PostgreSQL 聚合、分组、排序
2022-04-05 15:34 jym蒟蒻 阅读(1958) 评论(0) 收藏 举报聚合函数
用于汇总的函数。
COUNT,计算表中的行数(记录数)。
计算全部数据的行数:
SELECT COUNT(*)
FROM Product;
NULL之外的数据行数:
SELECT COUNT(purchase_price)
FROM Product;
结果如下图。

对于一个含NULL的表:
将列名作为参数,得到NULL之外的数据行数;将星号作为参数,得到所有数据的行数(包含NULL)。
SUM、AVG函数只能对数值类型的列使用。
SUM,求表中的数值列的数据的和。
SELECT SUM(sale_price)
FROM Product;
purchase_price里面的数据有NULL,四则运算中存在NULL,结果也是NULL,但这里面结果不是NULL。
这是因为,聚合函数以列名为参数,计算的时候会排除NULL的数据。
SELECT SUM(sale_price), SUM(purchase_price)
FROM Product;

AVG,求表中的数值列的数据的平均值。
SELECT AVG(sale_price)
FROM Product;
对于列里面数据有NULL的,会事先去掉NULL再计算。如AVG(purchase_price),分母是6而不是8。
SELECT AVG(sale_price), AVG(purchase_price)
FROM Product;

MAX,求表中任意列数据最大值。
MIN,求表中任意列数据最小值。
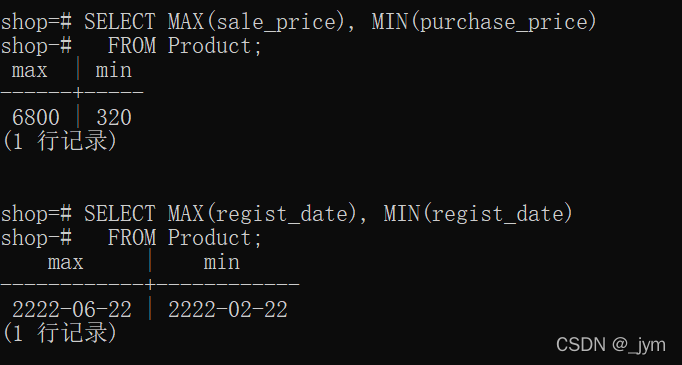
SELECT MAX(sale_price), MIN(purchase_price)
FROM Product;
SELECT MAX(regist_date), MIN(regist_date)
FROM Product;
计算去除重复数据后的数据行数:
DISTINCT要写在括号中,目的是在计算行数前先去重。
SELECT COUNT(DISTINCT product_type)
FROM Product;

所有的聚合函数的参数中都可以使用DISTINCT。
下面这个SUM(DISTINCT sale_price),先把sale_price里面的数据去重,然后再求和。
SELECT SUM(sale_price), SUM(DISTINCT sale_price)
FROM Product;
对表分组:前面使用聚合函数,对表中所有数据进行汇总处理。
还可以先把表分成几组,再进行汇总处理。
格式:
SELECT <列名1>,<列名2>,...
FROM <表名>
GROUP BY <列名1>,<列名2>,...;
按商品种类统计数据:
使用GROUP BY product_type,会按商品种类对表切分。
GROUP BY指定的列,称为聚合键、分组列。
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
按商品种类对表切分,得到以商品种类为分界的三组数据,然后,计算每种商品数据行数。

如果聚合键里面含有NULL,也将NULL作为一组特定数据。
SELECT purchase_price, COUNT(*)
FROM Product
GROUP BY purchase_price;

如果加上WHERE子句,格式如下:
SELECT <列名1>,<列名2>,...
FROM <表名>
WHERE
GROUP BY <列名1>,<列名2>,...;
先根据WHERE子句指定的条件进行筛选,然后再汇总处理。
下面语句的执行顺序:FROM、WHERE、GROUP BY、SELECT。
SELECT purchase_price, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY purchase_price;

使用聚合函数和GROUP BY时需要注意:
1.SELECT子句中,只能存在三种元素:常数、聚合函数、GROPU BY子句指定的列名(聚合键)。
使用GROPU BY子句时,SELECT子句中不能出现聚合键之外的列名。
2.GROUP BY子句里面不能使用SELECT子句中定义的别名。
这是因为SQL语句在DBMS内部先执行GROUP BY子句,再执行SELECT子句。执行GROUP BY子句时候,DBMS还不知道别名代表的是啥,因为别名是在SELECT子句里面定义的。
3.GROUP BY子句执行结果的显示顺序是无序的。
4.只有SELECT子句、HAVING子句、ORDER BY子句里面能使用聚合函数。
使用GROPU BY子句,得到将表分组后的结果。
使用HAVING子句,指定分组的条件,从分组后的结果里面选取特定的组。
格式:
SELECT <列名1>,<列名2>,...
FROM <表名>
WHERE
GROUP BY <列名1>,<列名2>,...;
HAVING <分组结果对应的条件>
下面这个,选出包含两行数据的组。
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING COUNT(*) = 2;

