nlp CBOW模型实现
2022-04-05 14:47 jym蒟蒻 阅读(317) 评论(0) 收藏 举报实现CBOW模型类
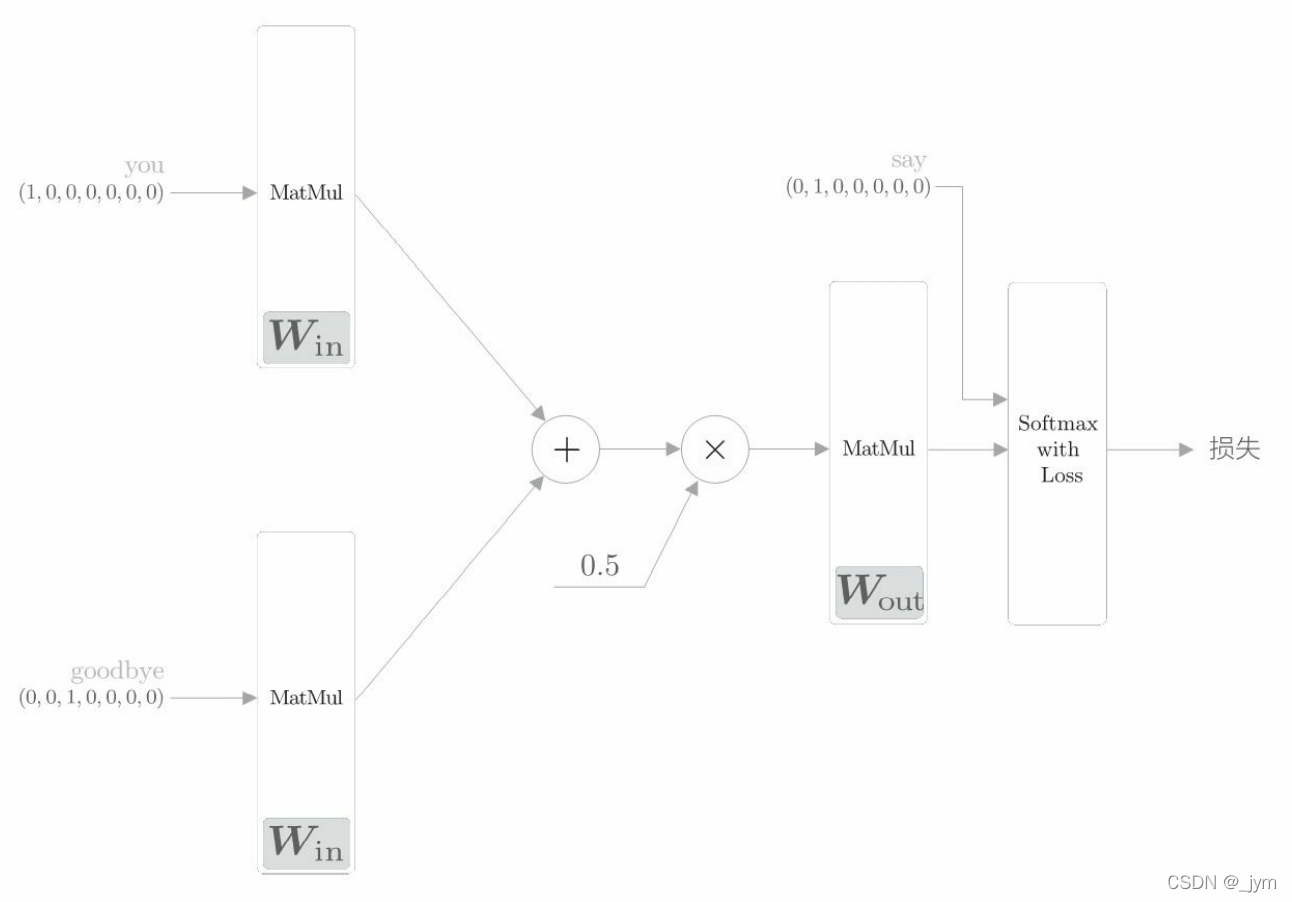
初始化:初始化方法的参数包括词汇个数 vocab_size 和中间层的神经元个数 hidden_size。首先生成两个权重(W_in 和 W_out),并用一些小的随机值初始化这两个权重。设置astype(‘f’),初始化将使用 32 位的浮点数。
生成层:生成两个输入侧的 MatMul 层、一个输出侧的 MatMul 层,以及一个 Softmax with Loss 层。
保存权重和梯度:将该神经网络中使用的权重参数和梯度分别保存在列表类型的成员变量 params 和 grads 中。
正向传播 forward() 函数:该函数接收参数 contexts 和 target,并返回损失(loss)。这两个参数结构如下。

contexts 是一个三维 NumPy 数组,第 0 维的元素个数是 mini-batch 的数量,第 1 维的元素个数是上下文的窗口大小,第 2 维表示 one-hot 向量。下面这个代码取出来的是什么?
