
nlp RNN 梯度消失和爆炸
2022-04-05 15:01 jym蒟蒻 阅读(253) 评论(0) 收藏 举报之前的RNN,无法很好地学习到时序数据的长期依赖关系。因为BPTT会发生梯度消失和梯度爆炸的问题。
对于RNN来说,输入时序数据xt时,RNN 层输出ht。这个ht称为RNN 层的隐藏状态,它记录过去的信息。
语言模型的任务是根据已经出现的单词预测下一个将要出现的单词。
学习正确解标签过程中,RNN层通过向过去传递有意义的梯度,能够学习时间方向上的依赖关系。如果这个梯度在中途变弱(甚至没有包含任何信息),权重参数将不会被更新,也就是所谓的RNN层无法学习长期的依赖关系。梯度的流动如下图绿色箭头。
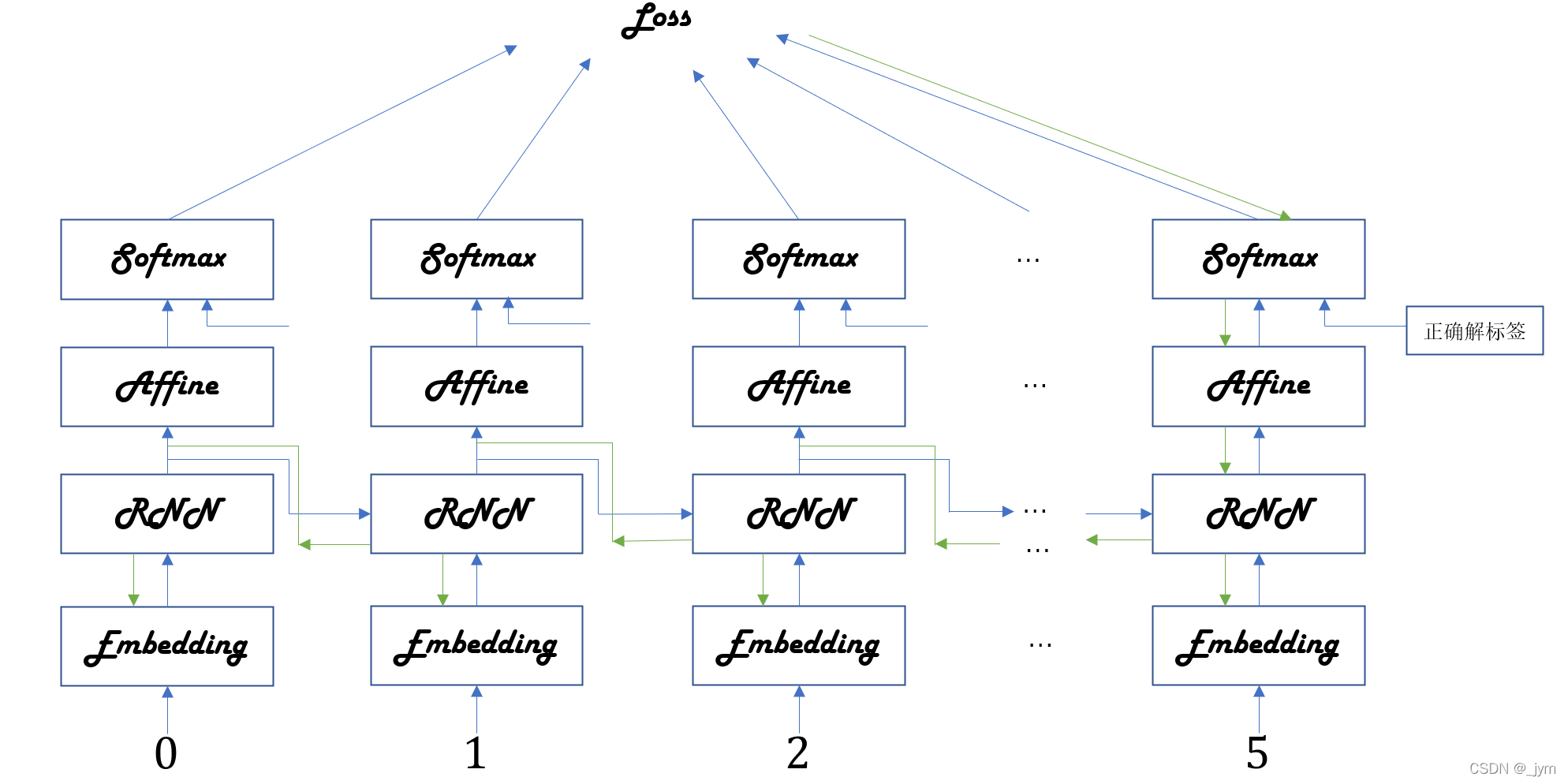
随着时间增加,RNN会产生梯度变小(梯度消失)或梯度变大(梯度爆炸)。
RNN 层在时间方向上的梯度传播,如下图。
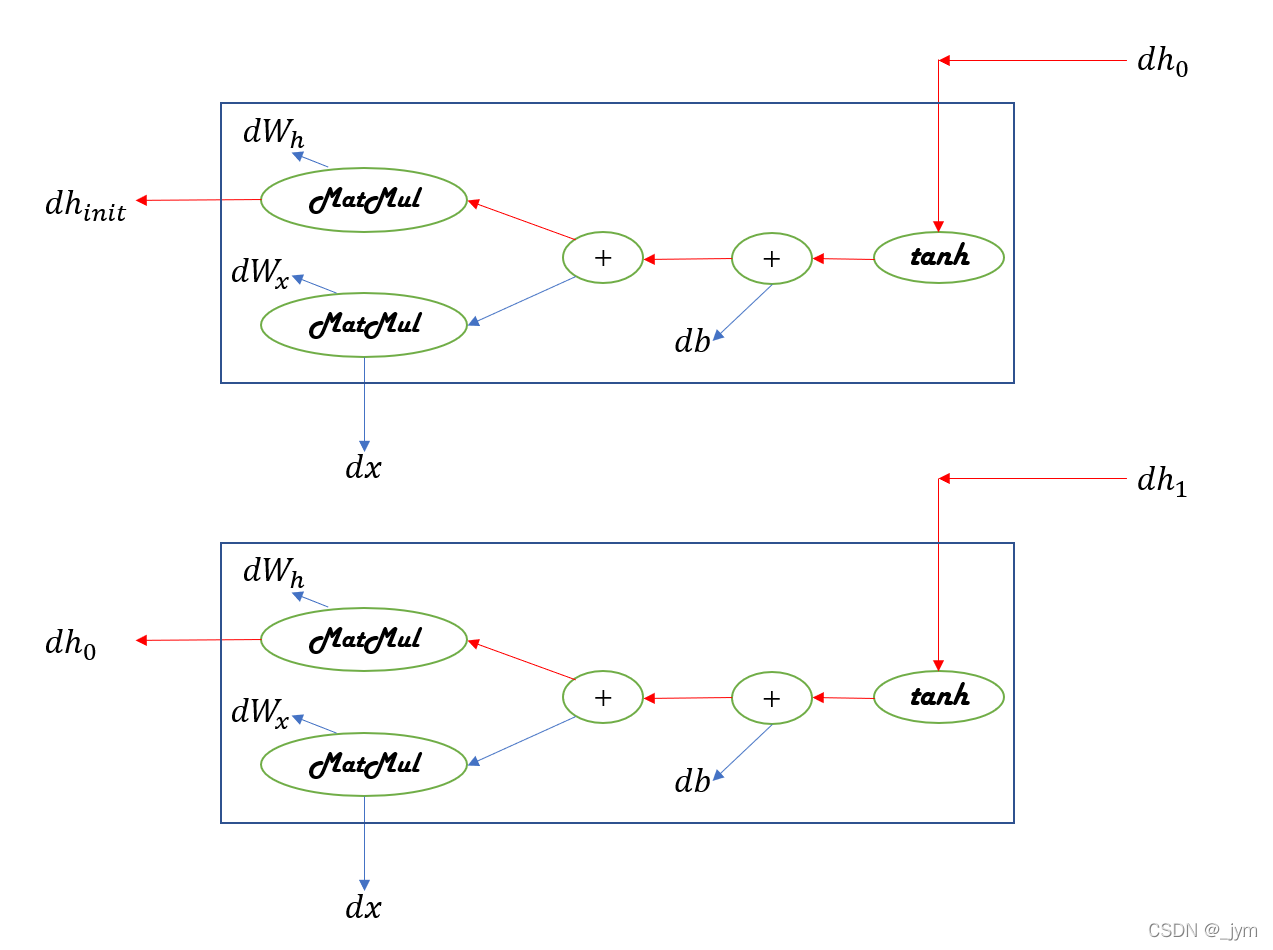
反向传播的梯度流经tanh、+、MatMul(矩阵乘积)运算。
+的反向传播,将上游传来的梯度原样传给下游,梯度值不变。
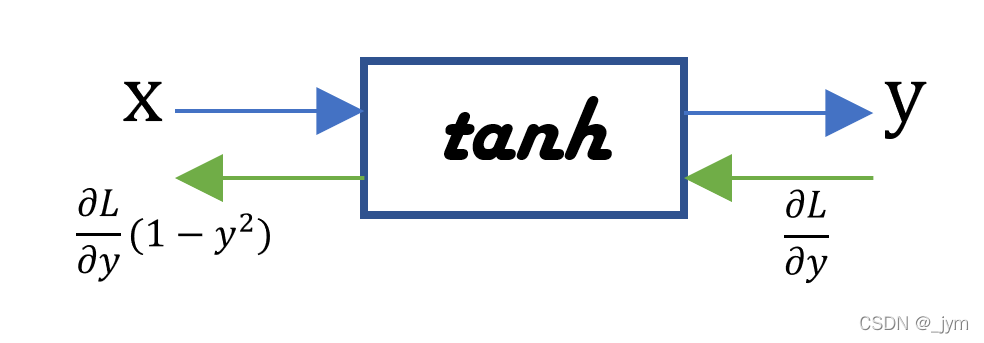
tanh的计算图如下。它将上游传来的梯度乘以tanh的导数传给下游。
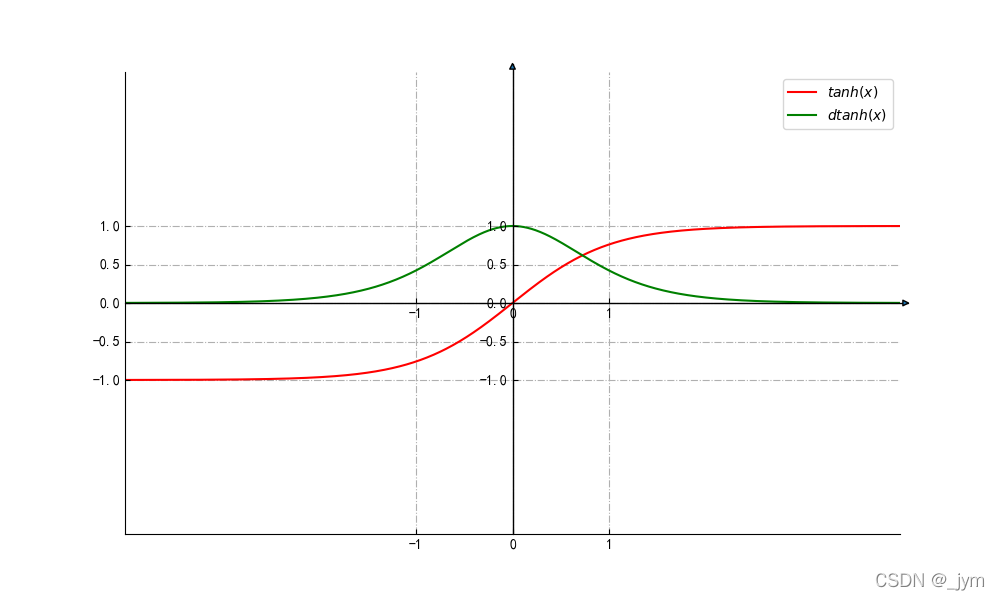
