Scala详解
13.6.9 列表转换:toArray, copyToArray
13.7.1 映射与处理:map、flatMap、flatten、foreach
13.7.2 过滤:filter、partition、find、takeWhile、dropWhile、span
14.4 可变(mutable)集合Vs.不可变(immutable)集合
14.5.1 集合转化为数组(Array)、列表(List)
1 快速入门
1.1 分号
分号表示语句的结束;
如果一行只有一条语句时,可以省略,多条时,需要分隔
一般一行结束时,表示表达式结束,除非推断该表达式未结束:
// 末尾的等号表明下一行还有未结束的代码.
def equalsign(s: String) =
println("equalsign: " + s)
// 末尾的花括号表明下一行还有未结束的代码.
def equalsign2(s: String) = {
println("equalsign2: " + s)
}
//末尾的逗号、句号和操作符都可以表明,下一行还有未结束的代码.
def commas(s1: String,
s2: String) = Console.
println("comma: " + s1 +
", " + s2)
多个表达式在同一行时,需要使用分号分隔
1.2 常变量声明
1.2.1 val常量
定义的引用不可变,不能再指向别的对象,相当于Java中的final
Scala中一切皆对象,所以,定义一切都是引用(包括定义的基本类型变量,实质上是对象)
val定义的引用不可变,指不能再指向其他变量,但指向的内容是可以变的:

val定义的常量必须要初始化
val的特性能并发或分布式编程很有好处
1.2.2 var变量
定义的引用可以再次改变(内容就更可以修改了),但定义时也需要初始化
在Java中有原生类型(基础类型),即char、byte、short、int、long、float、double和boolean,这些都有相应的Scala类型(没有基本类型,但好比Java中相应的包装类型),Scala编译成字节码时将这些类型尽可能地转为Java中的原生类型,使你可以得到原生类型的运行效率
用val和var声明变量时必须初始化,但这两个关键字均可以用在构造函数的参数中,这时变量是该类的一个属性,因此显然不必在声明时进行初始化。此时如果用val声明,该属性是不可变的;如果用var声明,则该属性是可变的:
class Person(val name: String, var age: Int)
即姓名不可变,但年龄是变化的
val p = new Person("Dean Wampler", 29)

var和val关键字只标识引用本身是否可以指向另一个不同的对象,它们并未表明其所引用的对象内容是否可变
1.2.3 类型推导
定义时可以省略类型,会根据值来推导出类型
scala> var str = "hello"
str: String = hello
scala> var int = 1
int: Int = 1
定义时也可明确指定类型:
scala> var str2:String = "2"
str2: String = 2
1.2.4 函数编程风格
以前传统Java都是指令式编程风格,如果代码根本就没有var,即仅含有val,那它或许是函数式编程风格,因此向函数式风格转变的方式之一,多使用val,尝试不用任何var编程
指令式编程风格:
def printArgs(args: Array[String]): Unit = {
var i = 0
while (i < args.length) {
println(args(i))
i += 1
}
}
函数式编程风格:
def printArgs(args: Array[String]): Unit = {
for (arg <- args)
println(arg)
}
或者:
def printArgs(args: Array[String]): Unit = {
//如果函数字面量只有一行语句并且只带一个参数,
//则么甚至连指代参数都不需要
args.foreach(println)
}
1.3 Range
数据范围、序列
支持Range的类型包括Int、Long、Float、Double、Char、BigInt和BigDecimal
Range可以包含区间上限,也可以不包含区间上限;步长默认为1,也可以指定一个非1的步长:


1.4 定义函数
函数是一种具有返回值(包括空Unit类型)的方法
函数体中最后一条语句即为返回值。如果函数会根据不同情况返回不同类型值时,函数的返回类型将是不同值的通用(父)类型,或者是可以相互转换的类型(如Char->Int)
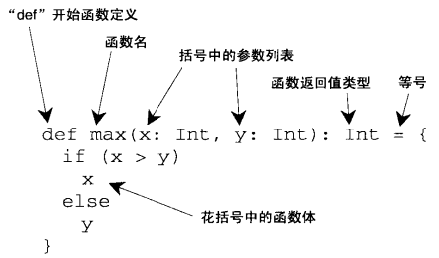
如果函数体只一条语句,可以省略花括号:
def max2(x:Int,y:Int)=if(x>y)x else y
scala> max2(3,5)
res2: Int = 5
Unit:返回类型为空,即Java中的void类型。如果函数返回为空,则可以省略
scala> def greet()=println("Hello")
greet: ()Unit
1.5 while、if
打印入口程序的外部传入的参数:
object Test {
def main(args: Array[String]): Unit = {
var i = 0
while (i < args.length) {
if (i != 0) print(" ")
print(args(i))
i += 1
}
}
}
注:Java有++i及i++,但Scala中没有。
与Java一样,while或if后面的布尔表达式必须放在括号里,不能写成诸如 if i < 10 的形式
1.6 foreach、for
object Test {
def main(args: Array[String]): Unit = {
var i = 0;
args.foreach(arg => { if (i != 0) print(" "); print(arg); i += 1 })
}
}
foreach方法参数要求传的是函数字面量(匿名函数),arg为函数字面量的参数,并且值为遍历出来的集合中的每个元素,类型为String,已省略,如不省略,则应为:
args.foreach((arg: String) => { if (i != 0) print(" "); print(arg); i += 1 })
如果函数字面量只有一行语句并且只带一个参数,则么甚至连指代参数都不需要:
args.foreach(println)
也可以使用for循环来代替:
for (arg <- args) println(arg)
1.7 读取文件
object Test {
def main(args: Array[String]): Unit = {
import scala.io.Source
//将文件中所有行读取到List列表中
val lines = Source.fromFile(args(0)).getLines().toList
//找到最长的行:类似冒泡排序,每次拿两个元素进行比较
val longestLine = lines.reduceLeft((a, b) => if (a.length() > b.length()) a else b)
//最长行的长度本身的宽度
val maxWidth = widthOfLength(longestLine)
for (line <- lines) {
val numSpaces = maxWidth - widthOfLength(line)
//让输出的每行宽度右对齐
val padding = " " * numSpaces
println(padding + line.length() + " | " + line)
}
}
def widthOfLength(s: String) = s.length().toString().length()
}

1.8 类、字段和方法
类的方法以 def 定义开始,要注意的 Scala 的方法的参数都是 val 类型,而不是 var 类型,因此在函数体内不可以修改参数的值,比如如果你修改 add 方法如下:
使用class定义类:
class ChecksumAccumulator {}
然后就可以使用 new 来实例化:
val cal = new ChecksumAccumulator
类里面可以放置字段和方法,这都称为成员(member)。
字段,不管是使用val还是var,都是指向对象的变量(即Java中的引用)
方法,使用def进行定义
class ChecksumAccumulator {
var sum = 0
}
object Test {
def main(args: Array[String]): Unit = {
val acc = new ChecksumAccumulator
val csa = new ChecksumAccumulator
}
}
刚实例化时内存的状态如下:
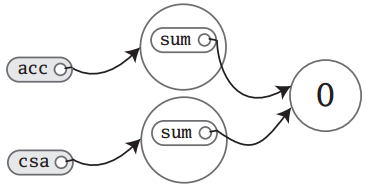
注:在Scala中,由于数字类型(整型与小数)都是final类型的,即不可变,所以在内存中如果是同一数据,则是共享的
由于上面是使用var进行定义的字段,而不是val,所以可以重新赋值:
acc.sum = 3
现在内存状态如下:
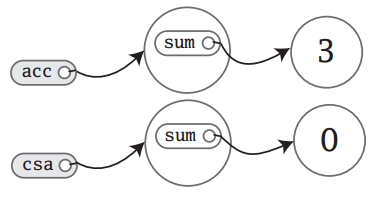
由于修改了acc中sum的内容,所以acc.sum指向了3所在的内存。
对象的稳定型就是要保证对象状态的稳定型,即对象中字段值在对象整个生命周期中持续有效。这需要将字段设为private以阻止外界直接对它进行访问与修改,因为私有字段只能被同一类里的方法访问,所以更新字段的代码将被锁定在类里:
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte): Unit = {
sum += b
}
}
与Java 不同的,Scala 的缺省修饰符为 public,也就是如果不带有访问范围的修饰符 public,protected,private,Scala 缺省定义为 public
类的方法以 def 定义开始,要注意的 Scala 的方法的参数都是 val 类型,而不是 var 类型,因此在函数体内不可以修改参数的值,比如如果你修改 add 方法如下:
def add(b: Byte): Unit = {
b = 1 // 编译出错,因为b是val :error: reassignment to val
sum += b
}
如果某个方法的方法体只有一条语句,则可以去掉花括号:
def add(b: Byte): Unit = sum += b
类的方法分两种,一种是有返回值的,一种是不含返回值
如果方法没有返回值(或为Unit),则定义方法时可以去掉结果类型和等号 =,并把方法体放在花括号里:
def add(b: Byte) { sum += b }
定义方法时,如果去掉方法体前面的等号 =,则方法的结果类型就一定是Unit,这不管方法体最后语句是啥,因为编译器可以把任何类型转换为Unit,如结果是String,但返回结果类型声明为Unit,那么String将被转换为Unit并丢弃原值。下面是明确定义返回类型为Unit:
scala> def f(): Unit = "this String gets lost"
f: ()Unit
去掉等号的方法返回值类型也一定是Unit:
scala> def g() { "this String gets lost too" }
g: ()Unit
加上等号时,如果没有确定定义返回类型,则会根据方法体最后语句来推导:
scala> def h() = { "this String gets returned!" }
h: ()java.lang.String
scala> h
res0: java.lang.String = this String gets returned!
Scala 代码无需使用“;”结尾,也不需要使用 return返回值,函数的最后一行的值就作为函数的返回值
1.9 Singleton单例对象
Scala中不能定义静态成员,而是以定义成单例对象(singleton object)来代替,即定义类时,使用的object关键字,而非class关键字,但看上去就像定义class一样:
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte): Unit = {
sum += b
}
def checksum(): Int = {
return ~(sum & 0xFF) + 1
}
}
import scala.collection.mutable.Map
object ChecksumAccumulator {
private val cache = Map[String, Int]()
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
cs
}
}
当单例对象(object)与某个类(class)的名称相同时(上面都为ChecksumAccumulator),它就被称为是这个类的伴生对象。类和它的伴生对象必须定义在一个源文件里。类被称为这个单例对象的伴生类。类和它的伴生对象可以互相访问其私有成员
可以将单例对象当作Java中的静态方法工具类来使用,可以直接通过单例对象的名称来调用:
ChecksumAccumulator.calculate("Every value is an object.")
其实,单例对象就是一个对象,不需要实例化就可以直接通过单例对象名来访问其成员,即单例对象名就相当于变量名,已指向了某个类的实例,只不过该类不是由你来实例化,而是在访问它时由Scala实例化出来的,且在JVM只有一个这个的实例。在编译伴生对象时,会生成一个相应名为ChecksumAccumulator$(在单例对象名后加上美元符号)的类:

类和单例对象的差别:单例对象定义时不带参数(Object关键字后面),而类可以(Class关键字后面可以带括号将类参数包围起来),因为单例对象不是使用new关键字实例化出来的(这也是 Singleton 名字的由来)
单例对象在第一次被访问的时候才会被始化
没有伴生类的单例对象被称为独立对象,一般作为相关功能方法的工具类,或者用作Scala应用的入口程序
1.10 Scala入口程序
在Java中,只要类中有如下签名的main方法,即可作为程序入口程序:
class T {
public static void main(String[] args) {}
}
在Scala中,入口程序不是定义在类class中的,而是定义在单例对象中的,
object T {
def main(args: Array[String]): Unit = {}
}
与Java 类似,Scala 中任何 Singleton对象(使用Object关键字定义),如果包含 main 方法,都可以作为应用的入口
Scala的每个源文件都会自动引入包java.lang和scala包中的成员,和scala包中名为Predef的单例对象的成员,该单例对象中包含了许多有用的方法,例如,当在Scala源文件中写pringln的时候,实际调用了Predef.println,另外当你写assert,实质上是调用Predef.assert
Java的源文件扩展名为.java,而Scala的源文件扩展名为.scala
在Java中,如果源文件中有public的class,则该public类的类名必须与Java源文件名一致,但在Scala中没有这种限制,但一般会将源文件名与类名设为一致
与Java一样,也有对应的编译与运行命令,它们分别是scalac(编译)与scala(运行),ava中的为javac、java,不管是Java还是Scala程序,都会编译成.class的字节码文件
Scala 为 Singleton 对象的 main 定义了一个 App trait 类型
Scala的入口程序还可以继承scala.App特质(Trait,Scala中的Trait像Java中的Interface,但不同的是可以有方法的实现),这样就不用写main方法(因为scala.App特质里实现了main方法),而直接将代码写在花括号里,花括号里的代码会被收集进单例对象的主构造器中,并在类被初始化时执行:
object T extends scala.App {
println("T")
}
缺点:命令参数行args不能再被访问;某些JVM线程会要求main方法不能通过继承得到,必须自己行编写;
1.11 基本类型
Java 支持的基本数据类型,Scala 都有对应的支持,不过 Scala 的数据类型都是对象,而且这些基本类型都可以通过隐式自动转换的形式支持比 Java 基本数据类型更多的方法:比如调用 (-1).abs() ,Scala 发现基本类型 Int 没有提供 abs()方法,但可以发现系统提供了从 Int 类型转换为 RichInt 的隐式自动转换,而 RichInt 具有 abs 方法,那么 Scala 就自动将 1 转换为 RichInt 类型,然后调用 RichInt 的 abs 方法。
Scala 的基本数据类型有: Byte,Short,Int,Long 和 Char (这些成为整数类型)。整数类型加上 Float 和 Double 成为数值类型。此外还有 String 类型,除 String 类型在 java.lang 包中定义,其它的类型都定义在包 scala 中。比如 Int 的全名为 scala.Int。实际上 Scala 运行环境自动会载入包 scala 和 java.lang 中定义的数据类型,你可以使用直接使用 Int,Short,String 而无需再引入包或是使用全称(如scala.xx与java.lang.xx)。
Scala的基本类型与Java对应类型范围完全一样,这样可以让Scala编译器直接把这些类型编译成Java中的原始类型

scala> var hex=0xa //十六进制,整数默认就是Int类型
hex: Int = 10
scala> var hex:Short=0x00ff //若要Short类型,则要明确指定变量类型
hex: Short = 255
scala> var hex=0xaL //赋值时明确指定数据为Long型,否则默认为Int类型
hex: Long = 10
scala> val prog=2147483648L //若超过了Int范围,则后面一定要加上 L ,置换为Long类型
prog: Long = 2147483648
scala> val bt:Byte= 38 //若要Byte类型,则要在定义时明确指定变量的类型为Byte类型
bt: Byte = 38
scala> val big=1.23232 //小数默认就是Double类型
big: Double = 1.23232
scala> val big=1.23232f //如果要定义成Float,则可直接在小数后面加上F
big: Float = 1.23232
scala> val big=1.23232D //虽然默认就是Double,但也可在小数后面加上D
big: Double = 1.23232
scala> val a='A' //类型推导成Char类型
a: Char = A
scala> val f ='\u0041' //也可以使用Unicode编码表示,以 \u 开头,u一定要小写,且\u后面接4位十六进制
f: Char = A
scala> val hello="hello" //类型推导成String类型
hello: String = hello
scala> val longString=""" Welcome to Ultamix 3000. Type "Help" for help.""" //以使用三个引号(""")开头和结尾,这样之间的字符都将看作是最原始的字符,不会被转义
longString: String = " Welcome to Ultamix 3000. Type "Help" for help." //注:开头与结尾的双引号不属于上面字符串的一部分,而是表示控制台上输出的是String
scala> val bool=true
bool: Boolean = true
1.12 字面量
字面量就是直接写在代码里的常量值
1.12.1 整数字面量
十六进制以 0x或0X开头:
scala> val hex = 0x5
hex: Int = 5
scala> val hex2 = 0x00FF
hex2: Int = 255
scala> val magic = 0xcafebabe
magic: Int = -889275714
注:不区分大小写
八进制以0开头
scala> val oct = 035 // (八进制35是十进制29)
oct: Int = 29
scala> val nov = 0777
nov: Int = 511
scala> val dec = 0321
dec: Int = 209
如果是非0开头,即十进制:
scala> val dec2 = 255
dec2: Int = 255
注:不管字面量是几进制,输出时都会转换为十进制
如果整数以L或l结尾,就是Long类型,否则默认就是Int类型:
scala> val prog = 0XCAFEBABEL
prog: Long = 3405691582
scala> val tower = 35L
tower: Long = 35
scala> val of = 31l
of: Long = 31
从上面可以看出,定义Int型时可以省去类型即可,如果是Long类型,定义时也可省略Long类型,此时在数字后面加上L或l即可,但也可以直接定义成Long也可:
scala> var lg:Long = 2
lg: Long = 2
如果要得到Byte或Short类型的变量时,需在定义时指定变量的相应类型:
scala> val little: Short = 367
little: Short = 367
scala> val littler: Byte = 38
littler: Byte = 38
1.12.2 浮点数字面量
scala> val big = 1.2345
big: Double = 1.2345
scala> val bigger = 1.2345e1
bigger: Double = 12.345
scala> val biggerStill = 123E45
biggerStill: Double = 1.23E47
小数默认就是Double类型,如果要是Float,则要以F结尾:
scala> val little = 1.2345F
little: Float = 1.2345
scala> val littleBigger = 3e5f
littleBigger: Float = 300000.0
当然Double类型也可以D结尾,不过是可选的
scala> val anotherDouble = 3e5
anotherDouble: Double = 300000.0
scala> val yetAnother = 3e5D
yetAnother: Double = 300000.0
当然,也要以在定义变量时明确指定类型也可:
scala> var f2 = 1.0
f2: Double = 1.0
scala> var f2:Float = 1
f2: Float = 1.0
1.12.3 字符字面量
使用单引号引起的单个字符
scala> val a = 'A'
a: Char = A
单引号之间除了直接是字符外,也可以是对应编码,编码是八进制或十六进制来表示
如果以八进制表示,则以 \ 开头,且为 '\0 到 '\377' (0377=255):
scala> val c = '\101'
c: Char = A
注:如果以八进制表示,则只能表示一个字节大小的字符,即0~255之间的ASCII码单字节字符,如果要表示大于255的Unicode字符,则只能使用十六进制来表示:
scala> val d = '\u0041'
d: Char = A scala>
val f = '\u0044'
f: Char = D
scala> val c = '\u6c5f'
c: Char = 江
注:以十六进制表示时,需以 \u(小写)开头,即后面跟4位十六进制的编码(两个字节)
实际上,十六进制可以出现在Scala程序的任何地方,如可以用在变量名里:
scala> val B\u0041\u0044 = 1
BAD: Int = 1
转义字符:
scala> val backslash = '\\'
backslash: Char = \

1.12.4 字符串字面量
使用双引号引起来的0个或多个字符
scala> val hello = "hello"
hello: java.lang.String = hello
特殊字符也需转义:
scala> val escapes = "\\\"\'"
escapes: java.lang.String = \"'
如果字符串中需要转义的字符很多时,可以使用三个引号(""")开头和结尾,这样之间的字符都将看作是最原始的字符,不会被转义(当然三个连续的引号除外):
发现第二行前面的空格也会原样输出来,所以第二行前面看起来缩进了,如果要去掉每行前面的空白字符(ASCII编码小于等于32的都会去掉),则把管道符号(|)放在每行前面,然后对字符串调用stripMargin:

1.12.5 Symbol符号字面量
以单引号打头,后面跟一个或多个数字、字母或下划线,但第一个字符不能是数字,这种字面量会转换成预定义类scala.Symbol的实例,如 'cymbal编译器将会调用工厂方法Symbol("cymbal")转化成Symbol实例。
scala> val s = 'aSymbol
s: Symbol = 'aSymbol
scala> s.name
res20: String = aSymbol
符号字面量 'x 是表达式 scala.Symbol("x") 的简写
Java中String的intern()方法:String类内部维护一个字符串池(strings pool),当调用String的intern()方法时,如果字符串池中已经存在该字符串,则直接返回池中字符串引用,如果不存在,则将该字符串添加到池中,并返回该字符串对象的引用。执行过intern()方法的字符串,我们就说这个字符串被拘禁了(interned),即放入了池子。默认情况下,代码中的字符串字面量和字符串常量值都是被拘禁的,例如:
String s1 = "abc";
String s2 = new String("abc");
System.out.println(s1 == s2);//false
System.out.println(s1 == s2.intern());//true
同值字符串的intern()方法返回的引用都相同,例如:
String s2 = new String("abc");
String s3 = new String("abc");
System.out.println(s2 == s3);// false
System.out.println(s2.intern() == s3.intern());// true
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2);//true
String str3 = new String("abc");
System.out.println(str1 == str3);//false
Sysmbol实质上也是一种字符串,其好好处:
1. 节省内存
在Scala中,Symbol类型的对象是被拘禁的(interned,即会被放入池中),任意的同名symbols都指向同一个Symbol对象,避免了因冗余而造成的内存开销:
val s1 = "aSymbol"
val s2 = "aSymbol"
println(s1.eq(s2)) //true :表明s1与s2指向同一对象
val s3 = new String("aSymbol") //由于在编译时就确定,所以还是会放入常量池
println(s1.eq(s3)) //false : 表明s1与s3不是同一对象
println(s1 == s3) //true:虽然不是同一对象,但是它们的内容相同
val s = 'aSymbol
println(s.eq('aSymbol)) //true
println(s.eq(Symbol("aSymbol"))) //true:只要是同名的Symbol,则都是指向同一对象
//即使s与s3的内容相同,但eq比较的是对象地址,所以不等
println(s.name.eq(s3)) //false
println(s.name == s3) //true:但内容相同
println(s.name.eq(s1)) //true : s与s1的的内容都会放入池中,所以指向的是同一对象
注:在Scala中,如果要基于引用地址进行比较,则要使用eq方法,而不是==,这与Java是不一样的
2. 快速比较
由于Symbol类型的对象会自动拘禁的(interned),任意的同名symbols(准确的说是值)都指向同一个Symbol对象,而相同值的字符串并不一定是同一个instance,所以symbols对象之间的比较操作符==速度会很快:因为它只基于地址进行比较,如果发现不是同一Symbols对象,则就认为不相同,不会在对内容进行比较(因为不同名的Symbols的值肯定也不相同)
Symbol类型的应用
Symbol类型一般用于快速比较,例如用于Map类型:Map<Symbol, Data>,根据一个Symbol对象,可以快速查询相应的Data, 而Map<String, Data>的查询效率则低很多。
虽说利用String的intern方法也可以实现Map<String, Data>的键值快速比较,但是由于需要显式地调用intern()方法,在编码时会造成很多的麻烦,而且如果忘了调用intern()方法,还会造成难以寻找的bug。从这个角度看,Scala的Symbol类型会自动进行intern操作(加入到池中),所以简化了编码的复杂度;而Java中除了字符串常量,是不会自动进行intern的,需要对相应对象手动调用interned方法
1.12.6 布尔字面量
scala> val bool = true
bool: Boolean = true
scala> val fool = false
fool: Boolean = false
1.13 操作符和方法
操作符如+加号,实质上是类型中有名为 + 的方法:
scala> val sum = 1 + 2 // Scala调用了(1).+(2)
sum: Int = 3
scala> val sumMore = (1).+(2)
sumMore: Int = 3
实际上Int类型包含了名为 + 的各种不同参数的重载方法,如Int+Long:
scala> val longSum = 1 + 2L // Scala调用了(1).+(2L)
longSum: Long = 3
既然+是名为加号的方法,可以以 1+2 这种操作模式来调用,那么其他方法也是可以如下方式来调用:
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s indexOf 'o' // 调用了s.indexOf(’o’)
res0: Int = 4
如果有多个参数,则要使用括号:
scala> s indexOf ('o', 5) // Scala调用了s.indexOf(’o’, 5)
res1: Int = 8
在 Scala 中任何方法都可以是操作符:Scala里的操作符不是特殊的语法,任何方法都可以是操作符,到底是方法还是操作符取决于你如何使用它。如果写成s.indexOf('o'),indexOf就不是操作符。不过如果写成,s indexOf 'o',那么indexOf就是操作符了
上面看到的是中缀操作符,还是前缀操作符,如 -7里的“-”,后缀操作符如 7 toLong里的“toLong”( 实为 7.toLong )。
前缀操作符与后缀操作都只有一个操作数,是一元(unary)操作符,如-2.0、!found、~0xFF,这些操作符对应的方法是在操作符前加上前缀“unary_”:
scala> -2.0 // Scala调用了(2.0).unary_-
res2: Double = -2.0
scala> (2.0).unary_-
res3: Double = -2.0
可以当作前缀操作符用的标识符只有+、-、!和~。因此,如果你定义了名为unary_!的方法,就可以对值或变量用 !P 这样的前缀操作符方式调用方法。但是如果你定义了名为unary_*的方法,就没办法将其用成前缀操作符了,因为*不是四种可以当作前缀操作符用的标识符之一。
后缀操作符是不用点与括号调用的不带任何参数的方法:
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s.toLowerCase()
res4: java.lang.String = hello, world!
由于不带参数,则可能省略括号
scala> s.toLowerCase
res5: java.lang.String = hello, world!
还可以省去点:
scala> import scala.language.postfixOps//需要导一下这个来激活后缀操作符使用方式,否则会警告
import scala.language.postfixOps
scala> s toLowerCase
res6: java.lang.String = hello, world!
1.14 数学运算
scala> 1.2 + 2.3
res6: Double = 3.5
scala> 3 - 1
res7: Int = 2
scala> 'b' - 'a'
res8: Int = 1
scala> 2L * 3L
res9: Long = 6
scala> 11 / 4
res10: Int = 2
scala> 11 % 4
res11: Int = 3
scala> 11.0f / 4.0f
res12: Float = 2.75
scala> 11.0 % 4.0
res13: Double = 3.0
数字类型还提供了一元的前缀 + 和 - 操作符(方法 unary_+ 和 unary_-)
scala> val neg = 1 + -3
neg: Int = -2
scala> val y = +3
y: Int = 3
scala> -neg
res15: Int = 2
1.15 关系和逻辑操作
scala> 1 > 2
res16: Boolean = false
scala> 1 < 2
res17: Boolean = true
scala> 1.0 <= 1.0
res18: Boolean = true
scala> 3.5f >= 3.6f
res19: Boolean = false
scala> 'a' >= 'A'
res20: Boolean = true
可以使用一元操作符!(unary_!方法)改变Boolean值:
scala> val thisIsBoring = !true
thisIsBoring: Boolean = false
scala> !thisIsBoring
res21: Boolean = true
逻辑与(&&)和逻辑或(||):
scala> val toBe = true
toBe: Boolean = true
scala> val question = toBe || !toBe
question: Boolean = true
scala> val paradox = toBe && !toBe
paradox: Boolean = false
与Java里一样,逻辑与和逻辑或有短路:
scala> def salt() = { println("salt"); false }
salt: ()Boolean
scala> def pepper() = { println("pepper"); true }
pepper: ()Boolean
scala> pepper() && salt()
pepper
salt
res22: Boolean = false
scala> salt() && pepper()
salt
res23: Boolean = false
scala> pepper() || salt()
pepper
res24: Boolean = true
scala> salt() || pepper()
salt
pepper
res25: Boolean = true
1.16 位操作符
按位与运算(&):都为1时才为1,否则为0
按位或运算(|):只要有一个为1 就为1,否则为0
按位异或运算(^):相同位产生0,不同产生1,因此0011 ^ 0101产生0110。
scala> 1 & 2 // 0001 & 0010 = 0000 = 0
res24: Int = 0
scala> 1 | 2 // 0001 | 0010 = 0011 = 3
res25: Int = 3
scala> 1 ˆ 3 // 0001 ^ 0011 = 0010 = 2
res26: Int = 2
scala> ~1 // ~0001 = 1110(负数原码:从最末一位向前除符号位各位取反即可) = 1010 = -2
res27: Int = -2
负数补码:反码+1
左移(<<),右移(>>)和无符号右移(>>>)。左移和无符号右移在移动的时候填入零。右移则在移动时填入左侧整数的最高位(符号位)。
scala> -1 >> 31 //1111 1111 1111 1111 1111 1111 1111 1111 向右移动后,还是 1111 1111 1111 1111 1111 1111 1111 1111,左侧用符号位1填充
res38: Int = -1
scala> -1 >>> 31 //1111 1111 1111 1111 1111 1111 1111 1111 向右无符号移动后,为0000 0000 0000 0000 0000 0000 0000 0001,左侧用0填充
es39: Int = 1
scala> 1 << 2 //0000 0000 0000 0000 0000 0000 0000 0001 向左位移后,为0000 0000 0000 0000 0000 0000 0000 0100,右侧用0填充
res40: Int = 4
1.17 对象相等性
基本类型比较:
scala> 1 == 2
res31: Boolean = false
scala> 1 != 2
res32: Boolean = true
scala> 2 == 2
res33: Boolean = true
这些操作对所有对象都起作用,而不仅仅是基本类型,如列表的比较:
scala> List(1, 2, 3) == List(1, 2, 3)
res34: Boolean = true
scala> List(1, 2, 3) == List(1, 3, 2)
res35: Boolean = false
还可以对不同类型进行比较,如:
scala> 1 == 1.0
res36: Boolean = true
scala> List(1, 2, 3) == "hello"
res37: Boolean = false
甚至可以与null进行比较:
scala> List(1, 2, 3) == null
res38: Boolean = false
== 操作符在比较之前,会先判断左侧的操作符是否为null,不为null时再调用左操作数的equals方法进行比较,比较的结果主要是看这个左操作数的equals方法是怎么实现的。只要比较的两者内容相同且并且equals方法是基于内容编写的,不同对象之间比较也可能为true。x == that判断表达式判断的过程实质如下:
if (x.eq(null))
that eq null
else
x.equals(that)
equals方法是检查值是否相等,而eq方法检查的是引用是否相等。所以如果使用 == 操作符比较两个对象时,如果左操作数是null,那么调用eq判断右操作数也是否为null;如果左操作数不是null的情况则调用equals基于对象内容进行比较
!= 就是 == 计算结果取反
Java中的==即可以比较原始类型,也可以比较引用类型。对于原始类型,Java的==比较值的相等性,与Scala一致,而对于引用类型,Java的==是比较这两个引用是否都指向了同一个对象,不过Scala比较对象地址不是 == 而是使用eq方法,所以Scala中的 == 操作符作用于对象时,会转换调用equals方法来比较对象的内容(在左操作数非null情况下)
AnyRef的equals方法默认调用eq方法实现,也就是说,默认情况下,判断两个变量相等,要求必须指向同一个对象实例
注:在Scala中,如果要基于引用地址进行比较,则要使用eq方法,而不是==,这与Java是不一样的
1.18 操作符优先级
Scala中没有操作符,操作符只是方法的一种表达方式,其优先级是根据作用符的第一个字符来判断的(也有例外,请看后面以等号 = 字符结束的一些操作符),如规定第一个字符*就比+的优先级高。以操作符的第一个字符为依据,优先级如下:
(所有其他的特殊字符)
* / %
+ -
:
= !
< >
&
^
|
(所有字母)
(所有赋值操作)
上面同一行的字符具有同样的优先级
scala> 2 << 2 + 2 // 2
<< (2 + 2)
res41: Int = 32
<<操作符第一个字符为<,根据上表 << 要比 + 优先级低
如果操作符以等号字符( =)结束 , 且操作符并非比较操作符<=, >=, ==,或=,那么这个操作符的优先级与赋值符( =)相同。也就是说,它比任何其他操作符的优先级都低。例如:
x *= y + 1
与下面的相同:
x *= (y + 1)
操作符 *= 以 = 结束,被当作赋值操作符,它的优先级低于+,尽管操作符的第一个字符是*看起来高于+。
任何以“:”字符结尾的方法由它的右操作数调用,并传入左操作数;其他结尾的方法与之相反,它们被左操作数调用,并传入右操作:a * b 变成 a.*(b), a:::b 变成 b.:::(a)。
多个同优先级操作符出现时,如果方法以:结尾,它们就被从右往左进行分组;反之,就从左往右进行分组,如:a ::: b ::: c 会被当作 a :::
(b ::: c),而 a * b * c 被当作(a * b) * c
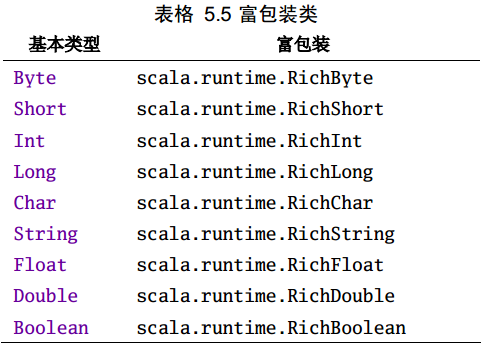
1.19 基本类型富包装类型
基本类型除了一些常见的算术操作外,还有一些更为丰富的操作,这些操作可以直接使用,更多需要参考API中对应的富包装类:


