
nlp CBOW模型
2022-04-05 14:44 jym蒟蒻 阅读(546) 评论(0) 收藏 举报
采用推理的方法认知单词、CBOW模型
基于计数的方法,根据一个单词周围的单词的出现频数来表示该单词。需要生成所有单词的共现矩阵,再对这个矩阵进行 SVD,以获得密集向量,如果语料库处理的单词数量非常大,将需要大量的计算资源和时间。基于计数的方法使用整个语料库的统计数据(共现矩阵、PPMI),通过一次处理(SVD)获得单词的分布式表示。
基于推理的方法,使用神经网络,在 mini-batch 数据上进行学习,神经网络一次只需要看一部分学习数据(mini-batch),并反复更新权重。神经网络的学习可以使用多台机器、多 个 GPU 并行执行,从而加速整个学习过程。
如果需要向词汇表添加新词并更新单词的分布式表示,基于计数的方法需要从头开始计算,重新完成生成共现矩阵、进行 SVD 等一系列操作。基于推理的方法(word2vec)允许参数的增量学习。可以将之前学习到的权重作为下一次学习的初始值,在不损失之前学习到的经验的情况下,高效地更新单词的分布式表示。
推理:当给出周围的单词(上下文)时,预测“?”处会出现什么单词。

基于推理的方法:输入上下文,模型输出各个单词的出现概率。这个模型接收上下文信息作为输入,并输出(可能出现的)各个单词的出现概率。作为模型学习的产物,也能得到单词的分布式表示。如下图所示。
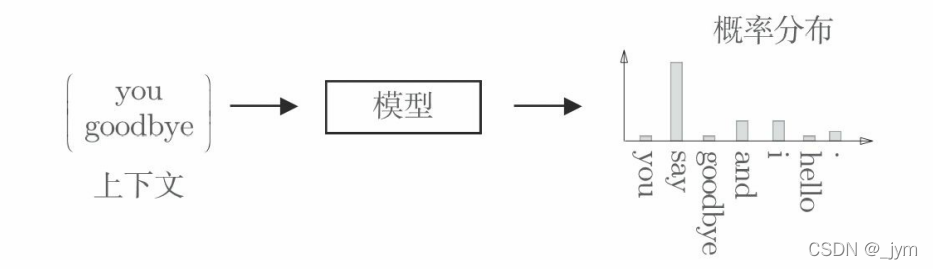
分布式假设:基于推理的方法和基于计数的方法一样,也基于分布式假设。分布式假设,“单词含义由其周围的单词构成”。
