

深度学习之从RNN到LSTM
1、循环神经网络概述
循环神经网络(RNN)和DNN,CNN不同,它能处理序列问题。常见的序列有:一段段连续的语音,一段段连续的手写文字,一条句子等等。这些序列长短不一,又比较难拆分成一个个独立的样本来训练。那么RNN又是怎么来处理这类问题的呢?RNN就是假设我们的样本是基于序列的。比如给定一个从索引$0$到$T$的序列,对于这个序列中任意索引号$t$,它对应的输入都是样本$x$中的第$t$个元素$x^{(t)}$。而模型在序列索引号t位置的隐藏状态$h^{(t)}$则是由$x^{(t)}$和在$t-1$位置的隐藏状态$h^{(t-1)}$共同决定的。而模型在$t$时刻的输出$o^{(t)}$,就是由$h^{(t)}$通过非线性转换得到的。
当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列。
以nlp的一个最简单词性标注任务来说,将”我” “吃” “苹果“ 三个单词标注词性为 我/nn 吃/v 苹果/nn。那么这个任务的输入就是:
我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。此时就需要RNN来处理该问题。
再者我们常见的语言模型有2-Gram或者是3-Gram,当n-Gram中的n大于3之后,样本容量会非常大,甚至超过现有的计算能力。此时RNN就可以解决该问题,理论上RNN可以往前往后关联任意多个词。
2、循环神经网络模型
先以一个最常见的RNN模型来展开
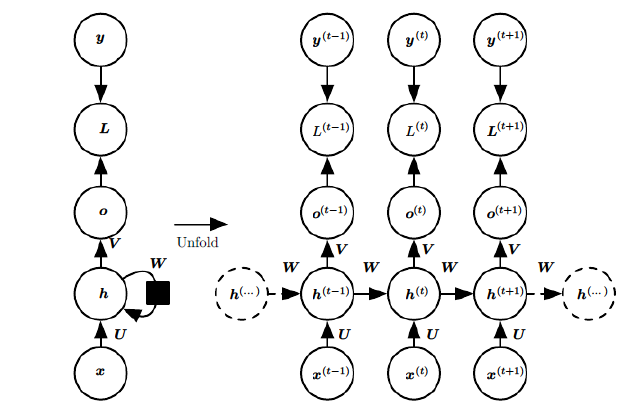
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