上述相应的富操作都是由下面相应的富包装类提供的,使用前会先自动进行隐式转换:
1.20 Scala标识符
变量(本地变量、方法参数、成员字段)、或方法的定义名都是标识符。
标识符由字母、数字、操作符组成
Scala中有4种标识符:
字母数字标识符:以字母或下划线开始,后面可以跟字母、数字或下划线。注:$ 字符本身也是当作字母的,但被Scala编译器保留作为特殊标识符使用,所以用户定义的标识符中最好不要包含 $ 字符,尽管能够编译通过。另外,虽然下划线可以用来做为标识符,但同样也有很多其他非标识符用法,所以也最好避免在标识符中含有下划线
Java中常量习惯全大写,且单词之间使用下划线连接,但Scala里习惯第一个字母必须大写,其他还是驼峰形式
操作符标识符:由一个或多个操作符组成,操作符是一些如 +、:、?、~ 或 # 的可打印ASCII字符(精确的说,应该是除字母、数字、括号、方括号、花括号、单引号、双引号、下划线、句号、分号、冒号、回退字符\b),以下是一些操作符标识符:
+、++、:::、<?>、:->
Scala编译器内部会将操作符标识符转换成含有 $ 字符的Java标识符,如操作符标识符 :-> 将被编译器转换成相应Java标识符 $colon$minus$greater (colon:冒号,minus:负号,greater:大于),如果要从Java代码访问这个标识符,则应该使用这个转换后的标识符,而不是原始的
在Java里 x<-y 会被拆分成4个词汇符号,所以与 x < - y 一样,但在Scala里,<- 将被作为一个标识符,所以会被拆分成3个词汇,从而得到 x <- y,如果想要拆分成 < 与 – 的话,需要在 < 与 – 之间加上一个空格
混合标识符:由字母、数字组成,后面跟下划线和一个操作符标识符,如 unary_+ 被用做定义一元操作符 + 的方法名,myvar_= 被用做定义赋值操作符 = 的方法名(myvar_=是由编译器用来支持属性property的)
字面量标识符:是用反引 `...` 包括的任意字符串,如 `x` `<clinit>` `yield`,因为yield在Scala中是保留字,所以在Scala中不能直接调用java.lang.Thread.yield()(使当前线程从运行状态变为就绪状态),而是这样调用java.lang.Thread.`yield`()
2 示例:分数(有理数)运算
有理数是一个整数a和一个非零整数b的比,例如3/8,通则为a/b,又称作分数。
0也是有理数。有理数是整数和分数的集合,整数也可看做是分母为1的分数。
有理数的小数部分是有限或为无限循环的数。无理数的小数部分是无限不循环的数。
与浮点数相比较,有理数的优势是小数部分得到了完全表达,没有舍入或估算
下面设计分数这样的类:
class Rational(n: Int, d: Int) // 分子:n、分母:d
如果类没有主体,则可以省略掉花括号。括号里的n、d为类参数,并且编译器会创建带这两个参数的主构造器(有主就有从)
Scala编译器将把类的内部任何即不是字段也不是方法的定义代码编译到主构造器中,如:
class Rational(n: Int, d: Int) {
println("Created " + n + "/" + d)
}
scala> new Rational(1, 2)
Created 1/2
res0: Rational = Rational@90110a
Rational 类继承了定义在 java.lang.Object 类上的 toString方法,所以打印输出了“Rational@90110a”。重写toString方法:
class Rational(n: Int, d: Int) {
override def toString = n + "/" + d // 重写时override关键字不能省略,这与Java不一样
}
scala> val x = new Rational(1, 3)
x: Rational = 1/3
构造时,分母非0检查:
class Rational(n: Int, d: Int) {
require(d != 0) //此句会放入主构造器中
override def toString = n + "/" + d
}
require方法为scala包中Predef对象中定义的方法,编译器会自动引入到源文件中,所以可直接使用不需导入。传入的如果是false时,会抛java.lang.IllegalArgumentException异常,对象构造失败
实现add方法:
class Rational(n: Int, d: Int) {
require(d != 0)
override def toString = n + "/" + d
def add(that: Rational): Rational =
new Rational(n * that.d + d * that.n, d * that.d)
}
由于n、d只是类参数,在整个类范围内是可见(但因为只是类的参数,作用域比较广而已——相当于方法的参数来说,编译器是不会为这些类的参数自动创建出相应的成员字段的),但只能被调用它的对象访问,其他对象不能访问。代码中的that对象并不是调用add方法的对象,所以编译时出错:
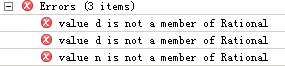
所以需要将n、d转存到字段成员中才可访问:
class Rational(n: Int, d: Int) {
require(d != 0)
private val numer: Int = n //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d
override def toString = n + "/" + d
// 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def add(that: Rational): Rational =
new Rational(n * that.denom + d * that.numer, d * that.denom)
}
scala> val oneHalf = new Rational(1, 2)
oneHalf: Rational = 1/2
scala> val twoThirds = new Rational(2, 3)
twoThirds: Rational = 2/3
scala> oneHalf add twoThirds
res0: Rational = 7/6
比大小:
def lessThan(that: Rational) = numer * that.denom < that.numer * denom
返回较大的:
def max(that: Rational) = if (lessThan(that)) that else this //Scala 也使用 this 来引用当前对象本身
在定义类时,很多时候需要定义多个构造函数,在 Scala 中,除主构造函数之外的构造函数都称为辅助构造函数(或是从构造函数),Scala 定义辅助构造函数使用 this(…)的语法,所有辅助构造函数名称为 this。如当分母为1时,只需传入分子,分母固定为1,下面增加一个这样的从构造器:
def this(n: Int) = this(n, 1)
Scala 的从构造器以 def this(...) 定义形式开头。每个从构造器的第一个语句都是调用同类里的其他构造器,但最终都会以调用主构造器而结束(注:在类里面调用自身主构造器也是使用this(...)形式来调用的),这样使得每个构造函数最终都会调用主构造函数,因此主构造器是类的唯一入口点。在 Scala 中也只有主构造函数才能(会)去调用基类的构造函数
而在Java中,构造器的第一个语句只有两个选择:要么调用同类的其他构造器,要么直接调用父类的构造器,如果省略,则默认为super(),即默认会调用父类的无参默认构造器
加入分数最简形式,形如66/42可以简化为11/7,分子分母同时除以最大公约数6:
class Rational(n: Int, d: Int) {
//此句会放入主构造器中
require(d != 0)
//分子与分母的最大公约数。Scala也会根据成员变量出现的顺序依次初始化它们,所以一般在使用前定义并初始化它,虽然在Scala中可以将g定义在numer、denom后面,但这样易出错,这与Java不太一样
private val g = gcd(n.abs, d.abs)
private val numer: Int = n / g //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d / g
//从构造器
def this(n: Int) = this(n, 1)//调用主构造器
override def toString = numer + "/" + denom
// 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def add(that: Rational): Rational =
new Rational(numer * that.denom + denom * that.numer, denom * that.denom)
//求两个数的最大公约数
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
}
object T {
def main(args: Array[String]): Unit = {
println(new Rational(66, 42)) //11/7
val oneHalf = new Rational(1, 2)
val twoThirds = new Rational(2, 3)
println(oneHalf add twoThirds) //7/6
}
}
定义操作符:到目前为止,已实现了分数相加的方法add,但不能像Scala库里面数字类型那样使用 + 操作符来完成两个分数的相加,其实将add方法名改为 + 即可:
class Rational(n: Int, d: Int) {
//此句会放入主构造器中
require(d != 0)
//分子与分母的最大公约数
private val g = gcd(n.abs, d.abs)
private val numer: Int = n / g //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d / g
//从构造器
def this(n: Int) = this(n, 1)
override def toString = numer + "/" + denom
// 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def +(that: Rational): Rational =
new Rational(numer * that.denom + denom * that.numer, denom * that.denom)
//实现乘法
def *(that: Rational): Rational =
new Rational(numer * that.numer, denom * that.denom)
//求两个数的最大公约数
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
}
object T {
def main(args: Array[String]): Unit = {
val x = new Rational(1, 2)
val y = new Rational(2, 3)
println(x + x * y) //5/6
println((x + x) * y) //2/3
}
}
上面只是针对分数Rational进行加、乘运行,不能与Int进行运算,下面对这些方法进行重载,并加上减、除运算:
class Rational(n: Int, d: Int) {
//此句会放入主构造器中
require(d != 0)
//分子与分母的最大公约数
private val g = gcd(n.abs, d.abs)
private val numer: Int = n / g //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d / g
//从构造器
def this(n: Int) = this(n, 1)
override def toString = numer + "/" + denom
//加: 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def +(that: Rational): Rational =
new Rational(numer * that.denom + denom * that.numer, denom * that.denom)
def +(i: Int): Rational = new Rational(numer + i * denom, denom)//方法重载
//减: 1/2 - 2/3 = (1*3)/(2 *3) - (2*2)/(3*2)
def -(that: Rational): Rational = new Rational(numer * that.denom - that.numer * denom, denom * that.denom)
def -(i: Int): Rational = new Rational(numer - i * denom, denom) //方法重载
//乘:1/2 * 2/3 =(1*2)/(2*3)
def *(that: Rational): Rational =
new Rational(numer * that.numer, denom * that.denom)
def *(i: Int): Rational = new Rational(numer * i, denom) //方法重载
//除:1/2 / 2/3 =(1*3)/(2*2)
def /(that: Rational): Rational = new Rational(numer * that.denom, denom * that.numer)
def /(i: Int): Rational = new Rational(numer, denom * i) //方法重载
//求两个数的最大公约数
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
}
object T {
def main(args: Array[String]): Unit = {
println(new Rational(2, 3) * 2)// 4/3
}
}
上面只能使用 new Rational(2, 3) * 2 ,而不能倒过来 2 * new Rational(2, 3),因为Int类就没有针对 Rational类型进行运算的方法,Rational不是Scala的标准类型,如果想使用2 * new Rational(2, 3) 这种形式,则需要在使用前进行隐式转换,则Int类型转换为Rational类型:
//需要在使用之前定义从Int到Rational的隐式转换方法
implicit def int2Rational(x: Int) = new Rational(x)
println(2 * new Rational(2, 3)) // 4/3
增加这个隐式置换后,其实此时 Rational 的一些Int重载方法是多余的,因为第一个整型操作符已转换为Rational类型,且第二个操作符也是Rational类型,所以Int类型的重载方法就多余了
3 内置控制结构
和其它语言(比如 Java,C#)相比,Scala 只内置了为数不多的几种程序控制语句: if,while,for ,try,match 以及函数调用,Scala 没有内置很多控制结构,这是因为 Scala 赋予了程序员自己通过函数来扩展控制结构的能力
Scala的控制结构特点都是有返回值的,如果没有这种特点,程序员常常需要创建一个临时变量用来保存结果
3.1 If表达式
Java传统方式:
var filename = "default.txt"
if (!args.isEmpty)
filename = args(0)
Scala中写法:
val filename = if (!args.isEmpty) args(0) else "default.txt"
这段代码使用 val 而无需使用 var 类型的变量。使用 val 为函数式编程风格
3.2 While循环
//计算最大公约数:(6,9)= 3
def gcdLoop(x: Long, y: Long): Long = {
var a = x
var b = y
while (a != 0) {
val temp = a
a = b % a
b = temp
}
b
}
//从控制台循环读取输入行
var line = ""
do {
line = readLine()
println("Read: " + line)
} while (line != "")
while和do-while结构之所以称为“循环”,而不是表达式,是因为它们不能产生有意义的结果,循环结果返回结果的类型是Unit,写做()。()的存在是Scala的Unit不同于Java的void的地方:
//返回值为空
def greet() { println("hi") }
def main(args: Array[String]): Unit = {
println(greet() == ())//hi true
}
另外,在Java等编程语言中,赋值语句本身会返回被赋予的那值:
String line = "";
System.out.println(line = "hello");// hello
但在Scala中,赋值语句本身不会再返回被赋予的那值,而是Unit:
var line = ""
println(line = "ho") // ()
所以下面从控制台读取将永远不能结束:
var line = ""
while ((line = readLine()) != "") // 不起作用,因为赋值语句固定返回为Unit()
println("Read: " + line)
由于while循环不产生值,因此在纯函数式语言中不推荐使用,它适合于传统指令式编程,而使用递归的函数式风格可以替代while。下面使用这种递归的函数式风格来代替上面使用while指令式风格求最大公约数:
//计算最大公约数,使用递归函数实现
def gcd(x: Long, y: Long): Long =
if (y == 0) x else gcd(y, x % y)
3.3 For表达式
3.3.1 集合枚举
枚举当前目录下所有文件,Java传统做法:
File[] filesHere = new java.io.File(".").listFiles();
for (int i = 0; i < filesHere.length; i++) {
System.out.println(filesHere[i]);
}
Scala枚举当前目录下的所有文件(包括目录):
val filesHere = new java.io.File(".").listFiles
![]()
for (file <- filesHere)
println(file)
<–为提取符,提取集合中的元素
Java1.5以后也有类似的语法:
File[] filesHere = new java.io.File(".").listFiles();
for (File file : filesHere) {
System.out.println(file);
}
Scala 的 for 表达式支持所有类型的集合类型,而不仅仅是数组,比如下面使用 for 表达式来枚举一个 Range 类型:
for (i <- 1 to 4)
println("Iteration " + i)

