java面经学习001
问题来源:牛客网
链接:https://www.nowcoder.com/discuss/429993?type=post&order=jing&pos=&page=2&channel=-2&source_id=search_post
1. 触发新生代GC,如果存活对象总量大于survivor区容量,咋办
2. 如果任务很多,线程池的阻塞队列会撑爆内存的哪个区域
3. 栈在堆上吗
4. GC root有哪些
5. 实例变量可以是GC root吗
6. 了解哪些GC算法,介绍一下
7. 给个场景,问怎么设置JVM参数
8. 问了很多SQL调优,各种语句能不能命中索引,能命中哪些,怎么优化
9. MySQL的一张表里有三个字段ABC,A的种类有1000种,B有1W种,C有10W种,ABC的联合索引怎么设置,怎么使用
10. Mybatis # 和 $ 的区别
11. Mybatis接口里的方法和XML里的SQL名可以不一样吗,不一样怎么办
12. Mybatis是如何完成SQL和接口里的方法的映射的(我回答了怎么配置),那你知道它是怎么实现的吗
13. 介绍下Spring的 IOC和AOP
14. 服务器给客户端发送IO流的过程
15. IO和NIO了解多少
16. 线程都有哪些状态,怎么转换的
17. Notify和notifyAll的区别
18. 介绍线程池,不同线程池区别在哪,你平时怎么使用线程池的
19. MySQL索引的数据结构
20. B+树了解多少
21. Cookie和SessionId说一下
22. 锁是怎么实现的
23. Synchronized同步块和synchronized方法,分别锁的是什么
24. 单例模式,饿汉和懒汉分别存在的问题
25. Volatile是怎么实现可见性的
26. 介绍下JMM
27. Happen before了解吗
28. A happen before B,意味着A一定在B之前执行吗
1. 触发新生代GC,如果存活对象总量大于survivor区容量,怎么办?
Java 堆内存分为新生代和老年代,新生代中又分为1个 Eden 区域 和两个 Survivor 区域(S0、S1)。
- 对于 Minor GC 的触发条件:大多数情况下,直接在 Eden 区中进行分配。如果 Eden区域没有足够的空间,那么就会发起一次 Minor GC;
- 对于 Full GC(Major GC)的触发条件:需要大量连续存储空间的对象会直接分配到老年代、长期存活的对象晋升到老年代,老年代空间不足以存放这些对象的时候会触发Full GC。
- 在JDK8中移除了永久代,改用了Metaspace,它也是方法区的一种实现,不过它与永久代最大的区别是Metaspace并不在虚拟机中,而是使用本地内存。当Metaspace空间不足进行回收时,需同时满足如下三个条件的类才会被卸载:该类所有的实例都已经被回收、加载该类的ClassLoader已经被回收、该类对应的java.lang.Class对象没有任何地方被引用,进而触发Full GC。
- 在发生Minor GC前,会检查老年代是否有足够的连续空间,如果当前老年代最大可用连续空间小于平均历次晋升到老年代大小,则触发Full GC。
2. 如果任务很多,线程池的阻塞队列会撑爆内存的哪个区域
Java中数据的存储位置分为以下5种:
- 寄存器:最快的存储区,位于处理器内部,但是数量极其有限。所以寄存器根据需求进行自动分配,无法直接人为控制。
- 栈内存:位于RAM当中,通过堆栈指针可以从处理器获得直接支持。堆栈指针向下移动,则分配新的内存;向上移动,则释放那些内存。这种存储方式速度仅次于寄存器。常用于存放对象引用和基本数据类型,而不用于存储对象)
- 堆内存:堆相对于栈的好处来说:编译器不需要知道存储的数据在堆里存活多长。当需要一个对象时,使用new写一行代码,当执行这行代码时,会自动在堆里进行存储分配。同时,因为以上原因,用堆进行数据的存储分配和清理,需要花费更多的时间。
- 常量池:常量(字符串常量和基本类型常量)通常直接存储在程序代码内部(常量池)。这样做是安全的,因为它们的值在初始化时就已经被确定,并不会被改变。常量池在java用于保存在编译期已确定的,已编译的class文件中的一份数据。它包括了关于类,方法,接口等中的常量,也包括字符串常量,如String s = "java"这种申明方式
- 非RAM存储区:如果数据完全存活于程序之外,那么它可以不受程序的任何控制,在程序没有运行时也可以存在。其中两个基本的例子是:流对象和持久化对象。
堆内存
3.栈在堆上吗
来自:https://blog.csdn.net/wangmx1993328/article/details/89041186
