nlp RNN
2022-04-05 14:58 jym蒟蒻 阅读(218) 评论(0) 收藏 举报RNN(Recurrent Neural Network)循环神经网络。
类比血液在体内循环,从过去一直被更新到现在。
RNN具有环路。这个环路可以使数据不断循环。通过数据的循环,RNN一边记住过去的数据,一边更新到最新的数据。
RNN层的循环结构和它的展开如下图所示。下面的多个RNN层都是同一个层;输出分叉了,也就是说同一个输出被复制了,其中的一个输出将成为自身的输入。
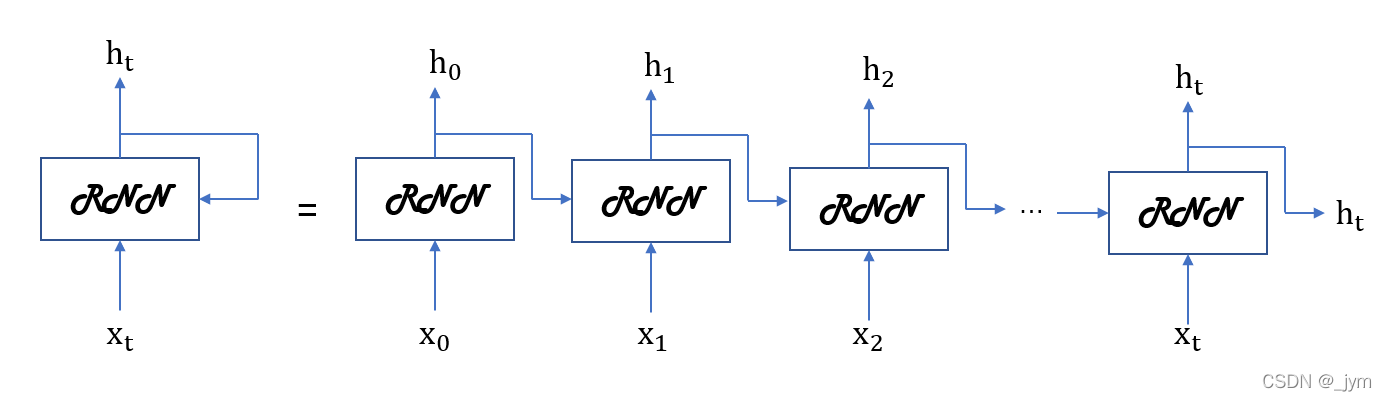
xt是t时刻的输入数据,输入t时刻的RNN层。各个时刻的RNN层接收t时刻的输入数据和前一个RNN层的输出数据。
ht:hidden state,隐藏状态。
ht可由下式表示。

Wx是将输入x转化为输出h的权重;Wh是将前一个RNN层的输出转化为当前时刻的输出的权重 ;b是偏置 。
ht-1和xt都是行向量。
式子右边先进行矩阵乘积运算,然后用双曲正切函数变换他们的和,得到时刻t的输出ht,这个ht向上传到另一个层,而且还向右传到自己的RNN层。
RNN的h存储的是状态,时间每前进一步,就以上式的形式被更新。
将RNN层展开后,就可以视为在水平方向上延伸的神经网络。
RNN可以使用误差反向传播法:Backpropagation Through Time(基于时间的反向传播),简称BPTT。