这幅图描述了在序列索引号t 附近RNN的模型。其中:
1)x(t)代表在序列索引号 t 时训练样本的输入。同样的,x(t-1) 和 x(t+1) 代表在序列索引号 t−1 和 t+1 时训练样本的输入。
2)h(t) 代表在序列索引号 t 时模型的隐藏状态。h(t)由x(t)和 h(t-1) 共同决定。
3)o(t) 代表在序列索引号 t 时模型的输出。o(t)只由模型当前的隐藏状态 h(t) 决定。
4)L(t) 代表在序列索引号 t 时模型的损失函数,模型整体的损失函数是所有的L(t)相加和。
5)y(t) 代表在序列索引号 t 时训练样本序列的真实输出。
6)$U, W, V$这三个矩阵就是我们的模型的线性关系参数,它在整个RNN网络中是共享的。也正是因为是共享的,它体现了RNN的模型的“循环反馈”的思想。
3、循环神经网络的前向传播算法
循环网络的前向传播算法非常简单,对于t时刻:
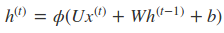
其中$\phi (.)$为激活函数,一般来说会选择tanh函数,b为偏置。则 t 时刻的输出:
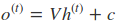
最终模型的预测输出为:
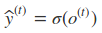
其中σ为激活函数,激活函数通常选择softmax函数。
4、循环神经网络的反向传播算法
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。当然这里的BPTT和DNN中的BP算法也有很大的不同点,即这里所有的 $U, W, V$ 在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失L为:
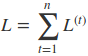
因此可以得到U,V,W的偏导,其中V的比较好求

而在求W和U的时候就比较的复杂了。
在反向传播时,在某一序列位置 t 的梯度损失由当前文职的输出对应的梯度损失和序列索引位置 t + 1 时的梯度损失两部分共同决定的。
对于W在某一序列位置 t 的梯度损失需要反向传播一步步的计算。
比如以$t=3$时刻为例
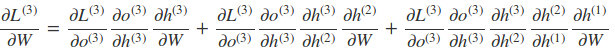
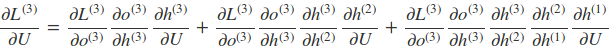
因此,在某个时刻的对 W 或是 U 的偏导数,需要追溯这个时刻之前所有时刻的信息。根据上面的式子可以归纳出 L 在 t 时刻对 W 和 U 偏导数的通式:
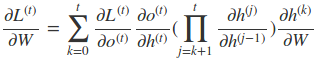

而对于里面的乘积部分,我们引入激活函数,则可以表示为:
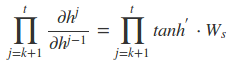
或者是
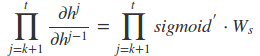
然而对于 Sigmoid 函数和 tanh 函数及其导数有以下的特点
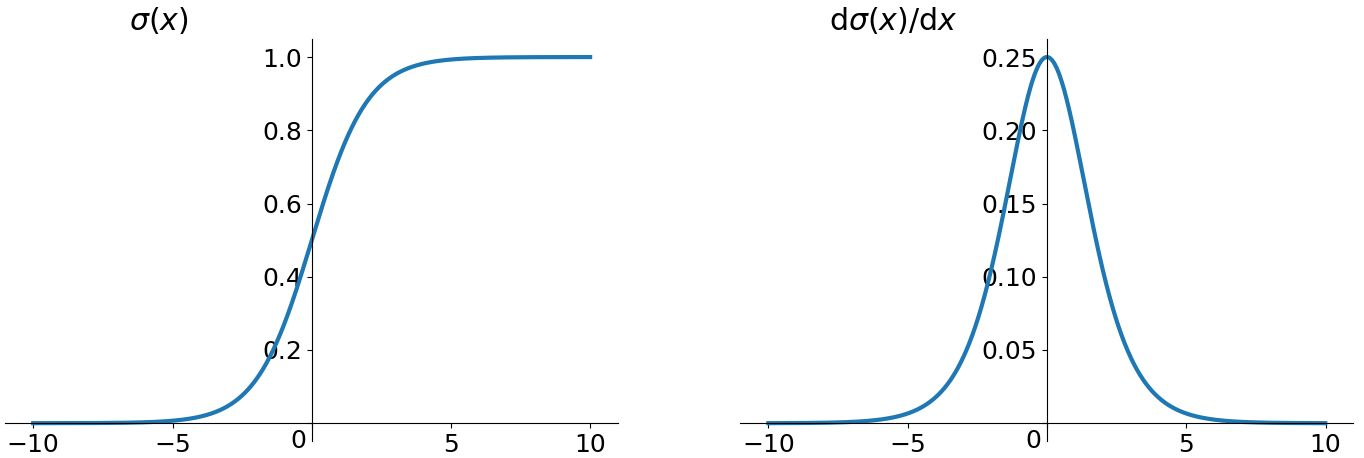
sigmoid 函数及其导数
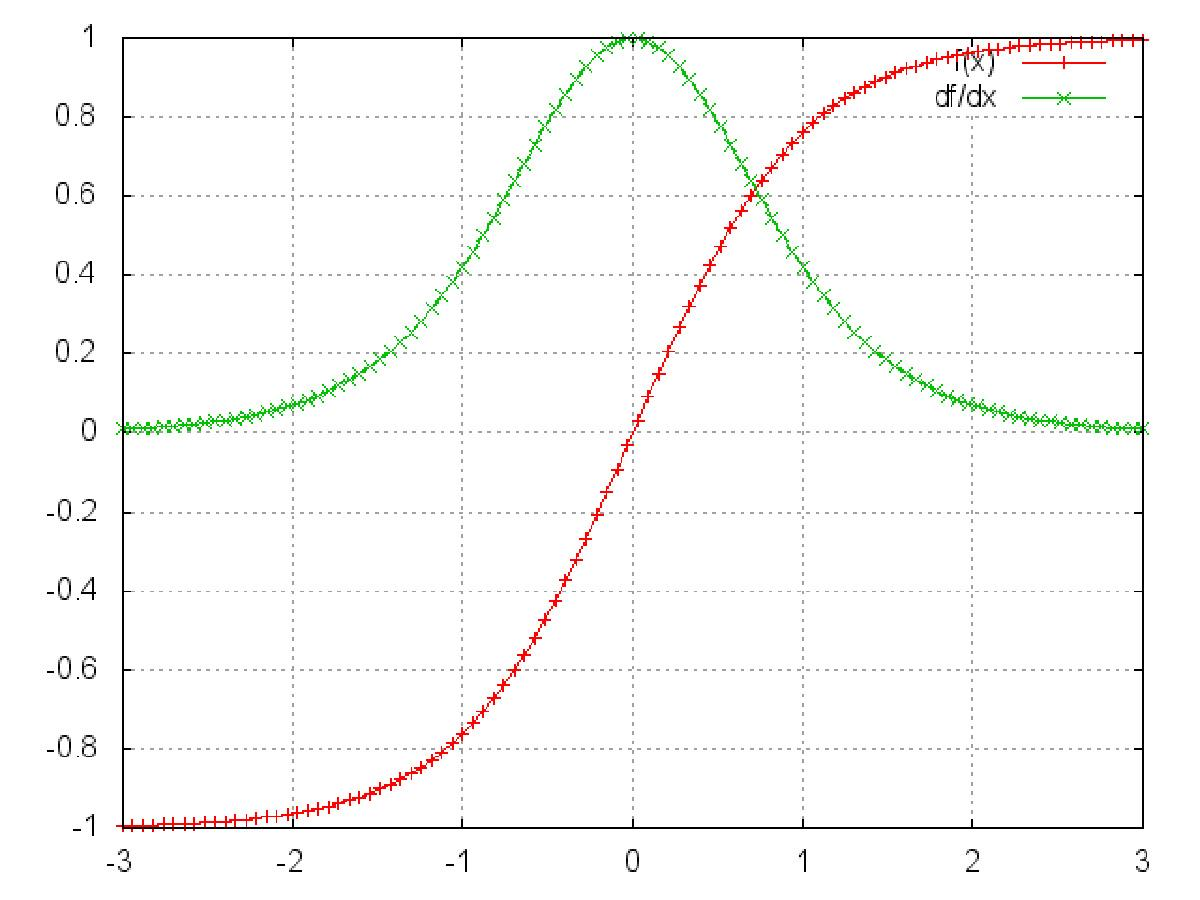
tanh 函数及其导数
Relu 函数及其导数
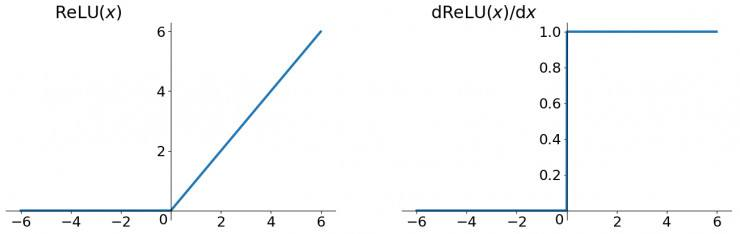