y=tanh(x)的值及其导数的值如下图。导数值小于1,x越远离0,值越小。反向传播梯度经过tanh节点要乘上tanh的导数,这就导致梯度越来越小。
如果RNN层的激活函数使用ReLU,可以抑制梯度消失,当ReLU输入为x时,输出是max(0,x)。x大于0时,反向传播将上游的梯度原样传递到下游,梯度不会退化。
对于MatMul(矩阵乘积)节点。仅关注RNN层MatMul节点时的梯度反向传播如下图。每一次矩阵乘积计算都使用相同的权重Wh。
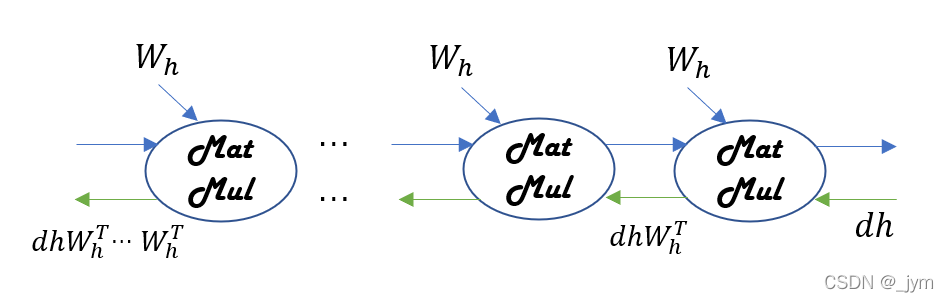
N = 2 # mini-batch的大小
H = 3 # 隐藏状态向量的维数
T = 20 # 时序数据的长度
dh = np.ones((N, H))#初始化为所有元素均为 1 的矩阵,dh是梯度
np.random.seed(3)
Wh = np.random.randn(H, H)#梯度的大小随时间步长呈指数级增加,发生梯度爆炸
#Wh = np.random.randn(H, H) * 0.5
#梯度的大小随时间步长呈指数级减小,发生梯度消失,权重梯度不能被更新,模型无法学习长期的依赖关系
norm_list = []
for t in range(T):
dh = np.dot(dh, Wh.T)#根据反向传播的 MatMul 节点的数量更新 dh 相应次数
norm = np.sqrt(np.sum(dh**2)) / N#mini-batch(N)中的平均L2 范数,L2 范数对所有元素的平方和求平方根.
