拨开字符编码的迷雾--编译器如何处理文件编码
拨开字符编码迷雾系列文章链接:
1. Visual Studio字符集
使用Visual Studio创建的C++工程可以在工程属性配置属性-->常规中配置字符集:使用Unicode字符集(默认)、使用多字节字符集。
如图:
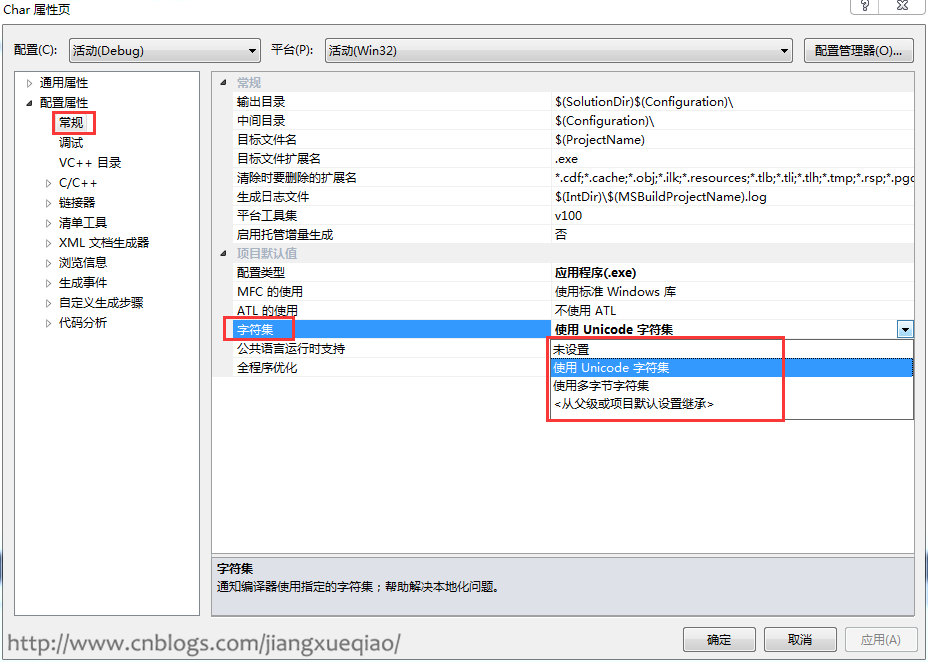
但这个设置项不会对编译器处理字符编码产生直接的影响(注意这里的“直接”二字,第3节会说到),只会在工程属性配置属性-->C/C++-->预处理器加入相应的宏:
使用Unicode字符集 --> _UNICODE和UNICODE宏
使用多字节字符集 --> _MBCS宏
这几个宏一般用来判断是使用char还是wchar_t,在系统API中使用比较多,如MessegeBox通过是否定义了UNICODE宏来决定是使用LPCSTR还是LPCWSTR(LPCSTR即const char, LPCWSTR即const wchar_t):
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
2. char和wchar_t
上面提到了,定义API时通过判断UNICODE宏是否定义来决定是使用char还是wchar_t,那么char和wchar_t有什么不同了?