one-hot 表示:神经网络无法直接处理 you 或 say 这样的单词,要用神经网络处理单词,需要先将单词转化为固定长度的向量。在 one-hot 表示中,只有一个元素是 1,其他元素都 是 0;将单词转化为 one-hot 表示,就需要准备元素个数与词汇个数相等的向量,并将单词 ID 对应的元素设为 1,其他元素设为 0。
单词的表示:单词可以表示为文本、单词 ID 和 one-hot 表示。如果语料库中,一共有 7 个单词(“you”“say”“goodbye”“and”“i”“hello”“.”),单词表示如下图所示。

将单词转化为固定长度的向量(one-hot 表示),神经网络的输入层的神经元个数就可以固定下来,比如,输入层由 7 个神经元表示,分别对应于 7 个单词。
全连接层变换:c 和 W 的矩阵乘积相当于“提取”权重的对应行向向量。
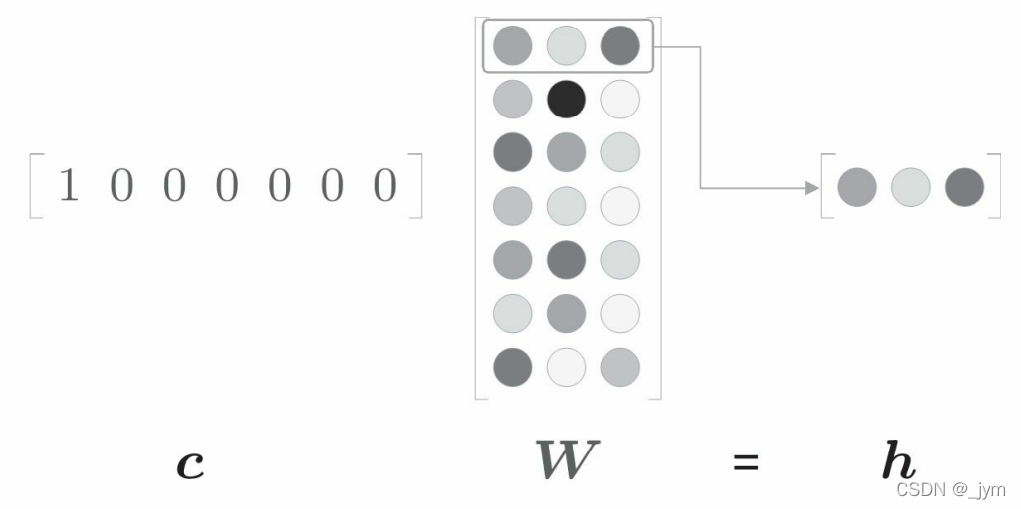
import numpy as np
c = np.array([[1, 0, 0, 0, 0, 0, 0]]) # 输入
W = np.random.randn(7, 3) # 权重
h = np.dot(c, W) # 中间节点
print(h)
# [[-0.70012195 0.25204755 -0.79774592]]
CBOW模型:它是根据上下文预测目标词的神经网络。模型的输入是上下文。这个上下文用 [‘you’, ‘goodbye’] 这 样的单词列表表示。可以转换为 one-hot 表示,以便 CBOW 模型进行处理。大致结构如下。
