
nlp 共现矩阵和余弦相似度
2022-04-05 14:34 jym蒟蒻 阅读(893) 评论(0) 收藏 举报通过共现矩阵和余弦相似度实现机器对单词的认知、python实现
- 本文介绍的定义:
- 一、语料库预处理
- 二、单词的分布式表示
- 三、单词的相似度
- 四、相似单词排序
语料库、计数方法的目的、语料库预处理、单词的分布式表示、分布式假设、上下文、窗口大小、基于计数的方法表示单词、用向量表示单词、共现矩阵、单词的相似度、余弦相似度、相似单词排序。
语料库:大量的文本数据。
计数方法的目的:从语料库中提取语言的本质。
语料库预处理:将文本分割为单词,并将分割后的单词列表转化为单词ID列表。实现代码如下,其中corpus 是单词ID列表,word_to_id 是单词到单词ID的字典,id_to_word是单词ID到单词的字典。
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
举个例子:
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
print(corpus)
print(word_to_id)
print(id_to_word)
输出:
[0 1 2 3 4 1 5 6]
{'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}
{0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'}
单词的分布式表示:颜色通过RGB三原色分别存在多少来表示,RGB这样的向量表示,可以更准确地指定颜色,颜色之间的关联性(是否是相似的颜色)也更容易通过向量表示来判断和量化。类似于颜色的向量表示方法运用到单词上,形成单词含义的向量表示,在自然语言处理领域,这称为分布式表示。
分布式假设:某个单词的含义由它周围的单词形成。单词本身没有含义,单词含义由它所在的上下文(语境)形成。
上下文:上下文是指某个单词的周围词汇。
窗口大小:将上下文的大小(即周围的单词有多少个)称为窗口大小。
基于计数的方法表示单词:如何基于分布式假设使用向量表示单词?可以在关注某个单词的情况下,对它的周围出现了多少次什么单词进行计数,然后再汇总,称为“基于计数的方法”。
用向量表示单词:向量表示的是每个单词的上下文(与窗口大小有关)所包含的单词的频数(出现次数)。

共现矩阵:如下图所示,汇总所有单词的向量表示的表格。
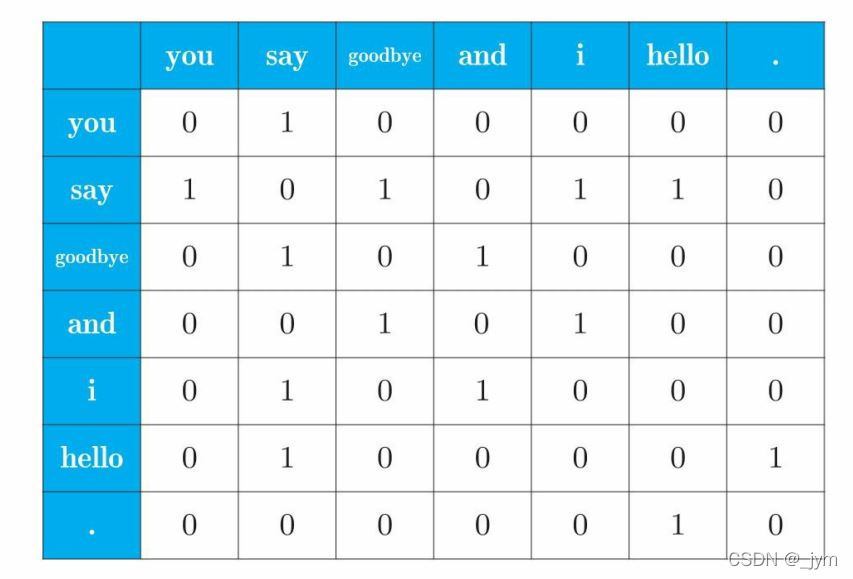
代码:
def create_co_matrix(corpus, vocab_size, window_size=1):
'''生成共现矩阵
:param corpus: 语料库(单词ID列表)
:param vocab_size:词汇个数
:param window_size:窗口大小(当窗口大小为1时,左右各1个单词为上下文)
:return: 共现矩阵
'''
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix
C = create_co_matrix(corpus, vocab_size, window_size=1)
for i in range(7):
print(C[i])
输出:
[0 1 0 0 0 0 0]
[1 0 1 0 1 1 0]
[0 1 0 1 0 0 0]
[0 0 1 0 1 0 0]
[0 1 0 1 0 0 0]
[0 1 0 0 0 0 1]
[0 0 0 0 0 1 0]
单词的相似度:两个单词含义相近的程度。
前面通过共现矩阵将单词表示为了向量,如何测量向量间的相似度?有代表性的方法有向量内积、欧式距离、余弦相似度等。
余弦相似度:设有x、y两个向量,他们的余弦相似度公式如下。余弦相似度直观表示了两个向量在多大程度上指向同一方向,两个向量完全指向相同的方向时,余弦相似度为 1;完全指向相反的方向时,余弦相似度为 -1。

实现余弦相似度:需要解决除数为0问题,可以在执行除法时加上一个微小值。
实现代码:
def cos_similarity(x, y, eps=1e-8):
'''计算余弦相似度
:param x: 向量
:param y: 向量
:param eps: 用于防止“除数为0”的微小值
:return:
'''
nx = x / (np.sqrt(np.sum(x ** 2)) + eps)
ny = y / (np.sqrt(np.sum(y ** 2)) + eps)
return np.dot(nx, ny)
例子:求you和i的相似度 。
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
c0 = C[word_to_id['you']] #you的单词向量
c1 = C[word_to_id['i']] #i的单词向量
print(cos_similarity(c0, c1))
输出:
0.7071067691154799
相似单词排序:当某个单词被作为查询词时,将与这个查询词相似的单词按降序显示出来。
实现步骤:
1.取出查询词的单词向量:
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
2.求查询词的单词向量和其他所有单词向量的余弦相似度。
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
3.基于余弦相似度的结果,按降序显示它们的值。argsort()方法可以按升序对 NumPy 数组的元素进行排序,返回值是数组的索引。将 NumPy 数组的各个元素乘以 -1 后,再使用 argsort() 方法,可以按降序输出单词相似度。
count = 0
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s: %s' % (id_to_word[i], similarity[i]))
count += 1
if count >= top:
return
完整代码:
def most_similar(query, word_to_id, id_to_word, word_matrix, top=5):
'''相似单词的查找
:param query: 查询词
:param word_to_id: 从单词到单词ID的字典
:param id_to_word: 从单词ID到单词的字典
:param word_matrix: 汇总了单词向量的矩阵,假定保存了与各行对应的单词向量
:param top: 显示到前几位
'''
if query not in word_to_id:
print('%s is not found' % query)
return
print('\n[query] ' + query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
count = 0
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s: %s' % (id_to_word[i], similarity[i]))
count += 1
if count >= top:
return
例子:按降序显示与you最相似的前五个单词。
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
most_similar('you', word_to_id, id_to_word, C, top=5)
输出:结果和我们的感觉存在很大的差异。一个可能的原因是,这里的语料库太小了。
[query] you
goodbye: 0.7071067691154799
i: 0.7071067691154799
hello: 0.7071067691154799
say: 0.0
and: 0.0
 浙公网安备 33010602011771号
浙公网安备 33010602011771号