我们可以从中观察到,sigmoid 函数的导数范围是(0, 0.25], tanh 函数的导数范围是 (0, 1] ,他们的导数最大都不大于 1。因此在上面求梯度的乘积中,随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于 0,这就会引起梯度消失现象。梯度消失就意味着那一层的参数再也不更新了,则模型的训练毫无意义。Relu 函数一定程度上可以解决梯度消失的问题,但是容易引起梯度爆炸的问题。此外 tanh 函数的收敛速度要快于 sigmoid 函数,而且梯度消失的速度要慢于 sigmoid 函数。
利用BPTT算法训练网络时容易出现梯度消失的问题,当序列很长的时候问题尤其严重,因此上面的RNN模型一般不能直接应用。而较为广泛使用的是RNN的一个特例LSTM。
5、LSTM 网络
Long Short Term 网络,一般就叫做 LSTM ,是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。

LSTM 同样是这样的结构,但是重复的模块的结构更加复杂。不同于 单一神经网络层,整体上除了 h 在随时间流动,细胞状态 c 也在随时间流动。细胞状态 c 就代表着长期记忆,而状态 h 代表了短期记忆。
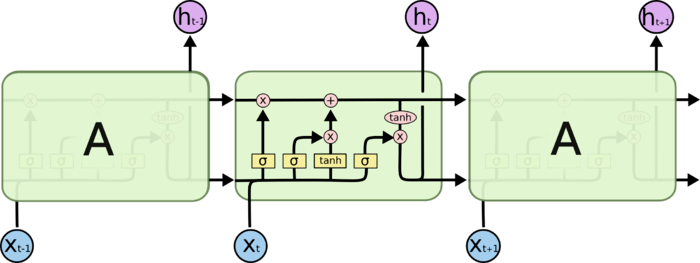
上面我们给出了LSTM的模型结构,下面我们就一点点的剖析LSTM模型在每个序列索引位置 t 时刻的内部结构。
从上图中可以看出,在每个序列索引位置 t 时刻向前传播的除了和RNN一样的隐藏状态 ht ,还多了另一个隐藏状态,如图中上面的长横线。这个隐藏状态我们一般称为细胞状态(Cell State),记为 Ct 。如下图所示:
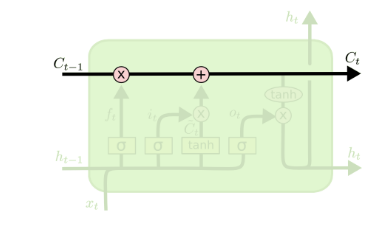