char和wchar_t是标准C/C++字符类型,并不是windows特有的。 char固定占1个字节,wchar_t固定占2个字节,从内存的角度来看,char、wchar_t和其他数据类型一样,只是代表一段内存块,用来存储固定长度的二进制0或1。 在编程时,我们一般习惯于将字符串储到char或wchar_t定义的内存空间中,将整形存储在int定义的内存空间中。
所以,用char还是wchar_t来存储字符,只是内存分配和数据存储上面的事情,它们本身也是与字符编码无直接关系的( 同样注意这里的“直接”二字,第3节会说到)。
3. 编译器如何处理硬编码字符
VC++编译器编译源代码的步骤中,涉及编码处理的步骤主要有2个:
第1步:预处理
1.1) 读取源文件,判断源文件采用的字符编码类型。(这一步不会改变文件内容)
编译器判断源文件编码类型的步骤为:
1. 若文件开始处有BOM(EF BB BF),则判定为UTF-8编码;
2. 若没有BOM,则试图从文件的前8个字节来判断文件是否像UTF-16编码,如果像,则就判断为UTF-16编码。
3. 如果既没BOM,也不是UTF-16编码,则使用系统当前的代码页(简体中文操作系统为CP936)。
不了解字符编码的朋友可以参考前一篇博客拨开字符编码的迷雾--字符编码概述
1.2) 将源文件内容转成源字符集(Source Character Set),默认为UTF-8编码。
第2步:链接
2.1) 将1.2中得到的UTF-8转为执行字符集(Execution Character Set):
- 对于宽字符串(即C/C++中以
L标记的串,如L"abc",L'中'),执行字符集为UTF-16编码。 - 对于窄字符串(和宽字符串对应,即不以
L标记的串),执行字符集为系统当前的代码页。

现在我们就可以说清楚Visual Studio字符集设置、char、wchar_t是如何间接影响到编译器对字符编码的处理了:
Visual Studio字符集设置
|
决定声明哪一个宏(UNICODE还是_MBCS宏)
|
宏又决定了API参数使用char还是wchar_t
|
编译器在进行【执行字符集】编码时对char和wchar_采用不同的处理方式,从而对字符编码产生了影响。
在Visual Studio 2010(含)之后,支持使用
# pragma execution_character_set来设置执行字符集。
4. 实例分析
- 已知汉字“中”的各种编码如下:
GBK D6 D0
Unicode 2D 4E
UTF-8 E4 B8 AD
- 函数
DumpCharacterCode用于按字节打印内存中的数据:
void DumpCharacterCode(const char* pChar, int iSize) {
for(int i = 0; i < iSize; i++) {
char a = *pChar++;
printf("%02X ", a & 0xff);
}
printf("\n");
}
-
设置系统代码页的方法:
“控制面板” --> “区域和语言” --> “管理” --> “非Unicode程序的语言” --> “更改系统区域设置” -
Visual Studio保存文件到指定编码方法:
“文件” --> “高级保存选项”
4.1 测试编译器处理窄字符编码
测试代码如下:
int _tmain(int argc, _TCHAR* argv[])
{
char buf[100] = {"中"}; // char
DumpCharacterCode(buf, 2); // 也可以打印4个字节
return 0;
}
针对不同的系统代码页和源文件编码,打印出的汉字“中”的编码分别为:
| 测试用例 | 系统代码页 | 保存源文件编码 | 编译器判断文件采用的编码 | 源字符集(Source Character Set) | 执行字符集(Execution Character Set) | 打印输出 |
|---|---|---|---|---|---|---|
| 用例1 | 简体中文 CP936 | 简体中文 CP936 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | D6 D0 |
| 用例2 | 简体中文 CP936 | UTF-8 BOM | UTF-8 | UTF-8 | 简体中文 CP936 | D6 D0 |
| 用例3 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | 编译错误(C2146) |
| 用例4 | 西欧 CP1252 | 简体中文 CP936 | 西欧 CP1252 | UTF-8 | 西欧 CP1252 | D6 D0 |
| 用例5 | 西欧 CP1252 | UTF-8 BOM | UTF-8 BOM | UTF-8 | 西欧 CP1252 | 3F 00 |
表格中列4~6依次对应编译处理源文件的几个步骤。
3F对应的ASCII字符为?,编译器遇到不能识别的字符时,就会用?来替代。 出现?的情况会伴随着编译警告C4566。
上面出现了1次3F(用例5),导致乱码的原因是UTF-8 --> 西欧 CP1252. 西欧 CP1252也就是ASCII的扩展,不支持汉字,所以用3F替代。
用例3为什么会编译错误?