BPTT缺陷:基于BPTT求梯度,要在内存中保存各个时刻RNN层的中间数据,随着时序数据变长,计算机的内存使用量(和计算量)会增加,而且随着层变多,梯度逐渐变小,梯度将无法向前一层传递。
解决办法:处理长时序数据时,将时间轴方向上过长的网络在合适的位置进行截断,创建多个小型网络,然后对截出来的小型网络执行误差反向传播法。也就是Truncated BPTT(截断的 BPTT)方法。
Truncated BPTT:只是网络的反向传播的连接被截断,正向传播的连接依然被维持。
将反向传播的连接中的某一段RNN层称为块。以各个块为单位完成误差反向传播法。
进行RNN的学习时,必须考虑到正向传播之间是有关联的,必须按顺序输入数据。
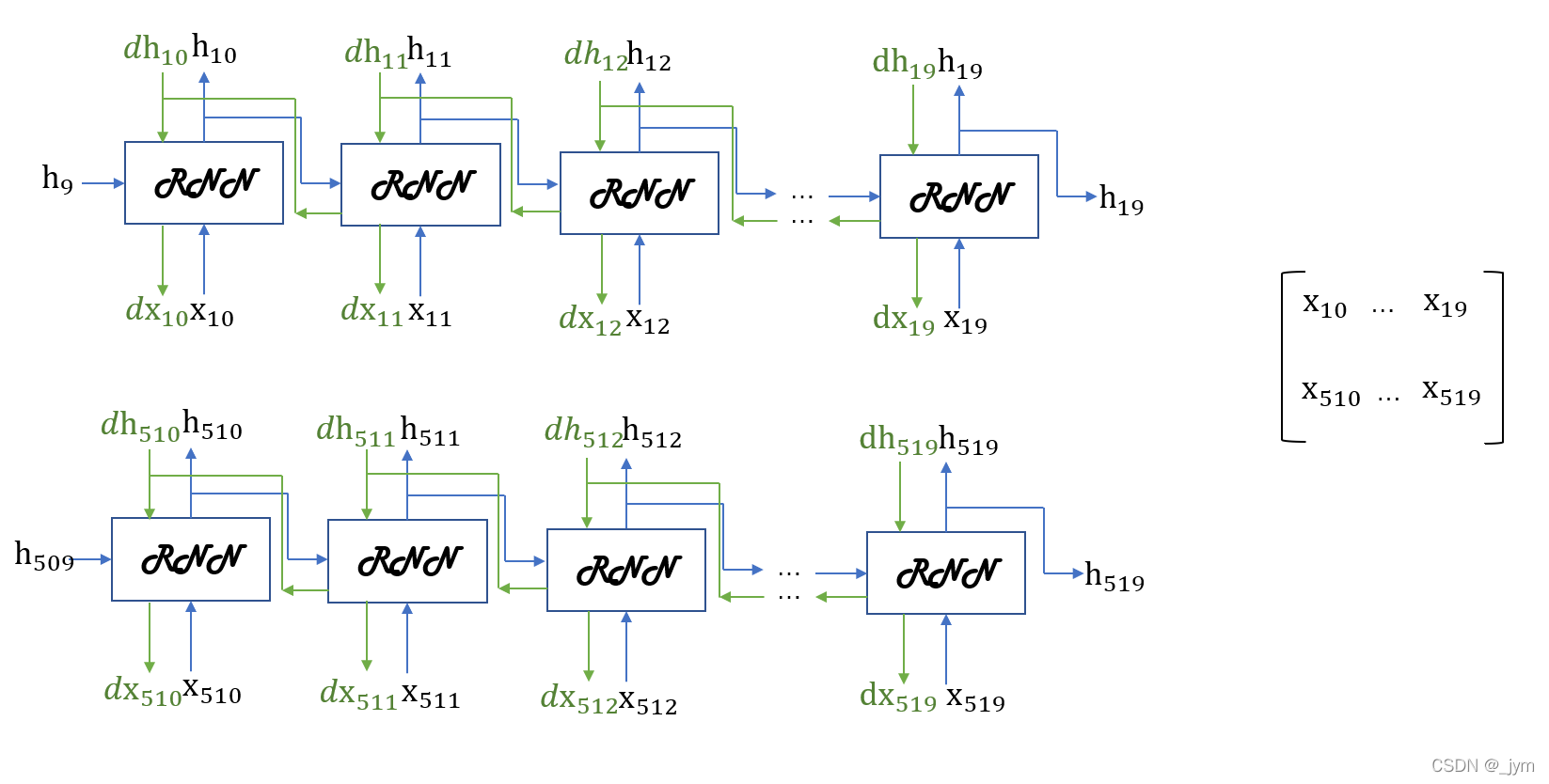
处理长度为1000的时序数据,使学习以10个RNN层为单位进行。
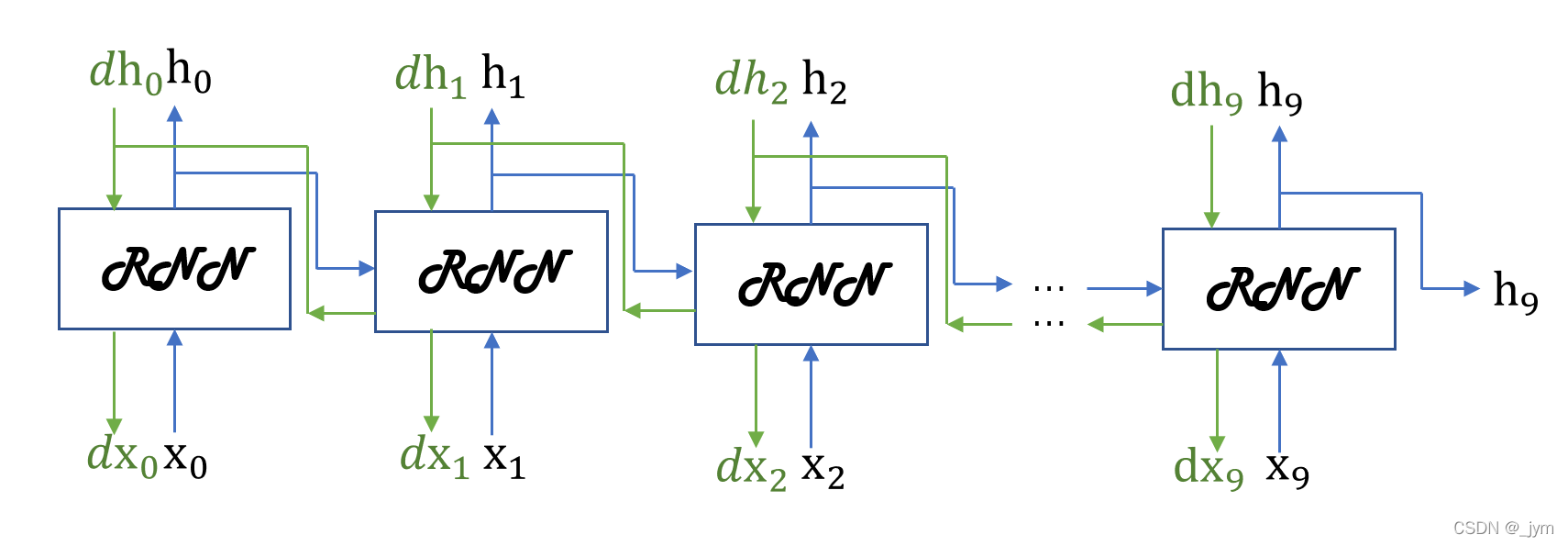
正向传播的计算需要前一个块最后的隐藏状态。如下图需h9。
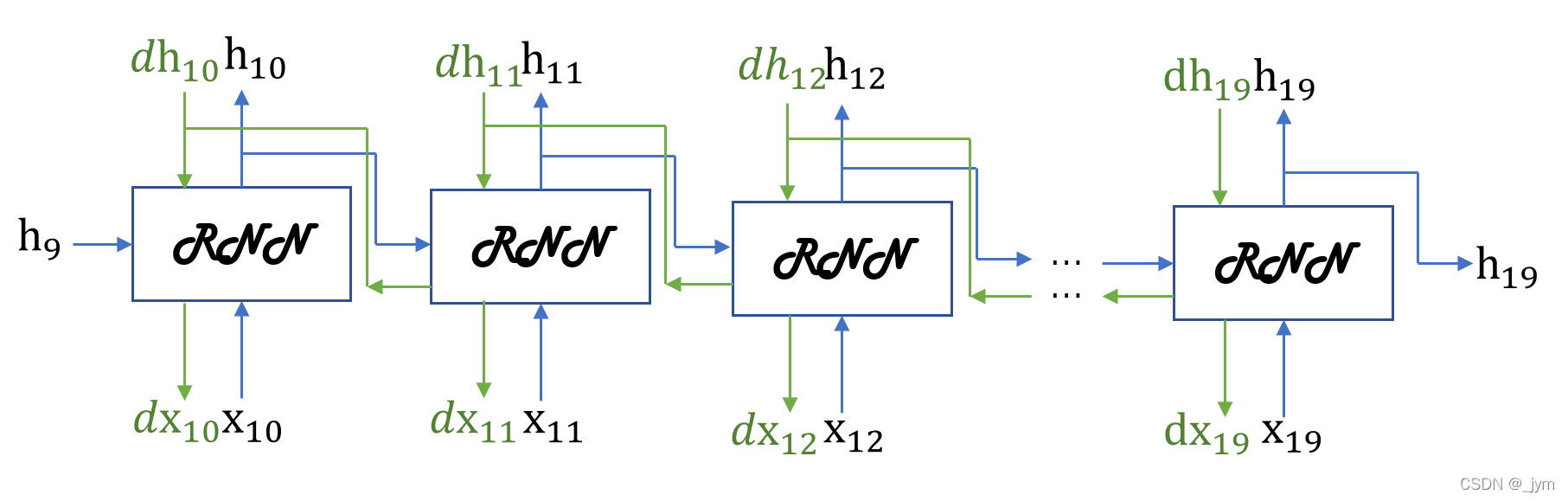
上面的是一次处理一个数据,一次处理x个数据就是所谓的批处理。
如果批大小为2:
因为进行RNN的学习时,正向传播之间是有关联的,必须按顺序输入数据。
在输入数据的开始位置,需要在各个批次中进行偏移。所谓的偏移,就是在进行mini-batch学习时,平移各批次输入数据的开始位置,按顺序输入。