norm_list.append(norm)#将各步的 dh 的大小(范数)添加到 norm_list 中
print(norm_list)
# 绘制图形
plt.plot(np.arange(len(norm_list)), norm_list)
plt.xticks([0, 4, 9, 14, 19], [1, 5, 10, 15, 20])
plt.xlabel('time step')
plt.ylabel('norm')
plt.show()
如果Wh是标量,由于Wh被反复乘了T次,当Wh大于1时,梯度呈指数级增加;当 Wh 小于1时,梯度呈指数级减小。
如果wh是矩阵,矩阵的奇异值表示数据的离散程度,根据奇异值(多个奇异值中的最大值)是否大于1,可以预测梯度大小的变化。奇异值比1大是梯度爆炸的必要非充分条件。
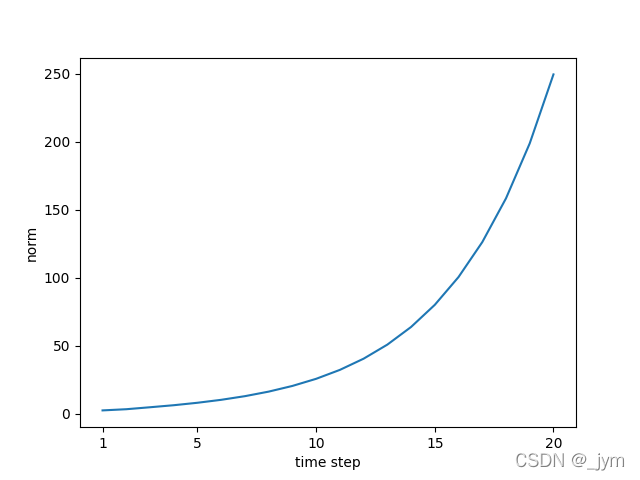
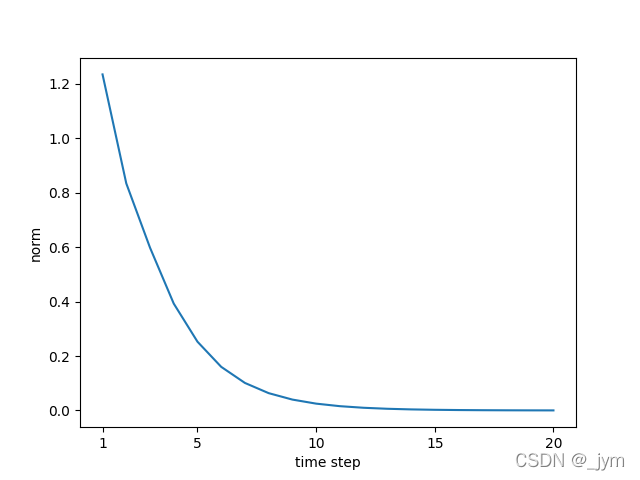
梯度裁剪(gradients clipping)是解决解决梯度爆炸的一个方法。
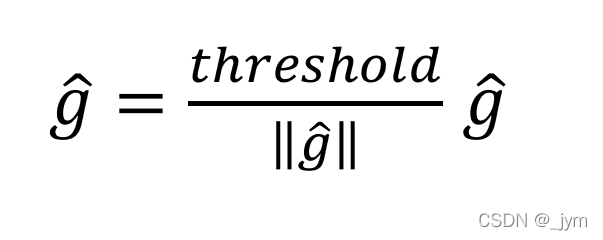
将神经网络用到的所有参数的梯度整合成一个,用g表示,将阈值设置为threshold,如果梯度g的L2范数大于等于该阈值,就按如下方式修正梯度。
dW1 = np.random.rand(3, 3) * 10
dW2 = np.random.rand(3, 3) * 10
grads = [dW1, dW2]
max_norm = 5.0#阈值
def clip_grads(grads, max_norm):
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm)#L2 范数对所有元素的平方和求平方根
rate = max_norm / (total_norm + 1e-6)
if rate < 1:#如果梯度的L2范数total_norm大于等于阈值max_norm,rate是小于1的,此时就需要修正梯度
for grad in grads:
grad *= rate
print('before:', dW1.flatten())
clip_grads(grads, max_norm)
print('after:', dW1.flatten())
before: [7.14418135 3.58857143 7.82910303 8.04057218 8.8617387 1.89963886
3.0606848 8.14163088 5.25490409]
after: [1.43122195 0.71891263 1.56843501 1.61079946 1.77530697 0.38056213
0.61315903 1.63104494 1.05273561]
为了解决梯度消失,需要从根本上改变 RNN 层的结构。
LSTM 和GRU中增加了一种门结构,可以学习到时序数据的长期依赖关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号