问题梳理
reeantrantlock 原理
synchronized
早期是重量级锁,用户态转成核心态,效率低。
后来优化了。java6后优化了。
- 自适应自旋
- 锁消除
- 锁粗话
- 轻量级
- 偏向锁
- 重量级
自旋锁与自适应自旋锁
共享数据的锁定持续时间短,切换线程不值得。
线程执行循环,不让出CPU。
自旋java6后默认开启。
java6后,引入自适应自旋锁,自旋的次数不确定。
锁消除
虚拟机的优化,对运行上下文,确定不能竞争的锁,就把锁删除掉。
StringBuffer sb = new StringBuffer(); sb.append("112233");
这种,单线程操作,是没有锁的在jvm里。
锁粗话
扩大锁范围,避免加锁和解锁。
锁升级
同一线程多次获得,锁就偏向锁 ;偏向锁,当前线程ID == markWorkId时 ,就可以直接访问
场景:-》
第二个线程加入锁的争用,就升级轻量级。适用交替执行。
场景:-》
同一时间访问同一个锁,就会升级为重量级锁。

Reentrantlock 重入锁
java5开始引入。
lock() 后要 uncock()
公平: 锁给等待时间最久的线程。 synchronized不公平。公平吞吐量不高。
可以设置等待时间。
Lock方法,底层调用unsafe的park()方法 unsafe: 在任意内存位置出读写数据。
公平锁 会在获得锁时,判断aqs队列是否有,有的话优先队列中的。
非公平锁,就是直接cas,state为0直接获得锁。
CAS
AtomicInteger 底层基于unsafe
CompletableFuture类
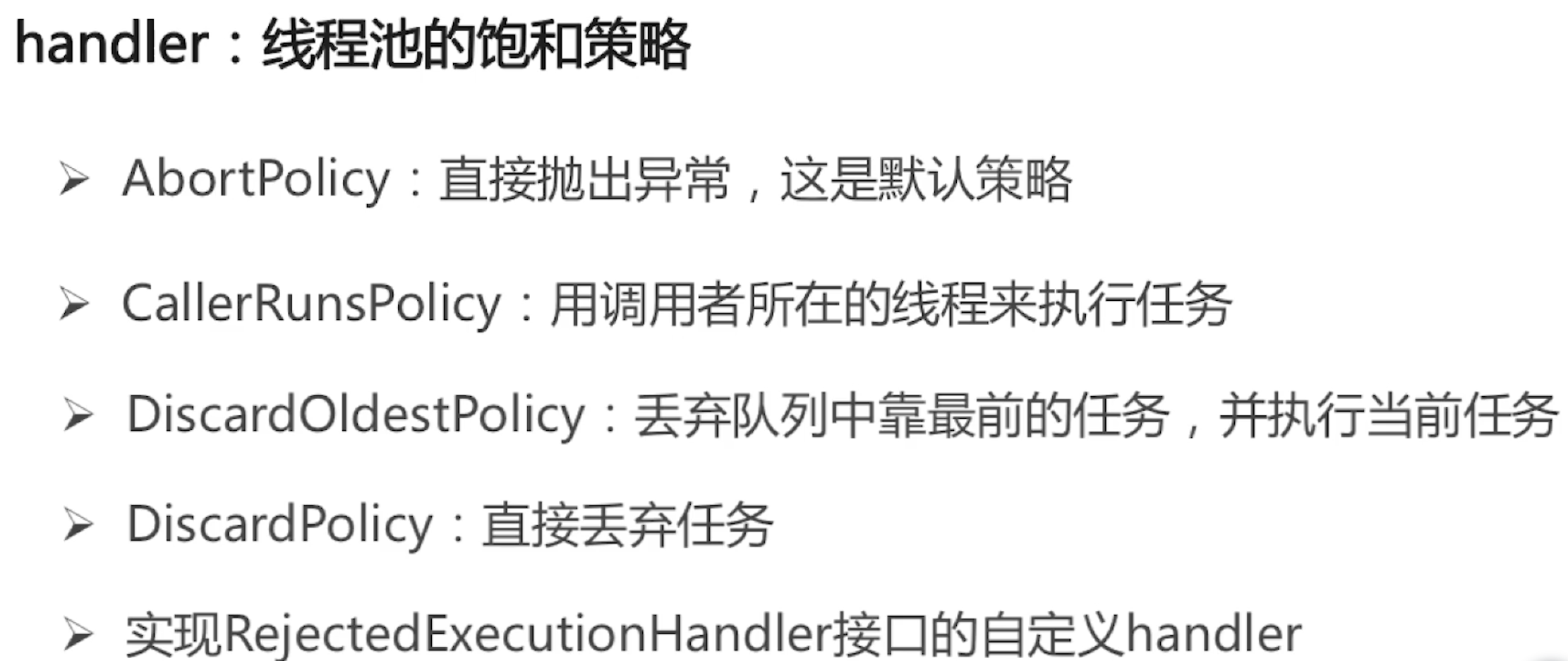
线程池丢弃策略
策略模式 装饰器模式 模板模式
https://www.cnblogs.com/jiangym/p/17590157.html
resource和autowired区别
- 如果是spring容器,两个等价。
不同点:
autowired 先在spring容器中找以bean为类型的Bean实例,如果找不到或者找到多个,则通过fieldName来找。
resource相反。
直白来说
@Autowired
A a 这时先匹配A, 如果A有多个实现类,则找@Component中名为a的,如果找不到就报错。
@Resource
B b 则先找b,如果B有多个实现类,b还匹配不到@Component中名,则在B的实现类中找到多个,则报错。
- @Autowired 可以在构造器上,resource不可以。
- autowired是spring的;resource是jdk的;
循环依赖
https://www.cnblogs.com/jiangym/p/17545169.html
spring相关问题
- ioc、aop的概念
- IOC:通过控制反转。我们可以把对象交给容器管理。我们在想使用的时候从容器中取。
- 不用关心引用bean的实现细节,不用创建多个bean,bean修改对使用方无感知。
- pojo形成BeanDefinition注入到springContainer后,由ApplicationContext调用。
- AOP:面向切面编程。在bean实例的初始化完成,进行后续的beforeInstantiation中生成代理。
- jdk动态代理,不能代理没有接口的类。
- cglib代理。代理没有接口的类。
- 缓存、日志
- IOC:通过控制反转。我们可以把对象交给容器管理。我们在想使用的时候从容器中取。
- 基于字段的依赖注入有什么不好
- 最好用setter注入,也可用构造器注入。基于字段的注入容易npe
- bean初始化流程
- AbstractApplicationContext#refresh
- BeanFactoryPostProcessor
- InitializingBean
- beanPostProcessor
- 销毁
- springboot3新特性
- jdk17最低;
- aot编译(预先编译)加快程序启动;