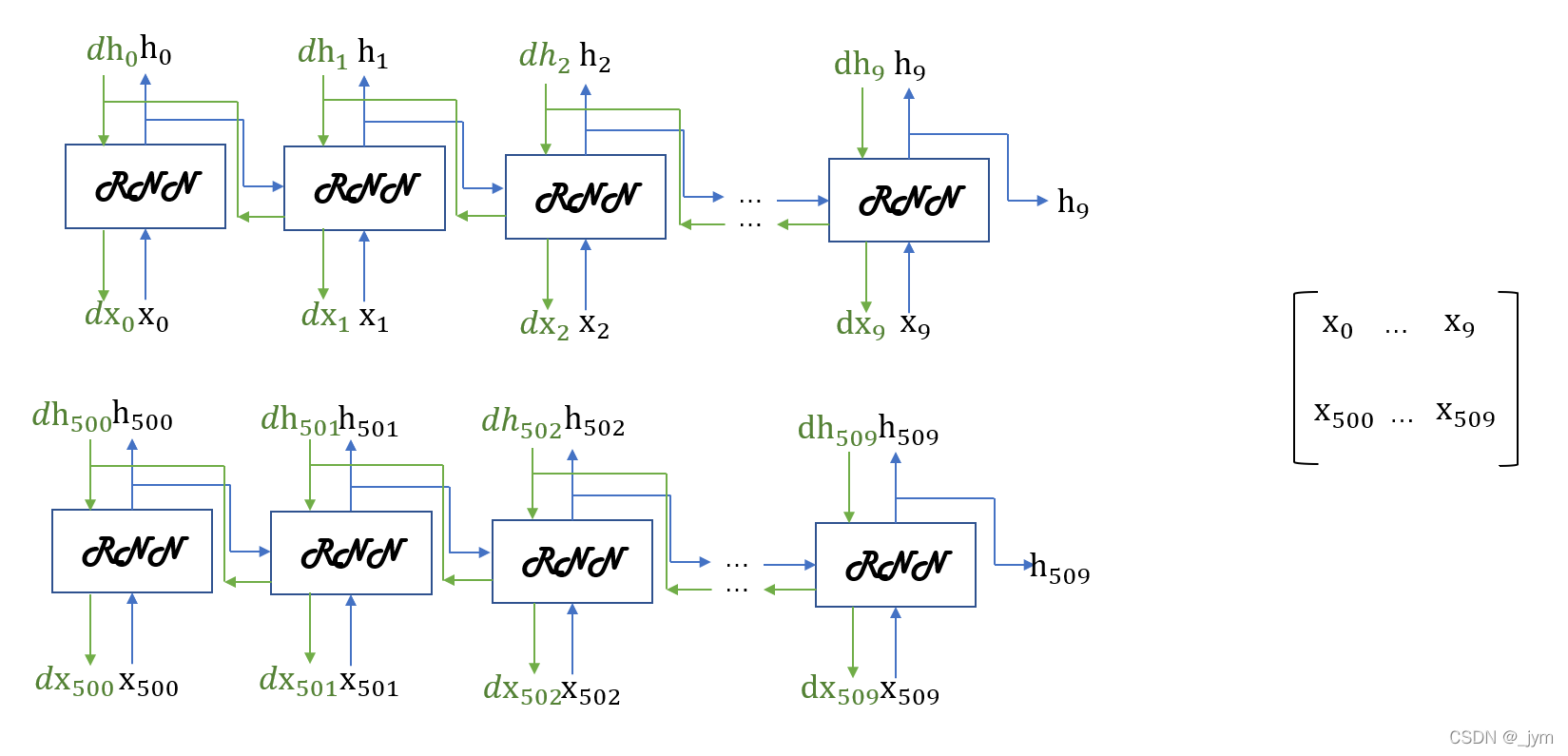
第1个样本数据从头开始按顺序输入,第2个数据从第500个数据开始按顺序输入。开始位置平移了500。
批次的第1个元素是x0…x9,第2个元素是x500…x509
实现Truncated BPTT RNN,只需创建一个在水平方向上长度固定的网络序列。
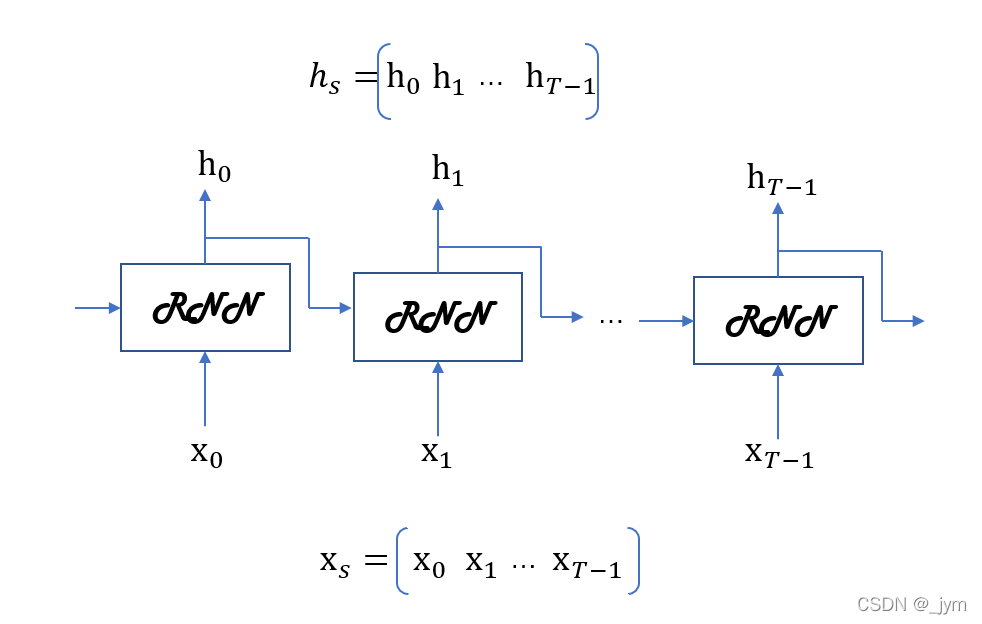
目标神经网络接收长度为T的时序数据。
输出各个时刻的T个隐藏状态。
Time RNN层:将展开循环后的层视为一个层。如下所示。
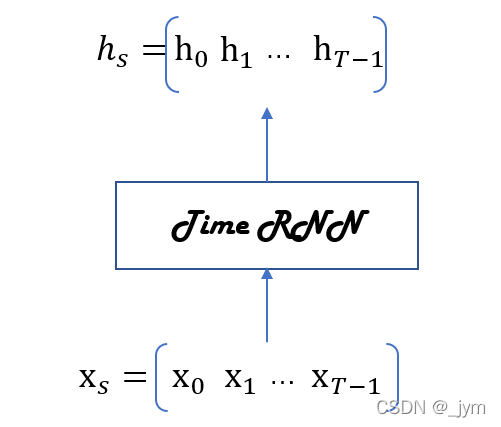
进行Time RNN层中的单步处理的层称为RNN 层;一次处理T步的层称为Time RNN层。
整体处理时序数据的层以Time作为开头命名。
实现RNN的话,首先,实现单步处理的RNN类;然后,利用这个RNN类,实现进行T步处理的TimeRNN类。
RNN 正向传播的数学式:
Wx是将输入x转化为输出h的权重;Wh是将前一个RNN层的输出转化为当前时刻的输出的权重 ;b是偏置 。
ht-1和xt都是行向量。
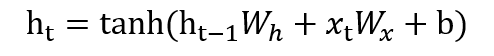
假设批大小为N,输入向量xt维数是D,隐藏状态向量维数是H。
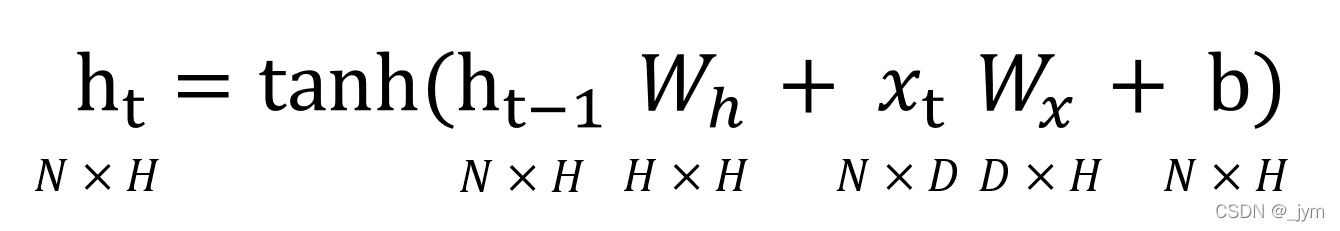
