00、Word Count
1、开发环境
1、eclipse-jee-neon-3
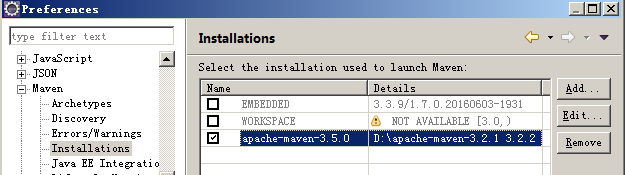
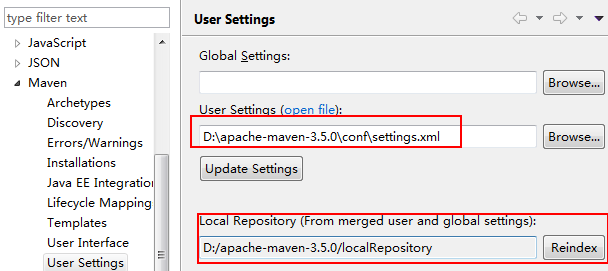
3、下载Maven,修改D:\apache-maven-3.5.0\conf\settings.xml配置文件:
本地库位置:
<localRepository>D:/apache-maven-3.5.0/localRepository</localRepository>
仓库使用阿里云:
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
4、配置Maven
2、本地Local模拟运行
本地模式,即不需要启动Spark即可模拟运行,如果初始RDD来自于HDFS上的文件,则仅需启动Hadoop,不管是在Eclipse中直接运行,还是通过spark-submit提交运行

2.1、Java版
pom.xml文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkcore</groupId>
<artifactId>sparkcore-java</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>sparkcore-java</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.9</version>
</dependency>
</dependencies>
</project>package sparkcore.java;
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
/**
* 使用java开发本地测试的wordcount程序
*/
public class WordCountLocal {
public static void main(String[] args) {
// 编写Spark应用程序
// 本地执行,是可以执行在eclipse中的main方法中,执行的
// 第一步:创建SparkConf对象,设置Spark应用的配置信息
// 使用setMaster()可以设置Spark应用程序要连接的Spark集群的master节点的url
// 但是如果设置为local则代表,在本地运行
SparkConf conf = new SparkConf().setAppName("WordCountLocal").setMaster("local");
// 以spark-submit提交运行时,需要设置,如直接以Java应用程序启动,则可以去掉
conf.set("spark.testing.memory", "536870912");// 512M
// 第二步:创建JavaSparkContext对象
// 在Spark中,SparkContext是Spark所有功能的一个入口,你无论是用java、scala,甚至是python编写
// 都必须要有一个SparkContext,它的主要作用,包括初始化Spark应用程序所需的一些核心组件,包括
// 调度器(DAGSchedule、TaskScheduler),还会去到Spark Master节点上进行注册,等等
// 一句话,SparkContext,是Spark应用中,可以说是最最重要的一个对象
// 但是呢,在Spark中,编写不同类型的Spark应用程序,使用的SparkContext是不同的,如果使用scala,
// 使用的就是原生的SparkContext对象
// 但是如果使用Java,那么就是JavaSparkContext对象
// 如果是开发Spark SQL程序,那么就是SQLContext、HiveContext
// 如果是开发Spark Streaming程序,那么就是它独有的SparkContext
// 以此类推
JavaSparkContext sc = new JavaSparkContext(conf);
// 第三步:要针对输入源(hdfs文件、本地文件,等等),创建一个初始的RDD
// 输入源中的数据会打散,分配到RDD的每个partition中,从而形成一个初始的分布式的数据集
// 我们这里呢,因为是本地测试,所以呢,就是针对本地文件
// SparkContext中,用于根据文件类型的输入源创建RDD的方法,叫做textFile()方法
// 在Java中,创建的普通RDD,都叫做JavaRDD
// 在这里呢,RDD中,有元素这种概念,如果是hdfs或者本地文件呢,创建的RDD,每一个元素就相当于是文件里的一行
// JavaRDD<String> lines = sc.textFile("file:///D:/eclipse-jee-neon-3/workspace/sparkcore-java/test.txt");
// 如果本地文件为Linux
JavaRDD<String> lines = sc.textFile("file:////root/spark/core/test.txt");
// 如果文件放在HDFS上时,需要先启动Hadoop
// JavaRDD<String> lines = sc.textFile("hdfs://node1:8020/test.txt");
// 第四步:对初始RDD进行transformation操作,也就是一些计算操作
// 通常操作会通过创建function,并配合RDD的map、flatMap等算子来执行
// function,通常,如果比较简单,则创建指定Function的匿名内部类
// 但是如果function比较复杂,则会单独创建一个类,作为实现这个function接口的类
// 先将每一行拆分成单个的单词
// FlatMapFunction,有两个泛型参数,分别代表了输入和输出类型
// 我们这里呢,输入肯定是String,因为是一行一行的文本,输出,其实也是String,只不过是多个放在集合中
// 这里先简要介绍flatMap算子的作用,其实就是,将RDD的一个元素,给拆分成一个或多个元素
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
// 接着,需要将每一个单词,映射为(单词, 1)的这种格式
// 因为只有这样,后面才能根据单词作为key,来进行每个单词的出现次数的累加
// mapToPair,其实就是将每个元素,映射为一个(v1,v2)这样的Tuple2类型的元素
// 如果大家还记得scala里面讲的tuple,那么没错,这里的tuple2就是scala类型,包含了两个值
// mapToPair这个算子,要求的是与PairFunction配合使用,第一个泛型参数代表了输入类型
// 第二个和第三个泛型参数,代表的输出的Tuple2的第一个值和第二个值的类型
// JavaPairRDD的两个泛型参数,分别代表了tuple元素的第一个值和第二个值的类型
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
// 接着,需要以单词作为key,统计每个单词出现的次数
// 这里要使用reduceByKey这个算子,对每个key对应的value,都进行reduce操作
// 比如JavaPairRDD中有几个元素,分别为(hello, 1) (hello, 1) (hello, 1) (world, 1)
// reduce操作,相当于是把第一个值和第二个值进行计算,然后再将结果与第三个值进行计算
// 比如这里的hello,那么就相当于是,首先是1 + 1 = 2,然后再将2 + 1 = 3
// 最后返回的JavaPairRDD中的元素,也是tuple,但是第一个值就是每个key,第二个值就是key的value
// reduce之后的结果,相当于就是每个单词出现的次数
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(
// 第一与第二个参数为输入类型(为两个Tuple2的第二个元素类型),第三个为输出类型
new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 到这里为止,我们通过几个Spark算子操作,已经统计出了单词的次数
// 但是,之前我们使用的flatMap、mapToPair、reduceByKey这种操作,都叫做transformation操作
// 一个Spark应用中,光是有transformation操作,是不行的,是不会执行的,必须要有一种叫做action
// 接着,最后,可以使用一种叫做action操作的,比如说,foreach,来触发程序的执行
wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " : " + wordCount._2);
}
});
sc.close();
}
}将上面程序通过Mave打包成jar文件,上传到Linux平台,然后通过spark-submit提交本地运行(无需启动Spark,如果用到的文件在HDFS上面,则要启动Hadoop):
spark-submit \
--master local[1] \
--class sparkcore.java.WordCountLocal \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 2 \
/root/spark/core/sparkcore-java-1.0.jar
2.2、配置Hadoop客户端
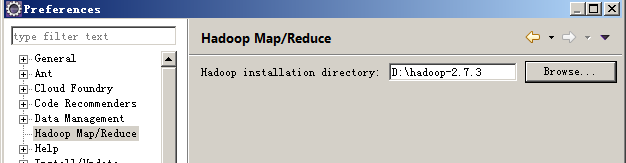
运行时可能会抛如下异常,但不影响结果,原因是Hadoop没有配置,也可以按照下面进行配置