Java 栈(Stack)
1、Java 栈是与每一个线程关联的,JVM 在创建每一个线程的时候,会分配一定的栈空间给线程,Java Stack 为每个线程独享。
2、Java Stack 主要用来存储线程执行过程中的局部变量,方法的返回值,以及方法调用上下文(对象的引用), 以帧为单位保存线程的运行状态。
3、栈空间随着线程的终止而释放。
4、StackOverflowError:如果在线程执行的过程中,栈空间不够用,那么 JVM 就会抛出此异常,这种情况一般是死递归造成的。
堆(Heap)
1、Java 中堆是由所有的线程共享的一块内存区域,堆用来保存各种 JAVA 对象,比如数组,线程对象等。
2、JVM 堆一般又可以分为以下三部分:新生代、老年代、永久区:
- Perm(永久区)
Perm 代主要保存 class(类,包括接口等),method(方法),filed(属性) 等元数据,这部分的空间一般不会溢出,除非一次性加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到 java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因就有可能是每次都重新部署,但是重新部署后,类的 class 没有被卸载掉,这样就造成了大量的 class 对象保存在了 perm 中,这种情况下,一般重新启动应用服务器可以解决问题。
- Tenured(年老代)
Tenured 区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在 Young 复制转移一定的次数以后,对象就会被转移到 Tenured 区,一般如果系统中用了 application 级别的缓存,缓存中的对象往往会被转移到这一区间。
- Young(年轻代)
Young 区被划分为三部分,Eden(伊甸园) 区和两个大小严格相同的 Survivor(幸存者)区,其中 Survivor 区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制对象用。
在 Young 区间变满的时候,minor GC 就会将存活的对象移到空闲的 Survivor 区间中,根据 JVM 的策略,在经过几次垃圾收集后,任然存活于 Survivor 的对象将被移动到 Tenured 区间
Apple app = new Apple(); app 引用存在栈里,引用地址对应对象 Apple 在堆里。
4.GC root有哪些
什么是GC root ?
https://www.zhihu.com/question/53613423/answer/135743258 -- RednaxelaFX
所谓“GC roots”(或者说 tracing GC的“根集合”)就是一组必须活跃的引用。一定是是一组必须活跃的引用,而不是对象。例如:当前所有正在被调用的方法的引用类型的参数/局部变量/临时值。
Tracing GC的根本思路就是:给定一个集合的引用作为根出发,通过引用关系遍历对象图,能被遍历到的(可到达的)对象就被判定为存活,其余对象(也就是没有被遍历到的)就自然被判定为死亡。注意再注意:tracing GC的本质是通过找出所有活对象来把其余空间认定为“无用”,而不是找出所有死掉的对象并回收它们占用的空间。 GC roots这组引用是tracing GC的起点。。要实现语义正确的tracing GC,就必须要能完整枚举出所有的GC roots,否则就可能会漏扫描应该存活的对象,导致GC错误回收了这些被漏扫的活对象。
有哪些:
一个对象可以属于多个root,GC root有几下种:
- 虚拟机栈(本地变量表)引用的对象;
- 方法区静态属性引用的对象;
- 方法区常量引用的对象;
- 本地方法栈JNI(一般指naive方法)中引用的对象;
5.实例变量可以是GC root吗
Java语言支持的变量类型有:
- 类变量:独立于方法之外的变量,用 static 修饰。
- 实例变量:独立于方法之外的变量,不过没有 static 修饰。
- 局部变量:类的方法中的变量。
public class Variable{
static int allClicks=0; //类变量
String str="hello world"; //实例变量
public void method(){int i =0; }//局部变量
}
- 实例变量在对象创建的时候创建,在对象被销毁的时候销毁;
- 实例变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息;
