用于文本分类的多层注意力模型(Hierachical Attention Nerworks)
论文来源:Hierarchical Attention Networks for Document Classification
1、概述
文本分类时NLP应用中最基本的任务,从之前的机器学习到现在基于词表示的神经网络模型,分类准确度也有了很大的提升。本文基于前人的思想引入多层注意力网络来更多的关注文本的上下文结构。
2、模型结构
多层注意力网络(HAN)的结构如下图所示:

整个网络结构包括四个部分:
1)词序列编码器
2)基于词级的注意力层
3)句子编码器
4)基于句子级的注意力层
整个网络结构由双向GRU网络和注意力机制组合而成,具体的网络结构公式如下:
1)词序列编码器
给定一个句子中的单词 $w_{it}$ ,其中 $i$ 表示第 $i$ 个句子,$t$ 表示第 $t$ 个词。通过一个词嵌入矩阵 $W_e$ 将单词转换成向量表示,具体如下所示:
$ x_{it} = W_e; w_{it}$
接下来看看利用双向GRU实现的整个编码流程:
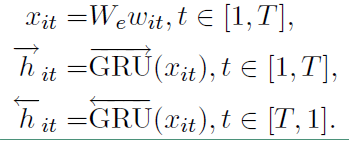
最终的 $h_{it} = [{\rightarrow{h}}_{it}, \leftarrow{h}_{it}]$ 。
2)词级的注意力层
注意力层的具体流程如下:
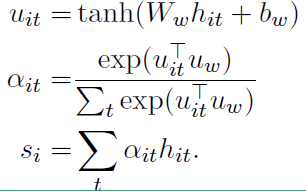
上面式子中,$u_{it}$ 是 $h_{it}$ 的隐层表示,$a_{it}$ 是经 $softmax$ 函数处理后的归一化权重系数,$u_w$ 是一个随机初始化的向量,之后会作为模型的参数一起被训练,$s_i$ 就是我们得到的第 $i$ 个句子的向量表示。
3)句子编码器
也是基于双向GRU实现编码的,其流程如下,
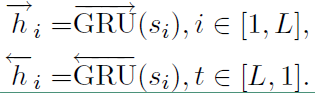
公式和词编码类似,最后的 $h_i$ 也是通过拼接得到的
4)句子级注意力层
注意力层的流程如下,和词级的一致
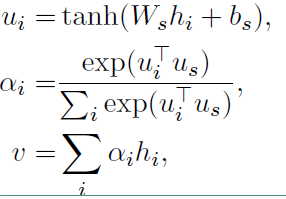
最后得到的向量 $v$ 就是文档的向量表示,这是文档的高层表示。接下来就可以用可以用这个向量表示作为文档的特征。
3、分类
直接用 $ softmax$ 函数进行多分类即可
![]()
损失函数如下:
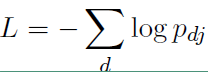

 浙公网安备 33010602011771号
浙公网安备 33010602011771号