07、RDD持久化

为了避免多次计算同一个RDD(如上面的同一result RDD就调用了两次Action操作),可以让Spark对数据进行持久化。当我们让Spark持久化存储一个RDD时,计算出RDD的节点会分别保存它们所求出的分区数据。如果一个有持久化数据的节点发生故障,Spark会在需要用到缓存的数据时重算丢失的数据分区。
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。
巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清理缓存,那么可以使用unpersist()方法。
Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
RDD持久化策略
RDD持久化是可以手动选择不同的策略的。比如可以将RDD持久化在内存中、持久化到磁盘上、使用序列化的方式持久化,多持久化的数据进行多路复用。只要在调用persist()时传入对应的StorageLevel即可。
持久化级别 | |
MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算 |
MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
MEMORY_AND_DSK_SER | 同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 | 如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
如何选择RDD持久化策略?
Spark提供的多种持久化级别,主要是为了在CPU和内存消耗之间进行取舍。下面是一些通用的持久化级别的选择建议:
1、优先使用MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
2、如果MEMORY_ONLY策略,无法存储的下所有数据的话,那么使用MEMORY_ONLY_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化。
3、如果需要进行快速的失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
4、能不使用DISK相关的策略,就不用使用,有的时候,从磁盘读取数据,还不如重新计算一次。
正确调用:
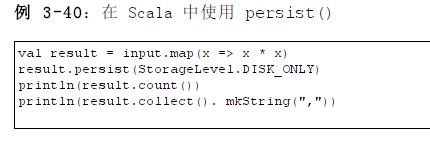
注意,需要在第一次调用Acton操作之前就要调用 persist() 方法。
如果要缓存的数据太多,内存中放不下,Spark会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。对于仅把数据存放在内存中的缓存级别,下一次要用到已经被移除的分区时,这些分区就需要重新计算。但是对于使用内存与磁盘的缓存级别(MEMORY_AND_DISK、MEMORY_AND_DISK_SER)的分区来说,被移除的分区都会写入磁盘。不论哪一种情况,都不必担心你的作业因为缓存了太多数据而被打断。
/**
* RDD持久化
*/
public class Persist {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Persist").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// cache()或者persist()的使用,是有规则的
// 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
// 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
// 而且,会报错,大量的文件会丢失
JavaRDD<String> lines = sc.textFile("test.txt").cache();
long beginTime = System.currentTimeMillis();
long count = lines.count();
System.out.println(count);
long endTime = System.currentTimeMillis();
System.out.println("cost " + (endTime - beginTime) + " milliseconds.");
beginTime = System.currentTimeMillis();
count = lines.count();
System.out.println(count);
endTime = System.currentTimeMillis();
System.out.println("cost " + (endTime - beginTime) + " milliseconds.");
sc.close();
}
}
原文出自 江正军 技术博客,博客链接:www.cnblogs.com/jiangzhengjun

 浙公网安备 33010602011771号
浙公网安备 33010602011771号