1、 将hadoop-2.7.3.tar.gz(前面自己编译的CentOS版本)解压到D:\hadoop-2.7.3,并将winutils.exe、hadoop.dll等文件到D:\hadoop-2.7.3\bin下,再将hadoop.dll放到C:\Windows及C:\Windows\System32下
2、 添加HADOOP_HOME环境变量,值为D:\hadoop\hadoop-2.7.2,并将%HADOOP_HOME%\bin添加到Path环境变量中
3、 双击winutils.exe,如果出现“缺失MSVCR120.dll”的提示,则安装VC++2013相关组件
4、 将hadoop-eclipse-plugin-2.7.3.jar插件包拷贝到Eclipse plugins目录下
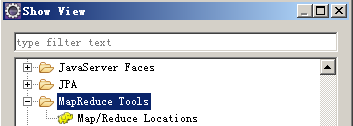
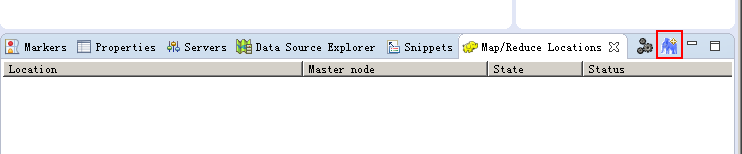
5、 运行Eclipse,进行配置:

2.3、Scala版:
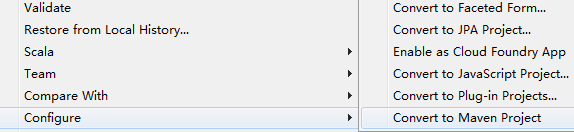
1、先创建Scala普通工程
2、右击工程,将普通工程转换为Maven工程
3、pom.xm
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkcore</groupId>
<artifactId>sparkcore-java</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>sparkcore-scala</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.9</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src</sourceDirectory>
</build>
</project>4、将scala版本修改成2.11:

5、然后打包与Java版本的Maven一样,也可以打包jar包
package sparkcore.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCountLocal {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
conf.set("spark.testing.memory", "536870912"); // 512M
val sc = new SparkContext(conf)
// val lines = sc.textFile("file:///D:/eclipse-jee-neon-3/workspace/sparkcore-scala/test.txt", 1);
// val lines = sc.textFile("file:////root/spark/core/test.txt", 1);
val lines = sc.textFile("hdfs://node1:8020/test.txt", 1);
val words = lines.flatMap { line => line.split(" ") }
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.reduceByKey { _ + _ }
wordCounts.foreach(wordCount => println(wordCount._1 + " : " + wordCount._2))
}
}与Java版本一样,可以在Eclipse中直接运行,也可以打成jar,传到Linux上,通过spark-submit提交本地运行:
spark-submit \
--master local[1] \
--class sparkcore.scala.WordCountLocal \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 2 \
/root/spark/core/sparkcore-scala-1.0.jar
3、Standalone模式运行
将任务提交到Spark集群上运行,所以Spark一定要开启,并有屏幕打印将不会直接打屏,而是在相应Work后台日志中显示

3.1、Java版
spark-submit \
--master spark://node1:7077 \
--class sparkcore.java.WordCountCluster \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 512m \
--executor-cores 1 \
/root/spark/core/sparkcore-java-1.0.jar
package sparkcore.java;
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
/**
* 将java开发的wordcount程序部署到spark集群上运行
*/
public class WordCountCluster {
public static void main(String[] args) {
// 如果要在spark集群上运行,需要修改的,只有两个地方
// 第一,将SparkConf的setMaster()方法给删掉,默认它自己会去连接(未设置时运行时以spark-submit中的--master指定模式为准)
// 第二,我们针对的不是本地文件了,修改为hadoop hdfs上的真正的存储大数据的文件
// 实际执行步骤:
// 1、将test.txt文件上传到hdfs上去
// 2、使用maven插件,对spark工程进行打Jar包
// 3、将打包后的spark工程jar包,上传到机器上执行
// 4、编写spark-submit脚本
// 5、执行spark-submit脚本,提交spark应用到集群执行
SparkConf conf = new SparkConf().setAppName("WordCountCluster");
conf.set("spark.testing.memory", "536870912");// 512M
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://node1:8020/test.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " : " + wordCount._2);
}
});
sc.close();
}
}3.2、Scala版
spark-submit \
--master spark://node1:7077 \
--class sparkcore.scala.WordCountCluster \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 512m \
--executor-cores 1 \
/root/spark/core/sparkcore-scala-1.0.jar
package sparkcore.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCountCluster {
def main(args: Array[String]) {
//当程序中使用setMaster指定后,以程序中设定的为准,会忽略掉spark-submit的--master
//如果没有设置setMaster,则以spark-submit中的--master为准
val conf = new SparkConf().setAppName("WordCountCluster").setMaster("spark://node1:7077")
conf.set("spark.testing.memory", "536870912") //
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://node1:8020/test.txt")
//如果以Standalone模式运行时,如果读取的操作系统本地文件,则每个Work上都要拷贝一份(但只会读取某一台机器上的文件)
// val lines = sc.textFile("file:////root/spark/core/test.txt", 1);
val words = lines.flatMap { line => line.split(" ") }
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.reduceByKey { _ + _ }
wordCounts.foreach(wordCount => println(wordCount._1 + " : " + wordCount._2))
}
}Spark配置项的优先顺序
(1)在用户代码中用SparkConf对象上的set()函数显式声明的配置。
(2)传递给spark-submit或spark-shell的标志。
(3)在spark-defaults.conf属性文件中的值。
(4)Spark的默认值。
4、在spark-shell中运行
运行前,需要启动Spark。spark-shell相当于本地Local模式,不会提交到Spark集群上跑,因此如果用的本地文件,则只需要在运行spark-shell 机器本地上放一个文件即可
[root@node1 ~]# spark-shell
scala> :paste
// Entering paste mode (ctrl-D to finish)
val lines = sc.textFile("file:////root/spark/core/test.txt", 1);
val words = lines.flatMap { line => line.split(" ") }
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.reduceByKey { _ + _ }
wordCounts.foreach(wordCount => println(wordCount._1 + " : " + wordCount._2))
// Exiting paste mode, now interpreting.
you : 2
hello : 4
me : 2
lines: org.apache.spark.rdd.RDD[String] = file:////root/spark/core/test.txt MapPartitionsRDD[1] at textFile at <console>:24
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:25
pairs: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:26
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:27
原文出自 江正军 技术博客,博客链接:www.cnblogs.com/jiangzhengjun

 浙公网安备 33010602011771号
浙公网安备 33010602011771号