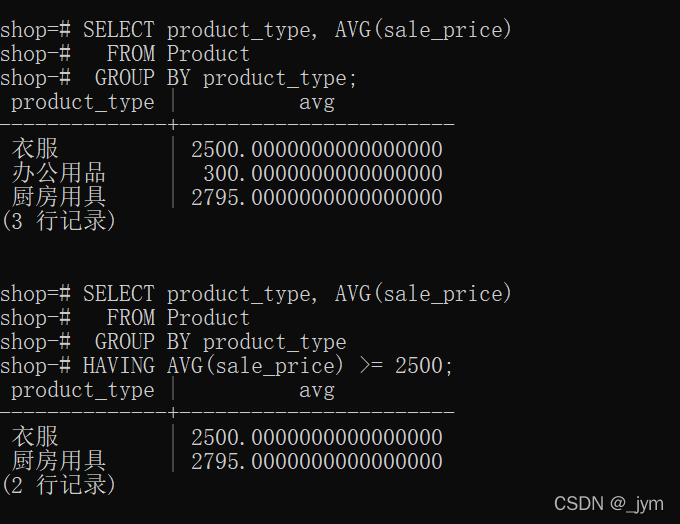
下面这个,选出平均值>=2500的组。
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) >= 2500;
HAVING子句中,能用的三种元素:常数、聚合函数、GROPU BY子句指定的列名(聚合键)。
聚合键所对应的一些条件,可以写在HAVING子句中,也可写在WHERE子句中。
下面两段代码结果都一样。
HAVING子句用来指定组的条件。WHERE子句用来指定数据行的条件。聚合键所对应的一些条件还是写在WHERE子句中好点。
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING product_type = '衣服';
SELECT product_type, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY product_type;

使用ORDER BY子句,可以对查询结果进行排序。
格式:
SELECT <列名1>,<列名2>,...
FROM <表名>
ORDER BY <排序基准列1>,<排序基准列2>,...;
ORDER BY子句写在SELECT语句末尾。
ORDER BY子句里面的列名称为排序键。
使用升序排列,使用ASC关键字,省略这个关键字,默认也是升序排列。
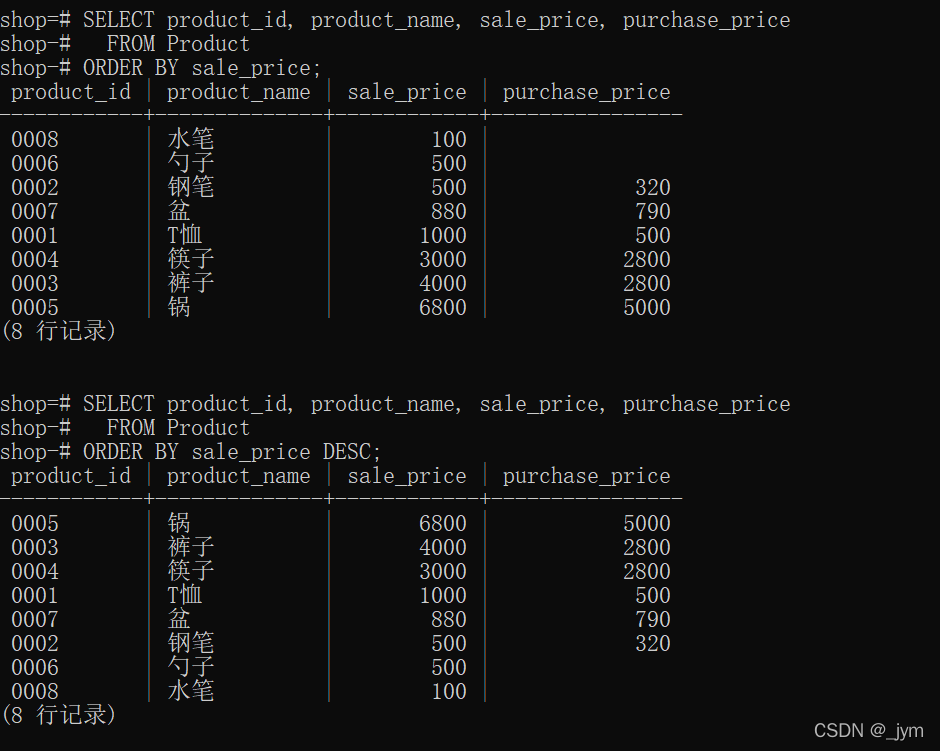
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price;
上面是升序排列,如果想要降序排列,使用DESC关键字。
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price DESC;
上面的排序,sale_price=500的有两个数据,这两个数据的顺序是随机的。
可以再添加一个排序键,对这两个数据排序。
下面就实现了,价格相同时,按照商品编号升序排序。
多个排序键时,优先使用左边的键,该列存在相同值,再参考右边的键。
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price, product_id;

如果,排序键里面有数据是NULL,NULL会在结果的开头或结尾显示。
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY purchase_price;

ORDER BY子句里面可以使用SELECT子句中定义的别名。
这是由SQL语句在DBMS内部执行顺序决定的。SELECT子句执行顺序在ORDER BY前,GROPU BY后。
FROM、WHERE、GROPU BY、HAVING、SELECT、ORDER BY
SELECT product_id AS id, product_name, sale_price AS sp, purchase_price
FROM Product
ORDER BY sp, id;

ORDER BY子句可以使用在表里,但不在SELECT子句里的列。
SELECT product_name, sale_price, purchase_price
FROM Product
ORDER BY product_id;
ORDER BY子句里面可以使用聚合函数。
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
ORDER BY COUNT(*);
 浙公网安备 33010602011771号
浙公网安备 33010602011771号