for (i <- 1 until 4)//不包括边界4
println("Iteration " + i)
val filesHere = new java.io.File(".").listFiles
//也可按传统方式通过索引遍历数组元数,但不推荐这样使用
for (i <- 0 to filesHere.length - 1)
println(filesHere(i))
3.3.2 If守卫
在for语句中添加if过滤器:
val filesHere = (new java.io.File(".")).listFiles
//只打印出后缀名为 .project 的文件
for (file <- filesHere if file.getName.endsWith(".project"))
println(file)
也可以将if语句拿出来写在循环体中,但不推荐:
for (file <- filesHere)
if (file.getName.endsWith(".project"))
println(file)
可以添加多个过滤器:
for (file <- filesHere if file.isFile if file.getName.endsWith(".project"))
println(file)
3.3.3 嵌套枚举
for语句中可以使用多个 <- 提取符形成嵌套循环。
下面外层循环是针对扩展名为.classpath的文件进行循环,然后读取每个文件中含有con字符的文本行:
val filesHere = (new java.io.File(".")).listFiles
def fileLines(file: java.io.File) =
scala.io.Source.fromFile(file).getLines.toList
def grep(pattern: String) =
for (
file <- filesHere if file.getName.endsWith(".classpath"); //循环文件
line <- fileLines(file) if line.trim.matches(pattern) //循环文本行
) println(file + ": " + line.trim)
grep(".*con.*")
注:嵌套之间要使用分号分隔,不过可以使用花括号来代替小括号,此时嵌套之间的分号就可以省略了:
def grep(pattern: String) =
for {
file <- filesHere if file.getName.endsWith(".classpath")
line <- fileLines(file) if line.trim.matches(pattern)
} println(file + ": " + line.trim)
3.3.4 变量中间绑定
如果某个方法多次用,可以将其先赋给某个val变量,这样只需计算一次,如上面两处调用line.trim:
def grep(pattern: String) =
for {
file <- filesHere if file.getName.endsWith(".classpath")
line <- fileLines(file)
trimmed = line.trim //结果临时保存在 trimmed 变量,可以定义val中间变量,val关键字可以省略
if trimmed.matches(pattern)
} println(file + ": " + trimmed)
3.3.5 yield生成新的集合
for clauses yield body
关键字 yield 放在 body(这里的body指单条语句)的前面,for 每迭代一次,产生一个 body,yield 收集所有的 body 结果,返回一个 body 类型的集合(一般情况下,当返回的元素类型与源集合中的元素类型相同时,则返回的集合类型与源集合类型相同;如果返回的元素类型与源集合元素类型不同时,则两集合类型则可能不同,请看下面代码)。如列出所有名为 .scala 结尾的文件,返回这些文件的集合(scalaFiles: Array[java.io.File]):
val filesHere = (new java.io.File(".")).listFiles // filesHere: Array[java.io.File]
def scalaFiles = for {file <- filesHere if file.getName.endsWith(".scala")} yield file //
scalaFiles: Array[java.io.File]
yield与for一样是关键字,它应该放在循环体最前面,如果循环体有多个语句时,可以使用花括号包起来,yield放在花括号外:
for {子句} yield {循环体}
scala> val arr = Array("a", "b")
arr: Array[String] = Array(a, b)
scala> val arr2 = for (e <- arr) yield e.length
arr2: Array[Int] = Array(1, 1) // 注:返回的类型还是Array,但里面元素的类型变了
scala> val map = Map(1 -> "a", 2 -> "b")
map: scala.collection.immutable.Map[Int,String] = Map(1 -> a, 2 -> b)
scala> val map2 = for ((k, v) <- map) yield v.length
map2: scala.collection.immutable.Iterable[Int] = List(1, 1) // 注:这里返回的是List类型,不是Array,也不是Map,因为Map变长,所以返回的List
scala> val map3 = for ((k, v) <- map) yield (k, v)
map3: scala.collection.immutable.Map[Int,String] = Map(1 -> a, 2 -> b)
3.4 try
val half =
if (n % 2 == 0) n / 2
else
throw new RuntimeException("n must be even")
尽管throw不实际产生任何值,你还是可以把它当作表达式,throw语句返回的类型为Nothing:
scala> def t = throw new RuntimeException("n must be even")
t: Nothing
if 的一个分支计算值,另一个抛出异常并得出 Nothing,整个 if 表达式的类型就是那个实际计算值的分支的类型,所以上面的half类型为Int,因为Nothing是任何类型的子类型,所以整个if表达式的类型为父类型Int
import java.io.FileReader
import java.io.FileNotFoundException
import java.io.IOException
var f: FileReader = null
try {
f = new FileReader("input.txt")
// Use and close file
} catch {//如果打开文件出现异常,将先检查是否是 FileNotFoundException 异常,如果不是,再检查是否是 IOException,如果还不是,在终止 try-catch 块的运行,而向上传递这个异常
case ex: FileNotFoundException =>
// 文件不存在捕获后在此处理异常
// ...
case ex: IOException =>
// 其它 I/O 错误捕获后在此处理异常
// ...
} finally { // 与Java一样,不管 try 块是否抛出异常,finally块都会执行
f.close() // 文件一定会被关闭
}
注:与 Java 异常处理不同的一点是,Scala 不需要你捕获 checked 的异常,所以下面语句虽然要抛出检测异常FileNotFoundException,但不需要使用try-catch 块来包围,这在Java中是不行的:
var f = new FileReader("input.txt")
和其它大多数Scala控制结构一样,try-catch-finally也产生值(Scala的行为与Java的差别仅源于Java的try-finally不产生值),比如下面的例子尝试分析一个 URL,如果输入的 URL 无效,则使用缺省的 URL 链接地址:
import java.net.URL
import java.net.MalformedURLException
def urlFor(path: String) =
try {
new URL(path)
} catch {
case e: MalformedURLException =>
new URL("http://www.scalalang.org")//缺省的 URL
}
如果抛异常但未捕获异常,则表达式没有值。
finally子句当使用return显示的返回时,这个值将覆盖 try-catch 产生的结果:
def f(): Int = try { return 1 } finally { return 2 }
println(f()) //2 结果会被返回
否则即使finally块最后一句有值,也会被抛弃:
def g(): Int = try { 1 } finally { 2 }
println(g()) //1 结果会被抛弃
正是因为这样容易弄混,所以finally子句不要返回值,而只作如关闭资源、清理之类的工作
3.5 match
类似Java中的switch,从多个选择中选取其一。match 表达式支持任意的匹配模式
val firstArg = if (args.length > 0) args(0) else ""
firstArg match {
case "salt" => println("pepper")
case "chips" => println("salsa")
case "eggs" => println("bacon")
case _ => println("huh?")
}
_下划线表示其它,类似Java中的default
不像Java那样,firstArg可以是任何类型,而不只是整型或枚举,示例中是字符串。另外,每个可选项最后并没有break,隐含就有
match表达式还可以产生值:
val firstArg = if (!args.isEmpty) args(0) else ""
val friend =
firstArg match {
case "salt" => "pepper"
case "chips" => "salsa"
case "eggs" => "bacon"
case _ => "huh?"
}
println(friend)
3.6 break、continue
Scala 内置控制结构特地去掉了 break 和 continue
如从一组字符串中寻找以“ .scala ”结尾的字符串,但跳过以“-”开头的字符串,Java中可以这样实现:
int i = 0;
boolean foundIt = false;
while (i < args.length) {
if (args[i].startsWith("-")) {
i = i + 1;
continue;
}
if (args[i].endsWith(".scala")) {
foundIt = true;
break;
}
i = i + 1;
}
完成可以这样,通过调代码结构可以去掉它们:
var i = 0
var foundIt = false
while (i < args.length && !foundIt) {
if (!args(i).startsWith("-")) {
if (args(i).endsWith(".scala"))
foundIt = true
}
i = i + 1
}
另外,在Scala中完使用可以递归函数来代替循环,下面使用递归实现上面同样功能:
def searchFrom(i: Int): Int =
if (i >= args.length) -1
else if (args(i).startsWith("-")) searchFrom(i + 1)
else if (args(i).endsWith(".scala")) i
else searchFrom(i + 1)
val i = searchFrom(0)
在函数化编程中使用递归函数来实现循环是非常常见的一种方法,我们应用熟悉使用递归函数的用法
如果你实在还是希望使用 break,Scala 在 scala.util.control 包中定义了 break 控制结构,它的实现是通过抛出异常给上级调用函数。下面给出使用 break 的一个例子,不停的从屏幕读取一个非空行,如果用户输入一个空行,则退出循环:
import scala.util.control.Breaks._
import java.io._
val in = new BufferedReader(new InputStreamReader(System.in))
breakable {//breakable是带了一个传名参数的方法
while (true) {
println("? ")
if (in.readLine() == "") break //break也是一个方法,会抛异常BreakControl
}
}
3.7 变量作用域
Scala允许你在嵌套范围内定义同名变量
大括号通常引入了一个新的范围,所以任何定义在花括号里的东西在括号之后就脱离了范围(但有个例外,因为嵌套for语句可以使用花括号来代替小括号,所以此种除外,可参见这里的中间变量trimmed):
def printMultiTable() {
var i = 1
// 这里只有i在范围内
while (i <= 10) {
var j = 1
// 这里i和j在范围内
while (j <= 10) {
val prod = (i * j).toString
// 这里i,j和prod在范围内
var k = prod.length
// 这里i,j,prod和k在范围内
while (k < 4) {
print(" ")
k += 1
}
print(prod)
j += 1
}
// i和j仍在范围内;prod和k脱离范围
println()
i += 1
}
// i仍在范围内;j,prod和k脱离范围
}
然而,你可以在一个内部范围内定义与外部范围里名称相同的变量:
val a = 1; //在这里要加上分号,因为此处不能推导
{
val a = 2
println(a) //2
}
println(a) //1
与Scala不同,Java不允许你在内部范围内创建与外部范围变量同名的变量。在Scala程序里,内部变量隐藏掉同名的外部变量,因此在内部范围内外部变量变得不可见
4 Scala方法和函数的区别
使用val(或var)语句可以定义函数,def语句定义方法:
class T{
def m(x: Int) = x + 3 //定义方法,m将是类T的成员方法
val f = (x: Int) => x + 3 //定义函数, f将是类T的成员字段
}
函数类型形如(T1, ..., Tn) => T(注意与传名参数类型区别:p: => T,p是参数名,当冒号后面无参,将无参空括号去掉就是传名参数了;如果参数定义成p:() => T,则是参数是函数类型,而非传名参数了),函数都实现了FuctionN(N[0..22])特质trait的对象,所以函数具有一些方法如equals、toString等,而方法不具有这些特性:
def m(x: Int) = x + 3
var f = (x: Int) => x + 3
// m.toString //编译失败
f.toString //编译通过
如果想把方法转换成一个函数,可以用方法名跟上下划线的方式:
def m(x: Int) = x + 3
(m _).toString//编译通过
通常在使用一个函数时是将赋值给函数变量或者是通过函数类型的参数传递给方法,函数的调用跟方法一样,也是在函数对象(值)后面接小括号进行函数的调用,在Java是不是允许在对象后面接小括号的(只能在方法名后面接小括号),这正因为apply是scala中的语法糖:可以在一个对象obj后面带上括号与参数(也可无参数),如obj(x,y),scala编译器会将obj(x,y)转换为obj.apply(x,y)方法的调用;而在一个类clazz上调用clazz(),scala编译器会转换为“类的伴生对象.apply()”(一般是工厂方法):
![]()
函数的调用必须通过后面接上括号,否则表示函数对象本身;而方法的调用可以就是方法名,而不需要接空括号
有两种方法可以将方法转换成函数:
val f1 = m _
在方法名称m后面紧跟一个空格和下划线告诉编译器将方法m转换成函数。也可以显示地告诉编译器需要将方法转换成函数:
val f1: (Int) => Int = m
通常情况下编译器会自动将方法转换成函数,例如在一个应该传入函数参数(即参数类型为函数)的地方传入了一个方法,编译器会自动将传入的方法转换成函数
将方法转换为函数的时候,如果方法有重载的情况,必须指定参数和返回值的类型:
scala> object Tool{
| def increment(n: Int): Int = n + 1
| def increment(n: Int, step: Int): Int = n + step
| }
scala> val fun = Tool.increment _
<console>:12: error: ambiguous reference to overloaded definition,
scala> val fun1 = Tool.increment _ : (Int => Int)
fun1: Int => Int = <function1>
scala> val fun2 = Tool.increment _ : ((Int, Int) => Int)
fun2: (Int, Int) => Int = <function2>
对于一个无参数的方法可以省略掉空括号,而无参函数是带空括号的:
scala> def x = println("Hi scala")//无参方法可省略掉空括号
x: Unit
scala> def x() = println("Hi scala")
x: ()Unit
scala> val y = x _
y: () => Unit = <function0> //无参函数类型是带空括号的
scala> y()
Hi scala
scala> x
Hi scala
方法是支持参数默认值的用法,但是函数会忽略参数默认值的,所以函数不能省略参数:
scala> def exec(s: String, n: Int = 2) = s * n
exec: (s: String, n: Int)String
scala> exec("Hi") //第二个参数使用了默认值
res0: String = HiHi
scala> val fun = exec _
fun: (String, Int) => String = <function2>
scala> fun("Hi") //无法使用默认值,不能省略参数
<console>:14: error: not enough arguments for method apply
scala> fun("Hi", 2) //必须设置所有参数
res2: String = HiHi
柯里化Currying函数可以只传入部分参数返回一个偏应用函数,而柯里化方法在转换成偏应用函数时需要加上显式说明,让编译器完成转换:
object TestCurrying {
def invoke(f: Int => Int => Int): Int = {//f是柯里化函数
f(1)(2)
}
def multiply(x: Int)(y: Int): Int = x * y // multiply是柯里化方法
def main(args: Array[String]) {
invoke(multiply) //编译器会自动将multiply方法转换成函数
// val partial1 = multiply(1) //multiply(1)相当于第二个方法的方法名,所以不能将方法赋值给变量
val partial2 = multiply(1):(Int => Int) //编译通过,且等效下面两个
val partial4 = multiply(1)_ // partial4的类型为 Int=>Int
val partial5: Int => Int = multiply(1)
val f = multiply _ //将multiply方法转换成柯里化函数f,f的类型为 Int=>(Int=>Int)
val partial3 = f(1) //只应用第1个参数返回函数,编译通过, partial3的类型为 Int=>Int
}
}
5 函数和闭包
5.1 方法
定义函数最通用的方法是作为某个对象的成员。这种函数被称为方法: method
//公有方法
def processFile(filename: String, width: Int) {
val source = Source.fromFile(filename)
for (line <- source.getLines)
processLine(filename, width, line)
}
//私有方法
private def processLine(filename: String, width: Int, line: String) {
if (line.length > width) //打印输长度超过给定宽度的行
println(filename + ": " + line.trim)
}
上面使用的是通常面向对象的编程方式
5.2 本地(内嵌、局部)函数
def processFile(filename: String, width: Int) {
def processLine(filename: String, width: Int, line: String) {//局部函数,只能在processFile方法(函数)中使用
if (line.length > width) print(filename + ": " + line)
}
val source = Source.fromFile(filename)
for (line <- source.getLines) {
processLine(filename, width, line)
}
}
本地函数可以直接访问所在外层函数的参数,所以上面可以改成:
def processFile(filename: String, width: Int) {
def processLine(line: String) {
if (line.length > width) print(filename + ": " + line)
}
val source = Source.fromFile(filename)
for (line <- source.getLines)
processLine(line)
}
5.3 函数字面量
你可以把函数写在一个没有名字的函数字面量(匿名字面量函数),并且可以把它当成一个值传递到其它函数,或赋值给其它变量
下面的例子为一个简单的函数字面量:
scala> (x: Int) => x + 1
res0: Int => Int = <function1> //res0为函数变量
=>表示这个函数将符号左边的东西(本例为一个整数),转换成符号右边的东西(加 1),=>符号左边是函数的参数,右边是函数体
函数字面量会被编译成类(实现了AbstractFunctionN抽象类的类),并在运行期实例化成函数值(即函数对象)。因此函数字面量和函数值的区别在于函数字面量存在于源代码中,而函数值则作为对象存在于运行期,这个区别很像类(源代码)与对象(运行期)之间的关系
任何函数值都是scala包中的FunctionN特质(trait)的一个实例,如不带参数的函数值是Function0特质的实例,带一个参数的函数值是Function1特质的实例等等:
scala> var inc = (x: Int) => x + 1
inc: Int => Int = <function1>
scala> inc.isInstanceOf[Function1[Int,Int]]
res8: Boolean = true
每个FunctionN特质都有一个apply方法,运行时实质上是由该方法来调用函数的
可以将函数字面量赋给一个函数类型的变量,并且可以参数变量调用:
scala> var increase = (x: Int) => x + 1
increase: (Int) => Int =
<function1> //
函数返回值为Int,函数体最后一条语句即返回值
scala> increase(10)
res0: Int = 11
由于函数字面量在编译时会被编译成相应的类以及实例化成相应的函数值对象,下面通过类的方式来实现上面函数字面量“(x: Int) => x + 1”所能自动化实现的过程:
//自定义类名为Increase的函数类
class Increase extends Function1[Int, Int] {
def apply(x: Int): Int = x + 2 //这里试着加2以示区别,加几并不重要
}
object T {
//创建匿名函数实例对象,匿名函数可以直接从Function1继承,并实现apply方法
var increase: Function1[Int, Int] = new Function1[Int, Int] {
def apply(x: Int): Int = x + 1
}
def main(args: Array[String]): Unit = {
println(increase(10)) //11。 变量后面可带括号参数,是因为该对象定义了相应的apply方法,increase(10) 等价于 increase.apply(10)
increase = new Increase()
println(increase(10)) //12
}
}
函数体有多条语句时,使用大括号:
scala> increase = (x: Int) => {
println("We")
println("are")
println("here!")
x + 1 // 函数返回值为Int,函数体最后一条语句即返回值
}
increase: (Int) => Int =
<function1>
scala> increase(10)
We
are
here!
res4: Int = 11
Iterable特质是 List, Set, Array,还有 Map 的共同超类,foreach 方法就定义在其中,它可以用来针对集合中的每个元素应用某个函数,即foreach方法参数允许传入函数:
scala> val someNumbers = List(-11, -10, -5, 0, 5, 10)
someNumbers: List[Int] = List(-11, -10, -5, 0, 5, 10)
scala> someNumbers.foreach((x: Int) =>
println(x)) // 只是简单的打印每个元素
-11
-10
-5
0
5
10
集合中还有filter函数也是可以传递一个函数的,用来过滤元素,传递进去的函数要求返回Boolean:
scala> someNumbers.filter((x: Int) => x
> 0)
res6: List[Int] = List(5, 10)
5.4 简化函数字面量
去除参数类型,以及外面的括号:
someNumbers.filter((x: Int) => x
> 0)
因数函数是应用于集合中元素,所以会根据集合元素类型来推导参数类型。
5.5 占位符_
下划线“_”来替代一个或多个参数,只要某个参数只在函数体里出现一次,则可以使用下划线 _ 来替换这个参数:
scala> someNumbers.filter(_ > 0)
res9: List[Int] = List(5, 10)
_ > 0 相当于x => x > 0,遍历时会使用当前相应元素来替换下划线(你可以这样来理解,就像我们以前做过的填空题,“_”为要填的空,Scala 来完成这个填空题,你来定义填空题)
有多少个下划线,则就表示有多少个不同的参数。多个占位符时,第一个下划线表示第一个参数,第二个下划线表示第二个参数,以此类推;所以同一参数多处出现时是无法使用这种占位符来表示的。
使用占位符时,有时无法推导出类型,如:
scala> val f = _ + _
此时需明确写出类型:
scala> val f = (_: Int) + (_: Int)
f: (Int, Int) => Int = <function2>
scala> def sum = (_:Int) + (_:Int) + (_:Int) //注:这里的下划线不是偏应用,它是函数字面量的占位符简化,该函数字面量为sum方法体最后一个语句,所以该方法返回值类型为函数
sum: (Int, Int, Int) => Int // 方法由三部分组成:方法名(这里为sum)+ 参数列表(这里没有,也不带空括号)+ 返回类型(这里为函数值类型(Int, Int, Int) => Int)
scala> sum //调用无参无空括号方法。由于参数为空,定义时去掉了空括号,所以调用时不能带空括号
res0: (Int, Int, Int) => Int =<function3> //返回的是函数字面量
scala> sum (1,2,3) //由于sum方法定义成了无参无空括号的方法,所以单独的语句 sum 就表示对sum方法进行了一次调用,而sum后面的(1,2,3)则是对函数值进行再一次调用
res1: Int = 6
5.6 偏应用函数
偏应用函数(Partial Applied Function)是指在调用函数时,有意缺少部分参数的函数。
前面的例子下划线 _ 代替的只是一个参数,实际上你还可以用“_”来代替整个参数列表(有多少个参数,则代表多少个参数),如println(_) ,或更简洁println _ ,或干脆println :
someNumbers.foreach(println _)
Scala 编译器自动将上面代码解释成:
someNumbers.foreach(x => println(x))
(注:下面的 “println _” 却又是返回的是无参数的偏应用函数,Why?因为println函数本身就有不带参数的形式,又由于这里没有信息指引f函数变量要带参数,所以 “_”就优先代表了0参数列表,所以f函数变量最终是一个无参数的函数变量。而上面的List.foreach(println _)中,由于foreach方法要求是带一个参数的函数,所以此时的“_”就去匹配一个参数列表的println函数
scala> val f = println _
f: () => Unit = <function0>
如果要带参数,这样才可以带一个参数:
scala> val f = (x:String)=>println(x)
f: String => Unit = <function1>
)
这个例子的下划线不是单个参数的占位符,而是整个参数列表的占位符(虽然示例中是只带有一个参数的println函数)
由于someNumbers.foreach方法要求传入的就是函数,所以此时下划线也可以直接省略,更简洁的写法:
someNumbers.foreach(println)
注:只能在需要传入函数的地方去掉下划线,其他地方不能,如后面的sum函数:
scala> val c = sum
<console>:12: error: missing argument list for method sum
Unapplied methods are only converted to functions when a function type is expected.
You can make this conversion explicit by writing `sum _` or `sum(_,_,_)` instead of `sum`.
val c = sum
^
以上在调用方法时,使用下划线“_”来代替方法参数列表(而不是传入具体参数值),这时你就是正在写一个偏应用函数(Partially applied functions)
在 Scala 中,当你调用函数传入所需参数时,你就把函数“应用”到参数,比如一个加法函数:
scala> def sum(a: Int, b: Int, c: Int) = a + b
+ c
sum: (Int,Int,Int)Int
你就可以把函数 sum 应用到参数 1, 2 和 3 上,如下:
scala> sum(1, 2, 3)
res12: Int = 6
一个偏应用函数指的是你在调用函数时,不指定函数所需的所有参数(或只提供部分,或不提供任何参数),这样你就创建了一个新的函数,这个新的函数就称为原始函数的偏应用函数,如:
scala> val a = sum _ //
将sum方法转换为偏应用函数后赋值给名为a的函数变量
a: (Int, Int, Int) => Int = <function3>
scala> a(1, 2, 3)
res13: Int = 6
scala> var b = sum(1,2,3); //如果在定义时就传入了具体值,则返回的就是具体的值了,此时b变量是Int变量,而非函数变量
b: Int = 6
上面的过程是这样的:名为a的变量指向了一个函数值对象,这个函数值是由Scala编译器依照偏应用函数表达式sum _ 自动产生的类的一个实例。且这个类有一个带3个参数的apply方法,编译器会将a(1,2,3) 表达式翻译成对函数值的apply方法的调用。因此a(1, 2, 3)实质为:
scala> a.apply(1, 2, 3)
res14: Int = 6
这种由下划线代替整个参数列表的一个重要的用途就是:可以将def定义的方法转换为偏应用函数,尽管不能直接将def定义的方法或嵌套函数赋值给函数变量,或当做参数传递给其它的方法,但是如果把方法或嵌套函数通过在名称后面加一个下划线的方式转换为函数后,就可以做到了
偏应用函数还可以部分指定参数,如:
scala> val b = sum(1, _: Int, 3) //变量 b 的类型为函数,是由 sum方法应用了第一个和第三个参数后构成的
b: (Int) => Int = <function1>
只缺少中间一个参数,所以编译器会产生一个新的函数类,其 apply 方法带一个参数,所以调用b函数变量时只能传入一个:
scala> b(2)
res15: Int = 6
此时,b(2)实质上是对函数值的apply方法调用,即b.apply(2),而b.apply(2)再去调用sum(1,2,3)
5.7 闭包
函数字面量在运行时创建的函数值(对象)称为闭包
scala> var more = 1
more: Int = 1
scala> val addMore = (x: Int) => x
+ more // 函数值赋值给addMorey,该函数值就是一个闭包
addMore: (Int) => Int = <function1>
scala> addMore(10)
res19: Int = 11
在闭包创建之后,闭包之外的变量more修改后,闭包中的引用也会根着变化,因此 Scala 的闭包捕获的是变量本身而不是当时变量的值:
scala> more = 9999
more: Int = 9999
scala> addMore(10)
res21: Int = 10009
上面是闭包之外的变量修改会影响闭包中相应变量,同样,在闭包中修改闭包外的变量,则闭包外的变量也会跟着变化:
scala> val someNumbers = List(-11, -10, -5, 0, 5, 10)
someNumbers: List[Int] = List(-11, -10, -5, 0, 5, 10)
scala> var sum = 0
sum: Int = 0
scala> someNumbers.foreach(sum += _) //在闭包中修改了闭包外的变量,外部变量也会跟着变化
scala> sum
res23: Int = -11
示例中的someNumbers.foreach(sum += _)语句中的 sum += _ 就是一个函数字面量,相当于 x => sum += x,具体参考前面的函数字面量与占位符
scala> var increase = (x: Int) => x
+ 1
increase: (Int) => Int = <function1>// 变量由两部分组成:变量名(这里为increase)+
类型(这里为函数值类型 (Int) => Int =
<function1> )
scala> def makeIncreaser(more: Int) = (x: Int) => x + more //这里的more 相当于闭包参数,要在调用时才能确定
makeIncreaser: (more: Int) Int => Int //方法由三部分组成:方法名(这里为makeIncreaser)+ 参数列表(这里为(more: Int))+ 返回类型(这里为函数值类型 Int => Int )
scala> val inc1 = makeIncreaser(1) //调用时确定闭包参数more为1,且返回函数值,并赋给inc1函数变量
inc1: Int => Int = <function1>
scala> val inc9999 =
makeIncreaser(9999)
inc9999: (Int) => Int = <function1>
上面每次makeIncreaser函数调用时都会产生一个闭包,且每个闭包都会有自己的more变量(即调用时传入的值)。
下面才开始真正调用函数字面量,且各自有自己的闭包参数more:
scala> inc1(10) //闭包参数more值为1
res24: Int = 11
scala> inc9999(10) //闭包参数more值为9999
res25: Int = 10009
5.8 可变参数
如果参数列表后面的参数类型都一样,可以使用*来代表参数列表,下面代表0个或多个String类型的参数,参数会存放到String类型的args数组中,即args类型为Array[String]:
scala> def echo(args: String*) =
for (arg <- args) println(arg)
echo: (String*)Unit
scala> echo()
scala> echo("one")
one
scala> echo("hello", "world!")
hello
world!
在函数内部,变长参数的类型,实际为一数组,比如上例的 String * 类型实际为 Array[String],然而,如今你试图直接传入一个数组类型的参数给这个参数,编译器会报错:
scala> val arr = Array("What's", "up", "doc?")
arr: Array[java.lang.String] = Array(What's, up, doc?)
scala> echo(arr)
<console>:7: error: type mismatch;
found :
Array[java.lang.String]
required: String
echo(arr)
ˆ
但你可以通过在变量后面添加一个冒号 : 和一个 _* 符号,这个符号告诉 Scala 编译器在传递参数时逐个传入数组的每个元素,而不是数组整体:
scala> echo(arr: _*)
What's
up
doc?
注:可变参数只能是参数列表中的最后一个
5.9 命名参数
通常情况下,调用函数时,参数传入和函数定义时参数列表一一对应。
scala> def speed(distance: Float, time:Float) :Float = distance/time
speed: (distance: Float, time: Float)Float
scala> speed(100,10)
res0: Float = 10.0
使用命名参数允许你使用任意顺序传入参数,比如下面的调用:
scala> speed( time=10,distance=100)
res1: Float = 10.0
scala> speed(distance=100,time=10)
res2: Float = 10.0
5.10 缺省参数值
Scala 在定义函数时,允许指定参数的缺省值,从而允许在调用函数时不传该参数,此时该参数使用缺省值。缺省参数通常配合命名参数使用,例如:
scala> def printTime(out:java.io.PrintStream = Console.out, divisor:Int =1 ) =
out.println("time = " + System.currentTimeMillis()/divisor)
printTime: (out: java.io.PrintStream, divisor: Int)Unit
scala> printTime()
time = 1383220409463
scala> printTime(divisor=1000)
time = 1383220422
5.11 尾(伪)递归
可以使用递归函数来消除需要使用 var 变量的 while 循环
def approximate(guess: Double): Double =
if (isGoodEnough(guess))
guess //该数已经足够好了,直接返回结果
else approximate(improve(guess)) //还不是最好,需继续改进
像上面,结尾是调用自己,这样的递归为尾递归
由于递归会产生堆栈调用而影响性能,所以你可能将递归修改为传递的While结构,如将上面的代码改进如下:
def approximateLoop(initialGuess: Double): Double = {
var guess = initialGuess
while (!isGoodEnough(guess))
guess = improve(guess)
guess
}
那么这两种实现哪一种更可取呢? 从简洁度和避免使用 var 变量上看,使用递归比较好。但依照以前经验递归比while循环慢,但实际上,经测试这两种方法所需时间几乎相同,Why?
其实,对于 approximate 的递归实现,Scala 编译器会做些优化,因为这里 approximate 的实现,最后一行是调用 approximate 本身,我们把这种递归叫做尾递归。Scala 编译器检测到尾递归时会自动使用循环来代替,因此,你应该还是多使用递归函数来解决问题,如果是尾递归,那么在效率上是不会有什么损失的
尾递归函数在每次调用不会构造一个新的调用栈。所有递归其实都在同一个执行栈中运行,而是Scala会使用While结构来优化这种递归
如下面的调用不是尾递归调用,因为最后一句虽然调用了自己,但在调用自己后,还进了增1操作:
scala> def boom(x: Int): Int ={
if (x == 0) throw
new Exception("boom!")
else boom(x - 1) + 1}
scala> boom(3)
java.lang.Exception: boom!
at .boom(<console>:5)
at .boom(<console>:6)
at .boom(<console>:6)
at .boom(<console>:6)
at .<init>(<console>:6)
...
从上面调用堆栈来看,boom函数是真正递归调用了多次(boom函数被调用了多次),所以不是尾递归。将上面的加一去掉后,才是尾递归调用,测试如下:
scala> def bang(x: Int): Int ={
if (x == 0) throw
new Exception("bang!")
else bang(x - 1)}
scala> bang(5)
java.lang.Exception: bang!
at .bang(<console>:5)
at .<init>(<console>:6)
...
从上面可以看出,函数bang只被调用了一次,即没有被递归调用,所以是尾递归
注:尾递归只在函数体最后一句直接调用函数本身,才能形成尾递归,其它任何情况下的间接调用则不会形成尾递归,如下面的间接调用不会形成尾递归:
def isEven(x: Int): Boolean = if (x == 0) true else isOdd(x - 1)
def isOdd(x: Int): Boolean = if (x == 0) false else isEven(x - 1)
虽然isEven 和 isOdd 都是在最后一句调用,它们是两个互相递归的函数,scala 编译器无法对这种递归进行优化,另外下面也不会形成尾递归:
val funValue = nestedFun _ //使用偏应用表达式将方法转换为函数值
def nestedFun(x: Int) {
if (x != 0) { println(x); funValue(x - 1) }
}
6 控制抽象
Scala 没有内置很多控制结构,这是因为 Scala 赋予了程序员自己通过函数扩展控制结构的能力
6.1 函数封装变化
如果方法中的某段逻辑是变化的,可以将这段逻辑封装在一个函数里,然后通过方法参数将该函数值传进去,这样就可以将方法中变化的逻辑剥离出来(使用Java中的接口也可以将变化封装起来)
比如下面实现一个过滤文件的方法,但过滤的算法是各种各样的,所以将过滤算法封装在函数里,然后在具体过滤时通过matcher函数类型参数传递过去:
object FileMatcher {
private def filesHere = (new java.io.File(".")).listFiles
//由于匹配的逻辑是变化的,所以将匹配的逻辑封装在函数里通过matcher参数传递进来,matcher参数类型中有=>,表示函数,该函数接收两个String类型参数,且返回布尔类型值
def filesMatching(query: String, matcher: (String, String) => Boolean) = {//此时的matcher函数带有两个参数
for (file <- filesHere; if matcher(file.getName, query)) //过滤出只需要的文件,但怎么过滤通过matcher传递进来
yield file
}
//然后这样使用:
def filesEnding(query: String) = filesMatching(query, _.endsWith(_)) //返回以query结尾的文件名
def filesContaining(query: String) = filesMatching(query, _.contains(_))//返回包含了query的文件名
def filesRegex(query: String) = filesMatching(query, _.matches(_)) //返回匹配query的文件名
}
这些调用用到了函数字面量占位符号法:
_.endsWith(_)相当于 (fileName: String, query: String) => fileName.endsWith(query) ,甚至可以省略参数的类型:(fileName, query) => fileName.endsWith(query) :
def filesEnding(query: String) = filesMatching(query, (fileName: String, query: String) => fileName.endsWith(query))
由于第一个参数fileName在函数字面量体中第一个位置被使用,第二个参数query在第二个位置中使用,所以你可以使用占位符语法来简化:_.endsWith(_),所以出现上面简洁写法
上面示例中 query传递给了 filesMatching,但 filesMatching方法中并没有直接使用它,而又是直接把它传给了matcher 函数,所以这个传来传去的过程不是必需的,因此可以将filesMatching方法 和 matcher 函数中的参数 query 去掉,而是在函数字面量体中直接使用闭包参数query(正是因为闭包才可以省去query参数的传递):
object FileMatcher2 {
private def filesHere = (new java.io.File(".")).listFiles
def filesMatching(matcher: String => Boolean) = {//此时的matcher函数只有一个参数
for (file <- filesHere; if matcher(file.getName))
yield file
}
def filesEnding(query: String) = filesMatching((fileName) => fileName.endsWith(query)) // 直接使用闭包参数query
def filesContaining(query: String) = filesMatching(_.contains(query))
def filesRegex(query: String) = filesMatching(_.matches(query))
}
下面我们再来看看Scala类库对变化封装的示例:
传统判断集合中是否存在负数的方式:
def containsNeg(nums: List[Int]): Boolean = {
var exists = false
for (num <- nums)
if (num < 0)
exists = true
exists
}
Scala集合类中的exists方法对是否存在这一变化的逻辑进行封装,只需传递判断的逻辑(即函数)即可,所以可以这样:
def containsNeg(nums: List[Int]) = nums.exists(_ < 0)
exists方法代表了控制抽象,其实是Scala将上面传统的代码替我们进行了封装(如循环相关的代码),我们只需传入变化的逻辑即可,下面是集合的exists方法源码:
def exists(p: A => Boolean): Boolean = {
var these = this
while (!these.isEmpty) {
if (p(these.head))
return true
these = these.tail
}
false
}
比如判断是否存在偶数,只需转入具体的判断逻辑:
def containsOdd(nums: List[Int]) = nums.exists(_ % 2 == 1)
6.2 柯里化currying
Scala 允许程序员自己新创建一些控制结构,并且可以使得这些控制结构在语法看起来和 Scala 内置的控制结构一样,在 Scala 中需要借助于柯里化(Currying)
柯里化将方法或函数是将一个带有多个参数的列表拆分成多个小的参数列表(一个或多个参数)的过程,并且将参数应用前面参数列表时会返回新的函数技术
scala> def plainOldSum(x: Int, y: Int) = x + y
plainOldSum: (x: Int, y: Int)Int
scala> plainOldSum(1, 2)
res4: Int = 3
将plainOldSum写成柯里化的curriedSum,前面函数使用一个参数列表,“柯里化”把函数定义为多个参数列表(且第一个参数列表只有一个参数,剩余的参数放在第二个参数列表中):
scala> def curriedSum(x: Int)(y: Int) = x + y //柯里化方法
curriedSum: (x: Int)(y: Int)Int
scala> curriedSum(1)(2)
res5: Int = 3
当你调用 curriedSum (1)(2) 时,实际上是依次调用两个普通函数(非柯里化函数),第一次调用使用一个参数 x,返回一个函数值,第二次使用参数y调用这个函数值。下面我们来用两个分开的定义来模拟 curriedSum 柯里化函数的过程:
scala> def first(x: Int) = (y: Int) => x + y
first: (x: Int)Int => Int
// first方法返回的是函数值(对象),x是既是方法参数,又是函数闭包参数
调用first方法会返回函数值,即产生第二个函数:
scala> val second = first(1) //产生第二个函数
second: (Int) => Int =
<function1> //second为函数变量,引用某个函数值
scala> second(2) //调用second函数产生最终结果
res6: Int = 3
上面first,second的定义演示了柯里化函数的调用过程,它们本身和 curriedSum 没有任何关系,但是可以引用到第二个函数second,如下:
scala> val second = curriedSum(1)_ //“curriedSum(1)” 相当于第二个方法的方法名。在前面示例中,当占位符标注用在传统方法上时,如 println _,你必须在名称和下划线之间留一个空格。在这里不需要,因为
println_ 是 Scala 里合法的标识符,
curriedSum(1)_不是
second: (Int) => Int =
<function1>
scala> onePlus(2)
res7: Int = 3
注意与下面的区别:
scala> val func = curriedSum _ //这里是将整个curriedSum方法转换为函数,该函数带两个参数,而前面只是将方法curriedSum的一部分(第二个参数列表)转换为函数,所以上面只带一个参数
func: Int => (Int => Int) = <function1>
再看一个柯里化的例子,把带有三个参数的函数f转换为只有一个参数的部分应用函数f:
scala> def curry[A, B, C, D](f: (A, B, C) => D): A => (B => (C => D)) = (a: A) => (b: B) => (c: C) => f(a, b, c)//柯里化函数
curry: [A, B, C, D](f: (A, B, C) => D)A => (B => (C => D))
scala> val f = curry((_: Int) + (_: Int) + (_: Int))
f: Int => (Int => (Int => Int)) = <function1> //将带有三个参数的函数柯里化成3个单一参数的函数
scala> f(1)
res4: Int => (Int => Int) = <function1>
scala> f(1)(2)
res5: Int => Int = <function1>
scala> f(1)(2)(3)
res6: Int = 6
下面与上面不同的是,把带有三个参数的函数f转换为第一个是单个参数,第二个包括所有余下参数的部分应用函数f:
scala> def curry2[A, B, C, D](f: (A, B, C) => D): A => ((B, C) => D) = (a: A) => (b: B, c: C) => f(a, b, c)
curry2: [A, B, C, D](f: (A, B, C) => D)A => ((B, C) => D)
scala> val f2 = curry2((_: Int) + (_: Int) + (_: Int))
f2: Int => ((Int, Int) => Int) = <function1>
scala> f2(1)
res9: (Int, Int) => Int = <function2>
scala> f2(1)(2,3)//第二个参数列表带两个参数
res10: Int = 6
甚至转换第一个参数列表带两个参数,第二个参数列表只带一个参数的函数,这也是可以的:
scala> def curry3[A, B, C, D](f: (A, B, C) => D): (A,B) => C => D = (a: A,b:B) => (c:C) => f(a, b, c)
curry3: [A, B, C, D](f: (A, B, C) => D)(A, B) => C => D
scala> val f3 = curry3((_: Int) + (_: Int) + (_: Int))
f3: (Int, Int) => Int => Int = <function2>
scala> f3(1,2) //第一个参数列表带两个参数
res12: Int => Int = <function1>
scala> f3(1,2)(3)
res13: Int = 6
上面是柯里化,下面进行反柯里化,将多个参数列表合并成一个参数列表:
scala> def uncurry[A, B, C](f: A => B => C): (A, B) => C = (a: A, b: B) => f(a)(b)
uncurry: [A, B, C](f: A => (B => C))(A, B) => C
scala> val uf = uncurry((a:Int)=>(b:Int)=>a + b)//反柯里化
uf: (Int, Int) => Int = <function2>
scala> uf(1,2)
res14: Int = 3
下面是接收两个参数的方法,进行部分应用。即我们有一个A和一个需要A和B产生C的函数,可以得到一个只需要B就可以产生C的函数(因为我们已经有A了)
scala> def curry1[A, B, C](a: A, f: (A, B) => C): B => C = (b: B) => f(a, b)//也可将(b: B) => f(a, b)写成f(a,_)
curry1: [A, B, C](a: A, f: (A, B) => C)B => C
//a参数会应用到f函数参数的第一个A类型的参数中,这样会返回只应用了第一个A类型参数的f1的偏应用函数
scala> val f1 = curry1(1,(_:Int) +(_:Int))//f1实为f函数的一个偏应用函数
f1: Int => Int = <function1>
scala> f1(2)
res1: Int = 3
如果将上面curry1方法中的f函数参数具体化,即在将f函数代码直接在curry1方法中写出来,而不是通过方法参数传递进去,下面示例是上面的具体化,函数代码直接在方法体中描述出来,而非参数传递进来:
scala> def makeIncreaser(more: Int) = (x: Int) => x + more
makeIncreaser: (more: Int) Int => Int
scala> val inc1 = makeIncreaser(1)
inc1: Int => Int = <function1>
scala> inc1(10)
res24: Int = 11
6.3 编写新的控制结构
将不要用户关心的逻辑封装起来,比如资源的打开与关闭:
def withPrintWriter(file: File, op: PrintWriter => Unit) {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
withPrintWriter方法只提供两个参数:一个是对哪个文件进行操作,二是对文件进行一个什么样的操作(写还是读?),除此之外如打开与关闭文件则封装起。
如下使用,对date.txt 文件进行写println操作,具体写什么则在函数里指定(这里写当前日期):
withPrintWriter(
new File("date.txt"),
w => w.println(new java.util.Date)
)
这样当调用withPrintWriter方法操作文件后,文件一定会关闭
在Scala里,如果调用的方法只有一个参数,就能可选地使用大括号替代小括号包围参数:
scala> println("Hello,
world!")
Hello, world!
你可以写成:
scala> println { "Hello,
world!" }
Hello, world!
上面第二种用法,使用{}替代了(),但这只适用在使用一个参数的调用情况。 前面定义 withPrintWriter 函数使用了两个参数,因此不能使用{}来替代(),但如果我们使用柯里化重新定义下这个函数如下:
def withPrintWriter(file: File)(op: PrintWriter => Unit) {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
将一个参数列表,变成两个参数列表,每个列表含一个参数,这样我们就可以使用如下语法来调用:
withPrintWriter(new File("date.txt")) {
writer => writer.println(new java.util.Date);
//上面的语句还可以简写如下:
//_.println(new java.util.Date)
}
第一个参数还是使用()将参数包围起来(也可以使用{}),第二个参数放在了花括号之间,这样withPrintWriter看起来和Scala内置控制结构(如if、while等)语法一样
6.4 传名参数by-name parameter
上篇我们使用柯里化函数定义一个控制机构 withPrintWriter,它使用时语法调用已经很像 Scala 内置的控制结构,有如if、while的使用一般:
withPrintWriter(new File("date.txt")) {
writer => writer.println(new java.util.Date)
}
不过仔细看一看这段代码,它和 scala 内置的 if 或 while 表达式还是有些区别的,withPrintWrite r的{}中的函数是带参数的含有“writer=>”。 如果你想让它完全和 if 和 while 的语法一致,在 Scala 中可以使用传名参数来解决这个问题。
Scala的解释器在解析函数参数(function arguments)时有两种方式:先计算参数表达式的值(reduce the arguments),再传递到函数内部;或者是将未计算的参数表达式直接应用到函数内部。前者叫做传值调用call-by-value,后者叫做传名调用call-by-name:
def addByName(a: Int, b: => Int) = a + b //传名
def addByValue(a: Int, b: Int) = a + b //传值
使用传名调用时,在参数名称和参数类型中间有一个“=>”符号。如果a = 1,b = 2 + 3,调用个方法的结果都是 6,但过程是不一样的:
· addByName(1, 2 + 3)
· ->1 + (2 + 3)
· ->1 + 5
· ->6
· addByValue(1, 2 + 3)
· ->addByValue(1, 5)
· ->1 + 5
· ->6
只有无参函数才能通过传名参数进行传递,在传入其它方法前,是不会执行的,而是将传入的函数逻辑代码直接嵌入(替换)到传名参数所在的地方(有点Include的意思)
下面设计一个myAssert断言方法,带一个函数值参数predicate,如果标志位assertionsEnabled被设置true(表示开启断言功能),且传入的函数返回true时,将什么也不做(即断言成功),如果传入的函数返回false时,则断言失败;如果标志位assertionsEnabled被设置false(表示关闭断言功能),则什么也不做:
scala>var assertionsEnabled = true
def myAssert(predicate: () => Boolean) =
if (assertionsEnabled && !predicate())
throw new AssertionError
myAssert: (predicate: () => Boolean)Unit //空括号表示predicate函数不带参数
scala> myAssert(() => 5 > 3) // 断言成功 ,这里是传值,传递的是函数值
调用myAssert时或许你想去掉空参数列表和=>符号 ()=>,写成如下形式,但报错:
scala> myAssert(5 > 3) //报错 ,但传名参数可以实现这种想法
<console>:15: error: type mismatch;
found : Boolean(true)
required: () => Boolean
myAssert(5 > 3)
^
上面使用的是按值传递(在传入到方法就已执行并计算出结果——该结果是无参函数字面量“() => 5 > 3”函数值对象),传递的是函数类型的值,我们可以把按值传递参数修改为按名称传递的参数。要实现一个传名参数,参数类型应该以 => 开头,而不是 ()=> 开头,如上面你可以将predicate参数的类型从“() => Boolean”改为“=> Boolean”,经过这种改造后,myAssert方法中的 predicate 参数则叫传名参数:
scala>def byNameAssert(predicate: => Boolean) = //去掉了=>前面的括号()
if (assertionsEnabled && !predicate) // predicate是名称参数,会将predicate替换成传入的函数逻辑代码。这里的predicate不是函数值对象,因为如果是函数值对象,调用时后面一定要接括号的,所以predicate在这里相当于一个占位符,将会使用传入的函数代码来替换
throw new AssertionError
byNameAssert: (predicate: => Boolean)Unit
此时调用byNameAssert方法时就可以省略空的参数() =>了,此时使用byNameAssert看上去好像在使用内建控制结构了:
scala> byNameAssert(5 > 3) // 断言成功。 另一实例参考这里的传名参数
注:此时不会将 5 > 3 先进行计算然后再传入byNameAssert方法,如果这样的话,传入的是Boolean类型,就不是函数值类型
上面的myAssert、byNameAssert两个方法只是写法上不一样,都可以正确断言。其实两者有着本质的区别,myAssert是传值参数,byNameAssert是传名参数。
或许你可能想将参数的类型从函数值类型直接定义为Boolean,下面的方法boolAssert虽然看上去与byNameAssert相似,但在某些情况下是不能正确实现断言功能 :
scala>def boolAssert(predicate: Boolean) =
if (assertionsEnabled && !predicate)
throw new AssertionError
此时下面的断言是可以成功的:
scala> byNameAssert(5 > 3) // 断言成功
但在断言标志assertionsEnabled设为false关闭断言时,针对“1 / 0 == 0”这样的断言就会抛异常(除0了):
scala> boolAssert(1 / 0 == 0)
java.lang.ArithmeticException: / by zero
但byNameAssert将不会抛异常:
scala> byNameAssert(1 / 0 == 0)
原因就是boolAssert方法中的参数类型直接是Boolean类型,则传入的“1 / 0 == 0”会先进行运行,此时 1 / 0 就会抛异常;而 byNameAssert(1 / 0 == 0),表达式 “1 / 0 == 0” 不会被事先计算好传递给 byNameAssert,而是先将 “1 / 0 == 0”创建成一个函数类型的参数值,然后将这个函数类型的值作为参数传给 byNameAssert ,实质上“1 / 0 == 0”是最后由这个函数的 apply 方法去调用,但此时的assertionsEnabled标志为false形成短路,所以最终没能执行,所以也不会抛异常
前面传名参数传递的都是函数逻辑代码,实质上传名参数可以接受任何逻辑代码块,只要代码块类型与传名参数类型相同:
def time(): Long = {
println("获取时间")
System.nanoTime()
}
def delayed(t: => Long): Long = {
println("进入delayed方法")
println("参数t=" + t)
t
}
def main(args: Array[String]) {
//还可以直接传递方法调用,实质上会使用这里 time() 代替delayed方法体内的 t 名称参数
delayed(time())
//由于time是无参方法,所以调用时也可能省略括号
//delayed(time)
println("-------------------")
delayed({ println("传名参数可接受任何逻辑代码块"); 1 })
}

前面的 withPrintWriter 我们暂时没法使用传名参数去掉参数里的 writer=>,因为传进去的op函数参数是需要参数的(即需要对哪个目标文件进行操作),不过我们可以看看下面的例子,设计一个 withHelloWorld 控制结构,即这个 withHelloWorld 总会打印一个“hello,world”:
import scala.io._
import java.io._
//op这个函数是不需参数的,所以可以设计成按名传递
def withHelloWorld(op: => Unit) {
op // op是名称参数,会将op替换成传入的函数逻辑代码
println("Hello,world")
}
调用一:
val file = new File("date.txt")
withHelloWorld { //调用时,会将上面方法体内的op传名参数所在地方,使用这对花括号中的逻辑代码块替换掉
val writer = new PrintWriter(file)
try {
writer.println(new java.util.Date)
} finally {
writer.close()
}
}
Hello,world
调用二:
withHelloWorld {
println("Hello,Guidebee")
}
Hello,Guidebee
Hello,world
可以看到 withHelloWorld 的调用语法和 Scala 内置控制结构非常象了
总结,传名参数的作用就是:给方法传递什么样的代码,那就会使用什么样的代码替换掉方法体内的传名参数
7 组合与继承
7.1 抽象类
abstract class Element {
def contents: Array[String]
}
一个含有抽象方法的类必须定义成抽象类,也就是说要使用abstract关键字来定义类
抽象类中不一定有抽像方法,但抽象方法所在的类一定是抽象类
abstract抽象类的不能实例化
contents 方法本身没有使用 abstract 修饰符,一个没有定义实现的方法就是抽象方法,和 Java 不同的是,抽象方法不需要使用 abstract 修饰符来表示,只要这个方法没有具体实现,就是抽象方法
声明: declaration
定义: definition。
类 Element 声明了抽象方法contents,但当前没有定义具体方法
7.2 无参方法
abstract class Element {
def contents: Array[String] //抽象方法
def height: Int = contents.length //无参方法,不带参数也不带括号
def width(): Int = if (height == 0) 0 else contents(0).length //空括号方法,不带参数但带括号
}
注:如果定义时去掉了空括号,则在调用时也只能去掉;如果定义时带上了空括号,则调用时可以省略,也可以不省略:假设e是Element实例,调用上面的height只可以是这样:e.height,而不能是e.height();但调用width方法时,即可以是e.width,也可以是e.width()
一般如果方法没有副作用(即只是读取对象状态,而不会修改对象的状态,也不会去调用其它类或方法)情况下,推荐使用这种无参方法来定义方法,因为这样访问一个方法时好像在访问其字段成员一样,这样访问代码做到了统一访问原则,也就是说height、width不管定义成字段还是方法(定义时省略空括号),客户端访问代码都可以不用变,因为此时访问的height、width方式都一样
不带括号的无参方法很容易变成属性字段,只需将def改为val即可:
abstract class Element {
def contents: Array[String] //抽象方法
val height = contents.length
val width = if (height == 0) 0 else contents(0).length
}
访问字段要比访问方法略快,因为字段在类的初始化时就已经计算过了,而方法则在每次调用时都要计算
由于Scala 代码可以直接调用 Java 函数和类,但 Java 没有使用“统一访问原则”,如在Java 里只能是 string.length(),而不能是 string.length。为了解决这个问题,Scala 对于Java里的空括号函数的使用也是一样,也可以省略这些空括号:
Array(1, 2, 3).toString
//实际上调用的是Java中Object中的toString()方法
"abc".length //实为调用的Java中String的length()方法
//以前这种在Java中常规调用法在Scala中也还是可以的
Array(1, 2, 3).toString()
"abc".length()
原则上,Scala的函数调用中可以省略所有的空括号,但如果使用的函数不是纯函数,也就是说这个不带参数的函数可能修改对象的状态或是我们利用它调用了其他一些功能(比如调用其它类打印到屏幕,读写 I/o等),一般的建议还是使用空括号:
"hello".length // 没有副作用,所以无须(),因为String是不可变类
println() // I/O操作,最好别省略()
总之,Scala推荐使用将不带参数且没有副作用的方法定义为无参方法,即省略空括号,但永远不要定义没有括号但带副作用的方法,因为那样的话方法调用看上去像是访问的字段,会让调用都感觉到访问属性还产生了其他作用呢?另外,从调用角度从发(前面是从定义角度出法),如果你的调用方法执行了其他操作就要带上括号,但如果方法仅仅是对某个属性字段的访问,则可以省略
7.3 extends
class ArrayElement(conts: Array[String]) extends Element {
def contents: Array[String] = conts
}
extends会将所有非私有的成员会继承过来
如果你在定义类时没有使用 extends 关键字,在 Scala 中这个定义类缺省继承自 scala.AnyRef,如同在 Java 中缺省继承自 java.lang.Object。这种继承关系如下图:
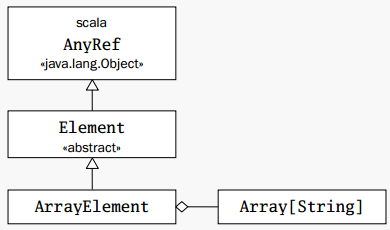
重写override:子类重写父子相同名称的方法(方法签名也要相同),或同名成员字段
实现implement:子类实现父类中抽象方法
scala> val ae = new ArrayElement(Array("hello", "world"))
ae: ArrayElement = ArrayElement@d94e60
scala> ae.width //访问从父类Element继承过来的成员
res1: Int = 5
val e: Element = new ArrayElement(Array("hello")) //父类的引用指向子类的实例
7.4 字段重写无参方法(或实现无参抽象方法)
和 Java 稍有不同的一点是,Scala 中方法与字段是在同一个命名空间,也就是说Scala 中不允许定义同名的无参成员函数(方法,不管是否有无空括号)和成员变量,这样的好处是可以使用成员变量来重写一个无参的成员函数(或实现抽象无参方法)。比如下面B类中的属性成员a字段实现了父类A中的a抽象方法:
abstract class A {
def a:Int //抽象方法
}
class B extends A {
val a = 1 //实现父类的抽象方法,这里是实现而非重写,所以前面可以省略 override
}
注:字段实现父类中同名抽象无参方法时,可以是val,也可以是var,这与字段与字段之间的重写不太一样
上面示例中属于实现,所以实现时可以省略override,但如果子类重写父类的非抽象方法(具体方法)时前面是要带override如:
class A {
def a: Int = 1
}
class B extends A {
override val a = 1 // 由于是重写父类同名非抽象方法,所以一定要加上 override 关键字
}
注:Java1.5 中, @Override 标注被引入并与 Scala 的 override 修饰符作用一样,但Java中的 override不是必需的
上面的示例都是子类中的成员字段实现或重写父类中同名的无参方法,但无参方法是不能重写同名成员字段:
scala> class A {
| var a: Int = 1
| }
defined class A
scala> class B extends A {
| override def a = 1 //这里编译出错
| }
<console>:13: error: overriding variable a in class A of type Int;
method a cannot override a mutable variable 方法不能重写变量(或常量,val定义的为常量)
override def a = 1
^
Scala 里禁止在同一个类里用同样的名称定义字段和方法,而在 Java 里这样做被允许。例如,下面的 Java 类能够很好地编译:
//在Java里的代码
class CompilesFine {
private int f = 0;
public int f() {
return 1;
}
}
但是相应的 Scala 类将不能编译:
class WontCompile
{
private var f = 0 // 编译不过,因为字段和方法重名
def f = 1
}
7.5 字段重写字段
子类的成员字段也是可以重写父类的同名字段的,但只有val类型的常量才能被重写,并且重写时也只能使用val来修饰:
class A {
val a: Int = 1
}
class B extends A {
override val a:Int = 2 //属性重写,不能省略override
}
如果将上面示例中的两个val其中任何一个修改成var就会报错。
另外,父类私有private的对于子类是不可见的,所以不能重写:
class A {
private val a: Int = 1
}
class B extends A {
val a: Int = 2
}
注:字段间的重写不能省略override关键字
abstract class Fruit {
val v: String
def m: String
}
abstract class Apple extends Fruit {
val v: String
val m: String // OK to override a ‘def’ with a ‘val’
}
abstract class BadApple extends Fruit {
def v: String // ERROR: cannot override a ‘val’ with a ‘def’
def m: String
}
7.6 参数化成员字段
上面的示例中,有这样一段类似定义的代码:
class T(a: Int) {
val f = a
}
其中a: Int为类的参数,在实例化时需要传入此参:
val t = new T(1);
scala> t.f
res0: Int = 1
scala> t.a // 不会产生名为a的成员变量
<console>:14: error: value a is not a member of T
t.a
^
虽然a是类一级别的参数,但它不会自动成为类的成员变量,所以t.a是错误的,此情况下的a仅仅是参数罢了,但如果在a: Int 的前面加上 val 或 var呢?请看下面:
class T(val a: Int) {
val f = a
}
val t = new T(1);
scala> t.f
res3: Int = 1
scala> t.a // 会产生名为a的成员变量
res4: Int = 1
scala> t.a = 2 // 由于定义的是 val 类型,所以不能修改其值,t.a在t构造时会被初使化;如果定义成var,则此处可以修改
<console>:13: error: reassignment to val
t.a = 2
^
上面示例说明,只要在类的参数前面加上 val 或 var,类的参数除了作为类构造时的一个参数外,类的参数还自动成为类的一个同名成员字段,这个成员字段与直接在类体中定义是没有区别的,即此时类参数与类成员合二为一了,即类的参数进一步提升为了参数化成员字段
参数化成员字段定义前面还可以加上private、protected、override修饰符,这跟在类中直接定义没有区别:
class Cat {
val dangerous = false
}
class Tiger(
override val dangerous: Boolean,//重写父类的属性成员,前面的override关键字不能省略
private var age: Int) extends Cat
上面Tiger 的定义实质上是下面代码写法的简写,这是一样的:
class Tiger(param1: Boolean, param2: Int) extends Cat {
override val dangerous = param1
private var age = param2
}
此时param1、param2仅仅是类参数而已,不会成为类的属性成员
7.6.1 var成员变量、getter与setter方法
在Scala中,对象的每个非private[this]访问的var类型成员变量都隐含定义了getter和setter方法(val变量不会生成setter方法),但这些getter和setter方法的命名方式并没有沿袭Java的约定,var变量x的getter方法命名为“x”,它的setter方法命名为“x_=”。例如,如果类中存在var定义:
var hour = 12//定义一个非私有的var变量时,除了会生成相应本地字段(private[this]修饰的字段)外,还会生相应的gtter与setter方法
则除了有一个成员字段会生产之外,还额外生成getter方法“hour”,以及setter方法“hour_=”。不管var前面是什么样的访问修饰符(除private[this]外,因为如果是private[this]则不会生成相应相应getter与setter方法),生成的成员字段始终会使用private[this]来修饰,表示只能被包含它的对象访问,即使是同一类但不同对象也是不能进行访问的;而生成的getter和setter方法前面的访问修饰符与原val前访问修饰符相同,即:如果var定义为public,则它生成的getter和setter方法前访问修饰符也是public,如果定义为protected,那么它们也是protected。
例如下面类型了一个Time类,里面定义了两个公开的var变量hour和minute:
class Time {
var hour = 12
var minute = 0
}
下面是上面public var变量实际所生成的类,这是完全相同的(类里定义的本地字段(private[this]修饰的字段)h和m的命令是随意命名的,要求是不与任何已经存在的名称冲突):
class Time {
private[this] var h = 12
private[this] var m = 0
def hour: Int = h
def hour_=(x: Int) { h = x }
def minute: Int = m
def minute_=(x: Int) { m = x }
}
所以,你也可以直接通过上面第二种getter、setter方式来取代var变量的定义,这样你可以在getter或setter方法里做一些控制。如下面再次改写上面的代码,加上数据有效性检测:
class Time {
private[this] var h = 12
private[this] var m = 12
def hour: Int = h
def hour_=(x: Int) {
require(0 <= x && x < 24) //参数有效性检测
h = x
}
def minute = m
def minute_=(x: Int) {
require(0 <= x && x < 60) //参数有效性检测
m = x
}
}
可以只定义getter和setter方法而不带有本地关联字段(private[this] var类型的字段),有时是需要这样做的:比如温度就有两种,摄氏度与华氏度,但它们之间是可以相互换算的,这样就没有必须设置两个var变量分别存储摄氏度与华氏度,而是以某一种来存储,另一种在setter与getter时进行相应换算即可。下面就是以摄氏度来存储,而华氏度有相应getter与setter方法来进行转换即可:
class Thermometer {
var celsius: Float = _ //摄氏度(℃),会自动生产相应的getter与setter方法
def fahrenheit = celsius * 9 / 5 + 32//以华氏度单位来显示
def fahrenheit_=(f: Float) {//传进来的是华氏度(℉),需要转换后存入
celsius = (f - 32) * 5 / 9
}
override def toString = fahrenheit + "F/" + celsius + "C"
}
上面的celsius变量,初始值设置为了“_”,这个符号表示根据变量的类型来初始化初值:对于数值类型会设置为0,布尔类型为false,引用类型为null
注意,Scala不可以随意省略“=_”初始化器,如果写成
var celsius: Float
这将表示celsius为抽象变量,这与Java中的成员变量省略初始化是不同的,Java成员变量(Java局部变量一定要显示初始化)如果省略初始化赋值,则还是会自动根据成员字段类型来进行初始化,而Scala中省略后则表示是一个抽象变量
7.7 调用父类构造器
要调用父类构造器(主或辅助构造器都可,以参数来决定),只要把你要传递的参数或参数列表放在父类名之后的括号里即可:
abstract class Element {
def contents: Array[String]
def height = contents.length
def width = if (height == 0) 0 else contents(0).length
}
class ArrayElement(conts: Array[String]) extends Element {
val contents: Array[String] = conts
}
//由于父类ArrayElement带了一个类参数conts,所以在定义子类LineElement时需要传递这个参数
class LineElement(s: String) extends ArrayElement(Array(s)) {
override def width = s.length
override def height = 1
}
7.8 多态
class UniformElement(ch: Char,
override val width: Int,
override val height: Int) extends Element {
private val line = ch.toString * width
def contents = Array.fill(height)(line)
}
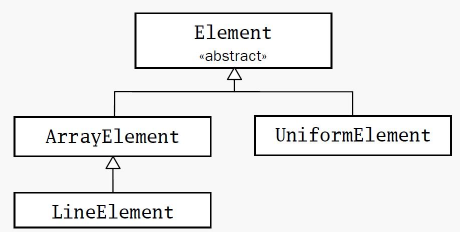
val e1: Element = new ArrayElement(Array("hello", "world"))//父类引用指向子类对象,即多态
val ae: ArrayElement = new LineElement("hello")//父类引用指向子类对象
val e2: Element = ae//祖父类引用指向孙类对象
val e3: Element = new UniformElement('x', 2, 3)//父类引用指向子类对象
为了演示多态,先临时删除 Element 中所有成员,添加一个 demo 方法,定义如下:
abstract class Element {
def demo() {
println("Element's implementation invoked")
}
}
class ArrayElement extends Element {
override def demo() {
println("ArrayElement's implementation invoked")
}
}
class LineElement extends ArrayElement {
override def demo() {
println("LineElement's implementation invoked")
}
}
class UniformElement extends Element //没有重写父类的方法
object T {
//参数类型为父类,任何子类实例都可以传递进来
def invokeDemo(e: Element) {
e.demo() //多态,在运行时调用相应子类方法
}
def main(args: Array[String]) {
invokeDemo(new ArrayElement)
invokeDemo(new LineElement)
invokeDemo(new UniformElement) //由于没有重写父类方法,所以调用的是父类Element中的方法
}
}