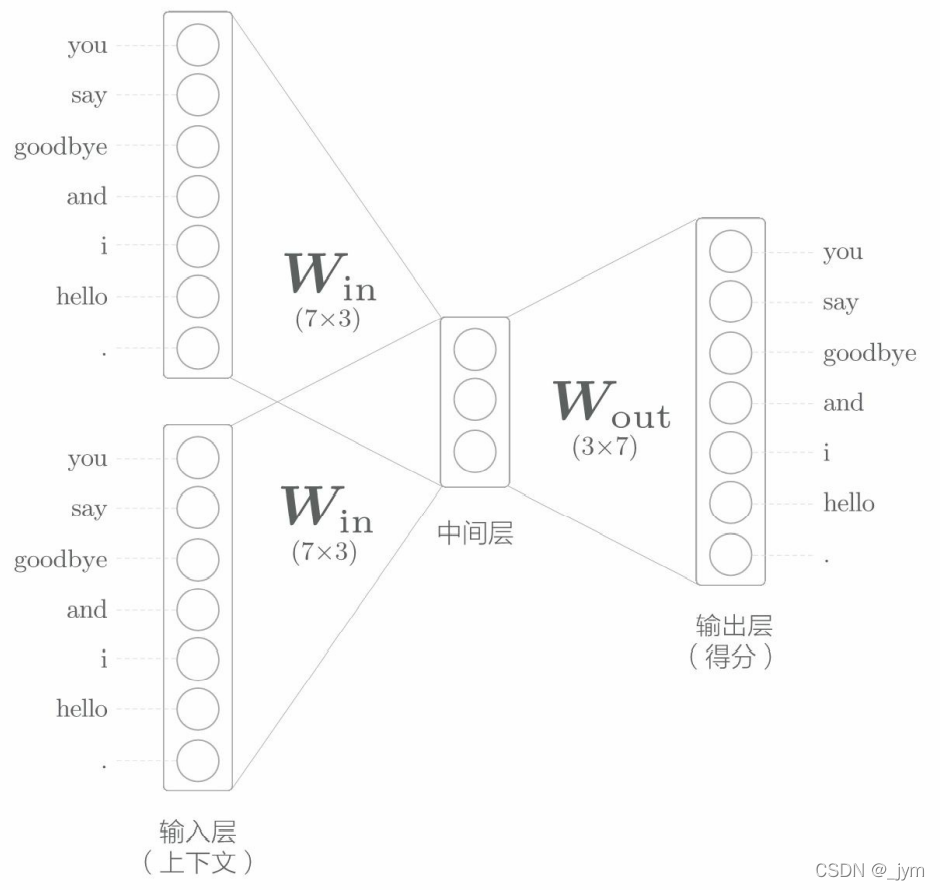
输入层:如果对上下文仅考虑两个单词,输入层有两个;如果对上下文考虑N个单词,则输入层会有N个。
中间层:中间层的神经元是各个输入层经全连接层变换后得到的值的平均,经全连接层变换后,第 1 个输入层转化为h1,第 2 个输入层转化为h2,那么中间层的神经元是(1/2)*(h1+h2)。中间层的神经元数量比输入层少,因为,中间层需要将预测单词所需的信息压缩保存,从而产生密集的向量表示。
输出层:输出层有 7 个神经元,这些神经元对应于各个单词。输出层的神经元是各个单词的得分,它的值越大,说明对应单词的出现概率就越高。对这些得分应用 Softmax 函数,就可以得到概率。
全连接层:从输入层到中间层的变换由全连接层完成,全连接层的权重是一个 7 × 3 的矩阵,权重的各行对应各个单词的分布式表示。
CBOW模型正向传播、矩阵乘积层实现
把矩阵乘积称为MatMul节点:
下面这个图表示矩阵乘积y=xW的计算图 。因为考虑了mini-batch 处理,假设x中保存了N个数据。此时x 、W、y 的形状分别是 N×D、D×H 、N×H 。
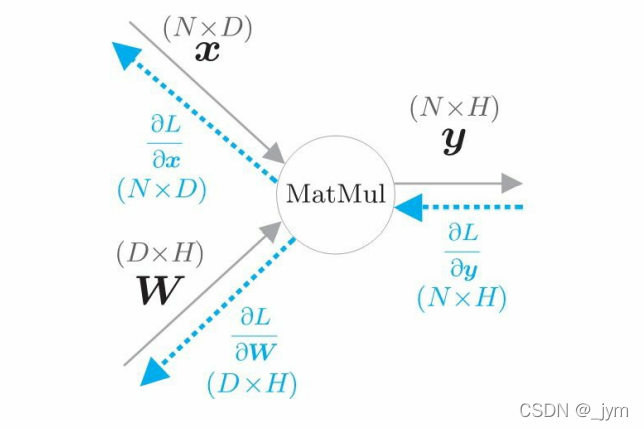
下面是推反向传播的数学式:
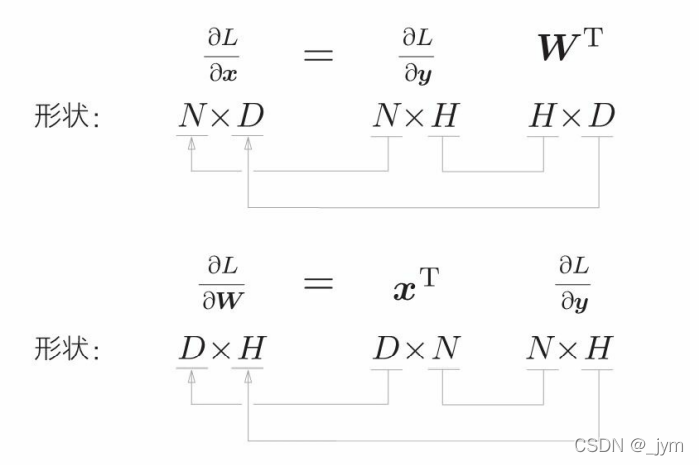
用代码表述MatMul层:params 中保存要学习的参数,梯度保存在 grads 中。
下面这句话是设置梯度的值,使用省略号可以固定 NumPy 数组的内存地址,覆盖 NumPy 数组的元素。a=b 和 a[…]=b 的区别:使用省略号时数据被覆盖,变量a指向的内存地址不变,在 a = b 的情况下,a 指向的内存地址转到和b一样了。