- spring native对云原生友好。
- spring事务传播机制
- required;required_new;
- supported; not_supported
- mandatory
- never
- nested
- beanFactory和Factorybean区别
- spring常见的使用方式
- spring开启事务
- 编程式事务、
- 手动开启、提交和回滚
- 声明式事务
- @Transational注解
- 没有侵入,管理简单
- 最小力度只能在方法上
- 编程式事务、
- spring设计模式说几个
- ioc是工厂模式
- aop代理模式
- 单例模式:spring的一些bean
- spring循环依赖的解决
- 事务失效的原因有哪些
- 修饰非public方法
- 参数propagation错误
- 在一个类中调用,和private一回事,没有办法走到代理服务。
- 异常被捕获
- 数据库引擎不支持事务
- 怎么让一个bean优先加载
- dependsOn
- aop什么场景下会失效
- springboot和spring区别
- springboot简化了开发和部署,用于快速开发。
- 自动配置
- 内嵌web服务器
- 约定大于配置
- springboot简化了开发和部署,用于快速开发。
- 问什么不要直接用@Async
- simpleAsyncTaskExecutor这个线程不是池,不会复用线程。
什么样的对象能可达性分析 作为根
(1). 虚拟机栈中引用的对象。
(2). 方法区中的类静态属性引用的对象。
(3). 方法区中常量引用的对象。
(4). 本地方法栈中native方法引用的对象。
CMS常用参数
索引覆盖 但排序字段不在索引内 会回表吗
会
订阅binlog 三种log都存什么
binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。
场景是主从复制和数据恢复。
redolog :一个是内存中的日志缓冲(redo log buffer),另一个是磁盘上的日志文件(redo log file)
mysql每执行一条DML语句,先将记录写入redo log buffer,后续某个时间点再一次性将多个操作记录写到redo log file。
redo log是InnoDB特有的
undo log主要记录了数据的逻辑变化,
比如一条INSERT语句,对应一条DELETE的undo log,
对于每个UPDATE语句,对应一条相反的UPDATE的undo log,
这样在发生错误时,就能回滚到事务之前的数据状态
分库分表都在什么时候用
垂直划分业务,分库
水平分表,降低单表数据量。
索引优化
redis
https://www.cnblogs.com/jiangym/p/15839229.html
MQ
对于消息可靠性、消息顺序性等原理
消息堆积、消息丢失等问题解决经验
战报牌迁移
优惠券抢券功能,及怎么防刷的。
todo
Elasticsearch
高性能分布式搜索引擎;
数据存储在多节点上。
索引划分为多个分片;
全文索引;倒排索引;把词对应的文件存储下来
索引优化;
高效存储引擎;
异步请求处理;
内存存储,es使用了内存存储技术。
ZooKeeper
分布式配置管理;集群管理,master选举,负载均衡,
CP的分布式系统,牺牲可用性。
Spring源码
数据库锁机制
具有 SQL 调优、分库分表、索引优化、数据库灾备
Kafka原理与rocketMq的对比 消息可靠性,顺序性,nacos,zookeeper深入研究。
hbase
Mysql常用版本及特点
redis常用版本及特点
springboot版本及特点 熟悉框架实现原理和优缺点
多线程技术和数据库的调优经验;对JVM有深入理解,精通JVM性能调优
掌握Mysql数据库相关原理;熟悉NoSQL(Redis,MongoDB等)
nginx配置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号