微软的编译器只能识别带BOM的UTF-8,用例3的UTF-8没带BOM,编译器会判定源文件编码为系统当前代码页CP936。“中”的UTF-8编码为E4 B8 AD,列5执行从CP936到UTF-8转换之后变成了E6 B6 93 3F,列6再要将E6 B6 93 3F转换为CP936肯定是转换不回去的,相当于 UTF-8(1) --> UTF-8 (2),再将UTF-8(2)转换回CP936,这时肯定得到的字符不是原来的字符了。
用例4为什么输出的D6 D0,而不是3F?
对着用例4的各个顺序来看,源文件通过CP936保存着,但编译器通过CP1252来读取的,CP1252就是ASCII扩展,单字节的,虽然此时显示为乱码,但各字节仍然是D6 D0;然后将读取到的文件内容从CP1252转成UTF-8编码,转码后为C3 96 C3 90;然后再将UTF-8编码转回为CP1251,转码就又变成了D6 D0。 但这个D6 D0在CP1252中是无法显示的,如果我们在用例4加入MessageBoxA(NULL, "中", "test", MB_OK); 会发现弹出的对话框中显示仍然是乱码。
可以使用下面的代码进行测试(ANSIToUTF8、UTF8ToANSI函数见拨开字符编码的迷雾--字符编码转换):
int _tmain(int argc, _TCHAR* argv[])
{
char buf[3] = { 0 }; // 模拟CP936编码的“中”
buf[0] = 0xD6;
buf[1] = 0xD0;
std::string strUTF8 = ANSIToUTF8(buf, 1252);
char *p = (char*)strUTF8.c_str(); // 通过visual studio查看指针p处内存为: C3 96 C3 90
std::string str = UTF8ToANSI(strUTF8, 1252);
p = (char*)str.c_str(); // 通过visual studio查看指针p处内存为: D6 D0
return 0;
}
4.2 测试编译器处理宽字符编码
测试代码如下:
int _tmain(int argc, _TCHAR* argv[])
{
wchar_t buf[100] = {L"中"}; // wchar_t
DumpCharacterCode((char*)buf, 4); // 打印4个字节
return 0;
}
同样,针对不同的系统代码页和源文件编码,打印出的汉字“中”的编码分别为:
| 测试用例 | 系统代码页 | 保存源文件编码 | 编译器判断文件采用的编码 | 源字符集(Source Character Set) | 执行字符集(Execution Character Set) | 打印输出 |
|---|---|---|---|---|---|---|
| 用例1 | 简体中文 CP936 | 简体中文 CP936 | 简体中文 CP936 | UTF-8 | UTF-16 | 2D 4E 00 00 |
| 用例2 | 简体中文 CP936 | UTF-8 BOM | UTF-8 | UTF-8 | UTF-16 | 2D 4E 00 00 |
| 用例3 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | UTF-8 | UTF-16 | 编译错误(C2146) |
| 用例4 | 西欧 CP1252 | 简体中文 CP936 | 西欧 CP1252 | UTF-8 | UTF-16 | D6 00 D0 00 大小端 |
| 用例5 | 西欧 CP1252 | UTF-8 BOM | UTF-8 BOM | UTF-8 | UTF-16 | 2D 4E 00 00 |
5. 彻底避免硬编码字符乱码
通过第3节的说明,很容易知道,要开发支持多语言,在任意语言(系统代码页)的windows环境下都正常编译,且运行起来没有乱码的程序,需要遵循如下原则:
- 代码文件采用UTF-8 with BOM编码。
- Visual Studio字符集设置为Unicode字符集。
- 使用wchar_t。
做到上面3步,你的代码被别人从github上clone下来编译,不会因为你代码中含有中文等字符,产生类似error C2015这样的编译错误,更不会产生乱码。
本文介绍的方法只用来解决硬编码字符乱码的问题,至于数据传输中的乱码,需要统一字符编码来解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号