术主要步骤如下:
1.首先,通过一些软件工具如wireshark, netflow或自研软件等在网络流数据包经过的地方完成基础流量收集,这些数据集可以认为是初始流量数据集。
2.然后,需要对初始的流量数据进行预处理,从收集的初始流量数据集中提取多个候选统计特征,例如数据包的个数、包长字节数、包总比特数和数据包之间的间隔时间、整条网络流的持续时间等特征得到候选特征数据集。这些统计特征都属于网络流的宏观行为特征,与用于深度包检测的数据包有效载荷完全无关,在特征提取的计算时间复杂度方面更有优势。但是由于并不是每一个候选特征都能够为流量的分类带来很好的区分效果,可能有些特征之间存在很强的关联性,有些特征对流量的分类毫无影响,这些特征都是属于冗余特征。因此,在进行机器学习模型的训练之前都需要先使用一些特征降维技术来去除冗余特征,然后得到流量特征样本集。
3.最后,将包含了各种流量特征的数据集分成训练和测试数据集,选择一种机器学习算法使用这些数据集完成训练测试工作,在分类模型达到了满意的分类准确率后停止训练并保存该分类模型。当一个新的未知类型的网络流到达数据采集点时,采集流量数据并对数据进行预处理得到一条符合分类模型输入条件的特征数据,最终通过分类模型得到分类结果。
在基于有监督机器学习的流量分类方法中,流量类别是基于实际应用预定义的,还需要手动收集一组标记的训练样本用于分类器构造学习。为了实现高的分类准确度,有监督学习分类方法需要足够多的标记训练数据。在基于无监督的流量分类方法中,主要是使用基于聚类的方法如K均值聚类,该方法可以自动对一组未标记的训练样本进行分组,并使用聚类结果来训练流量分类器,由于聚类算法在聚类的过程中不使用样本的类别属性,因此能够识别出数据样本中没有分类定义的新型网络应用。在基于半监督的流量分类方法中,流量分类仅需要一小组有监督数据,就可以将一些无类别标记的流量划分到与它们最近的类中。
参考文献
[14] Madhukar A, Williamson C. A longitudinal study of P2P traffic classification[C]//14th IEEE
International Symposium on Modeling, Analysis, and Simulation. IEEE, 2006:179一188.
[15]Sen S, Spatscheck O, Wang D. Accurate, Scalable In Network Identification of P2P Traffic Using Application Signatures[C].In
Proceedings of the International conference on World Wide Web, 2004: 512-521.
[16] A.W. Moore, D. Zuev. Internet traffic classification using bayesian analysis techniques[C].In
Proceedings of the 2005 ACM SIGMETRICS International Conference on Measurement and
Modeling of Computer Systems, Banff, 2005, 50一60.
[17] Bernaille, Laurent. Implementation issues of early application identification[C].In Proceedings
of the Third Asian Internet Engineering Conference, AINTEC, Phuket, Thailand, 2012, 156一166.
[18]彭建芬,周亚建,王机等.TCP流量早期分类方法[[J].应用科学学报,2011, 29(1): 73-77.
[20] Williams N, Zander S, Armitage G. A preliminary performance study comparison of five
machine learning algorithms for practical IP traffic flow classification[R].SIGCOMM Computer
Communication Review, 2006, 36(5): 5一16
[21]Sun Mei-feng, Chen Jing-tao. Research of the traffic characteristics for the real time online
traffic classification[J].The Journal of China Universities of Posts and Telecommunications,
2011,18(3):92-98.
[22] Gu Cheng一ie, Zhang Shun-yi, Sun Yan-fei. Real-time Encrypted Traffic Identification using
Machine Learning[J]. Journal of Software, 2011,6(6):1009一1016.
[23] Wang Yong, Zhou Hui-yi, Feng Hao. Network traffic classification method basing on CNN[C].
Journal on Communications, 2018, 39(1):14-23.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号