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
jym做了一个测试:
import sys
sys.path.append('..')
from common.util import preprocess #, create_co_matrix, most_similar
from common.util import create_contexts_target, convert_one_hot
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
contexts, target = create_contexts_target(corpus, window_size=1)
#print(contexts)
#print(target)
vocab_size = len(word_to_id)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)
print(contexts[:, 0])
输出:然后从输出就知道了,取的是不同target的左边的单词。
[[1 0 0 0 0 0 0]
[0 1 0 0 0 0 0]
[0 0 1 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 0 0 1 0 0]
[0 1 0 0 0 0 0]]
反向传播 backward():神经网络的反向传播在与正向传播相反的方向上传播梯度。这个反向传播从 1 出发,并将其传向 Softmax with Loss 层。然后,将 Softmax with Loss 层的反向传播的输出 ds 传到输出侧的 MatMul 层。“×”的反向传播将正向传播时的输入值“交换”后乘以梯度。“+”的反向传播将梯度“原样”传播。
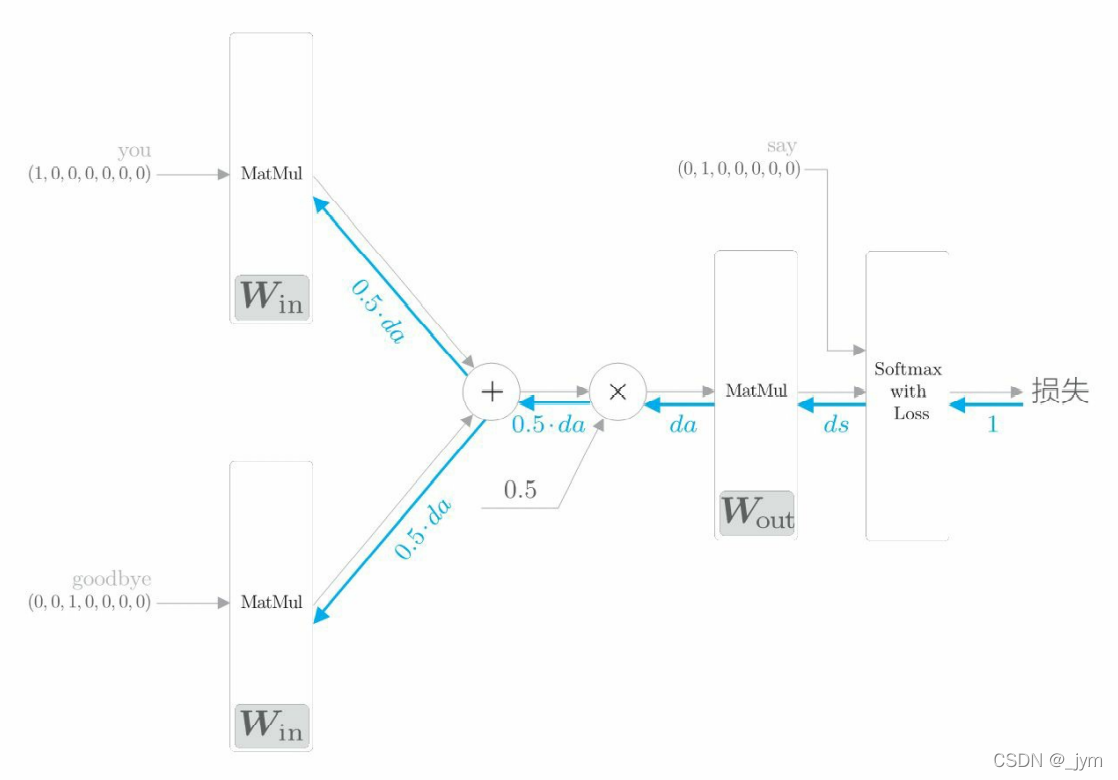
这个backward函数里面调用的是之前写好的层的反向传播函数,比如loss_layer.backward(dout),因此backward函数用完之后,各个权重参数的梯度就保存在了成员变量 grads 中(这是之前写的层里面的反向传播函数来实现的)。先调用 forward() 函数,再调用 backward() 函数,grads 列表中的梯度被更新。
import sys
sys.path.append('..')
