机器学习 Dropout方法
2022-04-05 14:25 jym蒟蒻 阅读(687) 评论(0) 收藏 举报解决神经网络过拟合问题—Dropout方法
- 一、what is Dropout?如何实现?
- 二、使用和不使用Dropout的训练结果对比
如果网络模型复杂,L2范数权值衰减方法就难以对付过拟合。这种情况下,用Dropout方法。
Dropout是一种在学习过程中随机删除神经元的方法。
训练时,随机选出隐藏层神经元,然后将其删除。每传递一次数据,就会随机选择要删除的神经元。
测试时,对各个神经元的输出,要成上训练时的删除比例。
实现代码:
每次正向传播,self.mask以False形式保存要删除的神经元。
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
self.mask随机生成和x形状相同数组,将值大于dropout_ratio元素设为True。
每次反向传播,如果正向传播时候传递了信号的神经元,反向传按原样传,反之不传。
class Dropout:
"""
http://arxiv.org/abs/1207.0580
"""
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
从MNIST数据集里只选出来300个数据,然后增加网络复杂幅度用7层网络,每层100个神经元,激活函数ReLU。
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了再现过拟合,减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]
# 设定是否使用Dropuout,以及比例 ========================
use_dropout = True # 不使用Dropout的情况下为False
dropout_ratio = 0.2
# ====================================================
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
# 绘制图形==========
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
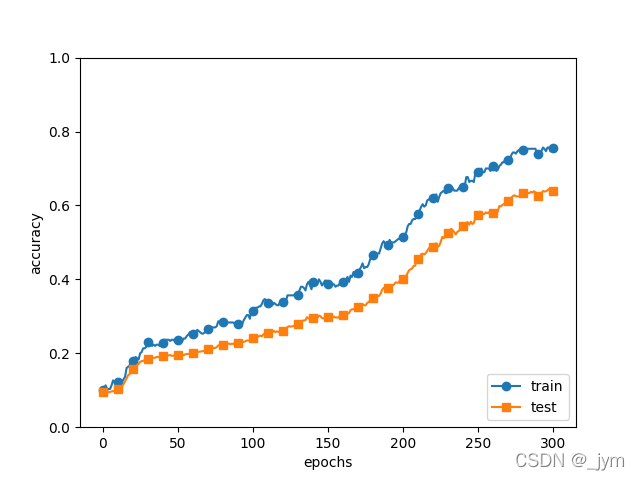
下图是使用Dropout的情况
下图是不使用Dropout的情况。
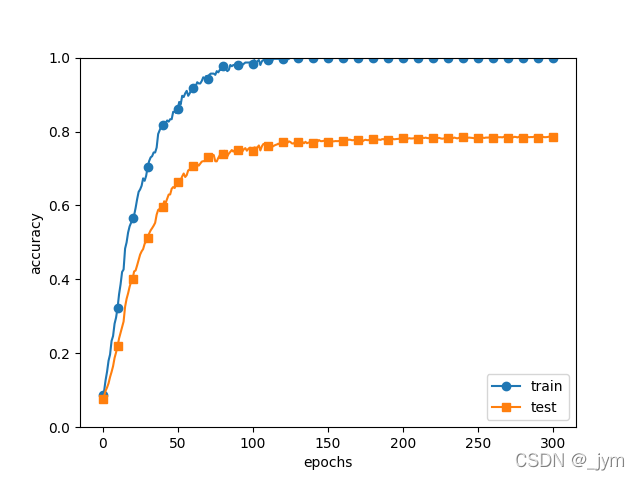
对比得出,使用Dropout,训练数据和测试数据的识别精度的差距变小了,并且训练数据也没有到100%识别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号