class RNN:
def __init__(self, Wx, Wh, b):#接收两个权重参数和一个偏置参数
self.params = [Wx, Wh, b]#参数设置为列表类型的成员变量params
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]#以各个参数对应的形状初始化梯度,保存在grads中
self.cache = None #cache是反向传播时要用到的中间数据
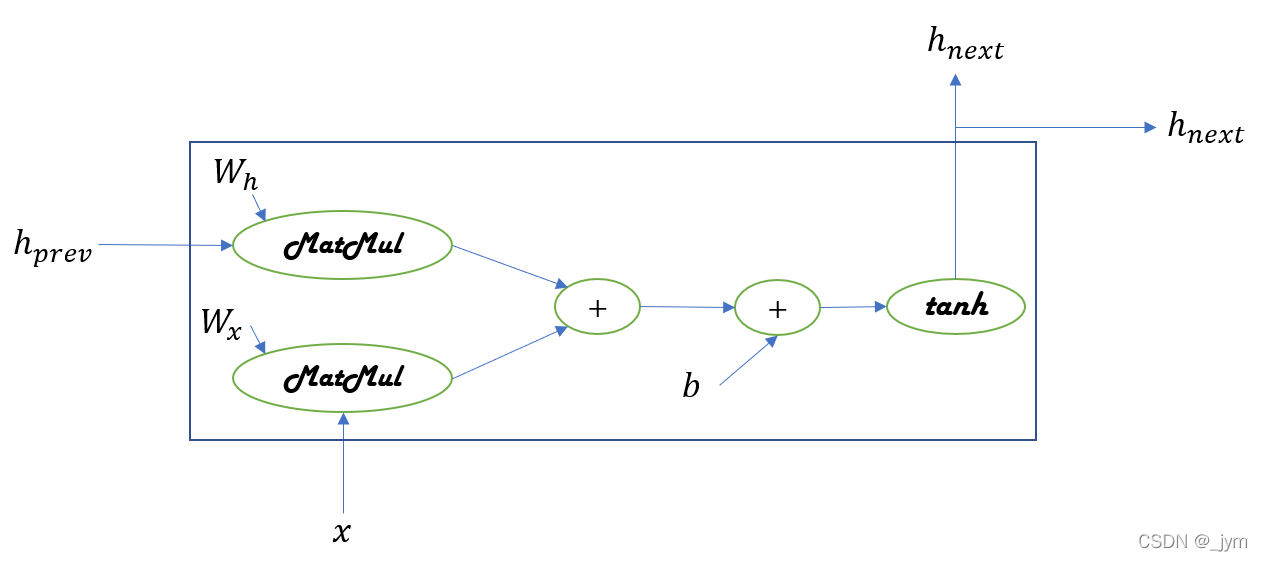
def forward(self, x, h_prev):#正向传播接收两个参数,从下方输入的x,从左边输入的 h_prev
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b#按照公式来
h_next = np.tanh(t)#当前时刻的RNN层的输出是h_next
self.cache = (x, h_prev, h_next)
return h_next
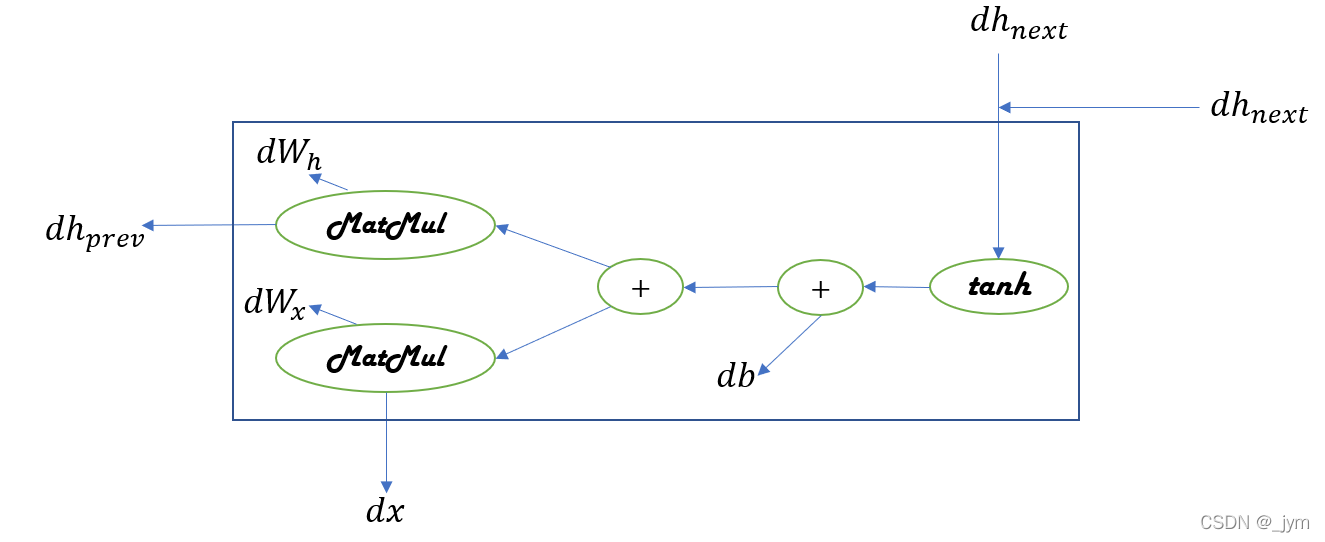
def backward(self, dh_next):#RNN 的反向传播
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache#取中间数据