import numpy as np
from common.layers import MatMul, SoftmaxWithLoss
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 初始化权重
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# 生成层
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
# 将所有的权重和梯度整理到列表中
layers = [self.in_layer0, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 将单词的分布式表示设置为成员变量
self.word_vecs = W_in
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
h = (h0 + h1) * 0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer0.backward(da)
return None
CBOW模型的学习、Trainer类的实现
CBOW 模型的学习的实现:给神经网络准备好学习数据。然后求梯度,并逐步更新权重参数。
Trainer类:学习的类。
初始化:类的初始化程序接收神经网络(模型)和优化器(SGD、Momentum、AdaGrad、Adam)
学习:调用 fit() 方法开始学习。参数:x,输入数据;t,监督标签;max_epoch,进行学习的 epoch 数;batch_size,mini-batch 的大小;eval_interval,输出结果(平均损失等)的间隔。 例如设置 eval_interval=20,则每 20 次迭代计算 1 次平均损失, 并将结果输出到界面上;max_grad,梯度的最大范数。 当梯度的范数超过这个值时,缩小梯度。
def fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20):
plot方法:画出 fit() 方法记录的损失(按照 eval_interval 评价的平均损失)。
class Trainer:
def __init__(self, model, optimizer):
self.model = model
self.optimizer = optimizer
self.loss_list = []
self.eval_interval = None
self.current_epoch = 0
def fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20):
data_size = len(x)
max_iters = data_size // batch_size
self.eval_interval = eval_interval
model, optimizer = self.model, self.optimizer
total_loss = 0
loss_count = 0
start_time = time.time()
for epoch in range(max_epoch):
# 打乱
idx = numpy.random.permutation(numpy.arange(data_size))
x = x[idx]
t = t[idx]
for iters in range(max_iters):
batch_x = x[iters*batch_size:(iters+1)*batch_size]
batch_t = t[iters*batch_size:(iters+1)*batch_size]
# 计算梯度,更新参数
loss = model.forward(batch_x, batch_t)
model.backward()
params, grads = remove_duplicate(model.params, model.grads) # 将共享的权重整合为1个
if max_grad is not None:
clip_grads(grads, max_grad)
optimizer.update(params, grads)
total_loss += loss
loss_count += 1
# 评价
if (eval_interval is not None) and (iters % eval_interval) == 0:
avg_loss = total_loss / loss_count
elapsed_time = time.time() - start_time
print('| epoch %d | iter %d / %d | time %d[s] | loss %.2f'
% (self.current_epoch + 1, iters + 1, max_iters, elapsed_time, avg_loss))
self.loss_list.append(float(avg_loss))
total_loss, loss_count = 0, 0
self.current_epoch += 1
def plot(self, ylim=None):
x = numpy.arange(len(self.loss_list))
if ylim is not None:
plt.ylim(*ylim)
plt.plot(x, self.loss_list, label='train')
plt.xlabel('iterations (x' + str(self.eval_interval) + ')')
plt.ylabel('loss')
plt