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。LSTM在在每个序列索引位置t的门一般包括遗忘门,输入门和输出门三种。下面我们就来研究上图中LSTM的遗忘门,输入门和输出门以及细胞状态。
5.1 遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
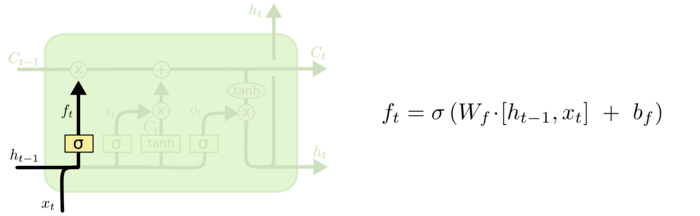
在这里 ht-1 表示历史信息,xt 表示当前流入细胞中新的信息。
xt 在这里的作用是为了根据当前输入的新的信息来决定要忘记哪些历史信息。
例如在语言模型中,基于已经看到的预测下一个词。
在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。
当我们看到新的主语,我们希望忘记旧的主语。
两者的结构都是向量,在这里我们将两个向量拼接起来输入。输出一个在 0 到 1 之间的数值,这个数值决定要遗忘多少历史信息。
1 表示“完全保留”,0 表示“完全舍弃”。
5.2 输入门
输入门(input gate)负责处理当前序列位置的输入,确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后一个 tanh 层创建一个新的候选值向量 $ \tilde{C}_t $ ,会被加入到状态中。它的子结构如下图:
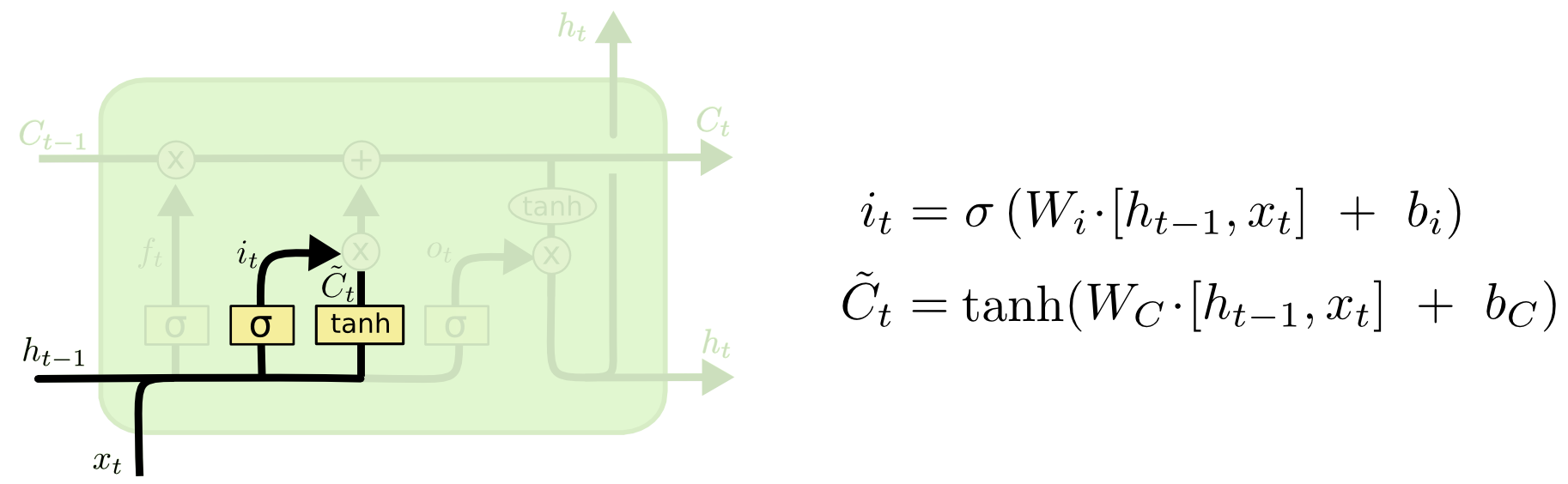
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。所以在更新新的细胞状态时,主要要做的两件事就是决定哪些历史信息该流入当前细胞中(遗忘们控制),决定哪些新的信息该流入细胞中(输入们控制)。