dt = dh_next * (1 - h_next ** 2)#tanh反向传播
db = np.sum(dt, axis=0)#加法层反向传播,将上游传来的导数原封不动传给下游
dWh = np.dot(h_prev.T, dt)#乘法层反向传播,将上游传过来的导数dt乘正向传播的翻转值,然后传给下游
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx#保存梯度
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
Time RNN层由T个RNN层构成。
之前在Truncated BPTT里面提到了块,将反向传播的连接中的某一段RNN层称为块。以各个块为单位完成误差反向传播法。
Time RNN 层将隐藏状态h保存在成员变量中,以在块之间继承隐藏状态。如下图所示。
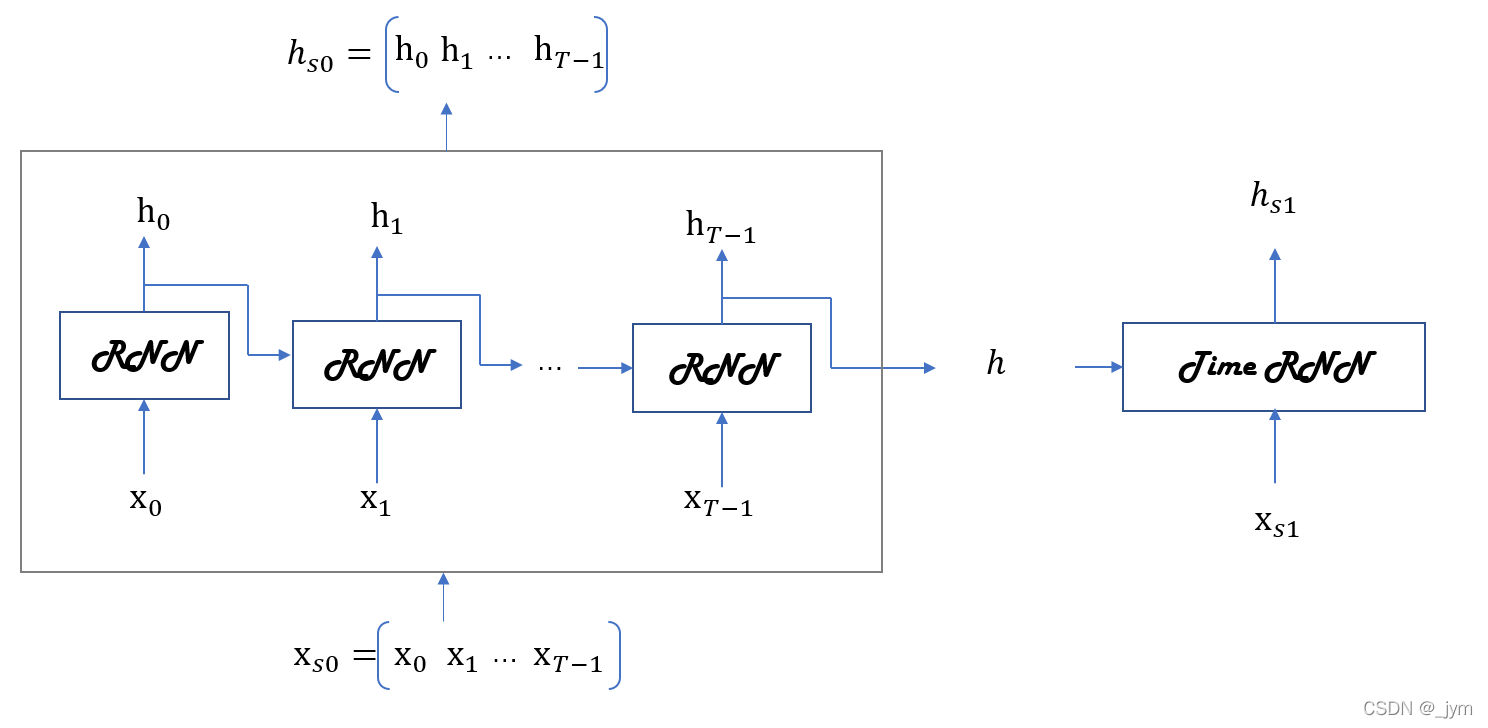
下面的stateful参数为True 时,Time RNN层维持隐藏状态。下一次调用Time RNN层的forward() 方法时,成员变量h将被继续使用。
成员变量h中存放最后一个RNN层的隐藏状态。
stateful 为 False时,每次调用Time RNN层的forward()时,第一个RNN层的隐藏状态都会被初始化为零矩阵。stateful为False的情况下,成员变量h将被重置为零向量。