- 实例变量可以声明在使用前或者使用后;
6. 了解哪些GC算法,介绍一下
- 标记清除(Mark-Sweep)
- 复制(Copying)
- 标记整理(Mark-Compact)
- 分代收集(Generational Collection)
1.标记清除
2.复制
首先在使用时候,将内存分为两块AB,回收后将A部分所有的存活对象移动到B,将A空闲出来。这种操作解决了碎片的问题,但也暴露出相应的弊端,比如说空间的浪费,在使用的时候将储存空间一分为二,内存优势大打折扣,一次GC触发之前只能用一半内存来工作。另一个显而易见的问题就是,当对象很多的时候,逐个复制去调整位置,也是个大问题。
3.标记整理
将对象标记之后,全部存活的对象向一端移动,然后清理掉存活对象边界以外的内存。
4.分代收集
这种方法内存空间分为了 老年代和新生代,老年代的特点就是其中的对象不怎么被回收,而新生代的特点就是其中的对象要经常被回收,
在老年代,由于对象回收量较小,所以一般采用标记整理算法。在新生代,由于对象回收量较大,所以一般采用复制算法。
但是也不是说一定要付出复制算法的超高代价,因为实际应用中,一般将新生代划分为一块大的Eden和两块小的Survivor空间,每次使用一块Eden和一块Survivor,当回收时,把所有的存活对象Copy到另一块Survivor上,其余的空间全清理,然后继续使用这块Survivor和Eden来进行操作。
7. 给个场景,问怎么设置JVM参数
https://blog.csdn.net/wang379275614/article/details/78471604
8.问了很多SQL调优,各种语句能不能命中索引,能命中哪些,怎么优化
https://www.cnblogs.com/jiangym/p/12968827.html
9. MySQL的一张表里有三个字段ABC,A的种类有1000种,B有1W种,C有10W种,ABC的联合索引怎么设置,怎么使用
联合索引是由多个字段组成的索引。
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name (index_col_name,...) index_col_name: col_name [(length)] [ASC | DESC]
如果你经常要用到多个字段的多条件查询,可以考虑建立联合索引,一般是除第一个字段外的其它字段不经常用于条件筛选情况,比如说a,b 两个字段,如果你经常用a条件或者a+b条件去查询,而很少单独用b条件查询,那么可以建立a,b的联合索引。如果a和b都要分别经常独立的被用作查询条件,那还是建立多个单列索引。 --百度百科
索引是key index (a,b,c)。 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
10. Mybatis # 和 $ 的区别
- #传入的参数在SQL中显示为字符串(当成一个字符串),会对自动传入的数据加一个双引号。
- $传入的参数在SqL中直接显示为传入的值
- #可以防止SQL注入的风险(语句的拼接);但$无法防止Sql注入。
- $方式一般用于传入数据库对象,例如传入表名。
- 表名作为变量时,必须使用 ${ }
11. Mybatis接口里的方法和XML里的SQL名可以不一样吗,不一样怎么办
(实体类中的属性名和表中的字段名不一样,可以使用resultMap标签来自定义映射。)
12. Mybatis是如何完成SQL和接口里的方法的映射的(我回答了怎么配置),那你知道它是怎么实现的吗
https://mybatis.org/mybatis-3/zh/sqlmap-xml.html
resultType 期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
</selectKey>
resultMap 对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。
<resultMap id="userResultMap" type="User"> <id property="id" column="user_id" /> <result property="username" column="user_name"/> <result property="password" column="hashed_password"/> </resultMap> <select id="selectUsers" resultMap="userResultMap"> ... </select>