7.9 final
与Java一样,final修饰方法或字段(只有Scala才支持字段重写),是不能被子类重写的;如果修饰的是类的话,则类是不能被继承
scala> class A{
| final def f = 1
| }
defined class A
scala> class B extends A{
| override val f = 1 //子类不能重写父类的final成员
| }
<console>:13: error: overriding method f in class A of type => Int;
value f cannot override final member
override val f = 1
^
scala> final class A{
| def f = 1
| }
defined class A
scala> class B extends A{ //final类不能被继承
| override val f = 1
| }
<console>:12: error: illegal inheritance from final class A
class B extends A{
^
7.10 组合与继承
继承与组合是实现类复用的两种最常用的技术
组合是has-a的关系
继承是is-a的关系
继承是is-a 的关系,比如说Student继承Person,则说明Student is a Person
缺点:
1) 子类从父类继承的方法在编译时就确定下来了,不支持动态继承,子类无法选择不同的父类,所以运行期间无法改变从父类继承的方法的行为
2) 继承关系最大的弱点是打破了封装,子类能够访问父类的实现细节,耦合度高,子类缺乏独立性,父类修改会影响所有子类
组合的优点:
1:不破坏封装,整体类与组合类之间松耦合,彼此相对独立,具有较好的可扩展性
3:支持动态组合。在运行时,整体对象可以选择不同类型的组合对象占为己用
Car表示汽车对象,Vehicle表示交通工具对象,Tire表示轮胎对象。三者的类关系如下图:
Car是Vehicle的一种,因此是一种继承关系(又被称为“is-a”关系);而Car包含了多个Tire,因此是一种组合关系(又被称为“has-a”关系),实现如下:
class Verhicle {
}
class Tire {
}
class Car extends Verhicle {
private Tire t = new Tire();
}
既然继承和组合都可以实现代码的重用,那么在实际使用的时候又该如何选择呢?一般情况下,遵循以下两点原则:
1) 除非两个类之间是“is-a”的关系,否则不要轻易地使用继承,不要单纯地为了实现代码的重用而使用继承,因为过多地使用继承会破坏代码的可维护性,当父类被修改的时候,会影响到所有继承自它的子类,从而增加程序的维护难度与成本
2) 不要仅仅为了实现多态而使用继承,如果类之间没有“is-a”的关系,可以通过接口+组合的方式来达到相同的目的。设计模式中的策略模式可以很好的说明这一点,采用接口与组合的方式比采用继承的方式具有更好的可扩展性。
由于Java语言只支持单继承,如果想同时继承两个类或多个类,在Java中是无法直接实现的,这可以通过组合来实现;另外如果继承使用太多,也会让一个class里面的内容变得臃肿不堪。所以在Java语言中,能使用组合的时候尽量不要使用继承。
7.11 工厂对象
使用工厂对象的好处是,可以提供统一创建对象的接口并且隐藏被创建具体对象的实现
实现 factory 对象的一个基本方法是采用 singleton 模式,在 Scala 中,可以使用类的伴生对象(companion 对象)来实现:
//对象 Element 的伴生类
abstract class Element {
def contents: Array[String]
def width: Int =
if (height == 0) 0 else contents(0).length
def height: Int = contents.length
//使用伴随对象的 factory 方法 Element.elem 替代 new 构造函数
def above(that: Element): Element =
//++操作符:将两个数据连接起来
Element.elem(this.contents ++ that.contents)
def beside(that: Element): Element = {
Element.elem(
for (
//取各自数组对应位置上的元素,生成二元组Tupele2
//例如,表达式: Array(1, 2, 3) zip Array("a", "b")
//将生成: Array((1, "a"), (2, "b"))
(line1, line2) <- this.contents zip that.contents
) yield line1 + line2)
}
override def toString = contents mkString "\n"
}
//类 Element 的伴生对象
object Element {
//库函数的用户不要了解 Element 的继承关系,甚至不需要知道类
//ArrayElement,LineElement 定义的存在,为了避免用户直接使用
//ArrayElement 或 LineElement 的构造函数来构造类的实例,因此我们可以把
//ArrayElement,UniformElement 和 LineElement 定义为私有
private class ArrayElement(val contents: Array[String])
extends Element {
}
private class LineElement(s: String) extends ArrayElement(Array(s)) {
override def width = s.length
override def height = 1
}
private class UniformElement(ch: Char,
override val width: Int,
override val height: Int) extends Element {
private val line = ch.toString * width
def contents = Array.fill(height)(line)
}
//伴生对象提供的三个工厂方法
def elem(contents: Array[String]): Element =
new ArrayElement(contents)
def elem(chr: Char, width: Int, height: Int): Element =
new UniformElement(chr, width, height)
def elem(line: String): Element =
new LineElement(line)
}
8 Scala层级
8.1 Scala类的层级
在 Scala 中,所有的类都有一个公共的超类称为 Any,那么定义在 Any 中的方法就是共同的方法:它们可以被任何对象调用
Scala 还在层级的最底端定义了一些有趣的类,如Null 和 Nothing,为通用子类。像 Any 是所有其它类的超类一样,Nothing是所有其它类的子类一样
层级的顶端是类 Any,定义了包含下列的方法(虚线为隐式转换):
层级的顶端是类 Any,定义了包含下列的方法:
final def ==(that: Any): Boolean
final def !=(that: Any): Boolean
def equals(that: Any): Boolean
def hashCode: Int
def toString: String
由于所有的类都继承自 Any,因此 Scala 中的所有对象都可有==,!=,或 equals 来比较,使用##或 hashCode 来求 hash 值,使用 toString 转为字符串。Any 的==和!=定位为 fianl,因此不可以被子类重载,但由于 == 判断表达式会调用equals进行相等性比较,所以可以重写 equals 来达到修改==和!=的定义
与Java一样,如果两个对象相等,则所对应的hashCode也要相等,所以在重写equals时也要重写hashCode
一个好的散列函数通常倾向于“为不相等的对象产生不相等的散列码”,相等对象的hashCode一定要相同
根类 Any 有两个子类:AnyVal 和 AnyRef。AnyVal 是 Scala 里每个内建值类型的父类。有9个这样的值类型:Byte,Short,Char,Int,Long,Float,Double,Boolean 和 Unit。其中的前8个对应到 Java 的基本类型,它们的值在运行时表示成 Java 的类型。Scala 里这些类的实例都直接写成字面量,如,42 是 Int 的实例,’x’是 Char 的实例,false 是 Boolean 的实例。值类型都被定义为即是抽象的又是 final 的,所以不能使用 new 创造这些类的实例。
另一个值类,Unit,相当于 Java 的 void 类型;被用作不返回任何结果的方法的结果类型。 Unit 只有一个实例值,被写作().
这些值类型都支持常用的算术运行操作符(实质为方法),如,Int 有名为 + 和 * 的方法,Boolean 有名为||和&&的方法。值类型从Any类继承了toString、hashCode、equals等方法,所以可以直接通过值来调用:
scala> 42.toString
res1: java.lang.String = 42
scala> 42.hashCode
res2: Int = 42
scala> 42 equals 42
res3: Boolean = true
8种值类型之间是独立的,不互为子类,但它们可以进行隐式转换,如scala.Int可以自动转换为 scala.Long 类型。另外,如果在这些值类型上调用如min, max, until, to 和 abs 等这些方法时,会隐式转换相应的scala.runtime.Richxxx,如scala.Int转换为scala.runtime.RichInt,scala.Double转换为scala.runtime.RichDouble,再调用这些方法,因为这些方法是由相应Rich类提供的:
scala> 42 max 43
res0: Int = 43
scala> 42 min 43
res1: Int = 42
scala> 1 until 5
res2: scala.collection.immutable.Range = Range(1, 2, 3, 4)
scala> 1 to 5
res3: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5)
scala> 3.abs
res4: Int = 3
scala> (-3).abs
res5: Int = 3
类 Any 的另一个子类是类 AnyRef。这个是 Scala 里所有引用类的基类。AnyRef 实质上就是Java 中类 java.lang.Object 的别名。因此 Java 里写的类和 Scala 里写的都继承自 AnyRef。你可以认为 java.lang.Object 是 Java 平台上实现 AnyRef 的方式。因此,尽管你可以在 Java 平台上的 Scala 程序里交换使用 Object 和 AnyRef,推荐在任何地方都只使用 AnyRef
Scala 类与 Java 类不同在于它们除了继承了AnyRef,还继承自一个名为 ScalaObject 的特质trait,该特质仅供Scala内部使用,且只有一个$tag 方法
8.2 基本类型实现
Scala 的基本数据类型是如何实现的?实际上,Scala 与 Java 同样的方式存储整数Int:都占 32 位(4字节),这使得JVM 平台和与 Java 库的互操作性方面来说很重要。Scala的基本类型的标准的操作,如Int基本类型的加减乘除都有如Java中的int基本类型操作一样(虽然如Int等数据类型里的+被定义成了抽像方法)。然而,当整数Int需要被当作Java对象看待的时候,如在Int上调用 toString 方法或者把Int赋值给 Any 类型的变量时,Scala 会调用scala.runtime.BoxesRunTime.boxToInteger(int i)方法将Int转换为java.lang.Integer
// Java代码
boolean isEqual(int x,int y) {
return x == y;
}
System.out.println(isEqual(421,421)); // true
上面不会发生自动装箱,但下面isEqual 会将参数值转变为 java.lang.Integer:
// Java代码
boolean isEqual(Integer x, Integery) {
return x == y;
}
System.out.println(isEqual(421,421)); // false
Java中,因为在基本值类型上 == 表示的值是否相等,而在引用类型上 == 表示引用相等,而 Integer 是引用类型,所以结果是 false。这是展示了 Java 不是纯面向对象语言的一个方面。我们能清楚观察到原始类型和引用类型之间的差别。
但在Scala中,== 作用在基本类型或是引用类型上都是一样的,对值类型来说,自然的比较的是基本类型的值,而对于引用类型,== 被视为继承自 Object 的 equals 方法的别名,会调用equals方法来进行对象内容的比较:
scala>def isEqual(x:Int, y:Int) = x == y
isEqual:(Int,Int)Boolean
scala>isEqual(421,421)
res10:Boolean = true
scala>def isEqual(x:Any, y:Any) = x == y
isEqual:(Any,Any)Boolean
scala>isEqual(421,421)
res11:Boolean = true
scala>val x = "abcd".substring(2)
x:java.lang.String = cd
scala>valy="abcd".substring(2)
y:java.lang.String=cd
scala>x==y
res12:Boolean=true
上面示例结果为true,如果是在Java,则为false,此时需要使用equals进行比较再为true
在Scala中,由于 == 作用于对象时,会调用相应类的equals进行内容比较,如果就是想要对引用地址进行比较(看是否指向的是同一对象),则是要使用类AnyRef定义的eq方法,该方法就像Java里对于引用类型的 == 那样:
scala>val x = new String("abc")
x:java.lang.String = abc
scala>val y = new String("abc")
y:java.lang.String = abc
scala>x == y
res13:Boolean = true
scala>x eq y
res14:Boolean = false
scala>x ne y
res15:Boolean = true
在Scala中可以:
scala> null.eq(null)
res8: Boolean = true
因为null为自动转换为Null对象。但在Java中只能 null == null 来代替
8.3 Null、Nothing
在上面的类层次图中,有scala.Null 和 scala.Nothing两个类,它们是一种特殊的类型,为了某些情况下的统一处理
Null类是null引用对象的类型,它是每个引用类型(即继承自AnyRef的类)的子类,但它不是值类型,所以不能将null赋值给值变量,下面表达式编译会出错:
scala>val i: Int = null
Nothing类型在Scala的类层级的最底端,因此它是任何其他类型(包括AnyVal值类型)的子类型,然而这个类型没有任何实例(也就是没有任何值对应 Nothing 类型),通常用来表示程序不正常的终止时无返回值。如 Scala 的标准库中的 Predef 对象有一个 error 方法,如下定义:
def error(message:String): Nothing = throw
new RuntimeException(message)
error 的返回类型是 Nothing,告诉用户方法不是正常返回的(代之以抛出了异常)。因为 Nothing是任何其它类型的子类,你可以非常灵活的使用像 error 这样的方法。例如:
def divide(x: Int, y: Int): Int =
if (y != 0) x / y
else error("can't divide by zero")
def main(args: Array[String]) {
divide(1, 0)
}
如果被除数为0时,则会抛异常:
Exception in thread "main" java.lang.RuntimeException: can't divide by zero
at scala.sys.package$.error(package.scala:27)
at scala.Predef$.error(Predef.scala:139)
at scalatest.t$.divide(T.scala:6)
at scalatest.t$.main(T.scala:9)
at scalatest.t.main(T.scala)
所以这里Nothing完全是为了统一返回Int,为了能正常编译,否则else分支则一定要返回一个Int的值
8.4 Any类
Scala里,每个类都继承自通用的名为Any的超类。因为所有的类都是Any的子类,所以定义在Any中的方法就是“共同的”方法:它们可以被任何对象调用。Scala还在层级的底端定义了一些类,如Null和Nothing,扮演通用的子类。即,Any是所有其他类的超类,Nothing是所有其他类的子类。
层级的顶端是Any类,定义了下列方法:
final def ==(that: Any): Booleanfinal def !=(that: Any): Booleandef equals(that: Any): Booleandef hashCode: Intdef toString: String
解释:因为每个类都继承自Any,所以Scala程序里的每个对象都能用==、!=或equals比较,用hashCode做散列,以及用toString格式化。Any类里的等号和不等号方法被声明为final,因此他们不能再子类里重写。实际上,==总是与equals相同,!=总是与equeal相反。因此,独立的类可以通过重写equals方法改变==或!=的意义。
根类Any有两个子类:AnyVal和AnyRef。
AnyVal是Scala里每个内建值类的父类。有9个这样的值类:Byte、Short、Char、Int、Long、Float、Double、Boolean和Unit。其中的前8个都对应到Java的基本类型。这些值类都被定义为既是抽象的又是final的,不能使用new创造这些类的实例。Unit被用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。
值类的空间是平坦的;所有的值类都是scala.AnyVal的子类型,但是它们不是其他类的子类。但是不同的值类类型之间可以隐式地互相转换。例如,需要的时候,类scala.Int的实例可以通过隐式转换放宽到类scala.Long的实例;Int支持min、max、until、to、abs等操作,其实是从类Int隐式转换到scala.runtime.RichInt的。
AnyRef类是Scala里所有引用类(reference class)的基类。它其实是Java平台上java.lang.Object类的别名,基本上AnyRef=Object。
Scala类与Java类的不同在于它们还继承自一个名为ScalaObject的特别记号特质。是想要通过ScalaObject包含的Scala编译器定义和实现的方法让Scala程序的执行更高效。
8.5 底层类型
scala.Null和scala.Nothing是用统一的方式处理Scala面向对象类型系统的某些“边界情况”的特殊类型。
Null类是null引用对象的类型,它是每个引用类(继承自AnyRef的类)的子类。Null不兼容值类型。
Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型。然而,根本没有这个类型的任何值。Nothing的一个用处是它标明了程序不正常的终止。
例如:
def error(message: String): Nothing = throw new RuntimeException(message) def divide(x: Int, y: Int): Int = if(y != 0) x / y else error("Can't divide by zero")上面的例子中,error的返回类型是Nothing,告诉用户,方法不是正常返回的。因为Nothing的任何其他类型的子类,所以你可以非常灵活地使用像error这样的方法。
9 特质trait
9.1 trait基本概念
特质是Scala里代码复用的基础单元。特质相当于Java中的Interface(更像是Abstract抽象类),但又是有区别的:特质封装了方法和字段的定义,和Java中的Interface相比,它的方法可以有实现,这一点有点和抽象类定义类似。但和类继承不同的是,Scala 中类继承为单一继承,也就是说子类只能有一个父类,但一个类可以混入多个trait,这些 trait 定义的成员变量和方法也就变成了该类的成员变量和方法,由此可以看出 trait 集合了 interface 和抽象类的优点,同时又没有破坏单一继承的原则
特质的定义除了使用关键字 trait 之外,与类定义无异:
trait Philosophical {
def philosophize() {
println("I consume memeory, therefor I am!")
}
}
这个 trait 名为 Philosophical。它没有声明基类,因此和类一样,有个缺省的基类 AnyRef。
一旦定义好 trait,就可以使用 extends 或 with将它混入到一个类中,例如:
class Frog extends Philosophical {
override def toString = "gree"
}
注意混入特质trait与其他语言的多继承是有区别的,可参考为什么不是传统的多继承章节
你可以使用extends关键字混入某个特质,混入时除了将特质中的所有方法继承过来以外,也隐式地将特质的超类也继承过来,这与继承某个类是一样的。如这里类 Frog 是 AnyRef(也是Philosophical的超类)的子类并混入了Philosophical。从特质继承的方法可以像从超类继承的方法那样使用。样例如下:
scala> val frog = new Frog
frog: Frog = green
scala> frog.philosophize()
I consume memory, therefore I am!
特质同样也是类型。以下是把 Philosophical
用作类型的例子:
scala> val phil: Philosophical
= frog
phil: Philosophical = green
scala> phil.philosophize()
I consume memory, therefore I am!
phil变量的类型是 Philosophical特质类型。因此,变量 phil 可以被初始化为任何混入了Philosophical 特质的类的对象。
如果想把一个特质混入到一个已经明确使用extends继承某个类的类中时,可以使用with来进行混入,因为定义类时只能出现一次extends:
class Animal
class Frog extends Animal with Philosophical
{
override def toString = "green"
}
如果有多个特质需要混入,则加在with后面即可。下面是把 Philosophical 和 HasLegs 都混入到 Frog 类中:
class Animal
trait HasLegs
class Frog extends Animal with Philosophical
with HasLegs {
override def toString = "green"
}
另外 Frog 类还可以重写特质中的philosophize 方法,语法与重写超类中的方法是一样的:
class Animal
class Frog extends Animal with Philosophical {
override def toString = "green" //重写超类Any中的方法
override def philosophize() {//重写特质中的方法
println("It ain't easy being " + toString + "!")
}
}
在使用with时,一定要与extends一起使用,即不可单独使用with;如果是继承class,只可使用extends,不可使用with
特质就像带有具体方法的Java接口。你可以用特质来定义做任何类定义能做的事,但除了以下两点外基本是一样的:
第一点:特质不允许带类参数,即传递给类的主构造器的参数。换句话说,你可以这样定义类:
class Point(x: Int, y: Int)
但不能定义这样的特质:
trait NoPoint(x: Int, y: Int) // 编译不过
第二点:可以请参见后面章节:特质作为可堆叠改变
当同时使用extends 和 with时,要求extends继承类(如果是extends的某个特质,则在继承树中向上找到最顶层的类class)与with混入的特质继承体系中最顶层class相同或是其子类(with混入的trait的父类是extends继承的类或trait父类的子类),trait的继承类会限定它混入的范围:
class A {}
trait B extends A {}// extends A 会限制B特质只能混入到A的子类中
class C {}
trait D extends C {}//
class E extends D with B {//编译报错:![]()
}
如果将 class C {} 修改为 class C extends B {} 则可以编译通过,因为此时E是A的子类了
9.2 接口的胖与瘦
这里的瘦与胖是指接口(Java中的Interface)或特质(Scala中的trait)中的方法多少,方法多的称为胖接口,少的称为瘦接口
设计成瘦接口还是胖接口的设计需要用户来权衡。胖接口有更多的方法,对于调用者来说更便捷。而瘦接口有较少的方法,侧对于实现者来说更简单,而且调用瘦接口的客户因此要写更多的代码。
Java中的接口一般都设计的过瘦,比如CharSequence接口,它是String类的父接口,仅提供了以下4个接口:
public interface CharSequence {
int length();
char charAt(int index);
CharSequence subSequence(int start, int end);
public String toString();
}
如果使用Scala语言来描述这个接口的话,如下:
trait CharSequence {
def charAt(index: Int): Char
def length: Int
def subSequence(start: Int, end: Int): CharSequence
def toString(): String
}
从设计来说,虽然可以将String中的很大一部分方法移到CharSequence接口中去,但Java中的CharSequenc接口仅提供这4个接口,因为大部分方法移到接口之后,任何需要CharSequence接口的类都要实现所有的方法,这样给实现者造成负担,但在Java中可以通过Interface+Abstract来减少没必要的实。而在Scala中,特质trait很好的解决了这个问题,因为trait中可以有方法的实现,这样可以在特质中提供一些默认的实现,这样就可以减少因混入特质需要实现很多方法的负担,所以在Scala中设计胖的接口是很方便的
根据设计原则,一般不建议设计大的接口,因为这样可能违反了“单一职责原则”,一般会将大的接口拆分成多个接口,这样子类在实现或混入时就可以选择只需要实现的接口即可
正是因为Scala中的trait特质具有Java中的接口Interface与抽像类Abstract相结合的特点,所以在Scala中更推崇胖的接口,在设计时只需要简单的定义一个具有少量抽象方法的特质,然后定义一些潜在的大量具体方法,这样在混入到某个类后,只需实现少量的抽像方法,而同时又拥有了大量的具体实现方法,这使得在同一特质中很容易就做到了胖瘦相结合,即提供少量的抽象及大量的具体潜在的功能
9.3 特质作为可堆叠改变
前面一节讲的是如何使用特质triat简单快捷的创建胖接口(虽然在在Java中麻烦点,但可以借助于Interface + Abstract来实现),这一节讲特质的另一个作用:为类提供可堆叠的改变
类class和特质trait的另一个区别在于:不论在类class的哪个角落,class中的super 是静态绑定的,即在class定义时,类中出现的super就已经确定具体指向的是哪个父类(如果直接父类没有则逐级向顶层找,直到找到要调用的方法或成员);而在特质trait定义时,特质中出现的 super是不能全部确定的(有一部分是可以确定下来的,比如继承树底层些节点中的super可以确定,但往继承树顶层方向节点中的super就可能不能确定,因为这些节点可能连接左侧特质),这要等到特质混入时才能确定super指的是谁,这与混入的顺序以及这些混入特质之间的继承关系也有关,具体规则则请参考后面章节所总结的
假设下面要实现一个简单的队列,其抽象接口如下:
//队列抽象
abstract class IntQueue {
def get(): Int
def put(x: Int)
}
下面这个是最基础的实现类,但可以使用Trait特质来扩展它,扩展请看后面的三个特质:
import scala.collection.mutable.ArrayBuffer
//队列基本实现
class BasicIntQueue extends IntQueue {
private val buf = new ArrayBuffer[Int]
def get() = buf.remove(0) //出队
def put(x: Int) { buf += x } //入队
}
scala> val queue = new BasicIntQueue
queue: BasicIntQueue = BasicIntQueue@24655f
scala> queue.put(10)
scala> queue.put(20)
scala> queue.get()
res9: Int = 10
上面是一个队列的最基本实现,你可以定义如下的特质混入后对其基础实现BasicIntQueue进行扩展:
1) Doubling: 把所有放入到队列的元素加倍
2) Incrementing: 把所有放入到队列的元素加一
3) Filtering: 负数不能放入队列中
第一种做法就是直接修改BasicIntQueue代码,将这三个功能代码逻辑附加到put方法中(实际上可以通过装饰设计模式来解决)。这可以通过trait来解决这个问题,将这三个功能分别封装在各有自的trait中,需要几个功能时就混入几个,也就是说这三个操作是可以叠加的(有点像装饰模式),你可以通过这三个基本操作的任意不同组合和基础队列类BasicIntQueue “混合”,从而可以得到你具有新功能的队列。
由于Java I/O库需要很多性能的各种组合,如果这些性能都是用继承的方法实现的,那么每一种组合都需要一个类,这样就会造成大量的类出现。而如果采用装饰模式,那么类的数目就会人大减少。Java IO装饰模式示例:
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(new File("xxx")),"GBK"));
先看看特质Doubling实现:
//特质继承自IntQueue,这表示该特质只能混入到从IntQueue类或其子类继承的类中,即特质定义中extends限定了混入的范围
trait Doubling extends IntQueue {//该特质在原BasicIntQueue的基础上对元素加倍
abstract override def put(x: Int) { super.put(2 * x) }//在特质中可以使用“super”前缀来调用超类抽象方法(在类中是不行的,包括Java),但一定要在方法定义前加上“abstract override”,并且方法名还要求与调用的抽象方法名一样,如这里都是put;注:虽然方法前有abstract关键字,但特质中的abstract override方法还是实现方法,因为有了方法体,只是super要在混入时才能确定
}
abstract override:意义为扩展与重写父类同名方法,override是重写,并且使用“super”调用父类同名方法这属于方法的扩展
scala> class MyQueue extends
BasicIntQueue with Doubling //混入(扩展)翻倍功能,此时(混入时)特质Doubling中的super能确定为BasicIntQueue,所以super.put实质是BasicIntQueue.put,且在调用该方法前将元素值翻倍,然后向上链式传递调用,即达到“叠加修改”的效果
defined class MyQueue
scala> val queue = new MyQueue
queue: MyQueue = MyQueue@91f017
scala> queue.put(10)
scala> queue.get()
res12: Int = 20 //元素值已翻倍
上面MyQueue类没有定义一行代码,只是简单的继承一个类BasicIntQueue及混入一个特质Doubling,这种情况下,你完全可以在new实例化时混入,而不是在定义时,如上面可以改写成:
scala> val queue = new BasicIntQueue
with Doubling
queue: BasicIntQueue with Doubling = $anon$1@5fa12d
scala> queue.put(10)
scala> queue.get()
res14: Int = 20
下面再来扩展实现另外两个特质trait:
trait Incrementing extends IntQueue {//把所有放入到队列的元素加一
abstract override def put(x: Int) { super.put(x + 1) } //扩展与重写父类的功能
}
trait Filtering extends IntQueue {//负数不能放入队列中
abstract override def put(x: Int) {//扩展与重写父类的功能
if (x >= 0) super.put(x)
}
}
有了这些不同功能的特质,此时如果想实现这样一个队列:既能够过滤负数又对每个进队列的元素加一:
scala> val queue = (new BasicIntQueue
with Incrementing with Filtering) //注意混入的顺序非常重要:具体规则请参考后面特质研究章节。这里会先调用Filtering.put方法,这会过滤掉负数,即如果是负数则不能放入队列中。Incrementing的put第二个被调用,这会对将要入队的元素进行加一操作。最后才是BasicIntQueue的put方法调用,该方法才会真正将元素放入到队列中
queue: BasicIntQueue with Incrementing with Filtering...
scala> queue.put(-1); queue.put(0);
queue.put(1) // -1会被过滤掉,不会放入队列中,并且放入队列中的元素为都会被加一
scala> queue.get()
res15: Int = 1
scala> queue.get()
res16: Int = 2
如果你逆转特质的混入次序,那么元素首先会加 1, 然后如果仍然是负的才会被抛弃:
scala> val queue = (new BasicIntQueue
with Filtering with Incrementing) //先加一,再过滤
queue: BasicIntQueue with Filtering with Incrementing...
scala> queue.put(-1);queue.put(0); queue.put(1)
scala> queue.get()
res17: Int = 0 //从这里可以看出负数也被放进来了,原因就是先进行加1操作了
scala> queue.get()
res18: Int = 1
scala> queue.get()
res19: Int = 2
总而言之,这种风格的代码能带给你极大的灵活性。通过以不同的组合和次序混入不同的特质时,可以创建也具有不同功能的队列类,或者干脆在new实例化时混入,这样都不需要定义类就可以创建出具有不同功能的队列对象
9.4 为什么不是传统的多继承
多继承即一个子类可以有多个父类,它继承了多个父类的特性。Java不支持类之间的多继承(只有接口能继承多个,但没有实现),即一个子类只能有一个父类;而C++支持多继承
通过特质可以实现多继承,但这种多继承不同于传统多继承。由于Java中没有多继承,就拿C++来说吧。C++中没有super,多继承时如果想要调用父类都有的同名方法时,取而代之的是“基类::同名方法()”方式,super就相当于这里的基类,很明显在类定义时就已确定下来,并且这些父类同名方法中只会有一个被调用,其它同名方法不会都被调用,除非将“基类::同名方法()”中的基类更名后再调用,但在Scala中,你可以做到只调用最右侧特质中的某个方法,只要这个方法在其他特质都存在,再结合super.编程形成链式调用,这可以参考前面的特质作为可堆叠改变章节,而且这种链接调用不只是发生在不同特质的同名方法间,而且不同方法间也可以,并且调用的顺序都是可以通过混入的顺序来改变的,这非常灵活
当你使用 new 实例化一个类的时候, Scala 把这个类和所有它继承的类还有它的特质以线性(linear)的次序放在一起。然后,当你在其中的一个类中调用super,被调用的方法就是方法链的下一节,形成方法的链式调用而产生堆叠行为,即某个方法(即最后一层被调用的方法,也即设计中最基础的实现方法,如上节队列中BasicIntQueue基础类中的put方法)在链式的一层层调用中功能得到了扩展。
Scala 的线性化的主要属性可以用下面的例子演示:假设你有一个类 Cat,继承自超类 Animal 以及两个特质 Furry 和 FourLegged。 FourLegged 又扩展了另一个特质 HasLegs:
class Animal
trait Furry extends Animal
trait HasLegs extends Animal
trait FourLegged extends HasLegs
class Cat extends Animal with Furry with FourLegged
白色箭头表明继承,箭头指向的是父类;黑箭头表明了线性化的次序,箭头指向 super的方向,即混入特质后调用super的走向
上面的继承关系图是静态的,这根据类与特质定义的静态关系就很容易就画出来了,上面图中的白色箭头即是;上面黑色表明了super的指向