self.grads[0][...] = dW
class MatMul:
def __init__(self, W):
self.params = [W]#w就是权重矩阵
self.grads = [np.zeros_like(W)]#构造一个和W矩阵维度一致,但是全为0的矩阵。
self.x = None
def forward(self, x):
W, = self.params
out = np.dot(x, W)#矩阵x和矩阵w相乘
self.x = x
return out
def backward(self, dout):
W, = self.params
dx = np.dot(dout, W.T)#dout是上游传来的;W.T是把W转置了
dW = np.dot(self.x.T, dout)
self.grads[0][...] = dW
return dx
CBOW 模型一开始有两个 MatMul 层,这两个层的输出被加在一起。然后,对这个相加后得到的值乘以 0.5 求平均,可以得到中间层的神经元。最后,将另一个 MatMul 层应用于中间层的神经元,输出得分。
MatMul 层的正向传播其实也就是求矩阵乘积。
CBOW 模型网络结构:
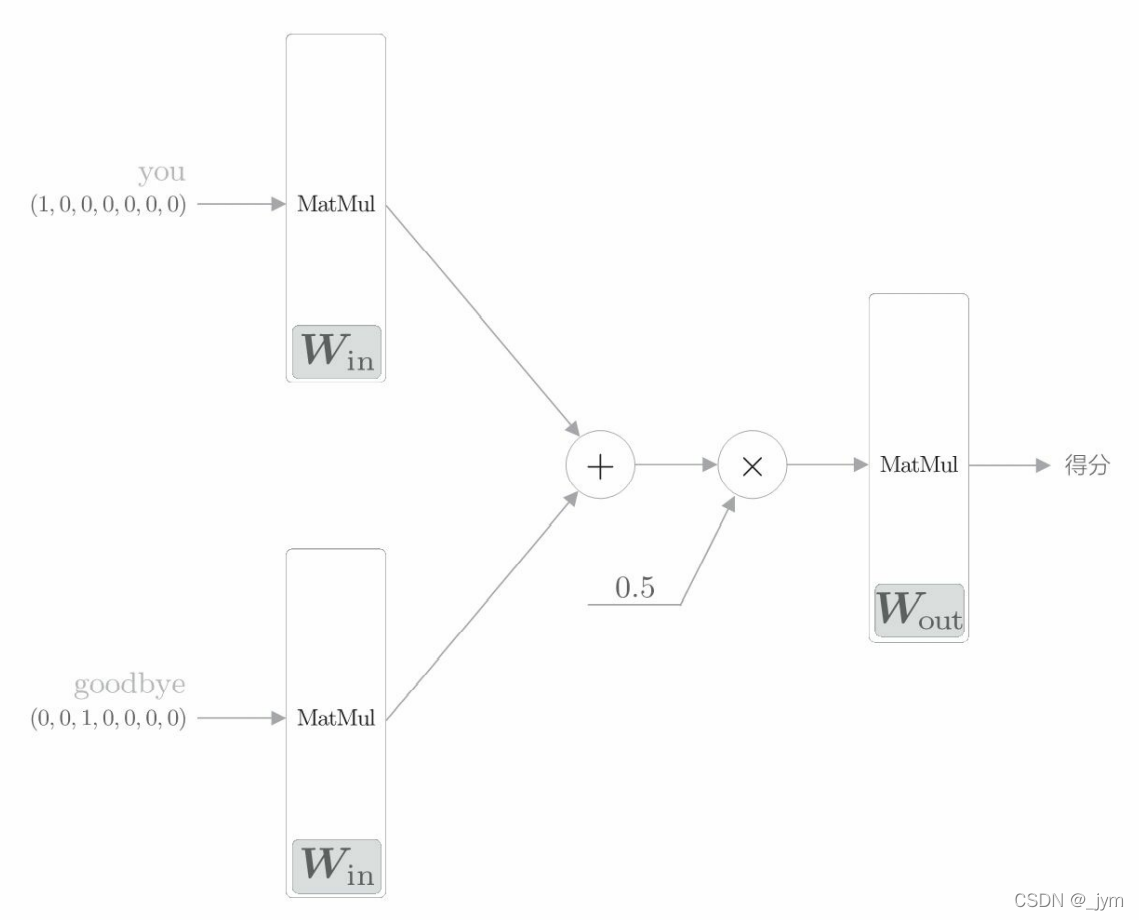
python实现 CBOW 模型的推理:这里面输入侧的 MatMul 层共享权重 W_in。
import sys
sys.path.append('..')