在获得了输入门和遗忘门系数之后就可以更新当前的细胞状态,Ct-1 更新为 Ct 。
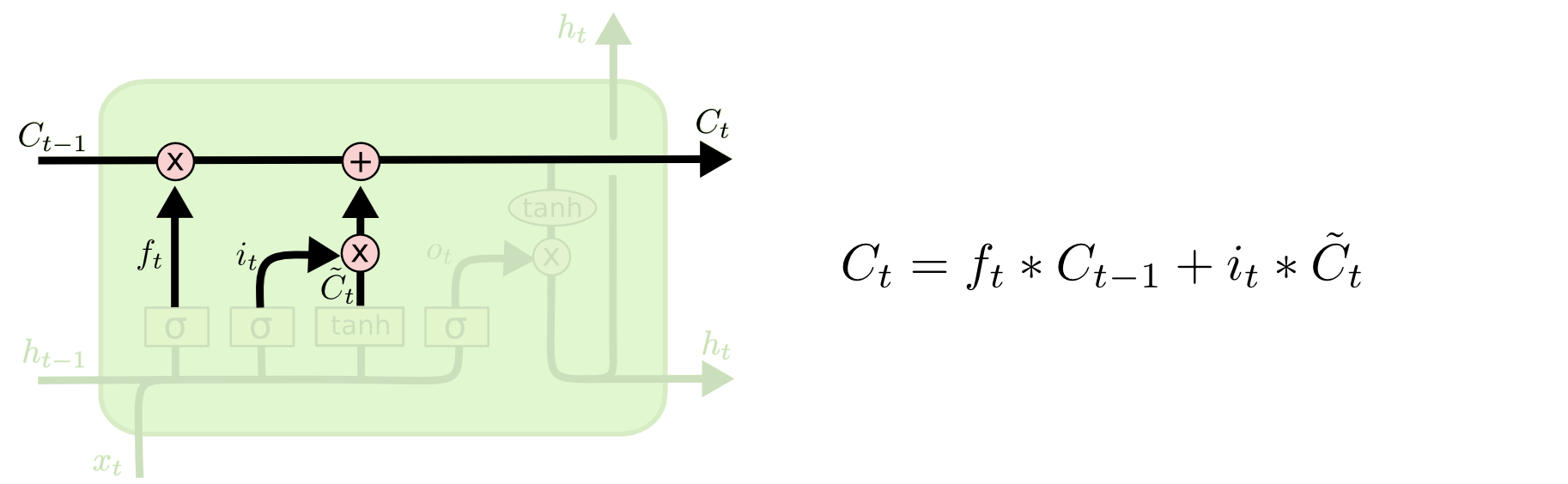
5.3 输出门
在得到了新的隐藏细胞状态 Ct ,我们就得开始去输出结果,输出门的子结构如下:
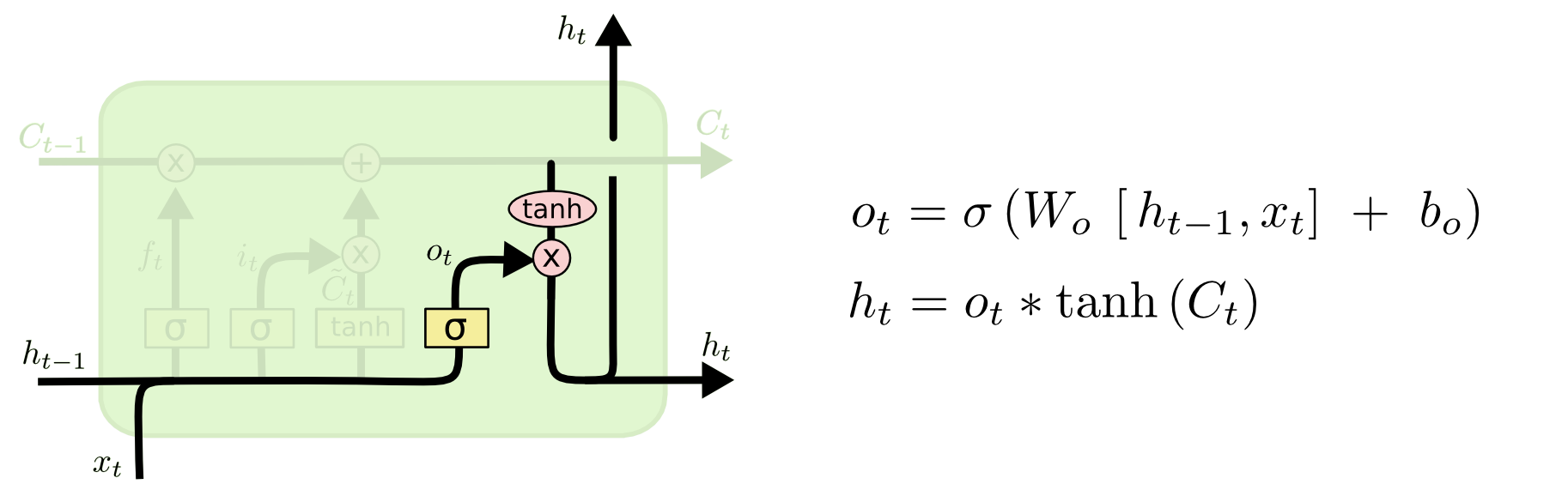
从图中可以看出,隐藏状态 ht 的更新由两部分组成,输出门依然是由历史信息 ht-1 和新的信息 xt 来决定的,。
输入门、遗忘门、输出们所对应的函数都是 sigmoid 函数(因为 Sigmoid 函数的输出值范围为0-1,相当于控制门的百分比过滤),因此输出的结果是[0, 1],当为0时,门完全关闭,当为1时,门完全打开。输入们控制这当前输入值有多少信息流入到当前的计算中,遗忘门控制着历史信息中有多少信息流入到当前计算中,输出们控制着输出值中有多少信息流入到隐层中。所有LSTM除了有三个门来控制当前的输入和输出,其他的和RNN是一致的。
6、LSTM前向传播算法
LSTM模型有两个隐藏状态 ht , Ct ,模型参数几乎是RNN的4倍,因为现在多了 Wf, Uf, bf, Wa, Ua, ba, Wi, Ui, bi, Wo, Uo, bo 这些参数。
前向传播过程在每个序列索引位置的过程为:
1)更新遗忘门输出:
2)更新输入门两部分输出:
3)更新细胞状态:
4)更新输出门输出:
5)更新当前序列索引预测输出:
知道了前向传播,反向传播和RNN中的一样,也是借助梯度下降来训练模型,具体的训练过程可以看这里
总归LSTM模型结构是非常复杂的,而且参数众多,因此调参时要非常仔细,并且要深刻理解模型的每个结构才能更好的选取参数。
**本文为结合多篇博客的总结笔记**