源码:https://blog.csdn.net/mz4138/article/details/81132980#%E9%81%8D%E5%8E%86resultmap%E6%A0%B9%E8%8A%82%E7%82%B9
13. 介绍下Spring的 IOC和AOP
IOC
https://blog.csdn.net/zhangcongyi420/article/details/89419715
- spring ioc指的是控制反转,“控制反转”,不是什么技术,而是一种设计思想。IOC容器负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。交由Spring容器统一进行管理,从而实现松耦合。
- 传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对 象的创建;
- 谁控制谁?IoC 容器控制了对象;
- 控制什么?主要控制了外部资源获取(不只是对象包括比如文件等)。
- 传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;
- 为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;
- 哪些方面反转了?依赖对象的获取被反转了。
当web容器启动的时候,spring的全局bean的管理器会去xml配置文件中扫描的包下面获取到所有的类,并根据你使用的注解,封装到全局的bean容器中进行管理,一旦容器初始化完毕,beanID以及bean实例化的类对象信息就全部存在了,现在我们需要在某个service里面调用另一个bean的某个方法的时候,我们只需要依赖注入进来另一个bean的Id即可,调用的时候,spring会去初始化完成的bean容器中获取即可,如果存在就把依赖的bean的类的实例化对象返回给你,你就可以调用依赖的bean的相关方法或属性等;
AOP
AOP为Aspect Oriented Programming的缩写,利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
(1)Aspect(切面):通常是一个类,里面可以定义切入点和通知
(2)JointPoint(连接点):程序执行过程中明确的点,一般是方法的调用
(3)Advice(通知):AOP在特定的切入点上执行的增强处理,有before,after,afterReturning,afterThrowing,around
(4)Pointcut(切入点):就是带有通知的连接点,在程序中主要体现为书写切入点表达式
(5)AOP代理:AOP框架创建的对象,代理就是目标对象的加强。Spring中的AOP代理可以使JDK动态代理,也可以是CGLIB代理,前者基于接口,后者基于子类
14. 服务器给客户端发送IO流的过程
流是一种抽象概念,它代表了数据的无结构化传递。按照流的方式进行输入输出,数据被当成无结构的字节序或字符序列。从流中取得数据的操作称为提取操作,而向流中添加数据的操作称为插入操作。用来进行输入输出操作的流就称为IO流。换句话说,IO流就是以流的方式进行输入输出 -- 百度百科
字节缓冲输出流,BufferedOutputStream
https://baijiahao.baidu.com/s?id=1658663993265649977&wfr=spider&for=pc
- 创建FileOutputStream对象,构造方法中绑定要输出的目的地
- 创建BufferedOutputStream对象,构造方法中传递BufferedOutputStream对象,提高BufferedOutputStream对象效率
- 使用BufferedOutputStream对象中的方法write,把数据写入到内部缓冲区
- 使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中。
- 释放资源(会先调用flush方法刷新数据,可省略)
15. IO和NIO了解多少
https://www.cnblogs.com/xiaoxi/p/6576588.html
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。
| IO | NIO |
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
1、面向流与面向缓冲
Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2、阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3、选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
16. 线程都有哪些状态,怎么转换的
线程:进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。一个车间里,可以有很多工人。他们协同完成一个任务。线程就好比车间里的工人。一个进程可以包括多个线程。车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。 --http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
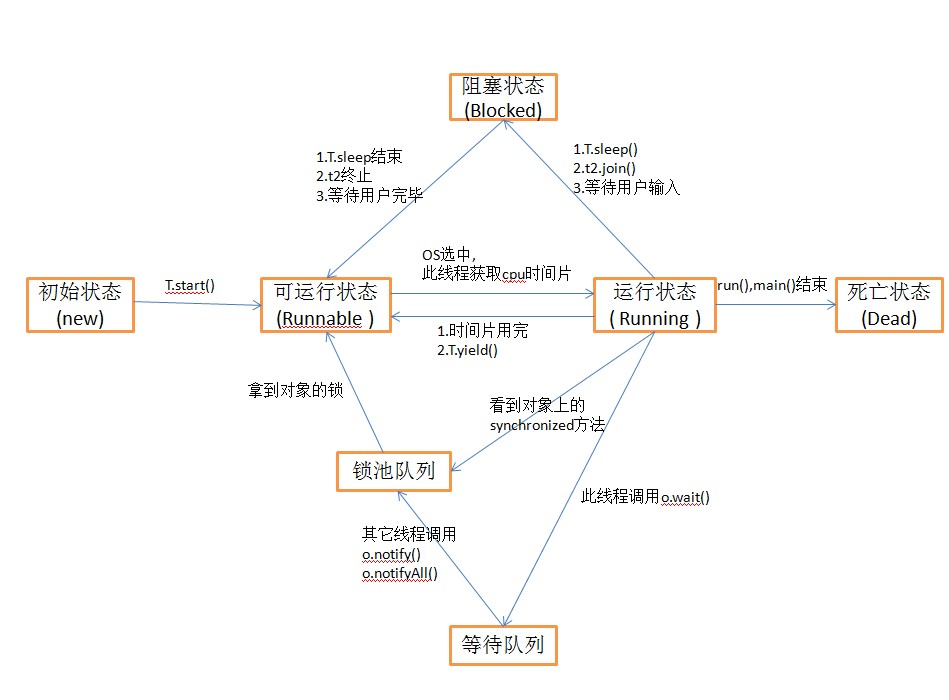
图16-1
17. Notify和notifyAll的区别
由图16-1可知,进入等待队列后,会由notify或notifyAll唤醒
当你调用notify时,只有一个等待线程会被唤醒而且它不能保证哪个线程会被唤醒,这取决于线程调度器。虽然如果你调用notifyAll方法,那么等待该锁的所有线程都会被唤醒,但是在执行剩余的代码之前,所有被唤醒的线程都将争夺锁定,这就是为什么在循环上调用wait,因为如果多个线程被唤醒,那么线程是将获得锁定将首先执行,它可能会重置等待条件,这将迫使后续线程等待。因此,notify和notifyAll之间的关键区别在于notify()只会唤醒一个线程,而notifyAll方法将唤醒所有线程。
18. 介绍线程池,不同线程池区别在哪,你平时怎么使用线程池的
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
Java通过Executors提供四种线程池
newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级执行。
- newCachedThreadPool 创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖 于操作系统(或者说JVM)能够创建的最大线程大小。
- newFixedThreadPool 创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束 ,那么线程池会补充一个新线程。
- newScheduledThreadPool 创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
- newSingleThreadExecutor 创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
多线程处理数据。
(线程A+线程B与线程C是并行,当A+B时间处理完成后,等待0.2s,获取C的返回值,一同结束,这样就缩短了程序的执行时间,可以使用线程的feature.get方法,带参数则等待参数的时常,超时抛出runtime,不带参数则一直等待取到结果)
(可以用来做海量数据的处理,当我们要从kafka中截取大量字符并作筛选,这时就可以开多个线程同时处理,以免堆积)。
19. MySQL索引的数据结构
Mysql支持的索引类型:
- B-Tree
- 哈希索引
- 空间数据索引(R-Tree)
- 全文索引
- 其他索引类别:TokuDB使用分形树索引;括聚簇索引、覆盖索引。
索引优点:
- 索引大大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机I/O变为顺序I/O。
--《高性能Mysql》
20. B+树了解多少
https://blog.csdn.net/endlu/article/details/51720299#commentBox:文章
https://www.bilibili.com/video/BV1DE411i77d?from=search&seid=13671731004673037769:视频
为什么说B+树比B树更适合数据库索引?
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
4、B树在提高了IO性能的同时并没有解决元素遍历的效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
哈希索引和Btree索引的比较
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量.