Cat 的线性化次序以下列的从后向前的顺序计算。 Cat 线性化的最后部分是它的超类, Animal 的线性化。这个线性化被无损的复制过来。(这些类型每一个的线性化次序展示在上面所列表格 12.1 中)。因为 Animal 没有显式扩展超类或混入任何超特质,因此它缺省地扩展了 AnyRef,并随之扩展了Any。因此, Animal 的线性化, 看上去是这样的:
![]()
倒数第二部分是第一个混入,特质 Furry 的线性化,但是所有已经在 Animal 的线性化之中的类现在被排除在外,因此 Cat 的线性化中每个类仅出现 1 次。结果是:
![]()
它之前是 FourLegged 的线性化,任何已被复制到线性化中的超类及第一个混入再次被排除在外:
![]()
最后, Cat 线性化的第一个类是 Cat 自己:
![]()
当这些类和特质中的任何一个通过 super 调用了方法,那么被调用的实现将是它线性化的右侧的第一个实现。
9.5 特质研究
特质是抽象的,是不能直接实例化的:
trait C {
def p = { println("C.p()") }
}
new C().p //编译出错:trait C is abstract; cannot be instantiated
abstract override方法在重写时,也还要加上“abstract override”:
abstract class A {
def f
}
trait B extends A {
abstract override def f = { println("B.p()"); super.f }
}
trait C extends B {
//这里的abstract override关键字不能省略,重写时还得原样加上
abstract override def f = { println("B.p()"); }
}
具有“abstract override”方法的特质(B)在混入时需要定义的类(C)使用extends关键字从一个实现了该方法的类(Basic)继承,一般该类(Basic)的父类(A)与特质(B)的父类(A)是同一个类(A):
abstract class A {
def f
}
class Basic extends A{
//实现抽象方法在时可以省略掉override关键字
def f = { println("Basic.f()"); }
}
trait B extends A {
abstract override def f = { println("B.p()"); }
}
class C extends Basic with B
如果某个特质(B)继承(包括直接或间接)了某个类(A),则这表示该特质(B)只能混入到从其父类(A)继承的类(C)中:
abstract class A {
def f
}
trait B extends A {
//f方法没有通过 super.来调用,所以前面就没有abstract override关键字加以定义,但在B继承体系里找会找到C中f方法的实现,所以这里的f最终调用C.f()
def p = { println("B.p()"); f }
}
class C extends A with B{
def f = { println("C.f()") }
}
new C().p//B.p()->C.f()
或混入到从其父类的子类(A1)继承的类(C)中:
abstract class A {
def f
}
trait B extends A {
def p = { println("B.p()"); f }
}
class A1 extends A {
def f = { println("A1.f()") }
}
class C extends A1 with B
new C().p//B.p()->A1.f()
如果某个特质(B)继承某个抽象类(A),则这个特质(B)是不需要实现其中的抽象方法(f)的(这像Java中的接口继承其他接口一样):
abstract class A {
def f
}
trait B extends A {}
但如果将B定义成class时,则编译会出错,除非也将其定义为抽象类:
abstract class A {
def f
}
class B extends A {//编译出错:class B needs to be abstract, since method f in class A of type => Unit is not defined
}
“abstract override”关键字只能用在特质中,不能用在类中:
abstract class A {
def f
}
class B extends A {
abstract override def f = { super.f } //编译错误:‘abstract override’ modifier only allowed for members of traits
}
与Java一样,在类class中不能使用“super.”明确的去调用父类的抽象方法,只能直接调用(即可以省略“super.”后直接调用抽象方法):
abstract class A {
def f
}
abstract class B extends A {
def p = { f }
}
但在Scala中的trait中可以通过“super.”去调用父类的抽象方法(也可以直接调用)
abstract class A {
def f
}
trait B extends A {
//A.f()抽象方法的实现
abstract override def f = { println("B.f()");super.f } //通过“super.”前缀调用,super.f调用父类抽象方法
def p = { println("B.p()");f }//直接调用。调用实现方法,这里为 B.f()
}
class Basic extends A{
def f = {println("Basic.f()")}
}
class C extends Basic with B
new C().p //B.p()->B.f()->Basic.f()
是否带“super.”前缀方法调用区别:
abstract class A {
def f
}
trait B extends A {
abstract override def f = { println("B.f()"); super.f}
}
trait C extends B {
//无“super.”前缀的调用f() 会从继承树最底层向上逐级找实现方法,
//而super.f()则只会从父类延着继承树向上逐级找相应方法
def p = { println("C.p()"); f }//注:如果这里是 super.f() 会调用父类的B.f(),这里的f()则会调用重写后的方法即D.f()
}
trait D extends C {
//重写了B.f(),所以上面 C.p()方法中的f将会调用这个重写的方法
abstract override def f = { println("D.f()"); super.f}
}
class E extends A {
def f = { println("E.f()"); }
}
class F extends E with D
new F().p //C.p()->D.f()->B.f()->E.f()
如果将C.p方法修改成如下:
def p = { println("C.p()"); super.f }
则
new F().p //C.p()->B.f()->E.f()
如果混入的特质(或其继承树)中含有“abstract override”方法时,类(D)不能直接混入这个特质(B):
abstract class A {
def f
}
trait B extends A {
abstract override def f = { super.f }
}
class D extends B //编译错误: class D needs to be a mixin, since method f in trait B of type => Unit is marked ‘abstract’ and ‘override’, but no concrete implementation could be found in a base class
而是要先extends一个现过抽象方法(A.f)基础类(Basic),然后再混入特质(B)编译才可以通过:
abstract class A {
def f
}
trait B extends A {
abstract override def f = { super.f }
}
class Basic extends A {
def f = {}//实现A.f()
}
class D extends Basic with B
特质中方法体里没通过“super.”调用父类的抽象方法时,也是可以定义成“abstract override”类型的方法的(如下面的B.f(),方法体里就没有super.f):
abstract class A {
def f
}
trait B extends A {
abstract override def f = { } // 去掉了super.f 调用也可以定义成“abstract override”
}
abstract class ABCD {
def f
}
trait A1 extends ABCD {
/*
* 虽然前面有个abstract,但还是属于ABCD.f的一个实现
*/
// abstract override def f = { println("A1.f()"); super.f }
/*
* 如果A1、A3里的 f() 方法都注释掉时,这里的 f 实质上调用的是
* ABCD.f,即为抽象方法,所以此时也会调头去调用特质B2.f,而不需
* 要写成 super.f,这样反而编译不能通过
*
* 如果将A1、A3里的 f()方法定义都打开,则这里的f 会调用特质A3中自己
* 已有的实现,即 A3.f ,如果A3.f被注掉了,则会调用 A1.f 实现方法,
* 如果都没有,则会向上找,即找到ABCD.f抽象方法,由于是抽象的,所以
* 调头去调用B2中的f实现,自然会找到B2.f实现方法 。
*/
def p = { println("A1.p()"); f }
}
trait A2 extends A1 {
override def p = { println("A2.p()"); super.p }
}
trait A3 extends A2 {
override def p = { println("A3.p()"); super.p }
//可以重写 A1.f 实现方法
abstract override def f = { println("A3.f()"); super.f }
}
class Basic extends ABCD {
def f = { println("Basic.f()") }
}
class D extends Basic with B2 with A3 {
override def p = { println("D.p()"); super.p }
}
trait B1 extends ABCD {
//方法中没有super.f,也可以加上 abstract override,并且这条定义语句不能注掉
//否则下面的p方法定义编译出错
abstract override def f = { println("B1.f()"); }
def p = { println("B1.p()"); super.f }
}
trait B2 extends B1 {
override def p = { println("B2.p()"); super.p }
//注:下面的super不能省略,否则又会去调用 D.p() ,这样会产生死循环
//重写,将A3.f()的调用接过来
abstract override def f = { println("B2.f()"); super.p }
}
new D().p
D.p()
A3.p()
A2.p()
A1.p()
A3.f()
B2.f()
B1.p()
Basic.f()
不管是否使用“super”调用,都会先在本继承体系树找(不带“super”前缀调用会从继承体系树最底层逐级向上查找;带“super”前缀方式会从调用所在层逐级向上查找),如果本继承体系树中找不到时,会自动跳转到其下一个特质或类的继承树中进行查找,所以不管调用的是实现方法还是抽象方法,都是有可能跳转其他特质或类所在的继承体系树中继承查找:
class A {
def f = {println("A.f()");}
}
trait B extends A {
//根据线性化图,这里的f调用会跳转到Basic.f()
def p = {println("B.p()");f}
}
class Basic extends A {
override def f = { println("Basic.f()");super.f}
}
class C extends Basic with B
new C().p //B.p()->Basic.f()->A.f()
class A {
override def toString() = { println("A"); super.toString();}
}
trait B {
override def toString() = { println("B"); super.toString();}
}
trait C {
override def toString() = { println("C"); super.toString();}
}
//上面B、C没有确定指定继承某个类,所以对混入范围没有限制,实质上是有的,因为没有明确指定其继承类时,默认会继承自AnyRef——相当于Java中的Object,所以这些特质只能混入到继承了AnyRef类或其子类的类中,显然下面的D类是符合这一规则的
class D extends A with B with C{
override def toString() = { println("D"); super.toString();}
}
new D().toString()//D->C->B->A
整体继承关系线路图连线规则:
1、图中每一个节点(类class和特质trait)都需要遍历到,所以线性化需要把每个节点都串起来,且每个节点只串连一次
2、先将每个混入的特质所定义时的静态继承关系图画出,以及所继承的类所在的静态继承关系图画出(类与特质在定义时的关系图是静态的,也是显示的,在画整体继承关系图中第一步就需要明确画出来)
3、除了类与特质在定义时就已确定的静态继承关系外,在特质混入时,就会隐式地将混入的每个特质及继承类所在的静态继承树连起来(如何将一个继承树连接到另一继承树,请看后面具体隐式线连接规则),这样就会形成最终的继承关系图,super就是按这个最终的关系图来动态切换的,所以第二步就是画这个隐式线
4、隐式线画法就是将各个混入的特质各自所在的继承关系图连接起来,连接的方法是:
a) 从定义的类本身开始,类本身作为整个继承体系树中的最底层节点,将它连接到右边混入(在有混入特质的情况下)的某个特质(不一定是最右侧的特质,因为混入的特质之间可能有继承关系)下面
b) 如果混入的特质之间没有父子关系,从最右侧混入的特质开始,在其继承体系树中,从最顶层(除开Object、Any、AnyRef隐式超类外)类或特质开始,找到第一个不是左侧混入特质或继承类的超类的节点(因为连接时不能违背定义时确定的静态继承关系,如定义时A是B的父类,在混入时就不能将A连接到B类的下面),然后将这个特质或类连接到左侧特质或类的下面;右侧的这个特质连好后,再处理左侧的,直到完成最后一个继承的类或混入的特质
c) 如果混入的特质间在定义时就有继承关系,则就不一定从最右侧混入的特质开始,此时与混入的先后顺序没有关系,即右侧不一定先遍历,而是谁是子类谁先遍历;如果左右特质或类没有父子关系,则依然是右侧先遍历
5、定义时就已确定的继承线路与这种经上面规则画出的隐式线一起组成了最终的整体继承关系图。方法的调用不管是否使用“super”调用,都会先在本继承体系树找:不带“super”前缀调用会从继承体系树最底层逐级向上查找;带“super”前缀方式会从调用所在层逐级向上查找。如果节点本身所在的继承体系树中找不到时,会自动跳转到下一个特质或类所在的继承树中进行查找,所以不管调用的是实现方法还是抽象方法,都是有可能跳转其他特质或类所在的继承体系树中继承查找的:
上面的画法实质可以分为以下三步:
第一步:画出类或特质定义的静态继承线1、2、3、6、7(当然包括混入的线4、5),即图中红色线
第二步:画出隐式连接线,如果混入的特质之间有明确的继承关系则直接画出(图中蓝色线),如下面的第2、3、4图中的蓝线;如果没有明确的继承关系,则从右侧继承树最顶层(除开Object、Any、AnyRef隐式超类外)类或特质开始,找到第一个不是左侧混入特质或继承类的父类的节点(特质或类),然后将这个特质或类连接到左侧特质或类的下面,如下第一幅图中的8号灰线与第五幅图中的灰线都是根据该规则所画出来的(图中的灰色线)注:有的混入关系很简单,蓝色线与灰色线就可以没有,如下面的第6、7图
第三步:然后根据每个节点都要被遍历到的原则,即可画出最终的线性化继承图,如每个图中的绿色线路即最终的线性化继承图:

第3个图所对应的源码:
class A {
def f = { println("A") }
}
trait B extends A {
override def f = { println("B"); super.f }
}
trait D extends B{
override def f = { println("D"); super.f }
}
trait C extends A with B with D {
override def f = { println("C"); super.f }
}
class E extends A with C with D {
override def f = { println("E"); super.f }
}
abstract class A {
def f
}
class B extends A{
def f = { println("B.f()"); }
}
trait C extends A {
abstract override def f = { println("C.p()"); }
}
class D extends B with C
abstract class A {
def f
}
trait B extends A {
def p = { println("B.p()"); f }
}
class C extends A with B{
def f = { println("C.f()") }
}
10 包、访问修饰符
10.1 包
与Java一样,未使用package指定包名时,它们存在于“未命名”的包中,或是缺省包中
在Scala将代码定义到某个包中有两种方式:
第一种:与 Java 一样,在文件的头定义包名,这种方法就后续所有代码都放在该报中。 比如:
package bobsrockets.navigation
class Navigator
第二种,使用嵌套结构来定义,这样一个源文件可以属于不同的包空间
package bobsrockets {
package navigation {
// 在bobsrockets.navigation包中
class Navigator
package tests {
// 在bobsrockets.navigation.tests包中
class NavigatorSuite
}
}
}
由于没有东西直接放在bobsrockets包下面,所以上面的嵌套也可以写成这样:
package bobsrockets.navigation {
// 在bobsrockets.navigation包里
class Navigator
package tests {
// 在bobsrockets.navigation.tests包里
class NavigatorSuite
}
}
第三种,将第一种与第二种结合起来:
package com
package bobsrockets.navigation {
// 在com.bobsrockets.navigation包里
class Navigator
package tests {
// 在com.bobsrockets.navigation.tests包里
class NavigatorSuite
}
}
与Java不一样的是,Java中的包与包之间只有层级关系,一个包访问另一包里的定义类时,需要包的全路径,即使它们之间有父子关系,所以Java包与包的关系是没有什么意义的,而Scala中的包的父子关系是嵌套关系:
package bobsrockets {
package navigation {
class Navigator{
//可以直接访问外层包下的定义,所以可以省略bobsrockets包前缀
new launch.Booster
}
}
package launch {
class Booster {
// 不用写bobsrockets.navigation.Navigator
val nav = new navigation.Navigator
}
}
}
但这种嵌套有时会隐藏掉其他同名包:
package launch {
class Booster3
}
package bobsrockets {
package navigation {
package launch {
class Booster1
}
class MissionControl {
val booster1 = new launch.Booster1
val booster2 = new bobsrockets.launch.Booster2
//Booster3访问时,就不能使用launch.Booster3了,因为只写launch时
//,就会误以为是bobsrockets.navigation.launch,所以要使用_root_
//来跳出嵌套
val booster3 = new _root_.launch.Booster3
}
}
package launch {
class Booster2
}
}
_root_ 是所有顶层包的前缀,即所有顶层包都属于_root_ 包的子包(注:默认包不属于_root_包,所以不能直接通过_root_来访问默认包中的类),如上面的_root_.launch、_root_.bobsrockets
10.2 包的导入
package bobsdelights
abstract class Fruit(
val name: String,
val color: String)
object Fruits {
object Apple extends Fruit("apple", "red")
object Orange extends Fruit("orange", "orange")
object Pear extends Fruit("pear", "yellowish")
val menu = List(Apple, Orange, Pear)
}
下面访问上面bobsdelights包中的成员:
// 访问Fruit
import bobsdelights.Fruit
// 访问bobsdelights的所有成员,所Java中的bobsdelights.*相同
import bobsdelights._
// 访问Fruits的所有成员,与Java中的静态字段引用一样
import bobsdelights.Fruits._ //这样就可以直接访问Fruits中的成员:Apple、Orange、Pear、menu
Scala 中的import可以出现在任何地方,并且还可以将某个实例(fruit)的成员导入进来后以简便的方式来访问其成员(name、color):
class T2 {
import bobsdelights.Fruit //
def showFruit(fruit: Fruit) {
import fruit._ //注意这里的fruit是对象,而非类
//由于上面使用 fruit._ ,所以下面的name就相当于fruit.name,color相当于fruit.color,即可以省略前缀 fruit.
println(name + "s are " + color)
}
}
Scala中还可以只导入包名(Java不可以),但访问这个包下的定义时,需要加上这个包名前缀:
import java.util.regex
class AStarB {
// 访问java.util.regex.Pattern
val pat = regex.Pattern.compile("a*b")
}
Scala中import比Java更为灵活,主要区别:
1、import可以出现在任何地方
2、除了可以import一个类之外,还可以import一个对象(包括伴生对象),以及某个包名
3、可以重命名或隐藏一些被导入的东西
Scala中的import可以重命名或隐藏成员,这可以通过在import成员的对象后面加上括号来做到:
import bobsdelights.Fruits
//只导入对象 Fruits 的 Apple 和 Orange 成员
import Fruits.{Apple, Orange}
/*
* 从对象 Fruits 导入了 Apple 和 Orange 两个成员,并将 Apple 对象重命名为 McIntosh。因
* 此这个对象可以用 Fruits.Apple 或 McIntosh 访问。重命名子句的格式是“<原始名> => <新名>”
*/
import Fruits.{Apple => McIntosh, Orange}
//以 SDate 的名字导入了 SQL 的日期类java.sql.Date,这样的话如果再导入java.util.Date后,
//就可以使用SDate来引用SQL中的日期类,而使用原名Date来引用util中的普通日期类,这样的话
//同时导入java.sql.Date与java.sql.Date后,还是可以区分开来
import java.sql.{Date => SDate}
//导入java.sql包,并且将sql包名重命名为 S,这样就可以写在S.Date来引用java.sql.Date类了
import java.{sql => S}
//导入对象 Fruits 的所有成员,与 import Fruits._同义
import Fruits.{_}
//导入Fruits 对象所有成员,并重命名 Apple 为 McIntosh
import Fruits.{Apple => McIntosh, _}
//除了Pear之外Fruits的所有成员都导入。“<原始名> => _”格式的子句会排除掉<原始名>的东西,把某样东西重命名为‘_’就是表示把它隐藏掉;而第二个‘_’则是除了前面排除的东西外导入所有的东西,注:当使用“<原始名> => _”与‘_’进行排除时,‘_’要放在最后
import Fruits.{Pear => _, _}
其实上面的导入语句相当以下两句:
import Fruits._ //先导入
import Fruits.{Pear => _} //再排除
“<原始名> => _”为排除的意思,排除是很有用的,例如同时导入了java.sql._与java.util._后,如果使用 Date 就会引起混淆,此时需要排除没用到的即可:
import java.util._
//排除java.sql.Array,否则下面args: Array[String]会报错,Array要是scala包中的Array类
//排除java.sql.Date, 否则下面的new Date()也会报错,因为java.util中也会有Date类
import java.sql.{ Array => _, Date => _, _ }
object T {
def main(args: Array[String]) {
new Date()
DriverManager.getDrivers
}
}
“import p._”等价于“import p.{_}”,“import p.n” 等价于“import p.{n}”
10.3 隐式导入
在每个源文件开头会隐式导入:
import java.lang._ // java.lang包的所有东西,在JAVA默认也会导入,不需要使用 import java.lang.* 语句显示导入
import scala._ // scala包的所有东西,scala包像Java中的java.lang包一样,会默认导入
import Predef._ // Predef 对象的所有东西,形如Java中的静态引用,如println()方法,而不需要Predef.println()
上面两个隐式导入java.lang._、scala._与其它明确导入还不太一样,后面的scala包会覆盖前面java.lang包中同名的东西,比如scala.StringBuilder会覆盖java.lang.StringBuilder,而其它明确导入的名中如果有相同的东西会提示出错,而不是覆盖原则
在Scala中,包java.lang,包scala和伴随对象Predef里的所有数据类型,属性和方法会被自动导入到每个Scala文件中
10.4 访问修饰符
Java中的访问修饰符:
|
继 承 与 访 问 |
|
public |
protected |
缺省 |
private |
|
同包同类 |
Y |
Y |
Y |
Y |
|
|
同包子类 |
Y |
Y |
Y |
N |
|
|
同包不子类 |
Y |
Y |
Y |
N |
|
|
不同包子类 |
Y |
Y |
N |
N |
|
|
不同包不子类 |
Y |
N |
N |
N |
10.4.1 私有成员
私有成员的处理方式与Java相同,private成员仅在定义的类或对象内部中可见。但又比Java稍有不同:
class Outer {
class Inner {
private def f() { println("f") }
class InnerMost {
f() // OK
}
}
def f() = (new Inner).f() // 错误: f不可访问
}
在Scala 中,(new Inner).f()是不合法的,因为它是在 Inner 中定义的私有类型,而在 InnerMost 中访问 f 却是合法的,这是因为 InnerMost 是包含在 Inner 的定义中(子嵌套类型)。 在 Java 语言中,以上两种访问都是可以的,Java 允许外部类访问其内部类的私有成员:
class T{
class T1{
private int a;
}
void f(){System.out.println(this.new T1().a);} // Java中访问内部类私有成员
}
10.4.2 保护成员
对保护成员的访问也同样比 Java 严格一些。 Scala 里, 保护成员只在定义成员的类中或其子类中可以被访问。但在Java 中,除了可以在定义的类或其子类中访问外,还可以在同一个包中的其他类(非子类也可)中访问( Scala 中也有途径达到这种效果):
package p {
class Super {
protected def f() { println("f") }
}
class Sub extends Super {
f()//保护类型的成员可以在子类进行访问
}
class Other {
(new Super).f() // 错误: f不可访问,即使在同一包中,但Java是允许的,虽然不是父子关系,但Other与Super在同一包中
}
}
10.4.3 公开成员
在Scala中,任何没有标记为 private 或 protected 的是公开的。 公开成员没有显式修饰符。这样的成员可以在任何地方被访问。而Java中的默认访问控制符为default(但不存在这个关键字,不能直接写),即包访问权限,只能在定义的类中或同一包中进行访问
10.4.4 细化保护范围
Scala中的访问控制还可以细化到某个包、类、对象等
package bobsrockets {
package navigation {
/*
* private[bobsrockets]表示bobsrockets包下面的所有类或对象可以直接访问
* Navigator类,虽然Navigator定义成了私有类
*
* Navigator类对包含在 bobsrockets 包的所有的类和对象都是可见的,除
* 此之外bobsrockets 包之外的所有代码都不能访问类 Navigator
*
* 因为 Vehicle 定义在包 launch 中,而 launch 包又是 bobsrockets 的子包,
* 所以Vehicle 能访问到 Navigator类
*
* 如果去掉[bobsrockets],则Vehicle类中就不能访问到Navigator
*/
private[bobsrockets] class Navigator { // 类前面也是可以使用访问修饰符的
//本身protected是不具有包访问权限的(只能本身或子类访问),但加上[navigation]后就类似具有Java的包访问权限
//如果去掉这里的[navigation],则T类中的 new Navigator().useStarChart编译会出错
protected[navigation] def useStarChart() {}
class LegOfJourney {
//与Java不同的是,Scala中外部类Navigator本来是不能访问内部类LegOfJourney中的私有成员的
//,但这里加上[Navigator]明确指定后,外部类Navigator则可以访问内部类LegOfJourney
//中的私有成员,如Navigator.f()方法
private[Navigator] val distance = 100
}
//private本来是允许同一类(而不会区分不同对象)里可以相互访问,但这里通过[this]限定只能在同一对象里访问
//(即对象私有),即只能访问对象自己的speed,而不能访问其它Navigator对象的speed,如下面的n.speed编译
//就会出错,如果去掉[this]才能编译通过
private[this] var speed = 200
def f = { new LegOfJourney().distance }
// def f1(n:Navigator)={n.speed} //编译出错,只能是 “speed” 或 “this.speed”
}
class T {
new Navigator().useStarChart
}
}
package launch {
import navigation._
object Vehicle {
private[launch] val guide = new Navigator
}
}
}

10.4.5 伴生对象可见性
Scala类里没有静态成员,而是使用伴生对象来代替,如下面Rocket 对象是 Rocket 类的伴生:
class Rocket {
import Rocket.fuel//访问伴生对象的私有方法
private def canGoHomeAgain = fuel > 20
}
object Rocket {
private def fuel = 10
def chooseStrategy(rocket: Rocket) {
if (rocket.canGoHomeAgain)//访问伴生类私有方法
goHome()
else
pickAStar()
}
def goHome() {}
def pickAStar() {}
}
不管是什么访问控制修饰符,伴生类与伴生对象之间是可以相互访问对方任何修饰符修饰的成员,即伴生类与伴生对象里的访问控制修饰符对方双不起作用
伴生对象中的protected没有意义,因为伴生对象没有任何子类
11 断言
对参数的断言,require() 方法用在对参数的检验上,不通过则抛出 IllegalArgumentException:

第二个参数为传名参数message,类型为Any,在断言方法里会调用传名参数message的toString方法
@inline final def require(requirement: Boolean, message: => Any) {
if (!requirement)
throw new IllegalArgumentException("requirement failed: "+ message)
}
assert() 或 assume() 方法在对中间运行结果进行检验,不成功则抛出 AssertionError 异常:

至于是用 assert() 或是 assume() 方法,就各取所好了,它们仅仅是意图上的区别:assert() 包含一个需证明的条件,assume() 代表的是一个公理性的论断。
def foo(who: String): Unit = {
require(who != null, "who can't be null")
val id = findId(who)
assert(id != null)
//or
assume(id != null, "can't find id by: " + who)
}
除了上面的assert、assume断言方法外,还可以使用 ensuring() 方法对块返回的结果进行断言,但它们不像 assert 断言方法那样可以随意放在任何代码行位置,它必须紧跟在返回结果块的后面,形如{...} ensuring(xx),这看起来像是在调用块返回结果的ensuring断言方法,实质上调用的是Ensuring类对象的ensuring,中间会将块返回结果隐式转换为Ensuring类型对象后进行的调用:
private def widen(w: Int): Element = {
if(w < width){
this
//这里对返回结果this进行断言,这种断言是对块结果进行断言,所以那怕只有一条语句也要使用括号括起来
} ensuring(_.width > 10)
else {
val left = elem(' ', (w - width)/2, height)
var right = elem(' ', (w - width - left.width, height)
left beside this beside right
} ensuring(w <= _.width) //断言的是上一行 left beside this beside right 结果
} ensuring((w + _.width) > 100) //ensuring 断言可以放在方法体外了,用来断言最终的结果
第一个 ensuring(_.width > 10) 中 "_" 代表前面的 this
第二个 ensuring(w <= _.width) 中的 "_" 代表的是它前面 left.beside this beside right 语句的值
最后一个 ensuring((w + _.width) > 100) 中的 "_" 代表的是此方法最终的结果,可能是 if 中的 this,也可能是 else 中的结果值。写在方法最外层的花括号后的 ensuring 语句是对返回结果的最终断言
ensuring对块结果进行判定,如果传入的表达式为真,则ensuring断言方法返回块结果,否则抛java.lang.AssertionError。
ensuring断言方法实质上是Ensuring类中的方法,所以{...} ensuring(xx) 调用形式看起来是调用了块返回结果的ensuring方法,但这些结果类型是不具体此断言方法,这实质上是发生了隐式类型转换,即在调用这些块结果ensuring方法进行断言时,这些结果对象会隐式自动转换为Ensuring类型的对象,这要归结于Predef.Ensuring隐式转换类:
implicit final class Ensuring[A](private val self: A) extends AnyVal {
//将被转换的对象存放在self成员中,并且在断言成功后原样返回
def ensuring(cond: Boolean): A = { assert(cond); self }
def ensuring(cond: Boolean, msg: => Any): A = { assert(cond, msg); self }
def ensuring(cond: A => Boolean): A = { assert(cond(self)); self }
def ensuring(cond: A => Boolean, msg: => Any): A = { assert(cond(self), msg); self }
}
JDK 1.4 才开始引入 assert 的支持,但默认是关闭的,需要用 -ea 和 -da命令参数打开和禁止,-da时代码中的 assert 语句全被忽略,一般会在单元测试中开启该选项
Scala中的断言也可以通过命令选项scalac : -Xdisable-assertions进行关闭,默认是打开的
12 样本类与模式匹配
12.1 简单示例
12.1.1 样本类
abstract class Expr
case class Var(name: String) extends Expr //变量
case class Number(num: Double) extends Expr //数字
case class UnOp(operator: String, arg: Expr) extends Expr //一元操作符
case class BinOp(operator: String, left: Expr, right: Expr) extends Expr //二元操作符
类前面带有case修饰符的类被称为样本类(case class),编译器会为这种类添加一些语法上的便捷设定:
1、 会添加与类名一致的工厂方法,即可以使用Var("x")来代替 new Var("x")
var v = Var("X")
var op = BinOp("+",Number(1),v)
2、 样本类的类参数列表中的所有参数前都会隐式自动的加上val定义关键字,这样样本类的类参数就会参数化成成员字段,所以可以以成员字段的方式来访问这些类参数:
println(v.name) //X
println(op.left) //Number(1.0)
3、 编译器会为样本类重写了toString、hashCode、equals(Scala中的 == 最后都要调用 equals 方法进行等值比较的)方法:
println(op) //BinOp(+,Number(1.0),Var(X))
println(op.right == Var("X")) // true
println(op == BinOp("+", Number(1.0), v)) // true,由于样本类重写了equals方法,并且该方法是基于内容比较的(所有成员字段会一一进行比较),所以这两个BinOp对象是相等的
样本类的这些特性都是为了支持模式匹配而特有的
12.1.2 模式匹配
/*
* 该方法非普通方法,它是一个模式匹配方法,等号右侧是匹配表达式
*
* match关键字前面的expr就是simplifyTop方法中定义的参数,它们是同一个
*
* match前面的参数变量才是真正需要进行匹配的对象,而simplifyTop
* 方法的参数列表中的参数不一定全都是需要进行匹配的对象,因为可能会有
* 多个参数
*/
def simplifyTop(expr: Expr): Expr = expr match {
/*
* 每项 case 与 => 之间的内容,就是上面match关键字前面的expr参数变量,会拿它与下面每个case语句
* 从上往下进行匹配,至到匹配为止
*
* 这里的e乃至后面的lft、rht、op都是“模式匹配占位”符号,既充当了模式匹配符角色,又充当占位符角色,
* 模式匹配相当于正则表达式中的“+{1}”;占位是为了在 => 右侧来引用模式匹配到的内容。所以e、lft、
* rht、op可以看作是名称化的匹配符,它们的名称可以随便取,只要 => 左右两边能对应起来即可,命名只是
* 为了在右侧能引用到匹配的内容
*
* 这些命名模式占位符 e、lft、rht、op 其实就是变量名,至于类型是什么,则要看这个占位符对应到样本类的
* 哪个类参数,对应的类参数类型就这些变量的类型
*
*/
case UnOp("-", UnOp("-", e)) => e //直接返回匹配到的内容。根据UnOp类参数可知,e的类型为Expr
case BinOp("+", lft, rht) => UnOp("+", rht) //lft匹配到后丢弃,只返回匹配到的rht相关对象
case BinOp(op, e, Number(1)) => { println(op); e } //op的类型String,会匹配到操作符字符串
//如上面几种情况都匹配不到,则会匹配到这个
case _ => expr
}
println(simplifyTop(UnOp("-", UnOp("-", Var("x"))))) //Var(x),与第一个case匹配
println(simplifyTop(BinOp("+", Var("y"), Number(0)))) //UnOp(+,Number(0.0)), 与第二个case匹配
println(simplifyTop(BinOp("÷", Var("z"), Number(1)))) //Var(z), 与第三个case匹配
println(simplifyTop(Number(1.1))) //Number(1.1), 与最后一个case匹配
match相当于Java中的switch,只不过用 “选择器 match { case备选项 }” 代替了“switch (选择器) { case备选项 }”
1. match是Scala的表达式,所以是可以有返回值的
2. Scala中一旦匹配到一个case如果,下面的case就不再走了,这不像Java那样需要break来跳过
3. 如果都没有匹配到,将会抛出MatchError异常,所以最后一个case一定匹配所有的情况,即“case _ =>”
//该模式匹配方法没有返回值
def simplifyTop(expr: Expr) = expr match {
case BinOp(op, left, right) =>
println(expr + "is a binary operation")
case _ => //默认什么也不做
}
12.2 模式种类
12.2.1 通配模式
通配模式“_”匹配任意对象
def simplifyTop(expr: Expr) = expr match {
//只关心是二元操作BinOp,而不关系具体的操作符与操作数
case BinOp(_, _, _) => println(expr + "is a binary operation")
case _ => println("It's something else")
}
12.2.2 常量模式
常量模式只匹配自身,任何字面量都可以用作常量,如下面的5、true、"hello"都是常量模式。另外,任何val修饰的变量(注:var不可以)或单例对象(object关键字修饰的)也可以被用作常量,如Nil使用的是object修饰的所以是单例对象,(![]() )它可以匹配空列表模式:
)它可以匹配空列表模式:
def describe(x: Any):String = x match {
case 5 => "five"
case true => "truth"
case "hello" => "hi!"
case Nil => "the empty list"
case _ => "something else"
}
scala> describe(5)
res5: java.lang.String = five
scala> describe(true)
res6: java.lang.String = truth
scala> describe("hello")
res7: java.lang.String = hi!
scala> describe(Nil)
res8: java.lang.String = the empty list
scala> describe(List(1,2,3))
res9: java.lang.String = something else
除此之外,Java中的常量(使用final修饰的)也是可以作为常量模式来使用的,请看下面章节
12.2.3 变量模式
变量模式类似于通配符,它可以匹配任意对象,但与通配不同的是,Scala会将变量绑定在匹配到的对象上,所以你可以通过这个绑定的变量来引用匹配到的对象
def f(expr: Int) = expr match {
case 0 => "zero"
//这里的somethingElse为通配符变量,非普通的变量名
case somethingElse => "not zero: " + somethingElse//默认匹配,相当于“_”,匹配所有。somethingElse为通配符,非普通变量名或成员变量名。somethingElse是命名通配占位符,也是匹配所有,但与“_”这个不同的是,在=>右侧可以通该名称来引用匹配到的对象
}
常量模式可以有符号名,如上节中的Nil就是一种有符号名的常量模式,下面就将Java中的Math类中的E、PI两个常量,作为有符号名常量模式来使用:
import Math.{ E, PI }
//这里的 E 不是参变量,而是普通的常量 Math.E
def f = E match {
//同样,这里的PI不是通配名,而是普通的常量 Math.PI
case PI => "strange math? Pi = " + PI // 由于PI是常量名,非通配符名,所以该case不会匹配到 E
case _ => "OK" // E只能匹配该case
}
那Scala是怎么区分常量名与通配符名的呢?Scala用了一个很简单的规则:将小写字母开头的简单名被当作是模式变量(通配符变量名),其他被认为是常量名。下面将PI修改为pI尝试一下后,就出现了警告提示:

那如果真有一个小字母开头的常量名时,那该如何办?有两种方式:
1、 在常量前加上访问前缀,如 this.pI或object.pI,这要求pI是成员字段
import Math.{ E, PI }
class T {
val pI = PI // 注:只能是val,不能是var
def f = PI match {
//或将 this.pI 修改为 `pI`
case this.pI => "strange math? Pi = " + pI
case _ => "OK"
}
}
2、 如果pI只是个本地常量,只能使用反引号将这个常量名引起来,
import Math.{ E, PI }
class T {
//注:Scala方法中的参数默认就是val类型的,而不是var,所以
//的方法里是不能修改参数(实质上如果是对象,是可以修改其
//对象中的内容的,只是不能修改其指向)
def f(pI:Double) = PI match {
//这里的 `pI` 使用的是f参数列表中的变量
case `pI` => "strange math? Pi = " + pI
case _ => "OK"
}
}
12.2.4 构造器模式
构造器模式的存在使得模式匹配真正变得强大,如前面的章节中的“BinOp("+", e, Number(0))”就是一种构造器模式,它由名称(BinOp)及括号内的若干模式:"+"、e、Number(0)构成,假如这个名称是一个样本类,那么这个构造器模式就表示待匹配对象是否是该名称的样本类的对象,然后再检查待匹配对象的构造器里的参数是否与另外提供的相应参数匹配模式相匹配,这是一种从外到内从左到右的一种匹配过程,而不管构造器嵌套多少层次。
expr match {
case BinOp("+", e, Number(0)) =>
println("a deep match")
case _ =>
}
示例中的“BinOp("+", e, Number(0))”匹配模式,需要进行三层匹配:第一层为“BinOp”模式,第二层为"+"、e、 Number(0) 三个模式,第三层为0,一共是5个子匹配模式
12.2.5 序列模式
你也可以像匹配样本类那样匹配如 List或Array这样的序列类
下面是匹配三个第一个元素为0的3个元素的列表:
def f(expr: List[Int]) = expr match {
case List(0, _, _) => println("found it")
case _ =>
}
val list = List(0, 1, 2)
f(list)//found it
如果想匹配一个不指定长度的序列,可以使用“_*”作为模式的最后匹配元素,“_*”这种模式能匹配序列中0到多个的元素
def f(expr: List[Int]) = expr match {
case List(0, _*) => println("found it")
case _ =>
}
val list = List(0)
f(list)//found it
12.2.6 元组模式
可以使用元组模式来匹配元组。如下面的 (a, b, c) 模式可以匹配任意的3元组:
def tupleDemo(expr: Any) = expr match {
case (a, b, c) => println("matched " + a + b + c)
case _ =>
}
tupleDemo(("a ", 3, "-tuple"))// matched a 3-tuple
12.2.7 类型模式
类型模式可以进行类型测试和类型转换。
下面的“s: String”、“m: Map[_, _]”就是类型模式:
def generalSize(x: Any): Int = x match {
case s: String => s.length
case m: Map[_, _] => m.size //这里使用的是 _ 通配符,可以匹配任何类型(key、value的类型),因为没有绑定名字,所以只能做匹配,不能提取,但也可以使用小写字母的类型变量来替代
case _ => -1
}
println(generalSize("abc")) //3
println(generalSize(Map(1 -> 'a', 2 -> 'b'))) //2
println(generalSize(Math.PI)) //-1
尽管s和x为同一对象,但x是Any类型,而s是String类型,所以待匹配对象x在与“s: String”“m: Map[_, _]”模式进行匹配时,会进行类型检测与类型转换。在Scala中,可以通过Any中的isInstanceOf方法进行类型检测,asInstanceOf进行类型转换(注:)。这样可以使用这两个方法来重写上面的实例(但这是一种不好的做法,推荐使用上面的类型模式来代替):
if (x.isInstanceOf[String]) {//检测类型
val s =
x.asInstanceOf[String] //转换类型
s.length
} else ...
泛型类型擦除
当你将泛型的具体类型写入到类型模式时,会发出未检查警告:

- non-variable type argument Int in type pattern scala.collection.immutable.Map[Int,Int] (the underlying of Map[Int,Int]) is unchecked since
it is eliminated by erasure
这是因为Scala与Java一样,使用了泛型的擦除模式,即类型参数信息没有保留到运行期,只是在编译期起作用。这可以通过调用isIntIntMap方法来证实这一点:
println(isIntIntMap(Map(1 -> 1))) //true
println(isIntIntMap(Map("a" -> "a"))) //true,这个还是返回true,按理来说返回false的
类型模式里的泛型类型参数会被擦除掉,但有个例外就是数组Array,因为在Scala和Java里,它们都是被特殊处理的,数组的元素类型将会与数组值保存在一起,因此可以做模式匹配,如:
def isStringArray(x: Any) = x match {
case a: Array[String] => "yes"
case _ => "no"
}
println(isStringArray(Array("abc"))) //yes
println(isStringArray(Array(1, 2, 3))) //no
12.2.8 给模式绑定变量
def simplifyTop(expr: Expr) = expr match {
case UnOp("abs", e) => println(e)
}
上面的e通配符可以所有情况,只要待匹配的UnOp第二个参数类型为Expr即可,所以下面两个都能匹配的到:
UnOp("abs", Number(-1))
UnOp("abs", UnOp("abs", Number(-1)))
但如果要求e只能匹配到UnOp类型对象,则可以在e后面跟一个 “@”符号后,再接上要求的匹配模式:
def simplifyTop(expr: Expr) = expr match {
case UnOp("abs", e @ UnOp("abs", _)) => println(e)
}
此时只能匹配到:
UnOp("abs", UnOp("abs", Number(-1)))
而不能再匹配到:
UnOp("abs", Number(-1))
更进一步,也可以给任何模式绑定一个变量名,便于在右侧引用匹配到的对象(这种有点像正则表达式中的分组匹配味道),如下面给整个模式绑定一个名为a的变量:
def simplifyTop(expr: Expr) = expr match {
case a @ UnOp("abs", e @ UnOp("abs", _)) => println(a); println(e)
}
实质上“UnOp("abs",UnOp("abs", _))”与“a @ UnOp("abs", e @ UnOp("abs", _))”模式是一样的,即匹配到的范围是一样的,只是后面模式绑定了变量,便于=>右侧引用匹配到的内容
12.3 模式守卫
你可以将:
BinOp("+", Var("x"), Var("x"))
写作:
BinOp("*", Var("x"), Number(2))
即“x + x”可以用“x * 2”来表示。下面尝试写这种转换的匹配模式:
def simplifyAdd(e: Expr) = e match {
case BinOp("+", x, x) => BinOp("*", x, Number(2))
case _ => e
}
但编译会出错:x is already defined as value x,因为模式变量仅允许在模式中出现一次,但可以使用模式守卫来重新制定这种匹配转换规则:
def simplifyAdd(e: Expr) = e match {
case BinOp("+", x, y) if x == y =>
BinOp("*", x, Number(2))
case _ => e
}
模式守卫拉在模式之后,以if开头,守卫中可以引用任意的模式中的变量,只要是一个布尔表达式即可。如果存在模式守卫,则只有在守卫返回true时才匹配成功
// 仅匹配正数
case n: Int if
0 < n => ...
//
仅匹配以字母 a 开头的字符串
case s: String if
s(0)
== 'a' => ...
12.4 模式重叠
模式匹配时,会依照case语句的先后顺序来执行匹配,一旦匹配成功,后面case不再进行匹配,所以前面的case应该比后面的case精确一些,即匹配到的内容会少一些,这与Java中捕获异常一样,Exception往往放在最后进行捕获,下面的代码在Java直接报错:

在Scala中,如果将粗略的匹配模式放在前,则编译时只会发出警告:
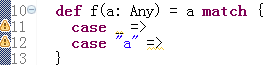
由于“_”会匹配所有,而 “"a"”只能精确匹配到 "a"的字符串,所以第二个case无法执行,正确写法是调换一下位置:
def f(a: Any) = a match {
case "a" =>
case _ =>
}
但有时编译器判断不出来,如下面第一个case会拦截所有String,所以以第二个case也是永远不会被匹配,但编译器没有发出警告,所以需要特别注意:

12.5 封闭类
模式匹配方法一旦写好之后,就意义味着所有情况都考虑到了,一般我们会在最后加一个默认case匹配“case _ =>”,它会匹配到其它所有情况,不过这仅仅在的确有一个合理的默认行为的情况下加上的,如果没有默认情况怎么办?比如现有的某个模式匹配方法已经考虑到了所有情况,但说不定那天别人又添加了一个样本类,那这个匹配方法需要修改。这就要求别人不能添加样本类,或者是我添加样子类后,别人写的模式匹配方法在编译时,编译器会提示他有新的样本类被遗漏了这也是可以的,这就需要用到封闭类
封闭类是被匹配对象所属于的一种特殊类,它是在定义类calss时,在前面使用 sealed关键字来修饰的一种类。封闭类是专用于模式匹配中的,
封闭类两个作用:
第一:除了类定义所在的文件之外,是不能再添加任何新的样本子类,这就会阻止别人随意的添加样本子类而导致现有的模式匹配方法遗漏新样本类匹配情况
第二:使用封闭类你还可以获得编译器更好的提示,如果你使用继承至封闭类的样本类做匹配,编译器将会检测是否还有某个样本类匹配情况合漏掉了(注:不只是检查样本类是否加入到了匹配模式中,那怕只有某个具体实例漏掉也会提示)
封闭sealed关键字一般是加上最顶层,即样本类的抽象父类前面,比如现重写前面示例:
sealed abstract class Expr //将样本类的抽象类定义成封闭的
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class UnOp(operator: String, arg: Expr) extends Expr
case class BinOp(operator: String, left: Expr, right: Expr) extends Expr
现在定义一个丢失了若干可能样本的模式匹配:

编译器会提示:match may not be exhaustive. It would fail on the following inputs: BinOp(_, _, _), UnOp(_, _)
这样的警告向你表明代码会有产生MatchError异常的风险,因为某些可能的模式(UnOp、BinOp)没有被处理
如果你能确定上面的describe匹配方法只用于Number、Var两种样本的匹配,又不想因遗漏而导致的编译器提示,则可以在最后添加一个默认匹配,并抛出一个运行时异常,这是比较好的处理方式:
def describe(e: Expr): String = e match {
case Number(_) => "a number"
case Var(_) => "a variable"
case _ => throw new RuntimeException // 不应该发生,如果发生了则抛RuntimeException
}
也可以使用注解 @unchecked 来告诉编译器不进行遗漏模式的检查:
def describe(e: Expr): String = (e: @unchecked) match {
case Number(_) => "a number"
case Var(_) => "a variable"
}
12.6 Option类
标准类库scala.Option类,有一个子类是Some类,代表有值,值为Some(x)(Some没有伴生对象,但Some是一个Case样本类,所以会自动有工厂方法),其中x为真实值(被Some包装了一下而已);一个单例对象是None,代表缺少值。并且它们都是case类型的类或对象
Scala集合类的某些标准操作会产生Option可选值,如Map的get方法,查到值时返回Some(value)对象,没查到时返回None对象(而Java中返回的为Null,这会容易导致程序运行错误):
val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
println(capitals get "France") //Some(Paris)
println(capitals get "North Pole") //None
由于get方法返回值可能是Some类型的值,也可能是None,从Option可选值中提取出真实值最通常的办法是通过模式匹配:
def show(x: Option[String]): String = x match {//提取真实的值
case Some(s) => s //有值时返回真实的值
case None => "?" //无值时返回一个问号
}
println(show(capitals get "Japan")) //Tokyo
println(show(capitals get "France")) //Paris
println(show(capitals get "North Pole")) //?
12.7 模式无处不在
Scala中的模式可以出现在很多地方,而不只是在match表达式里。
12.7.1 模式在变量定义中
在定义val或var时候,可以使用模式替代简单的标识符,如,可以使用模式拆分元组并把其中的每个值分配给变量
scala> val myTuple = (123, "abc")
myTuple: (Int, java.lang.String) = (123,abc)
scala> val (number, string) = myTuple
number: Int = 123
string: java.lang.String = abc
再如,如果你知道正在用的样本类的精确结构,也可以使用模式解构它:
scala> val exp = new BinOp("*", Number(5), Number(1))
exp: BinOp = BinOp(*,Number(5.0),Number(1.0))
scala> val BinOp(op, left, right) = exp
op: String = *
left: Expr = Number(5.0)
right: Expr = Number(1.0)
12.7.2 PartialFunction(偏函数)
偏函数是一种只能处理传入的一个(或多个)值的特殊函数,但它不像函数或方法那样,能处理所有传入的值。偏函数只能对部分情况进行处理,因而需要将多个偏函数组合,最终才能达到全面覆盖的目的,所以偏函数也称“部分”函数
普通函数 (Int) => String可以接收任意Int值,并返回一个字符串;而如果是(Int) => String类型的偏函数可能不能接受所有Int值为输入,如果传入不能处理的值,则会抛MatchError异常
偏函数的类型为PartialFunction,是一个只有一个参数的Function1类的子类(case语句只接受一个参数,则偏函数的类型声明自然就只有一个参数):
trait PartialFunction[-A, +B] extends (A => B){// extends关键字后面的“(A => B)”实质上就是Function1,所以偏函数实质上是一个带有一个参数的函数
偏函数一般有两种创建方法:
1、一是使用快捷而简便的方式就是使用case模式匹配,在下面示例中我们将会看见:
scala> val p:PartialFunction[Int, String] = { case 1 => "One" }
p: PartialFunction[Int,String] = <function1>
scala> p(1)
res3: String = One
2、 通过继承自PartialFunction 特质,并提供isDefinedAt、apply两函数的实现,下面是上面待价做法:
//注:如果要自己定义一个偏函数类,要从Function类继承,并实现isDefinedAt、apply两个方法
var p2: PartialFunction[Int, String] = new PartialFunction[Int, String] {
def isDefinedAt(x: Int): Boolean = x match { case 1 => true; case _ => false }
override def apply(v1: Int): String = v1 match{ case 1 => "One" }
}
println(p2(1))//One
实质上通过第一种方式创建偏函数时,编译器会将它翻译成第二种方法的代码,只是第一种
偏函数将函数求解空间中各个分支也分离出来,形成可以被组合的偏函数
偏函数中最常见的组合方法为orElse、andThen与compose。orElse相当于一个“或”运算,可以通过它将多个偏函数组合起来形成新的偏函数(或函数,前提是如果能全覆盖,这只是一个逻辑上的划分),就相当于形成了多个case合成的模式匹配。例如写一个求绝对值的运算,就可以利用偏函数:
//只能处理大于0的偏函数
val positiveNumber: PartialFunction[Int, Int] = {
case x if x > 0 => x
}
//只能处理等于0的偏函数
val zero: PartialFunction[Int, Int] = {
case x if x == 0 => 0
}
//只能处理小于0的偏函数
val negativeNumber: PartialFunction[Int, Int] = {
case x if x < 0 => -x
}
//可以将上面三个偏函数组合起,形成一个能处理所有情况的函数
def abs(x: Int): Int = {
(positiveNumber orElse zero orElse negativeNumber)(x)
}
利用orElse组合时,还可以直接组合case语句,这正是因为case语句相当于Function1类型的函数,例如:
//只处理偶数的偏函数
val pf: PartialFunction[Int, String] = {
case i if i%2 == 0 => "even"
}
//与处理奇数的偏函数组合起来形成一个能处理所以情况的函数
val tf: (Int => String) = pf orElse { case _ => "odd" }
orElse被定义在PartialFunction类型中,而andThen与compose却不同,它们实则被定义在Function1中,PartialFunction只是重写了这两个方法。这意味着函数之间的组合可以使用andThen与compose,偏函数也可以,它们只是组合的顺序不同,既然andThen与compose这两个是函数FunctionX里定义的方法,那先看看它们在FunctionX函数里是怎么使用的,以及 andThen与compose区别:
scala> def f(s: String) = "f(" + s + ")"
f: (s: String)String
scala> def g(s: String) = "g(" + s + ")"
g: (s: String)String
compose 组合其他函数形成一个新的函数 f(g(x)):
scala> val fComposeG = f _ compose g _
fComposeG: String => String = <function1>
scala> fComposeG("str")
res7: String = f(g(str))
andThen 和 compose很像,但是调用顺序是先调用第一个函数,然后调用第二个,即g(f(x)),与compose刚好相反:
scala> val fAndThenG = f _ andThen g _
fAndThenG: String => String = <function1>
scala> fAndThenG("str")
res8: String = g(f(str))
利用andThen组合每个偏函数都可以理解为是一个Filter,上一个偏函数的输出值会作为下一个偏函数的输入值,每个偏函数的函数类型是不要求一致的。对比orElse,则有所不同,orElse要求组合的所有偏函数必须是同样类型的偏函数定义,例如都是Int => String,或者String => Int等
既然andThen组合起来的每个偏函数相当于过滤器,即要求每个都能进行一部分处理,只要某个偏函数不满足处理情况,则会抛出MatchError。如下面的将数字 1、2替换为英文,实现如下:
val p1: PartialFunction[String, String] = {
case s if s.contains("1") => s.replace("1", "one")
}
val p2: PartialFunction[String, String] = {
case s if s.contains("2") => s.replace("2", "two")
}
val p = p1 andThen p2
如果调用p("123"),返回结果为"onetwo3",但如果传入p("13"),由于p2偏函数的isDefineAt返回false,就会抛出MatchError错误
由于偏函数继承自函数,因而,如果一个方法要求接收函数,那么它也可以接收偏函数。例如我们常常使用的List中的map、filter等方法,它们的参数类型就是一个函数,是可以接收偏函数:
val sample = 1 to 10
sample map {
case x if x % 2 == 0 => x + " is even"
case x if x % 2 == 1 => x + " is odd"
}
而List的collect方法则只能接收偏函数,即只能接收PartialFunction类型的函数
scala> List(1,2,"str") map {case i:Int=>i+1;case s:String=>s}
res9: List[Any] = List(2, 3, str)
12.7.2.1 Case语句块用作偏函数
由于偏函数PartialFunction是Function1的子类,所以case语句可以传给一个参数类型为函数的方法(即高阶函数):
scala> List(1, 2, 3).map({ case i: Int => i + 1 })
res0: List[Int] = List(2, 3, 4)
当然也可以是多个Case组成的块,匹配多种情况:
scala>List(1,2,"str") map {case i:Int=>i+1;case s:String=>s}
res9: List[Any] = List(2, 3, str)
在Scala里,可以使用case语句(如这里的“{ case i: Int => i + 1 }”)来创建一个匿名函数(函数字面量),这与一般
匿名函数创建方法有所区别。case i:Int=>i+1构建的匿名函数等同于(i:Int)=>i+1,所以上面写法等效下面:
scala> List(1,2,3) map {(i:Int)=>i+1}
res1: List[Int] = List(2, 3, 4)
也可以是多个Case语句块:
scala> List(1,2,"str") map {case i:Int=>i+1;case s:String=>s}
res26: List[Any] = List(2, 3, str)
List的map函数参数列表(f: A => B)是普通的函数Function1,而其collect 函数的参数列表(pf: PartialFunction[A, B])是一个偏函数PartialFunction:
List(1, 3, 5, "seven") map { case i: Int => i + 1 } // 运行时会报错,原因是"seven"为字符类型不能被匹配
List(1, 3, 5, "seven") collect { case i: Int => i + 1 } //可以很好的工作,原因是collect传进的是一个偏函数,所以这里的case会自动转换为PartialFunction对象,而PartialFunction对象具有isDefinedAt预先判断是否匹配的方法,正是因为List的collect函数在运行时,先调用了isDefinedAt这个方法(如这里的"seven"匹配不到,就会被忽略,不会去执行apply方法),如果判定可以匹配的到,则再调用PartialFunction对象apply方法,这样就避免了异常。这也是普通函数与偏函数的区别。
由于collect要求传入的是一个偏函数,所以上面的collect 后面的“{ case i: Int => i + 1 }”实质上相当于如下定义的:
scala> val inc: PartialFunction[Any, Int] = {
| case i: Int => i + 1
| }
我们也可以定义一个PartialFunction类,并提供isDefinedAt与apply的实现,然后再在collect函数中使用,下面是采用匿名类实例化的方式(当然也可以定义一个从PartialFunction继承的类,如果多次使用的话),与上面完全等价(即编译器会将上面的代码翻译成下面这样的代码):
scala> val inc = new PartialFunction[Any, Int] {
| def apply(any: Any) = any.asInstanceOf[Int]+1
| def isDefinedAt(any: Any) = if (any.isInstanceOf[Int]) true else false
| }
inc: PartialFunction[Any,Int] = <function1>
scala> List(1, 3, 5, "seven") collect inc //效果与 List(1, 3, 5, "seven") collect { case i: Int => i + 1 }一样
res28: List[Int] = List(2, 4, 6)
PartialFunction特质规定了两个要实现的方法:apply和isDefinedAt,isDefinedAt用来告知调用方这个偏函数接受参数的范围,这个例子中我们要求这个inc函数只处理Int型的数据。apply方法用来描述对已接受的值如何处理,在这个例子中,只是简单的把值+1,注意,非Int型的值已被isDefinedAt方法过滤掉了,所以不用担心类型转换的问题。
上面这个例子写起来显得非常笨拙,和前面的case语句方式比起来真是差太多了。这个例子从反面展示了:通过case语句组合去是实现一个偏函数是多么的简洁。同样是上面的inc函数,换成case去写如下:
scala> def inc: PartialFunction[Any, Int] = { case i: Int => i + 1 }
或者这样:
scala> val inc: PartialFunction[Any, Int] ={ case i: Int => i + 1 } // 都是inc,一个是方法,一个是变量,调用inc方法会返回的是一个偏函数实例,而变量在定义时就会初始化,而不像方法那样要等调用时才会执行方法体。下面使用时结果都一样
inc: PartialFunction[Any,Int]
scala> List(1, 3, 5, "seven") collect inc
res29: List[Int] = List(2, 4, 6)
val inc: Any => Int = { case i: Int => i + 1 }
请注意“val inc: PartialFunction[Any, Int]”与“val inc: Any => Int”这两种定义的区别:第一个inc是PartialFunction类型的变量,即偏函数变量;第二个inc是一个普通的函数变量,真正的类型为Function1,由于“Any => Int”与“Function1[Any, Int]”是等价的类型,所以“val inc: Any => Int = { case i: Int => i + 1 }”也可以如下定义:
val inc: Function1[Any, Int] = { case i: Int => i + 1 }
但此种类型(Function1)的inc是不能传递给List的collect方法
12.7.3 for表达式里的模式
在for表达式里也是可以使用模式:
scala> for ((country,
city) <- capitals)
println("The capital of "+ country +"
is "+ city)
The capital of France is Paris
The capital of Japan is Tokyo
在遍历之前,会判断被对象是否与模式匹配,只有匹配时才执行for循环体:
scala> val results = List(Some("apple"), None, Some("orange"))
results: List[Option[java.lang.String]]
= List(Some(apple),
None, Some(orange))
由于模式中加上了类型Some,所以None类型值不会被遍历出来:
scala> for (Some(fruit)
<- results) println(fruit)
apple
orange
去掉模式中的类型Some则才可以:
scala> for (fruit
<- results) println(fruit)
Some(apple)
None
Some(orange)
13 列表List
Scala中的列表List是一种不可变链接列表,底层是基于链表实现的,而并不是基于数组实现的
13.1 列表字面量
val fruit = List("apples", "oranges", "pears")
val nums = List(1, 2, 3, 4)
val diag3 =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1))
val empty = List()
List是immutable的,即里面的元素不能重新指向别的元素
13.2 列表类型
列表中的所有元素类型都具有相同的类型:List[T]
如下面指每个列表在定义时明确指定类型:
val fruit: List[String] = List("apples", "oranges", "pears")
val nums: List[Int] = List(1, 2, 3, 4)
val diag3: List[List[Int]] =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1))
val empty: List[Nothing] = List()
只要List[T]中的T类型为父类类型,则子类对象也是可以存放的,如List[Object]类型的列表可以存放String类型的元素:
val objct: List[Object] = List("String", new Integer(1))
空列表Nil的类型为List[Nothing],从类层级图中可以看出Nothing是最底层类型,它是所有类型的子类,所以List[Nothing]相当于List[T]的子类,所以类型为List[Nothing]的空列表对象,可以被当作List[T]列表类型的对象:
val xs: List[String] = List()
13.3 创建列表 ::
def ::(x: A): List[A]
在列表的最前面添加元素,并返回新的列表
1 :: List(2, 3) = List(2, 3).::(1) = List(1, 2, 3)
所有列表都是由两个基础的东西“::”和“Nil”构造出来的,Nil表示空列表。中缀操作符“::”表示从列表的前端进行扩展,也就是说,x::xs中第一个为x元素,后面跟着的xs是一个列表(即在xs列表前端追加x元素)。下面以这种结构来重新创建上面的列表:
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
val diag3 = (1 :: (0 :: (0 :: Nil))) ::
(0 :: (1 :: (0 :: Nil))) ::
(0 :: (0 :: (1 :: Nil))) :: Nil
val empty = Nil
注意:“::”左操作符一般为元素(当然也可以是列表),但右操作符则一定要是列表,所以这也就解释了为什么Nil是放在最后面的,而不是最前
另外,“::”操作符默认是右结合(即从括号最里层向外层开始计算)的,所以上面一些括号是可以省略的,如上面的nums定义可以直接这样:
val nums = 1 :: 2 :: 3 :: 4 :: Nil
13.4 列表基本操作
def head: A:返回列表的第一个元素
def tail: List[A]:返回除第一个元素之外所有元素组成的列表
def isEmpty: Boolean:判断列表是否为空
println(empty.isEmpty)//true
println(fruit.head)//apples
println(fruit.tail.head)//oranges
println(diag3.head)//List(1, 0, 0)
在空列表上调用head与tail方法时会抛异常:
scala> Nil.head
java.util.NoSuchElementException: head of empty
list
下面是对某个列表进行插入排序:
//插入排序
def isort(xs: List[Int]): List[Int] =
if (xs.isEmpty) Nil
//先将列表展开成一个个元素,最后以空列表结束;然后从里向往逐层调用insert
//最里层的insert方法是这样的:insert(最后一个元素,空列表)
else insert(xs.head, isort(xs.tail))
def insert(x: Int, xs: List[Int]): List[Int] =
if (xs.isEmpty || x <= xs.head) x :: xs
else xs.head :: insert(x, xs.tail)
val nums = 3 :: 2 :: 4 :: 1 :: Nil
println(isort(nums)) //List(1, 2, 3, 4)
插入排序效率很低,与列表长度平方成正比,后面以归并排序算法来实现
13.5 列表模式
可以对列表使用模式匹配做拆分。即可以使用 List(...) 形式的模式对列表所有的元素做匹配,也可以使用 :: 操作符和 Nil常量组成的模式进行拆分列表:
scala> val List(a, b, c)
= fruit
a: String = apples
b: String = oranges
c: String = pears
模式List(a, b, c)与长度为3的列表匹配,并将三个元素绑定到模式变量a,b和c上;如果不知道长度,则最好使用 :: 做匹配,如模式 a :: b :: rest 上课以匹配长度至少为2的列表(长度为2时匹配到的是一个空列表):
scala> val a :: b ::
rest = fruit
a: String = apples
b: String = oranges
rest: List[String] = List(pears)
其实列表的head与tail方法恰好与 模式 x::xs 相匹配(x匹配第一个元素,相当于head取到的第一个元素;而xs则匹配剩下所有元素组成的列表,相当于tail取到的所剩于元素列表),所以可以使用模式匹配来代替这两个方法,如使用模式匹配来实现上面的插入排序:
def isort(xs: List[Int]): List[Int] = xs match {
case List() => List()
case x :: xs1 => insert(x, isort(xs1))
}
def insert(x: Int, xs: List[Int]): List[Int] = xs match {
case List() => List(x)
case y :: ys => if (x <= y) x :: xs
else y :: insert(x, ys)
}
13.6 List常用方法
这些方法参数类型是非函数类型
13.6.1 连接列表::::
def :::(prefix: List[A]): List[A]
将prefix列表加在主调列表前面,并返回新的列表,原列表不变
List(1, 2) ::: List(3, 4) = List(3, 4).:::(List(1, 2)) = List(1, 2, 3, 4)
与前面的连接操作 “::” 不一样的是,“:::”的两个操作数都是列表,xs ::: ys 的结果就是依次包含xs和ys所有元素的新列表:
scala> List(1, 2) ::: List(3, 4, 5)
res0: List[Int] = List(1, 2, 3, 4, 5)
scala> List() ::: List(1, 2, 3)
res1: List[Int] = List(1, 2, 3)
scala> List(1, 2, 3) ::: List(4)
res2: List[Int] = List(1, 2, 3, 4)
与“::”一样,“:::”也是右结合的,所以:
xs ::: ys ::: zs
与下面是一样的:
xs ::: (ys ::: zs)
与“::”一样,“:::”即是操作符,也是List的方法
由于“:::”就右结合型的,即“:::”是右列表的方法,然后将左列追加在右列表的前面,所以当以方法形式调用时,也要注意是还是将被调用列表追加在调用列表的前面:
List(1, 2).:::(List(3, 4, 5)) //List(3, 4, 5, 1, 2)
自己实现 “xs:::ys”

