机器学习 卷积神经网络 手写数字识别
2022-04-05 14:30 jym蒟蒻 阅读(145) 评论(0) 收藏 举报一、CNN网络结构与构建
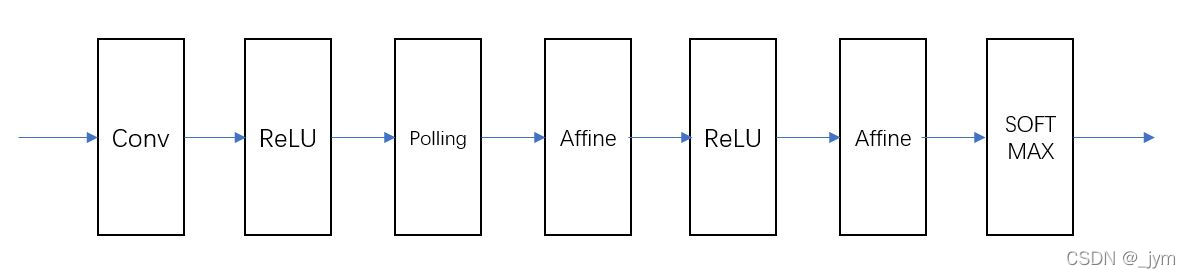
参数:
输入数据的维数,通道,高,长
input_dim=(1, 28, 28)
卷积层的超参数,filter_num:滤波器数量,filter_size:滤波器大小,stride:步幅,pad,填充。
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1}
hidden_size,隐藏层全连接神经元数量;
output_size,输出层全连接神经元数量;
weight_init_std,初始化时,权重的标准差;
hidden_size=100, output_size=10, weight_init_std=0.01
学习所需参数是第一层的卷积层和剩余两个全连接层的权重和偏置。权重、偏置,分别用W、b保存。
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
代码:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2']