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):#参数有权重、偏置和stateful,用stateful这个参数来控制是否继承隐藏状态。
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None#layers 在列表中保存多个 RNN 层
self.h, self.dh = None, None#h保存调用forward()方法时的最后一个 RNN 层的隐藏状态;dh保存调用backward()时,传给前一个块的隐藏状态的梯度
self.stateful = stateful
def forward(self, xs):#参数是获取的输入xs,xs包含T个时序数据
Wx, Wh, b = self.params
N, T, D = xs.shape#批大小是 N,输入向量的维数是 D,xs形状为(N,T,D)
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f')#为输出准备一个容器
if not self.stateful or self.h is None:#首次调用时,self.h 为 None;或者stateful=False,不继承隐藏状态
self.h = np.zeros((N, H), dtype='f')#RNN 层的隐藏状态 h 由所有元素均为 0 的矩阵初始化
for t in range(T):#在T次 for 循环中,生成 RNN 层
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)#调用正向传播,for运行完,成员变量 h 中将存放最后一个 RNN 层的隐藏状态
hs[:, t, :] = self.h#计算各个时刻RNN层的隐藏状态,并存放在 hs 的对应时刻(索引)中
self.layers.append(layer)#将生成的RNN层添加到成员变量 layers 中
return hs
def set_state(self, h):#设定 Time RNN 层的隐藏状态
self.h = h
def reset_state(self):#重设隐藏状态
self.h = None
对于Time RNN反向传播,上游(输出侧的层)传来的梯度为dhs,流向下游的梯度为dxs,将流向上一时刻的隐藏状态的梯度存放在成员变量dh中。
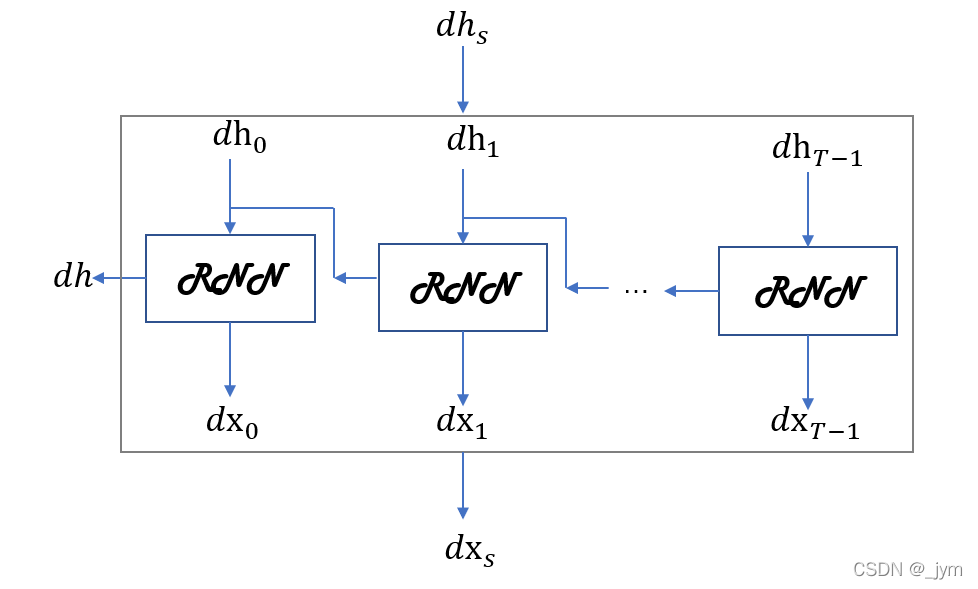
对于里面的RNN层。在正向传播存在分叉的情况下,在反向传播时各梯度将被求和。在反向传播时,流向RNN层的是求和后的梯度。
dx, dh = layer.backward(dhs[:, t, :] + dh)#dx是各个时刻的梯度,这里面流向 RNN 层的是求和后的梯度
Time RNN层中有多个RNN层。这些RNN层使用相同的权重。Time RNN 层最终权重梯度是各个RNN层的权重梯度之和。
for i, grad in enumerate(layer.grads):
grads[i] += grad#权重参数,要求各个RNN层的权重梯度的和
反向传播代码:
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')#里面存的是传给下游的梯度
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)#dx是各个时刻的梯度,这里面流向 RNN 层的是求和后的梯度
dxs[:, t, :] = dx#dx存放在 dxs 的对应索引处
for i, grad in enumerate(layer.grads):
grads[i] += grad#权重参数,要求各个RNN层的权重梯度的和
for i, grad in enumerate(grads):
self.grads[i][...] = grad#用最终结果覆盖成员变量self.grads
self.dh = dh
return dxs
现在实现了整体处理时序数据的Time RNN层。之前实现了RNN层。
接下来就要使用 RNN 实现语言模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号