“分治”原则:列表的许多算法首先是用模式匹配把输入列表拆分为更简单的样本,这是原则里的“分”;如果样本非空,则再次递归调用算法,这就是“治”
13.6.2 列表长度:length方法
def length: Int
scala> List(1, 2, 3).length
res3: Int = 3
注:与数组相比,列表的长度计算要比较慢,且随着列表中元素的增多而逐渐减慢,因为列表在计算长度时,需要体遍历整个列表。所以在判断列表是否为空是应该采用xs.isEmpty而不是xs.length == 0,因为xs.isEmpty方法一旦检测到有元素,则停止遍历;而数组是在定义就分配了固定大小,长度相当于数组的一个属性
13.6.3 列表尾部:last、init方法
def last: A
def init: List[A]
与上面head和tail基本操作一样,init和last与它们正好相反:last返回列表的最后一个元素,init返回除了最后一个元素之外前面所有元素的列表:
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
abcde: List[Char] = List(a, b, c, d, e)
scala> abcde.last
res4: Char = e
scala> abcde.init
res5: List[Char] = List(a, b, c, d)
与head和tail一样的是,对空列表调用它们都会抛异常;不一样的是,head和tail运行的时间都是常量,但last和init需要遍历整个列表计算结果,因此所耗的时间与列表长度成正比
13.6.4 反转列表:reverse
def reverse: List[A]
如果出于某种原因,需要频繁的访问列表的尾部,那可以先把列表反转再访问
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> abcde.reverse
res6: List[Char] = List(e, d, c, b, a)
与其列表操作一样,反转是返回一个新的列表,而不是修改原列表
xs.reverse.reverse
equals xs
xs.reverse.init equals xs.tail.reverse
xs.reverse.tail equals xs.init.reverse
xs.reverse.head equals xs.last
xs.reverse.last equals xs.head
反转操作可以用连接(:::)实现,时间复杂度为n的平方:
def rev[T](xs: List[T]): List[T] = xs match {
case List() => xs
case x :: xs1 => rev(xs1) ::: List(x)
}
这种不可变List标准库中是这样实现的:
override def reverse: List[A] = {
var result: List[A] = Nil
var these = this
while (!these.isEmpty) {
result = these.head :: result
these = these.tail
}
result
}
不管是上面那种实现,这种不可变列表与比可变列表的反转相比,这是很慢的,后面章节可以通过左折叠操作有所改善上面的rev反转方法
13.6.5 指定长度:take、drop、splitAt
def take(n: Int): List[A]
返回前n个元素的列表,注:n为个数,非索引
def drop(n: Int): List[A]
返回除前面n个元素以外的所有元素列表
def splitAt(n: Int): (List[A], List[A])
分成两个列表,第一个列表包含前面n元素,剩下的元素为第二个列表
take和drop可以根据指定的长度返回列表任意长度前面部分和后面部分
“xs take n”返回xs列表前n个元素,如果n大于xs.length,则返回整个xs;
“xs drop n”返回xs列表除前n个元素之外的所有元素,如果n大于xs.length,则返回空列表
splitAt操作在指定位置拆分成两个列表,并以TupleN对象形式返回:
xs splitAt n 等价 (xs take n, xs drop n)
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> abcde take 2
res8: List[Char] = List(a, b)
scala> abcde drop 2
res9: List[Char] = List(c, d, e)
scala> abcde splitAt 2
res10: (List[Char], List[Char]) = (List(a, b),List(c, d, e))
13.6.6 索引方法:apply、indices
def apply(idx: Int): A
取指定索引位置的元素,注意:这里的idx为索引,也是从0开始的;0 <= idx < length。请注意与List伴生对象的apply区别
def indices: Range
生产所有所有元素所对应的索引所组成的范围Rang
List的apply方法实现了与数组一样可根据索引下标来访问元素:
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> abcde apply 2
res11: Char = c
由于aply方法的特殊性:如果是伴生对象时,对象后面直接接括号则表示是调用伴生对象的apply方法;如果是非伴生对象的对象,后面直接接括号则表示是调用该对象的apply方法。这里属于第二种情况,因此可以省略apply方法:
scala> abcde(2)
res12: Char = c
列表中这种通过索引访问比起数组也是要慢得多,不是真正随机访问,且花费时间与索引值n成正比,实际上通过查看源码,apply其实是drop与head两个操作来完成的:
xs apply n 等价 (xs drop n).head
indices方法则是返回整个列表所有元素所对应索引值所组成的Range:
scala> abcde.indices
res0: scala.collection.immutable.Range = Range(0, 1, 2, 3, 4)
这也说明了列表中的元素索引也是从0开始,length - 1结束
13.6.7 zip、zipWithIndex
def zip[B](that: GenIterable[B]): List[(A, B)]
将主调列表与给定集合映射成Tuple类型元素的列表
def zipWithIndex: List[(A, Int)]
与zip一样,只是映射列表固定为索引列表,不能指定第二个列表
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> abcde.indices zip abcde
res14: List[(Int, Char)] = List((0,a), (1,b), (2,c),
(3,d),(4,e))
如果两个长度不一致,则以短的为准:
scala> val zipped = abcde zip List(1, 2, 3)
zipped: List[(Char, Int)] = List((a,1), (b,2), (c,3))
def unzip[A1, A2]: (List[A1], List[A2])
unzip是zip的逆过程:
scala> (abcde.indices zip abcde).unzip
res35: (scala.collection.immutable.IndexedSeq[Int], scala.collection.immutable.IndexedSeq[Char]) = (Vector(0, 1, 2, 3, 4),Vector(a, b, c, d, e))
常用到的情况是把列表元素与索引值zip在一起,这时使用zipWithIndex会更好,它能把列表的每个元素在列表中的位置组合成一对:
scala> abcde.zipWithIndex
res15: List[(Char, Int)] = List((a,0), (b,1), (c,2),
(d,3),(e,4))
13.6.8 toString、mkString
def toString(): String
def mkString: String
def mkString(sep: String): String
def mkString(start: String, sep: String, end: String): String
toString方法返回列表的标准字符串表达形式:
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> abcde.toString
res16: String = List(a, b, c, d, e)
mkString可以将列表转换成特定格式的字符串。xs mkString (pre, sep, post),xs为特转换的列表,pre、post为转换后字符串里的前缀与后缀,sep表示元素拼接的分隔符,最后形成的字符串为:
pre + xs(0) + sep + . . . + sep + xs(xs.length - 1) + post
mkString的还有两个重载体,第一个是只带分隔符参数的操作:
xs mkString sep 等价 xs mkString ("", sep, "")
第二个是不带任何参数:
xs.mkString等价xs mkString ""
scala> abcde mkString ("[", ",", "]")
res17: String = [a,b,c,d,e]
scala> abcde mkString ""
res18: String = abcde
scala> abcde.mkString
res19: String = abcde
scala> abcde mkString ("List(", ",
", ")")
res20: String = List(a, b, c, d, e)
mkString方法还有一个名为addString的变体,它是把构建好的字符串存放在StringBuilder对象中:
scala> val buf = new StringBuilder
buf: StringBuilder =
scala> abcde addString (buf, "(", ";", ")")
res21: StringBuilder = (a;b;c;d;e)
由于mkString 和 addString两个方法都是从List的超特质Iterable中继承而来,所以可枚举(迭代)的集合类上都有它们
13.6.9 列表转换:toArray, copyToArray
def toArray: Array[A]
def copyToArray(xs: Array[A], start: Int, len: Int): Unit
将列表中的所有元素拷贝到指定的xs数组中,start指定了从数组中的哪个索引位置开始存放,以及最多拷贝len个元素;如果列表长度不够或者是数组过短,将以实质拷贝为主
def copyToArray(xs: Array[A]): Unit
相当于copyToArray(xs, 0, xs.length)
def copyToArray(xs: Array[A], start: Int): Unit
相当于copyToArray(xs, start, xs.length - start)
数组与列表是可以相互转换的,List的toArray是将列表转换为数组,而Array的goList是将数组转换为列表:
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> val arr = abcde.toArray
arr: Array[Char] = Array(a, b, c, d, e)
scala> arr.toList
res23: List[Char] = List(a, b, c, d, e)
copyToArray,将列表中的元素复制到目标数组里一段连续的空间中:
xs copyToArray (arr, startIndex)
scala> val arr2 = new Array[Int](10)
arr2: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
scala> List(1, 2, 3)
copyToArray (arr2, 3)
scala> arr2.toString
res25: String = Array(0, 0, 0, 1, 2, 3, 0, 0, 0, 0)
如果存放不下,则丢弃后面的
13.6.10 列表迭代:iterator
def iterator: Iterator[A]
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> val it = abcde.iterator
it: Iterator[Char] = non-empty iterator
scala> it.next
res26: Char = a
scala> it.next
res27: Char = b
13.6.11 示例:归并排序
前面以两种方式写了插入排序,虽然算法简单,但效率不高。这里使用归并排序算法来进行排序
归并排序算法:首先如果列表长度为0或者仅有一个元素,它就已经是排好序的了,因此可以直接打返回;若列表长度大于等于2,则可以拆分为两个子列表,拆分的方法可以除2取整来一分为二。然后对每个子列表进行递归排序,最后通过归并操作将两个排序好的列表合并在一起

/*
* 归并排序方法:
*
* 方法为泛型方法,类型为T,即元素类型为T
*
* 第一个参数列表为比较函数,第二个参数列表为待排序的列表
*
* 升还是降则由less函数决定
*/
def msort[T](less: (T, T) => Boolean)(xs: List[T]): List[T] = {
//归并操作:将有序列表合二为一
def merge(xs: List[T], ys: List[T]): List[T] =
(xs, ys) match { //这里使用Tuple2将两个参数列表都进行匹配
case (Nil, _) => ys
case (_, Nil) => xs
case (x :: xs1, y :: ys1) => //在合的时候进行有序合并
if (less(x, y)) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
val n = xs.length / 2
if (n == 0) xs //如果是空列表或仅有一个元素的列表时,直接返回
else {
val (ys, zs) = xs splitAt n //从中间拆分
//先分(分成ys, zs两个列表)后合(merge),并对
//每个子列表进行同样的算法递归(msort)
merge(msort(less)(ys), msort(less)(zs))
}
}
scala> msort((x: Int, y: Int) => x < y)(List(5,8, 3, 6,2,7,9,4,1))
res28: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> val intSort = msort((x: Int, y: Int) => x < y) _
intSort: (List[Int]) => List[Int] = <function>
scala> intSort(List(5,8, 3, 6,2,7,9,4,1))
res3: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
13.7 List高阶函数
13.7.1 映射与处理:map、flatMap、flatten、foreach
def map[B](f: (A) ⇒ B): List[B]
B:返回列表中元素的类型
f:该函数会应用到主调列表中的每个元素上
返回:返回一个新的列表,新列表中的每个元素为主调列表中每个元素通过应用f函数后得到的新的元素
scala> List(1, 2, 3) map (_ +
1)
res29: List[Int] = List(2, 3, 4)
scala> val words = List("the", "quick", "brown", "fox")
words: List[java.lang.String] = List(the, quick, brown, fox)
scala> words map (_.length)
res30: List[Int] = List(3, 5, 5, 3)
scala> words map (_.toList.reverse.mkString)
res31: List[String] = List(eht, kciuq, nworb, xof)
final def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): List[B] (Traversable:可遍历的,GenTraversableOnce不可变集合都继承过它)
flatMap是map的一种扩展。在flatMap中,我们会传入一个函数,该函数对每个输入都会返回一个集合类型的对象(而不像map方法那样返回的只是一个元素),然后,flatMap把生成的多个集合“拍扁”成为一个列表:
scala> val books = List("Hadoop","Hive","HDFS")
books: List[String] = List(Hadoop, Hive, HDFS)
scala> books map (s=>s.toList)
res4: List[List[Char]] = List(List(H, a, d, o, o, p), List(H, i, v, e), List(H, D, F, S))
scala> books flatMap (s => s.toList)
res0: List[Char] = List(H, a, o, o, p, H, i, v, e, H, D, F, S)
上面的flatMap执行时,会把books中的每个元素都调用toList,生成List[Char],最终,多个Char的集合被“拍扁”成一个列表List[Char]
def flatten[B]: List[B]
flatten相对于flatMa就比较简单了,就是将嵌套集合本身拍扁,最终的集合类型为外层集合类型:
val xs = List(
Set(1, 2, 3),
Set(1, 2, 3)).flatten
// xs == List(1, 2, 3, 1, 2, 3)
val ys = Set(//Set集合也有这样的拍扁方法
List(1, 2, 3),
List(3, 2, 1)).flatten
// ys == Set(1, 2, 3)
final def foreach(f: (A) ⇒ Unit): Unit
foreach与map相似,只是不返回结果
scala> var sum = 0
sum: Int = 0
scala> List(1, 2, 3, 4, 5) foreach
(sum += _)
scala> sum
res36: Int = 15
13.7.2 过滤:filter、partition、find、takeWhile、dropWhile、span
def filter(p: (A) ⇒ Boolean): List[A]
返回满足给定条件的元素所组成的新列表
scala>
List(1, 2, 3, 4, 5) filter (_ %
2 == 0)
res37:
List[Int] = List(2, 4)
val words = List("the", "quick", "brown", "fox")
scala>
words filter (_.length == 3)
res38:
List[java.lang.String] = List(the, fox)
def partition(p: (A) ⇒ Boolean): (List[A], List[A])
与filter相似,只不过filter返回的是满足条件的所有元素列表;而这个除了返回满足条件的列表以外,不满足条件的列表也会返回,并且这两个列表组成一个Tuple2后返回
xs partition p 等价于 (xs filter p, xs filter (!p(_)))
scala>
List(1, 2, 3, 4, 5) partition (_ % 2
== 0)
res39:
(List[Int], List[Int]) = (List(2, 4),List(1, 3, 5))
def find(p: (A) ⇒ Boolean): Option[A]
返回第一个相匹配的元素所对应的Option值
scala>
List(1, 2, 3, 4, 5) find (_ %
2 == 0)
res40:
Option[Int] = Some(2)
scala> List(1, 2, 3, 4, 5) find (_ <= 0)
res41:
Option[Int] = None
final def takeWhile(p: (A) ⇒ Boolean): List[A]
返回满足条件的所有靠前面的元素,一旦某个元素不满足,立即返回,不管后面还是否有满足条件的元素
final def dropWhile(p: (A) ⇒ Boolean): List[A]
dropWhile则取的为takeWhile的补集,它们两所取集合刚好互补
scala> List(1, 2, 3, -4, 5)
takeWhile (_ > 0)
res42: List[Int] = List(1, 2, 3)
scala> List(1, 2, 3, -4, 5) dropWhile (_ > 0)
res8: List[Int] = List(-4, 5)
scala> val words = List("the", "quick", "brown", "fox")
scala> words dropWhile (_ startsWith "t")
res43: List[java.lang.String] = List(quick, brown, fox)
final def span(p: (A) ⇒ Boolean): (List[A], List[A])
span是将takeWhile与dropWhile组合成一个操作,满足与不满足都会返回,且以Tuple2元组返回
xs span p 等价于 (xs takeWhile p, xs dropWhile p)
scala> List(1, 2, 3, -4, 5) span (_
> 0)
res44: (List[Int], List[Int]) = (List(1, 2, 3),List(-4, 5))
13.7.3 判断条件:forall 、exists
def forall(p: (A) ⇒ Boolean): Boolean
如果为空列表,或者列表中所有元素满足指定的条件才为true;注:空列表时,判断条件根本不会走,只要条件编译通过即可
def exists(p: (A) ⇒ Boolean): Boolean
只要有一个满足条件即返回true;注:空列表返回false
示例:判断矩阵中是否有一行全是0的:
scala> def hasZeroRow(m: List[List[Int]]) = m
exists (row => row forall (_ == 0))
hasZeroRow: (List[List[Int]])Boolean
scala> hasZeroRow(diag3)
res45: Boolean = false
当为空列表时:
scala> var l = List(1).tail
l: List[Int] = List() //空列表的类型Int
scala> l.forall(_ > 0)
res20: Boolean = true
scala> Nil
res18: scala.collection.immutable.Nil.type = List()
scala> List()
res19: List[Nothing] = List() //空列表的类型Nothing
scala> List() == Nil
res16: Boolean = true
scala> Nil.forall((x)=>{println("--"); x.toString.length == 0})
res17: Boolean = true
scala> Nil.exists((x)=>{println("--"); x.toString.length == 0})
res22: Boolean = false
13.7.4 折叠/:、:\
def /:[B](z: B)(op: (B, A) => B): B = foldLeft(z)(op) //B为折叠结果类型,也为初始值类型,A为列表元素类型
对给定的初始值元素z以及列表中所有元素进行op函数操作,每次op函数需两个参数:op第一次操作的第一个参数为初始元素z,第二个参数为列表中的第一个元素,经过op函数操作运算后返回一个与初始元素z类型相同类型为B的结果,这个结果会被作为第二次op操作函数调用的第一个参数,第二次op操作函数的第二个参数为列表中的第二个参数...并返回最终的叠加结果
从源码可以看出,“/:”方法实质上是对foldLeft方法的调用,foldLeft方法才是真正实现的方法:
def foldLeft[B](z: B)(op: (B, A) => B): B = {//B为折叠结果类型,也为初始值类型,A为列表元素类型
var result = z //初始值
this foreach (x => result = op(result, x))//每次op操作完后的结果再次传入op进行下一次操作
result
}
比如前面计算一个整数列表的和sum(foreach应用),可以这样更简单来实现:
var sum = (0 /: List(1, 2, 3, 4, 5))(_ + _) //15
上面这种“(0 /: List(1, 2, 3, 4, 5))(_ + _)”是一种柯里化操作符调用的一种形式,并且将操作符 /: 应用在了第一个参数列表中(但为什么 初始值要放在前面而不是后面?右折叠却又是正常放在后面的,这种约束是在哪里设定的?请看这里)。上面写法实质与下面写法一样:
var sum = List(1, 2, 3, 4, 5)./:(0)(_ + _) //15
【另外看一个柯里化操作符调用:
class A {
def sum(x: Int)(y: Int) = x + y
}
new A().sum(1)(2) //3,通过方法通常调用方式进行调用
(new A sum 1)(2) //3,通过柯里化操作符形式调用
注:如果将上面的sum在类外面进行定义时(如在命令行中单独定义),此时就不能通过柯里化操作符形式调用了,只能采用通常的方法调用方式,因为此时方法不属于任何对象:
scala> def sum(x: Int)(y: Int) = x + y
sum: (x: Int)(y: Int)Int
scala> sum(1)(2) //3
res9: Int = 3
】
左折叠(fold left)操作“(z /: xs) (op)”与三个对象有关:初始值z,列表xs,以及二元操作op,折叠的结果是op应用到初始值z及每个元素上,其过程如下:
(z /: List(a, b, c)) (op) 等价于 op(op(op(z, a), b), c)

下面是另一个“/:”操作符的例子,将列表中的单词使用空格连接起来:
scala>val words = List("the", "quick", "brown", "fox")
scala>
("" /: words) (_ +" "+ _)
res46: java.lang.String = the quick brown fox
与左折叠“/:”操作对应的是右折叠操作符“:\”,不同的是,op的第一个参数是折叠的列表元素,第二个为初始值,且从列表中的最后一个元素向前面开始应用op函数。从源码可以看出,实质上最后都是以调用foldLeft方法来实质的,只是从最后一个元素开始应用op函数:
def :\[B](z: B)(op: (A, B) => B): B = foldRight(z)(op) //B为折叠结果类型,也为初始值类型,A为列表元素类型
def foldRight[B](z: B)(op: (A, B) => B): B = //B为折叠结果类型,也为初始值类型,A为列表元素类型
reversed.foldLeft(z)((x, y) => op(y, x)) //先反转,再调用左折叠
(List(a, b, c) :\ z) (op) 等价于 op(a, op(b, op(c, z)))
下面是一个将嵌套列表List[List[T]]展平的示例,这两个结果一样,但右折叠方法效率会高一点,这与:::操作符实现有关:
(List[Int]() /: List(List(1, 2), List(3, 4), List(5, 6)))(_ ::: _) //List(1, 2, 3, 4, 5, 6)
(List(List(1, 2), List(3, 4), List(5, 6)) :\ List[Int]())(_ ::: _) //List(1, 2, 3, 4, 5, 6)
通过左折叠来实现反转列表,时间复杂度为n,比前面章节中的rev效率要高:
def reverseLeft[T](xs: List[T]) = (List[T]() /: xs) { (ys, y) => y :: ys }
reverseLeft(List(1, 2, 3)) //List(3, 2, 1)
13.7.5 列表排序:sortWith
def sortWith(lt: (A, A) ⇒ Boolean): List[A] // A为列表元素类型
根据指定比较函数lt进行排序,且排序是稳定的,最终实质上是调用 java.util.Arrays.sort进行排序的
scala> List(1, -3, 4, 2, 6) sortWith
(_ < _)
res48: List[Int] = List(-3, 1, 2, 4, 6)
List("Steve", "Tom", "John", "Bob").sortWith(_.compareTo(_) < 0) // List("Bob", "John", "Steve", "Tom")
scala>val words = List("the", "quick", "brown", "fox")
scala>
words sortWith (_.length > _.length)
res49: List[java.lang.String] = List(quick, brown, the , fox)
13.8 List伴生对象的方法
前面讲的都是List类中的方法,针对某个对象才能使用,还有些方法是定义在全局可访问对象scala.List上的,它是List类的伴生对象
13.8.1 工厂方法:List.apply
def apply[A](xs: A*): List[A]
通过给定的元素来创建列表。前面看到过创建列表时使用了形如List(1, 2, 3)来创建列表,这种列表字面量只是List对象对元素1、2、3的简单应用,即List(1, 2, 3)是等价于List.apply(1, 2, 3):
scala> List.apply(1, 2, 3)
res50: List[Int] = List(1, 2, 3)
请注意与List类的apply方法区别
13.8.2 范围列表:List.range
def range[T](start: T, end: T, step: T): List[T]
创建从start到end(不包括,排除),间隔为step的整数列表。step可以是正也可以是负数
def range[T](start: T, end: T): List[T]
间隔固定为1
scala> List.range(1, 5)
res51: List[Int] = List(1, 2, 3, 4)
scala> List.range(1, 9, 2)
res52: List[Int] = List(1, 3, 5, 7)
scala> List.range(9, 0, -3)
res53: List[Int] = List(9, 6, 3)
13.8.3 连接多个列表:List.concat
def concat[A](xss: collection.Traversable[A]*): List[A]
将多个列表连接起来
scala> List.concat(List('a', 'b'), List('c'))
res58: List[Char] = List(a, b, c)
scala> List.concat(List(), List('b'), List('c'))
res59: List[Char] = List(b, c)
scala> List.concat()
res60: List[Nothing] = List()
13.9 Scala中的类型推断
前面写了一个归并排序的方法msort,它与List类中的 sortWith在使用是上有区别的,试着比较:
scala> val abcde = List('a', 'b', 'c', 'd', 'e')
scala> msort((x: Char, y: Char) => x
> y)(abcde)
res64: List[Char] = List(e, d, c, b, a)
和:
scala> abcde sortWith (_ > _)
res65: List[Char] = List(e, d, c, b, a)
这两种排序的结果都是一样的,注要区别在于函数传递时,sortWith使用了函数字面量简化形式,但msort不能这么写:
scala> msort(_ >
_)(abcde)
<console>:12: error: missing parameter type for expanded function
((x$1, x$2) => x$1.$greater(x$2))
msort(_
> _)(abcde)
ˆ
在abcde.sortWith(_ > _)中,abcde的类型为List[Char],因此就确定了sortWith方法参数类型为 (Char, Char) => Boolean,并且最终返回结果类型也会随之确定下来为List[Char]。由于函数入参类型已确定,所以就不必要在传递时再明确指出函数参数类型详细信息了。
再来看看msort(_ > _)(abcde),msort的类型是柯里化泛型方法,该方法的第一个参数列表的类型为 (T, T) => Boolean ,第二个参数类型为List[T],并且返回类型也是List[T],其中T是未知的类型,所以不能使用使用msort(_ > _)(abcde)。但如果在调用时指定方法的泛型具体类型,则就可以以这种简化的方式来调用了:
scala> msort[Char](_ >
_)(abcde)
res66: List[Char] = List(e, d, c, b, a)
另一种可能的解决方案是重新改写msort方法的参数列表顺序:
def msort[T](xs: List[T])(less:(T,
T) => Boolean): List[T] = {
// ...
}
现在就可以连泛型的具体类型也不用指定了,因为此时可以根据第一个参数列表的参数类型List[char]来推导出T的类型为char了,既然方法的泛型类型已确定,就自然可以使用下面这种最简洁的形式来调用了:
scala> msort(abcde)(_ > _)
res67: List[Char] = List(e, d, c, b, a)
通常情况下,一旦有有需要推断泛型类型的方法时,类型推断只会参考第一个参数列表中的类型,但如果在调用时第一个参数列表中还是有不确定的参数类型,则也是不行的,如下面将两个参数列表合成一个列表,虽然列表参数放在前,函数放在后面:
def msort[T](xs: List[T],less: (T, T) => Boolean): List[T] = {
但还是不可以这样使用:
scala> msort(abcde,_ > _)
<console>:14: error: missing parameter type for expanded function ((x$1, x$2) => x$1.$greater(x$2))
msort(abcde,_ > _)
^
通过上面的实验可以总结如下的设计原则:设计某个泛型方法时,如果参数中有函数参数以及非函数参数,则要采用柯里化,将参数分成多个参数列表,将明确类型的非函数参数放在第一个参数列表中,而函数参数放在最后一个参数列表中,这样一来,方法的泛型具体类型就可以通过第一个参数列表传递进去的数据的类型来推断出来,这样泛型的类型就可以转而用来完成函数参数的类型检查。从而使得方法的使用者可以避免提供更多的类型信息就能写出更为简洁的函数字面量
另外,再来看看左右折叠操作的定义:
def /:[B](z: B)(op: (B, A) => B): B = foldLeft(z)(op)
def :\[B](z: B)(op: (A, B) => B): B = foldRight(z)(op)
发现都是泛型方法,且泛型类型为B,B类型代替了初始值及最后结果值的类型。A为列表元素类型。由于结果类型与列表元素类型可能不同(也可能相同),所以就单独将它拿出来做为泛型参数了,这样不管结果类型是否与原列表中元素类型相同,都可以应用
14 集合类型
14.1 集合框架
Scala中常用的集合类型:数组(Array)、列表(List)、集(Set)、映射(Map),前面章节已多少使用过。由于标准库中的集合类涉及太多,不能完整的列出,下面只看一下大体结构:
Iterable是主要特质,它是可变与不可变序列(Seq)、集(Set)、映射(Map)人超特质(只要是Iterable的子类,都是可以在循环中进行遍历的,而集合类都是Iterable子类,所以集合类对象都是可以直接在循环中进行遍历)。序列(Seq)是一种有序的集合(插进去是什么样的顺序读出来就是什么样的顺序),例如数组(Array)和列表(List)。集(Set)中的元素不能重复(使用==方法来判断)。映射(Map)是一种键值映射关系的集合。
Iterable特质提供了一个抽像方法:abstract def iterator: Iterator[A],这个抽象方法由集合具体类去实现,所以集合类都提供了一个iterator()方法,用来提供遍历集合中元素的迭代器(枚举器):def iterator: Iterator[A] //泛型类A为集合中元素类型
Iterator特质有许多与Iterable特质相同的方法,但不是集合类的超类,Iterable与Iterator之间的差异与Java中的Comparable与Comparator这两个接口的区别一样:able代表具有某种能力(如可枚举的——指集合、可比较的——指集合中的元素),具有这样能力的类需要实现它们;ator则是侧重于功能的提供(如是怎么枚举的,怎么比较的),类一般不直接从它继承,只是提供一个产生这个ator实例的方法。
另外,Iterable可以被枚举若干次,但Iterator仅能使用一次,一旦使用Iterator枚举遍历了集合对象,你就不能再使用它了,得要再次调用iterator()方法获得
Iterator特质提供了两个重要的抽象方法:
· abstract def hasNext: Boolean
· abstract def next(): A
14.2 序列Seq
序列是继承自特质的Seq的类,保持插入顺序
14.2.1 列表List
前面章节讲过的列表List是一种不可变链接列表(注:不可变不是说不能变,而是说向不可变对象再发生改变后,会返回一个新的对象,而原对象不会发生变化,如Java中的String对象就是一个不可变对象,这也是设计模式中的不可变或叫原型模式),犹如Java中的LinkedList(但是可变的)。链接列表可以支持在列表的头部快速添加和删除,但不能提供对任意索引值的快速访问,因为这需要遍历整个列表才知道元素所在的索引位置。
链接列表的这种可以快速在头部添加和删除元素,这意味着可以很地用于列表的模式匹配应用中,因为在模式匹配中是经常需要将列表分为几部分,这多涉及到列表元素的删除操作与添加操作
scala> val colors = List("red", "blue", "green")
colors: List[java.lang.String] = List(red, blue, green)
scala> colors.head
res0: java.lang.String = red
scala> colors.tail
res1: List[java.lang.String] = List(blue, green)
14.2.2 数组Array
数组是基于一组连续内存分匹配空间,可以通过索引快速的访问任意位置上的元素
注:与Java中的数组一样,一旦创建出来是不能再增减元素的,如果要增减元素,则要使用ArrayBuffer
下面创建一个只有5个元素长度的数组,且元素类型为Int:
scala> val fiveInts = new Array[Int](5)
fiveInts: Array[Int] = Array(0, 0, 0, 0, 0)
创建数组时指定初始化元素:
scala> val fiveToOne
= Array(5, 4, 3, 2, 1)
fiveToOne: Array[Int] = Array(5, 4, 3, 2, 1)
Array("1", "2", "3") 相当于Array.apply("1", "2", "3")
注:Scala中通过索引访问元素时是通过圆括号而不是中括号,如下面修改数组中第1个位置上的值:
scala>
fiveInts(0) = fiveToOne(4)
scala> fiveInts
res1: Array[Int] = Array(1, 0, 0, 0, 0)
val greetStrings: Array[String] = new Array[String](3)
greetStrings(0) = "Hello"
greetStrings(1) = ","
greetStrings(2) = "world!\n"
for (i <- 0 to 2) print(greetStrings(i))
在Scala中,在一个对象(不只是伴生对象)后面跟一对圆括号时,Scala会把它转换成对该对象的apply方法的调用,这个规则不只对于数组,任何对于对象的值参数应用将会被转换为对apply方法的调用,当然前提是这个类型定义过apply,所以:
val greetStrings: Array[String] = new Array[String](3)相当于var greetStrings: Array[String] =Array.apply(null,null,null)
greetStrings(i)相当于greetStrings.apply(i)
所以这就从另一方面说明为什么在Scala中使用圆括号来使用索引,而不是中括号
另外数据元素赋值操作也是相应方法的调用,所以 greetStrings(0) = "Hello" 实质上是 greetStrings.update(0, "Hello")方法的调用
Java方法返回的数组可以在Scala无缝的使用
14.2.3 列表缓存ListBuffer
List类只能提供对列表头部,而非尾部的快速访问。因此,如果你需要向尾部添加元素,你应该考虑先将列表反转后,在头部加上元素,然后再调用reverse反转过来,不过这种效率不是很高。这可以使用ListBuffer来解决。
ListBuffer是一种可变对象(即内部是可以修改的,不会再以新的对象返回),属于scala.collection.mutable包中
ListBuffer实质上是对List链表进行封装
scala> import scala.collection.mutable.ListBuffer
import scala.collection.mutable.ListBuffer
scala> val buf = new ListBuffer[Int]
buf: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
scala> buf += 1 //在尾部追加元素
scala> buf += 2
scala> buf
res11: scala.collection.mutable.ListBuffer[Int] = ListBuffer(1,
2)
scala> 3 +: buf //在头部追加元素
res12: scala.collection.mutable.Buffer[Int]= ListBuffer(3, 1, 2)
scala> buf.toList
res13: List[Int] = List(3, 1, 2)
由于List是不可变对象,在修改时会产生新的List,这样会造成很多对象,这时可以考虑使用ListBuffer来代替它
14.2.4 数组缓存ArrayBuffer
ArrayBuffer是再一次对Array的包装,除了Array所有方法都有以外,还包括了额外的些操作,如向数组中增减元素的一些操作。但是,由于底层还是以数组来实现的,由于数组不适用于添加与删除元素,因为这会涉及到一大片元素的移动,所以一般也不要通过ArrayBuffer来对数组的做增减元素的操作
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
创建ArrayBuffer的时候,必须要指定方法的泛型参数,但可以不用指定初始长度,因为ArrayBuffer可以自动调整分配的空间:
scala> val buf = new ArrayBuffer[Int]()
buf: scala.collection.mutable.ArrayBuffer[Int] =ArrayBuffer()
在末尾添加元素:
scala>
buf += 12
scala> buf += 15
scala> buf
res16: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(12,
15)
所有数组能使用的方法,缓存数组也都能使用,如获取长度,可通过索引访问元素:
scala>
buf.length
res17: Int = 2
scala> buf(0)
res18: Int = 12
14.2.5 队列Queue
队列是先进先出的序列。Scala集合库也提供了可变和不可变的队列
下面创建一个不可变队列:
scala> import scala.collection.immutable.Queue
import scala.collection.immutable.Queue
scala> val empty = Queue[Int]()
//New一个空的队列
empty: scala.collection.immutable.Queue[Int] = Queue()
enqueue入队:
scala> val has1 =
empty.enqueue(1)
has1: scala.collection.immutable.Queue[Int] = Queue(1)
scala> val has123 =
has1.enqueue(List(2, 3)) //可以将某个集合直接列表入队
has123: scala.collection.immutable.Queue[Int] = Queue(1,2,3)
dequeue出队(注:对于不可变队列来说,dequeue方法将返回由队列头部元素和移除该元素之后剩余队列组成的对偶Tuple2):
scala> val (element,
has23) = has123.dequeue
element: Int = 1
has23: scala.collection.immutable.Queue[Int] = Queue(2,3)
可变队列的使用方式与不可变队列一样,只是入队使用 += 及 ++= 操作符添加元素。还有,出队后返回的还是原来的队列(只是头元素被移除了):
scala> import scala.collection.mutable.Queue
import scala.collection.mutable.Queue
scala> val queue = new Queue[String]
//New一个空的队列
queue: scala.collection.mutable.Queue[String] = Queue()
scala> queue += "a"
scala>
queue ++= List("b", "c")
scala> queue
res21: scala.collection.mutable.Queue[String] = Queue(a, b, c)
scala> queue.dequeue
res22: String = a
scala> queue
res23: scala.collection.mutable.Queue[String] = Queue(b, c)
14.2.6 栈Stack
栈是一种后进先出的序列。同样在Scala集合中也有可变和不可变两种栈。元素的入栈使用push,出栈使用pop方法,如果只是获取栈顶元素而不移除的话可以使用top。下面是一个使用可变栈的示例:
scala> import scala.collection.mutable.Stack
import scala.collection.mutable.Stack
scala> val stack = new Stack[Int]
stack: scala.collection.mutable.Stack[Int] = Stack()
scala> stack.push(1)
scala> stack
res1: scala.collection.mutable.Stack[Int] = Stack(1)
scala> stack.push(2)
scala> stack
res3: scala.collection.mutable.Stack[Int] = Stack(2, 1)
scala> stack.top
res8: Int = 2
scala> stack
res9: scala.collection.mutable.Stack[Int] = Stack(2, 1)
scala> stack.pop
res10: Int = 2
scala> stack
res11: scala.collection.mutable.Stack[Int] = Stack(1)
14.2.7 字符串
可以将任何字符当作 Seq[Char]
scala> def hasUpperCase(s: String) = s.exists(_.isUpper)
hasUpperCase: (String)Boolean
scala> hasUpperCase("Robert Frost")
res14: Boolean = true
scala> hasUpperCase("e e cummings")
res15: Boolean = false
示例中,调用了字符串s的exists方法,而String类本身并没有定义exists方法,但编译器会隐式转换为Seq[Char]类型
14.3 集(Set)、映射(Map)
set与map都有可变和不可变,不同包中的set、map决定了是可变还是不可变,immutable包下的为不可变,mutable包下的是可变。针对不可变集合操作后,导致元素个数发生改变的操作,如 + 操作(请看这里)会导致产生一个新的集合。下面是Set与Map的简化继承图:

注意:从图可以看出Set与Map在三个包中都是相同的名称,只是所在的包位置不一样
在默认情况下你使用“Set”或“Map”的时候,获得的都是不可变对象,如果需要可变版本,则要明确导入import。这种默认使用的就是不可见版本主要就来自于Predef对象的支持,Predef对象是每个Scala源文件隐含导入import的。Predef中定义的默认Set与Map:
object Predef {
type Set[T] = scala.collection.immutable.Set[T]
type Map[K, V] = scala.collection.immutable.Map[K,
V]
val Set = scala.collection.immutable.Set
val Map = scala.collection.immutable.Map
// ...
}
“type”关键字把scala.collection.immutable.Set[T]类 与 scala.collection.immutable.Map[K, V] 类以短的类路径形式重新定义成了Set[T]类与Map[K, V]类,这样在程序中就可以直接实例化Set[T]类与Map[K, V]类了,而不需要先import再实例new;另外,“val”关键字也将 scala.collection.immutable.Set伴生对象与scala.collection.immutable.Map伴生对象重新定义,这样在程序里也就可以直接使用Set与Map伴生对象(实质上为Predef.Set与Predef.Map);由此可见Predef的重新定义一切都是为了编程上的简化,当然更是一种默认的设置——默认设置不可变的Set和Map
如果在同一个源文件中既要用到可变版本,也要用到不可变版本的集合或映射,那就只能明确引入了:
scala> import scala.collection.mutable
import scala.collection.mutable
scala> val mutaSet = mutable.Set(1, 2, 3)
mutaSet: scala.collection.mutable.Set[Int] = Set(3, 1, 2)
14.3.1 集Set
集Set中的元素不会重复(Java中的Set也是不重复的),是否重复是通过对象的“==”操作符进行检测的

注:不可变Set中没有 “+=”、“-=”之类的方法,只有“+”、“-”方法,所以“=”是赋值操作,而不是方法名的一部分,所以针对不可变Set“set += 1”其实就是“set = set + 1”
14.3.2 映射Map
与Java中的Map一样,Key也是唯一的,不会重复



14.3.3 默认Set与Map
scala.collection.mutable.Set()工厂方法返回scala.collection.mutable.HashSet哈希类型的Set scala.collection.mutable.Map()工厂方法返回scala.collection.mutable.HashMap哈希类型的Map
而不可变Set与Map情况则更为复杂一些,如scala.collection.immutable.Set()工厂方法返回的什么样的Set则取决于你传递给它多少元素:

类似的,scala.collection.immutable.Map()工厂方法返回什么样的Map取决于传递进去的键值对数量:

不可变Set与Map工厂方法根据元素的数量来决定返回什么新的集合对象,目的是为了最优的性能,如果向EmptySet中添加元素,它将返回给你Set1,如果向Set1中添加元素,将返回Set2,如果再从Set2中删除元素,将又会返回Set1
14.3.4 排序的Set与Map
有时需要特定顺序的Set与Map,这可以通过SortedSet和SortedMap特质来实现(Java中也有相对应的Interface),这两个特质分别由TreeSet和TreeMap实现(嗯,Java中也是这两个实现类,并且Java中的TreeSet底层是通过TreeMap来实现的),与Java中的TreeMap一样,排序的算法也是通过红黑树来实现的。具体的顺序取决于元素混入的Ordered特质(犹如Java排序集合中的元素要实现Comparable接口一样),或者元素要能隐式地转换成Ordered特质。
排序Map:
scala.collection.immutable.SortedMap
scala.collection.mutable.SortedMap
排序Set:
scala.collection.immutable.SortedSet
scala.collection.mutable.SortedSet
scala> import scala.collection.mutable.TreeSet
import scala.collection.mutable.TreeSet
scala> val ts = TreeSet(9, 3, 1, 8, 0, 2, 7, 4, 6, 5)
ts: scala.collection.mutable.TreeSet[Int] = TreeSet(0, 1, 2, 3,
4, 5, 6, 7, 8, 9)
scala> val cs = TreeSet('f', 'u', 'n')
cs: scala.collection.mutable.TreeSet[Char] = TreeSet(f, n, u)
scala> import scala.collection.immutable.TreeMap
import scala.collection.immutable.TreeMap
scala> var tm = TreeMap(3 -> 'x', 1 -> 'x', 4 -> 'x')
tm: scala.collection.immutable.TreeMap[Int,Char]
= Map(1 -> x, 3 -> x, 4 -> x)
scala> tm += (2 -> 'x')
scala> tm
res38: scala.collection.immutable.TreeMap[Int,Char]
=Map(1 -> x, 2 -> x, 3 -> x, 4 -> x)
14.3.5 同步的Set与Map
如果想要线程安全的Map,可以把SynchronizedMap特质混入到特定实现类中,如把SynchronizedMap混入到HashMap:
//首先引入了scala.collection.mutable 包下面的Map、SynchronizedMap、HashMap
import scala.collection.mutable.{
Map,
SynchronizedMap,
HashMap
}
object MapMaker {
//创建一个线程安全的HashMap,该Map可用于多线程环境下
def makeMap: Map[String, String] = {
//实例化一个可变HashMap的同时,并混入SynchronizedMap,这样编译器将会产生
//混入了SynchronizedMap的HashMap合成子类对象,并且这个合成子类还重写了名
//为default的方法
new HashMap[String, String] with SynchronizedMap[String, String] {
//默认情况下,在Map找到不时会抛NoSuchElementException异常,但这个默认性为
//可以通过重写default方法来改变,如这里找到时,返回一个如下字符串
override def default(key: String) ="Why do you want to know?"
}
}
}
通过查看SynchronizedMap源码,发现里面的所有方法都是synchronized,这样就在HashMap类的实现方法外层套了一层同步方法而已(Java中可以通过java.util.Collections工具类来产生这样的同步集合):

scala> val capital =
MapMaker.makeMap
capital: scala.collection.mutable.Map[String,String] = Map()
scala> capital ++= List("US"
-> "Washington","Paris"
-> "France", "Japan"
-> "Tokyo")
res0: scala.collection.mutable.Map[String,String] = Map(Paris
-> France, US -> Washington, Japan -> Tokyo)
scala> capital("Japan")
res1: String = Tokyo
scala> capital("New Zealand")
res2: String = Why do you want to know?
scala> capital += ("New Zealand" -> "Wellington")
scala> capital("New Zealand")
res3: String = Wellington
与上面创建同步的HashMap一样,可以通过混入SynchronizedSet创建同步的HashSet:
import scala.collection.mutable
val synchroSet = new mutable.HashSet[Int] with mutable.SynchronizedSet[Int]
虽然可以通过上面的方式来创建同步的Set与Map,但也可以直接使用java.util.concurrent包下面的并发集合,又或者,还可以使用非同步的集合与actor相结合,actor在后面章节会有介绍
14.4 可变(mutable)集合Vs.不可变(immutable)集合
不可变集合对于编程会更简单一些,但在大数据量的情况下,或频繁修改的情况下,可变集合性能会高一些
如果集合中的元素数量不多,不可变集合的数据存储还常常比可变集合更为紧凑,如HashMap默认实现的空映射占大约80字节,而每添加一个元素就多占用16个字节,而空的不可变Map是可以在所有引用中共享的单例对象(可变集合在多个对象中共享很易容问题,如线程安全就是一个问题),仅需要在所引用的地方需一个引用字段即可。还有,Scala库当对小于5个元素集合还做了优化,已经为每一种小于5个元素的集合定义了单独的类,如Set1~Set4、Map1~Map4,它们分别占用16到40字节不等,因此,对于较小的映射或集来说,不可变版本比可变版本的对象更为紧凑。由于多数集合都比较小,所以不可变类型将节省大量空间并提高性能
不可变集合与可变集合之间是可以很方便的转换的,Scala提供了一些语法糖,即使不可变Set与Map中并没有真正的 “+=” 方法(全面的说是不可变Set与Map中就根本没有以“=”结尾的方法名),但Scala还是为此提供了“+=”的语法解释,如:如果你对不可变Set写了 a += b(a为不可变Set对象,b为待添加的元素),而a集中并没有 += 方法(但有“+”这样的方法),Scala将会把它解释为 a = a + b:
scala> val people = Set("Nancy", "Jane")
people: scala.collection.immutable.Set[java.lang.String]
= Set(Nancy, Jane)
scala> people += "Bob"
<console>:6: error: reassignment to val
people += "Bob"
ˆ
上面报错并不是说不可变Set不支持“+=”这样的操作,而是因为“+=”操作会返回一个新的不可变Set对象,并赋值给people,但people却又是val型的,所以报错了,如果将val修改为var则可以运行成功:
scala> var people = Set("Nancy", "Jane")
people: scala.collection.immutable.Set[java.lang.String]
=Set(Nancy, Jane)
scala> people += "Bob"
scala> people
res42: scala.collection.immutable.Set[java.lang.String] = Set(Nancy,
Jane, Bob)
虽然不可变Set集中并没有“+=”方法,但解释器会将“=”解释为赋值等于号,而不是方法名的一部分,这也就解释了为什么会对不可变Set与Map进行元素增减时,会返回一个新的集合对象。
相应的Set 中还有“-”、“++”方法,也可以与“=”结合起来使用:
scala>
people -= "Jane"
scala> people ++= List("Tom", "Harry")
scala> people
res45: scala.collection.immutable.Set[java.lang.String] = Set(Nancy,
Bob, Tom, Harry)
下面来看看这种语法糖的方便之处:
var capital = Map("US" -> "Washington", "France" -> "Paris")
capital += ("Japan" -> "Tokyo")// 此处的“=”属于赋值等于号,Scala解释器自己会知道
println(capital("France"))
这段代码使用了不可变的Map,如果你想尝试改用可变集合,仅需要用可变版本的Map即可,这样就可以重写对不可变Map的默认引用:
import scala.collection.mutable.Map // 这是唯一要改的地方,即将可变Map引入进来,下面其他代码不变!!!
var capital = Map("US" -> "Washington", "France" -> "Paris")
capital += ("Japan" -> "Tokyo")// 此处的“=”属于可变Map“+=”方法名的一部分,Scala解释器自己也会知道
println(capital("France"))
注:切换后,并不是所有代码都不需要修改,这种只针对以等号结尾的方法是便于切换的,而那些在可变与不可变集合中相互不存在,存在但不尽相同的方法就会有问题了
另外,这种语法糖不仅对集合有效,其它类也是可以的,如浮点Double类中也没有“+=”这样的方法,但可以使用:
scala> var roughlyPi
= 3.0
roughlyPi: Double = 3.0
scala> roughlyPi += 0.1
scala> roughlyPi += 0.04
scala> roughlyPi
res48: Double = 3.14
这种效果就类似于Java中的赋值操作符:+=、-=、*=
14.4.1 Map可变与不可变
scala> val ages = Map("Leo" -> 30, "Jen" -> 25, "Jack" -> 23)
ages: scala.collection.immutable.Map[String,Int] = Map(Leo -> 30, Jen -> 25, Jack -> 23)
scala> ages("Leo") = 31 //不可变Map中的内容是不能直接通过key索引方式来修改的,但可以通过 + 来修改(实质产生成的Map)
<console>:15: error: value update is not a member of scala.collection.immutable.Map[String,Int]
ages("Leo") = 31
^
scala> ages += "Leo"->31 //由于ages定义成了val不可变的,所以新返回一个Map时出错。Map的 + 操作即像集合中添加元素的意思,只要是改变元素个数的操作就会产生新的Map(不管待加入元素是否存在,哪怕值一样)
<console>:15: error: value += is not a member of scala.collection.immutable.Map[String,Int]
ages += "Leo"->31
^
scala> var ages = Map("Leo" -> 30, "Jen" -> 25, "Jack" -> 23)
ages: scala.collection.immutable.Map[String,Int] = Map(Leo -> 30, Jen -> 25, Jack -> 23)
scala> var ages2 = ages
ages2: scala.collection.immutable.Map[String,Int] = Map(Leo -> 30, Jen -> 25, Jack -> 23)
scala> ages eq ages2
res0: Boolean = true //指向的是同一对象
scala> ages("Leo") = 31 //修改内容,哪怕将ages定义成可变的,但不可变Map内容还是不可变
<console>:15: error: value update is not a member of scala.collection.immutable.Map[String,Int]
ages("Leo") = 31
^
scala> ages += "Leo"->31
scala> ages eq ages2
res4: Boolean = false //由于上面会产生一个新的Map(虽然个数没变,只是内容发生变化,但还是会产生新的Map),所以ages改变了指向,指向了新产生的Map集合
scala> ages
res4: scala.collection.immutable.Map[String,Int] = Map(Leo -> 31, Jen -> 25, Jack -> 23)
scala> ages2 = ages
ages2: scala.collection.immutable.Map[String,Int] = Map(Leo -> 31, Jen -> 25, Jack -> 23)
scala> ages eq ages2
res5: Boolean = true
scala> ages += ("Leo"->31) // 哪怕内容不变,这种+还是会产生新Map
scala> ages eq ages2
res7: Boolean = false
scala> ages2 = ages
ages2: scala.collection.immutable.Map[String,Int] = Map(Leo -> 31, Jen -> 25, Jack -> 23)
scala> ages eq ages2
res8: Boolean = true
scala> ages += "Leo"->31
scala> ages eq ages2
res10: Boolean = false
14.5 初始化集合
最常见的创建和初始化集合的办法是把初始值传递给相应伴生对象的工厂方法,只须把元素放在伴生对象名后面的括号中,编译器就会把它转化为该伴生对象的apply方法调用:
scala> List(1, 2, 3)
res0: List[Int] = List(1, 2, 3)
scala> Set('a', 'b', 'c')
res1: scala.collection.immutable.Set[Char] = Set(a, b, c)
scala> import scala.collection.mutable
import scala.collection.mutable
scala> mutable.Map("hi" ->2, "there" ->5)
res2: scala.collection.mutable.Map[java.lang.String,Int] = Map(hi ->2, there ->5)
scala> Array(1.0, 2.0, 3.0)
res3: Array[Double] = Array(1.0, 2.0, 3.0)
上面绿色为推导出来的类型。尽管初始化时可以让Scala编译器从传递给工厂方法的元素推断集合的元素类型,但有时需要初始化创建出来的集合可以存放不同类型的元素(但要求这些元素有同样的超类),这时不能靠类型推导,而是在创建时指定类型。比如现要即可以存放Int,也可存放String类型的元素,则需要创建Any类型的集合:
scala> val stuff = mutable.Set[Any](42)
stuff: scala.collection.mutable.Set[Any] = Set(42)
另一种较特殊情况:使用一个集合来初始化另一个集合,如想通过列表来初始化一个TreeSet:
scala> val colors = List("blue", "yellow", "red", "green")
colors: List[java.lang.String] = List(blue, yellow, red, green)
根据不能用List列表来初始一个TreeSet
scala> import scala.collection.immutable
import scala.collection.immutable
scala> val treeSet = immutable.TreeSet(colors) //注:如果是加入到其他非排序集合中是可以的,如HashMap
<console>:15: error: No implicit Ordering defined for List[String].
val treeSet = TreeSet(colors)
^
此时,只能先创建一个空的TreeSet[String]对象并使用TreeSet的++操作符把列表元素加入其中:
scala> val treeSet = immutable.TreeSet[String]() ++ colors
treeSet: scala.collection.immutable.SortedSet[String] = Set(blue, green, red, yellow) //注:已经排序了
TreeSet[String]() 等价于 TreeSet.empty[String]
14.5.1 集合转化为数组(Array)、列表(List)
将集合转化为列表只需调用集合的toList方法:
scala> val treeSet = TreeSet("blue", "yellow", "red", "green")
scala> treeSet.toList
res54: List[String] = List(blue, green, red, yellow)
将集合转化为数组只需调用集合的toArray方法:
scala> treeSet.toArray
res55: Array[String] = Array(blue, green, red, yellow)
注:TreeSet的toList与toArray返回的集合中的元素也是经过排序了的
另外,转化为列表或数组同样需要复制集合的所有元素,因此对于数据量大的集合比较慢
14.5.2 Set与Map的可变和不可变互转
有时需要将可变的Set或Map转换成不可变的Set或Map,或者反向转换,这可以利用前面的以List列表初始化TreeSet的技巧。比如现想把当前使用的可变集合转换成不可变集合,可以先创建一个空的不可变集合,然后调用不可变集合的 ++ 操作符将可变集合中的元素添加进去。
scala> import scala.collection.mutable
scala> val mTreeSet = mutable.TreeSet("blue", "yellow", "red", "green")
mTreeSet: scala.collection.mutable.TreeSet[String] = TreeSet(blue, green, red, yellow)
scala> val iTreeSet =Set.empty ++ mTreeSet //可变Set转换为不可变Set
iTreeSet: scala.collection.immutable.Set[String] = Set(blue, green, red, yellow)
scala> val mTreeSet = mutable.Set.empty ++ iTreeSet //再将不可变Set转换为可变Set
mTreeSet: scala.collection.mutable.Set[String] = Set(red, blue, green, yellow)
可以使用同样的技巧在可变映射与不可映射之间互转:
scala> import scala.collection.mutable
scala> val muta = mutable.Map("i" ->1, "ii" ->2)
muta: scala.collection.mutable.Map[java.lang.String,Int] =Map(ii ->2, i ->1)
scala> val immu = Map.empty ++ muta
immu: scala.collection.immutable.Map[java.lang.String,Int] =Map(ii ->2, i ->1)
14.6 元组Tuples
元组可以把固定数量元素组合在一起整体传输,与数组与列表不同,元组可以存放不同类型的对象,如下面定义了一个3个元素的Tuple3类型的元组,第一个元素的类型为Int,第二个元素类型为String,第三个元素类型为List:(1,"String",List()),它们每个
由于元素里放的元素是不同类型的对象,所以不能继承自Iterable,所以元组是一种不可遍历的集合
元组常用在方法的多值返回情况下,如果某个方法要返回多个值,一般我们使用数组,但有了元组后,使用元组将多个值组合成整体后返回
元组的实际类型取决于它含有的元素数量和这些元素的类型,如(99, "String")的类型是Tuple2[Int,String]。('u', 'r', 'the',1,4, "me")是Tuple6[Char, Char, Char,Int,Int,String],理论上可以创建任意长度的元组,但目前Scala库只支持到最大Tuple22
元组实例化之后,可以用 _1、_2…属性字段名(索引从1开始而非0)来访问其中的元素:
val pair = (99, "String")
pair._1//99
pair._2//String
可以将元组赋值给元组模式,这样提取每个元素就会很方便:
scala> val (i,s) = pair
i: Int = 99
s: String = String
不能像访问列表中的元素那样访问元组中的元素,如pair(0),那是因为列表中的apply方法始终返回同样的类型,但元组里的类型不尽相同,所以两者访问方法不一样,另外, _N 的索引是基于1的,而不是0
15 类型参数化(泛型)
15.1 主/从/父构造器、工厂方法
class A0{
println("父类主构造器" )
def this(f1:Int) = {this();println("父类子构造器 f1="+f1 )}
}
/**
* 每个类只有一个主构造函数,类名后面跟的参数列表(如果有)就是主构造函数的
* 参数列表。class body里所有除去字段和方法声明的语句,剩下的一切都是主构造函数的,
* 它们在class实例化时一定会被执行
*
* 从构造器就不能直接调用父类构造器,得让主构造器去调用(即在extends后面由参数来决定调用父类哪个构造器,主还是辅),
* 也只有主构造函数才能将参数传递到父类的构造函数中去
*
* 定义名称为this的方法为从构造器;主构造器不能显示定义,它是在类定义时自动生成的(如果带参数,则在类名后括号中指定),且
* 参数列表为类名后面跟的参数列表,但可以通过this来调用主构造器
*
* 由于构造器在调用其他构造器(注:在子类的辅助constructor是决不可以直接调用父类的constructor的,父类的主或辅助构造器是由子类主
* 构造器去调用)时,都只能放在构造函数第一句进行调用(而且在定义辅助构造器时,第一句一定要是调用主或辅助构造器),这样在
* 执行子类构造器前,会一定先执行完父类构造器,再执行子类构造器,并且这个执行顺序刚好与构造器调用顺序相反,这是由于调用
* 形成的栈决定的
*
* 主构造器在调用父类构造器时,可以决定调用父类里的哪个构造器,这是在继承时,后面参数
* 决定的,如这里的A0(f1)
*
* 如果将主构造器定义成private的,则外部就不能通过主构造器来实例化该类了。如这里如果
* 将A类的主构造器参数列表前加上private后,则下面的 new A(1, 2, 3) 编译就会出错
* 同样的道理,如果将某个从构造器定义成了private,则外部也不能通过该从构造器来实例化
* 该类了。如将this(f1: Int)定义成私有后,new A(1)编译就会出错
*/
class A /*private*/ (private val f1: Int, private val f2: Int, private val f3: Int) extends A0(f1){
//Scala会将类的内部即不是字段定义也不是方法定义的代码编译到主构造器中
println("主构造器");
//从构造器。注:从构造函数必须以调用主构造函数或者从构造器开始。
def this(f1: Int, f2: Int) = {
//这里调用的是主构造器
this(f1, f2, 0);//调用主构造器。注:构造器的调用也只能放在第一句,这与Java相似
println("this(f1,f2)从构造器")
}
//从构造器,调用另一从构造器
/*private*/ def this(f1: Int) = { this(f1, 0); println("this(f1)从构造器") }
}
new A(1)
println("----------------------")
new A(1, 2)
println("----------------------")
new A(1, 2, 3)

如果在同一源文件中定义一个与class类名相同的object,则这个object就是该类的伴生对象,这个类就是该对象的伴生类。当定义出伴生对象后,就可以为类定义工厂方法了:
object A {
def apply(f1: Int) = { println("伴生对象的apply工厂方法");new A(f1)}
}
A(2) //相当于A.apply(2)

注:伴生对象是可以访问伴生类中除了private[this]修饰以外的任何修饰符修饰的东西
class A {
def getF1 = { println("成员字段f1初始化"); 1 }
/**
* 成员字段与其它所有非方法里的语句,都属于主构造器中的语句
* 在实例化之前,成员字段会被初始化,且主构造器语句也会被执行
* 且初始化与执行顺序与书写的顺序一致
*
* 如下面四个语句会按顺序执行:
*/
println("主构造器语句1执行")
println("f1=" + f1)//虽然可以访问f1,但f1还未初始化,因为访问在定义之前了
private[this] var f1 = getF1
println("f1=" + f1)
var f2 = getF2
println("主构造器语句2执行")
def this(x: Int) = { this() /*调用主构造器*/ ; println("this(" + x + ")") }
def getF2 = { println("成员字段f2初始化"); 2 }
}
new A(3)

一般超类调用之后,才初始化子类的成员字段:
abstract class A {
val f1: Int = getF2
def getF2: Int
}
class B extends A {
val f2: Int = 2
def getF2: Int = { println(f2); f2 }
}
//输出的是0,而不是2,这与Java是一样的
new B //0
但可以通过在以下的语法来让子类成员在超类构造器调用前初始化:
abstract class A {
val f1: Int = getF2
def getF2: Int
}
class /*object也可*/ B extends { val f2: Int = 2; private[this] var a: Int = 1 } with A {
// val f2: Int = 2
def getF2: Int = { println(f2); f2 }
}
new B //2
如果是匿名类,则可以这样:
new { val f2: Int = 2 } with A { def getF2: Int = { println(f2); f2 } } //2
但要注意的是,花括号中是不能使用this的(如上面calss B中),除非是在实例化匿名类时(如上面的 new …with A),但此时this指向的是new语句所在的对象,而不是B
懒加载
object Demo {
val x = { println("initializing x"); "done" }
}
Demo //initializing x,对象实例化后就已初始化
object Demo {
lazy val x = { println("initializing x"); "done" }
}
Demo //
Demo.x //initializing x,直到使用时才初始化
上面是object,下面calss也是一样:
class Demo {
val x = { println("initializing x"); "done" }
}
var d = new Demo//initializing x
class Demo {
lazy val x = { println("initializing x"); "done" }
}
var d = new Demo //
d.x //initializing x
注:lazy只能修饰val,而不能是var
15.2 暴露接口与隐藏类
//向外部显露的接口,特质的作用类似Java中的Interface接口
trait A {
def f
}
object A {
/**
* 注:这里apply后面的方法返回类型不能省略,如果省略后,推断出类型为B,
* 但B是私有的类,不能向外提供,所以会编译出错。但如果B是public的,则可
* 以省略方法类型
*/
def apply: A = new B()
//具体类定义成private将其隐藏,向外通过特质提供接口
private class B extends A {
def f = println("B")
}
}
15.3 Scala中的泛型
在Scala中,使用泛型类(或特质)时,必须指定类型参数:
class A[T]
var t: A[String] = null
var t: A = null //编译出错:没有为A指定类型参数
class A
class B extends A
trait T[T]
尽管B是A的子类,但T[B]不是T[A]的子类:
var t1:T[A] = null
var t2:T[B] = null
t2 = t1//编译出错
如果修改成trait T[+T],则上面可以编译通过;
如果修改成trait T[-T],则下面也可编译通过
t1 = t2//编译出错
1)trait T[T] {}
这是非变情况。这种情况下,当类型B是类型A的子类型,也不认为T[B]是T[A]的子类,这种情况是和Java一样的
2)trait T[+T] {}
这是协变情况。这种情况下,当类型B是类型A的子类型,则可以认为T[B]是T[A]的子类。也就是被参数化类型的泛化方向与参数类型的泛化方向是一致的,所以称为协变
3)trait T[-T] {}
这是逆变情况。这种情况下,当类型B是类型A的子类型,则反过来可以认为T[A]是T[B]的子类型。也就是被参数化类型的泛化方向与参数类型的泛化方向是相反的,所以称为逆变
List[String]之所有是List[AnyRef]的子类,从List源码可以看出List类的类型参数是协变的,所以可以:
![]()
下面定义的Cell类为非协变的,编译是没有问题:
class Cell[T](init: T)
{
private[this] var current =
init
def get = current
def set(x: T) { current = x }
}
但在T前加上+后,set方法编译就会出问题
class Cell[+T](init: T)
{//注:如果是在init前加上了var,则这里编译还是会有问题,因为var构造参数会生成相应的类成员字段,这样的话会将协变参数传给方法参数,这是不可以的
private[this] var current =
init
def get = current
def set(x: T) { current = x } //编译出错
var x:T =
init //编译出错,因为var变量的成员会自动生产相应的getter(def x: T)与setter(def x_= (init:T))方法,并且setter方法的参数是init,根据规定:参数类型只能是逆变的,不能是协变的,即不允许将使用+号注解的类型参数(如这里的(init: T))赋值给一个var可变字段(如这里的var x:T),因为赋值过程实际上是通过setter方法(def x_= (init:T))进行的,而根据前面的规定协变类型参数是不能传递给方法的
}
原因分析:假设上面Cell[+T]的set方法也可以正常通过编译,且没有var x:T = init语句,则下面代码也就应该可以编译通过(但实际上是有问题的):
val c1 = new Cell[String]("abc")
val c2: Cell[Any] = c1 // 因为Cell的类型参数是协变的,所以c1是c2的子类,所以可以这样赋值
c2.set(1) //这里能调用set方法前提是假设上面Cell[+T]协变类的set方法通正常通过,实际上是不能通过编译的
val s: String = c1.get
上面第1、2行应该是没有什么问题,单独看第3行也是没有什么问题,因为c2元素类型为Any,set(1)当然可以,但第3行与第4行结合起来看,就会有问题,相矛盾:可以将Int类型值赋值给String?这显然是有问题的。这问题的原因就是第二行c1能赋给c2引起的,但c1赋值给c2原本是没有任何问题的,因为父类引用是可以指向子类对象的,但后面通过父类引用(c2)操作子类对象(c1)方法时出现了问题:c2.set只应该将String及String子类传进去,但这里却可将Int类型传递进去了。这里如果c1的T类型为c2里的T类型的父类型则可解决该问题,这就是类型参数逆变
Scala规定,协变([+T])类型只能作为方法的返回类型,而逆变([-T])类型只能作为方法的参数类型(或方法类型参数,如def meow[T]()),当然没有正负号注解的类型是可以用在任何地方的:
class Cell[-T, +U](p: (T) => U, u: U) {//此处的参数u没有任何意义,只是为了测试。构造参数列表里的T与U不受协变与逆变约束
/**
* 该方法中,T与U不能交互位置,因为Scala规定:协变([+T])类型只能作为方法的
* 返回类型,而逆变([-T])类型只能作为方法的参数类型。但构造参数列表除外,如
* 上面的构造参数列表中的T与U是可以互换位置
*/
def f(x: T): U = { p(x) }
}
print(new Cell[Int, String](_.toBinaryString).f(255) ,"") //11111111
函数A=>B 所对应的Function1 协变与逆变同时存在:
trait Function1[-S,+T] {
def apply(x: S): T
}
参数要求变逆变、返回类型要求协变的原因:父类出现的地方子类也可以出现,这是里氏替换原则
Scala上界(<:)和下界(>:)
1) U >: T
这是类型下界的定义,也就是U必须是类型T的父类(或本身)
class Cell[+T](init: T) {
//协变类型不能直接用在方法参数列表中,因为参数列表类型
//要求是逆变的
// def set(x: T) {}
//可通过类型定界来解决这个问题
def set[U >: T](x: U) {}
}
2) S <: T
这是类型上界的定义,也就是S必须是类型T的子类(或本身)
要注意的是,协变并不会被继承,父类声明协变,子类如果想要保持,仍需要声明成协变的(逆变也是一样):
scala>trait A[+T]
defined trait A
scala>class C[+T] extends A[T]
defined class C
scala>class X; class Y extends X;
defined class X
defined class Y
scala>val c:C[X] = new C[Y]
15.4 Java中的泛型
extends的作用在于定界,而定界又是为了调用某个泛型类的方法:
//边界接口
interface HasColor { java.awt.Color getColor(); }
class Colored<T extends HasColor> {
T item;
Colored(T item) { this.item = item; }
T getItem() { return item; }
// 允许调用边界接口的方法:
java.awt.Color color() { return item.getColor(); }
}
//边界类
class Dimension { public int x, y, z; }
// 多个边界时,边界接口要放在边界类后面,并且与继承一样: 多个边界时,只允许一个边界类,但允许多个边界接口
class ColoredDimension<T extends Dimension & HasColor> {
T item;
ColoredDimension(T item) { this.item = item; }
T getItem() { return item; }
//访问边界接口方法
java.awt.Color color() { return item.getColor(); }
//访问边界类中的成员
int getX() { return item.x; }
int getY() { return item.y; }
int getZ() { return item.z; }
}
通配符?的疑问:
class Fruit {}
class Apple extends Fruit {}
class Jonathan extends Apple {}
class Orange extends Fruit {}
public class CompilerIntelligence {
public static void main(String[] args) {
// ? 通配符,flist指向存放Fruit及任何子类List容器
List<? extends Fruit> flist = Arrays.asList(new Apple());
// 使用通配符定义的引用,不能通过该引用调用任何带有泛型参数的方法。如这里只知道flist中的元素类型为Fruit或其子类,如果为某个子类时,则另一子类是不能add进去的,所以干脆不允许调用任何带有泛型参数的方法
// !! flist.add(new Apple());
// !! flist.add(new Fruit());
// 但可调用返回参数类型是泛型的方法,尽管返回类型为泛型
// 但不管返回的是什么,至少是Fruit类型,所以是合理的
Apple a = (Apple) flist.get(0); // No warning
// 但可调用参数不是泛型参数的方法,通过查看源码,我们发现
// contains与indexOf的参数类型都是Object
flist.contains(new Jonathan());
flist.indexOf(new Fruit());
}
}
extends用来定上界:
<T extends MyClass>是用来解决不能调用泛型类型参T及实例的方法的问题,即解决了类型边界问题。
<? extends MyClass>是用来解决 “ArrayList<Fruit> list = new ArrayList< Apple>();”编译出错的问题或者是方法参数的传递问题。如果A是B的子类,则“ArrayList<? extends A> list = new ArrayList<B>();”,但““ArrayList<A> list = new ArrayList<B>();”是不行的
super用来定下界:
只能有<? super MyClass>形式,不能是<T super MyClass>
ArrayList<? extends Fruit>与ArrayList<? super Jonathan>的区别:
class Fruit {}
class Apple extends Fruit {}
class Jonathan extends Apple {}
class OtherJonathan extends Jonathan {}
public class SuperTypeWildcards {
static void writeTo(List<? extends Apple> apples) {
/*
* ArrayList<? extends Fruit>表示它定义的list1引用可指向能存放
* Fruit及其子类的容器实例,但不能真真的向容器里放入任何东西除了
* null。
*
* 这里使用的是 extends ,所以new ArrayList<XXX>()中的XXX只能是
* Fruit 或其子类。
*/
ArrayList<? extends Fruit> list1 = new ArrayList<Apple>();
// !! list1.add(new Apple());
// !! list1.add(new Fruit());
Fruit f = list1.get(0);//这是没有问题的,因为取出来的元素肯定是Fruit或其子类
/*
* ArrayList<? super Jonathan>表示它定义的list2引用可指向能存
* 放Jonathan及子类实例的容器,与上面不同的是可以向其中放入对象。
*
* 这里使用的是 super ,所以new ArrayList<XXX>()中的XXX只能 是
* Jonathan 或其父类,因为只有这样才能确保创建出来的容器能存 放
* Jonathan及子类实例
*/
ArrayList<? super Jonathan> list2 = new ArrayList<Fruit>();
// !! list2.add(new Fruit());//不能存入Fruit
// !! list2.add(new Apple());//不能存入Apple
list2.add(new Jonathan());
list2.add(new OtherJonathan());
// Jonathan j = list2.get(0); //编译出错,因为取出来的元素不一定为Jonathan,还有可能是Object类型
Object j = list2.get(0); //但取出来的肯定是Object
// 类型参数中含有super关键字所定义的引用只能指向类型参数及父类的实例
// !! ArrayList<? super Apple> list13 = new ArrayList<Jonathan>();
}
}
15.5 类型成员
trait Abstract {
//可以使用 <: 或 >: 来限制 T 的上界或下界,如:type T <: String
type T //抽象类型,在子类中指出具体类型
def transform(x: T): T //抽象方法,因为没有方法体
val initial: T //抽象常量,因为没有初始化
var current: T //抽象变量,因为没有初始化
}
class Concrete extends Abstract {
type T = String//T为String类型的别名
def transform(x: String) = x + x
val initial = "hi"
var current = initial
}
15.6 枚举
object Color extends Enumeration {
val Red = Value
val Green = Value
val Blue = Value
}
object Direction extends Enumeration {
val North = Value("North")
val East = Value("East")
val South = Value("South")
val West = Value("West")
}
scala> for (d <- Direction) print(d +" ")
North East South West
枚举值是从0开始编号的:
scala> Direction.East.id
res5: Int = 1
通过编号来使用枚举:
scala> Direction(1)
res6: Direction.Value = East
16 隐式转换
附件列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号