import numpy as np
from common.layers import MatMul
# 样本的上下文数据
c0 = np.array([[1, 0, 0, 0, 0, 0, 0]])
c1 = np.array([[0, 0, 1, 0, 0, 0, 0]])
# 初始化权重
W_in = np.random.randn(7, 3)
W_out = np.random.randn(3, 7)
# 生成层
in_layer0 = MatMul(W_in)
in_layer1 = MatMul(W_in)
out_layer = MatMul(W_out)
# 正向传播
h0 = in_layer0.forward(c0)
h1 = in_layer1.forward(c1)
h = 0.5 * (h0 + h1)
s = out_layer.forward(h)
print(s)
输出:
[[-0.78101945 -0.63278993 0.62227128 1.97029862 0.51288306 -0.48109863 0.6403517 ]]
CBOW模型的数据预处理
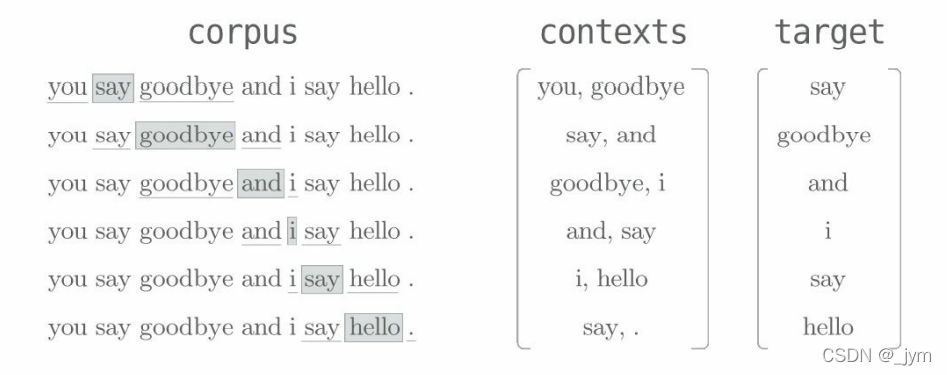
数据预处理:从语料库生成上下文和目标词。如下图所示,contexts 的各行成为神经网络的输入,target 的各行成为正确解标签(要预测出的单词)。
之前做过一个preprocess函数,将文本分割为单词,并将分割后的单词列表转化为单词ID列表。实现代码如下,其中corpus 是单词ID列表,word_to_id 是单词到单词ID的字典,id_to_word是单词ID到单词的字典。
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
然后生成上下文和目标词的create_contexts_target函数就可以将corpus(单词ID列表)作为参数。函数的输出contexts是一个二维数组,第 0 维保存的是各个上下文数据。函数的输出 target[N] 保存的是第 N 个目标词,如下图所示。

def create_contexts_target(corpus, window_size=1):
'''生成上下文和目标词
:param corpus: 语料库(单词ID列表)
:param window_size: 窗口大小(当窗口大小为1时,左右各1个单词为上下文)
:return:
'''
target = corpus[window_size:-window_size]
contexts = []
for idx in range(window_size, len(corpus)-window_size):
cs = []
for t in range(-window_size, window_size + 1):
if t == 0:
continue
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)
用这个函数:
import sys
sys.path.append('..')
from common.util import preprocess #, create_co_matrix, most_similar
from common.util import create_contexts_target
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
contexts, target = create_contexts_target(corpus, window_size=1)
print(contexts)
print(target)
输出:
[[0 2]
[1 3]
[2 4]
[3 1]
[4 5]
[1 6]]
[1 2 3 4 1 5]
因为这些上下文和目标词的元素还是单词 ID,所以 还需要将它们转化为 one-hot 表示。如下图所示。

实现代码如下:convert_one_hot函数的参数是单词 ID 列表和词汇个数。
def convert_one_hot(corpus, vocab_size):
'''转换为one-hot表示
:param corpus: 单词ID列表(一维或二维的NumPy数组)
:param vocab_size: 词汇个数
:return: one-hot表示(二维或三维的NumPy数组)
'''
N = corpus.shape[0]
if corpus.ndim == 1:
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
elif corpus.ndim == 2:
C = corpus.shape[1]
one_hot = np.zeros((N, C, vocab_size), dtype=np.int32)
for idx_0, word_ids in enumerate(corpus):
for idx_1, word_id in enumerate(word_ids):
one_hot[idx_0, idx_1, word_id] = 1
return one_hot
运行上面几个预处理函数:
import sys
sys.path.append('..')
from common.util import preprocess #, create_co_matrix, most_similar
from common.util import create_contexts_target, convert_one_hot
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
contexts, target = create_contexts_target(corpus, window_size=1)
print(contexts)
print(target)
vocab_size = len(word_to_id)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)
print(vocab_size)
print(target)
print(contexts)
结果:
[[0 2]
[1 3]
[2 4]
[3 1]
[4 5]
[1 6]]
[1 2 3 4 1 5]
7
[[0 1 0 0 0 0 0]
[0 0 1 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 0 0 1 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 1 0]]
[[[1 0 0 0 0 0 0]
[0 0 1 0 0 0 0]]
[[0 1 0 0 0 0 0]
[0 0 0 1 0 0 0]]
[[0 0 1 0 0 0 0]
[0 0 0 0 1 0 0]]
[[0 0 0 1 0 0 0]
[0 1 0 0 0 0 0]]
[[0 0 0 0 1 0 0]
[0 0 0 0 0 1 0]]
[[0 1 0 0 0 0 0]
[0 0 0 0 0 0 1]]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号