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
21. Cookie和Session说一下
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
cookie保存session:
用户登录后的id或者是session的key设置到cookie里面。
例如:
设置abc=456,每个用户的value都是不一样的,用户请求的时候读取cookie里的值,拿到用户对应的唯一的key,然后确定唯一的用户,之后就可以去除用户信息进行操作。
只要能定位到用户的方法,就是session的一种实现方案。
用户id也算是用户信息的一部分,一般保存在客户端不安全,可以把id的相关信息转化一下,转化为对应的唯一key,用户信息和sessionkey对应关系就存在服务端数据库或者缓存里,请求过来的时候,读取session key ,取出对应关系就可以。
22. 锁是怎么实现的
锁是一种保护机制,在多线程的情况下,保证操作数据的正确性与一致性。
种类:
- 乐观锁/悲观锁
- 独享锁/共享锁
- 在java中,synchronized关键字,是语言自带的,也叫内置锁,synchronized关键字,被synchronized修饰的方法或者代码块,在同一时间内,只允许一个线程执行,是独享锁
- 互斥锁/读写锁
- 可重入锁
- 公平锁/非公平锁
- 分段锁
- 偏向锁/轻量级锁/重量级锁
- 自旋锁
以上是一些锁的名词,这些分类并不是全是指锁的状态,有的指锁的特性,有的指锁的设计,下面总结的内容是对每个锁的名词进行一定的解释。
23. Synchronized同步块和synchronized方法,分别锁的是什么
https://www.imooc.com/video/18478
24. 单例模式,饿汉和懒汉分别存在的问题
https://www.runoob.com/design-pattern/singleton-pattern.html
单例模式属于创建型模式。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例。
1、懒汉式,线程不安全
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
这种方式是最基本的实现方式,这种实现最大的问题就是不支持多线程。因为没有加锁 synchronized,所以严格意义上它并不算单例模式。
这种方式 lazy loading 很明显,不要求线程安全,在多线程不能正常工作。
2、懒汉式,线程安全
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
优点:第一次调用才初始化,避免内存浪费。
缺点:必须加锁 synchronized 才能保证单例,但加锁会影响效率。
3、饿汉式
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
描述:这种方式比较常用,但容易产生垃圾对象。
优点:没有加锁,执行效率会提高。
缺点:类加载时就初始化,浪费内存。
它基于 classloader 机制避免了多线程的同步问题,不过,instance 在类装载时就实例化,虽然导致类装载的原因有很多种,在单例模式中大多数都是调用 getInstance 方法,
但是也不能确定有其他的方式(或者其他的静态方法)导致类装载,这时候初始化 instance 显然没有达到 lazy loading 的效果。
4、双检锁/双重校验锁
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
这种方式采用双锁机制,安全且在多线程情况下能保持高性能。
5、登记式/静态内部类
这种方式能达到双检锁方式一样的功效,但实现更简单。对静态域使用延迟初始化,应使用这种方式而不是双检锁方式。这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
6、枚举
这种实现方式还没有被广泛采用,但这是实现单例模式的最佳方法。它更简洁,自动支持序列化机制,绝对防止多次实例化。
25. Volatile是怎么实现可见性的
https://www.cnblogs.com/dolphin0520/p/3920373.html
26. 介绍下JMM
JAVA 内存模型(java memory model)允许编译器和缓存以数据在处理器特定的缓存(或寄存器)和主存之间移动的次序拥有重要的特权,除非使用了volatile或Synchronized明确请求了某些可见性的保证。
JMM和堆/栈这些完全不是一个概念,JVM是Java实现的虚拟计算机,而JMM就对应于类似于MSI、MESI这样的缓存一致性协议,用于定义数据读写的规则。
JMM是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
JMM就使用happens-before的概念来阐述多线程之间的内存可见性。happen-before原则是JMM中非常重要的原则,它是判断数据是否存在竞争、线程是否安全的主要依据,保证了多线程环境下的可见性。
27. Happen before了解吗
https://www.cnblogs.com/chenssy/p/6393321.html
happens-before原则定义如下:
1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2. 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
28. A happen before B,意味着A一定在B之前执行吗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号