LightGBM介绍及参数调优
1、LightGBM简介
LightGBM是一个梯度Boosting框架,使用基于决策树的学习算法。它可以说是分布式的,高效的,有以下优势:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
与常见的机器学习算法对比,速度是非常快的
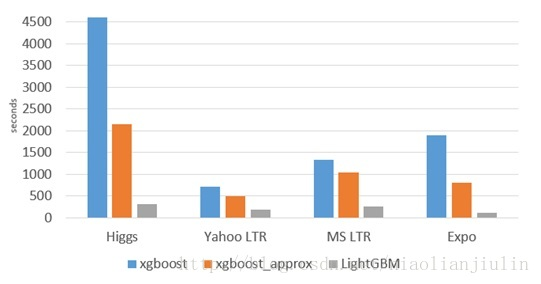
2、XGboost的缺点
在讨论LightGBM时,不可避免的会提到XGboost,关于XGboost可以参考此博文
关于XGboost的不足之处主要有:
1)每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
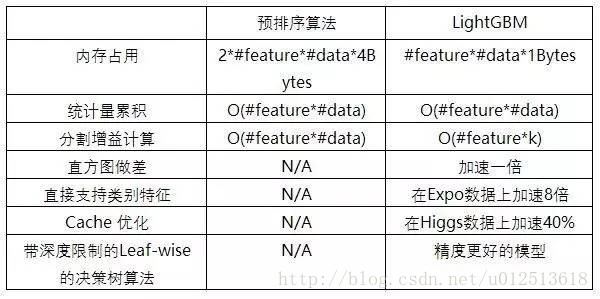
2)预排序方法的时间和空间的消耗都很大
3、LightGBM原理
1)直方图算法
直方图算法的基本思想是先把连续的浮点特征值离散化成$k$个整数,同时构造一个宽度为$k$的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。在XGBoost中需要遍历所有离散化的值,而在这里只要遍历$k$个直方图的值。
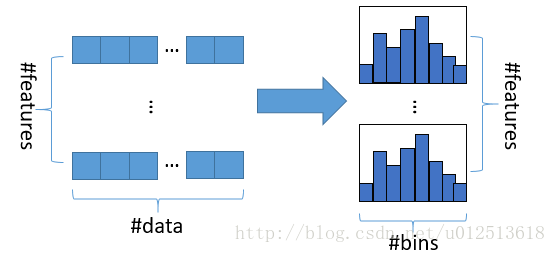
使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值。
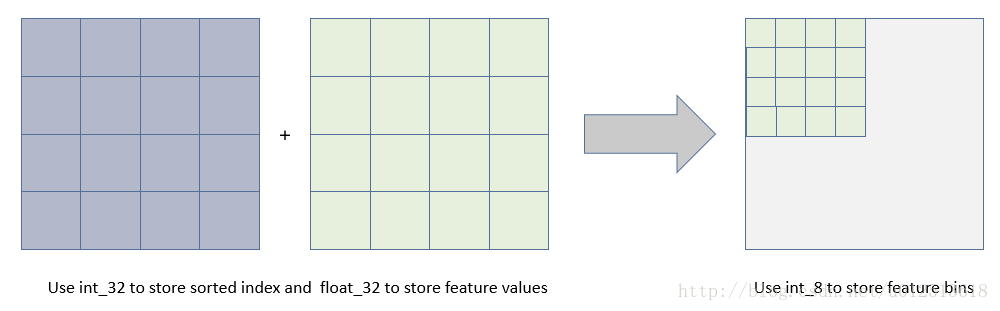
然后在计算上的代价也大幅降低,XGBoost预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算$k$次($k$可以认为是常数),时间复杂度从O(#data * #feature) 优化到O(k* #features)。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient
Boosting)的框架下没有太大的影响。
2)LightGBM的直方图做差加速
一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后(父节点在上一轮就已经计算出来了),可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

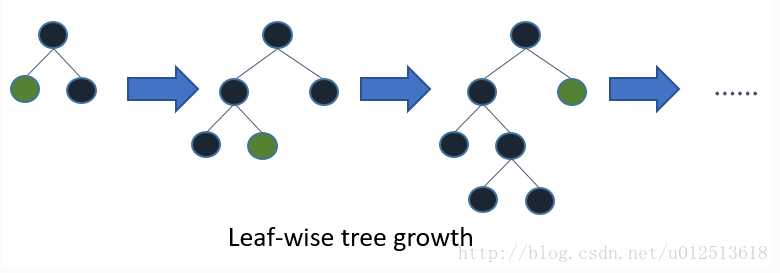
3)带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
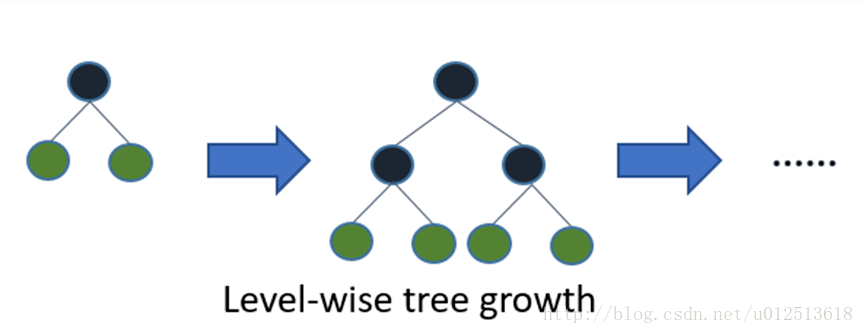
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
4)直接支持类别特征(即不需要做one-hot编码)
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的one-hot编码特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的one-hot编码展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。
5)直接支持高效并行
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
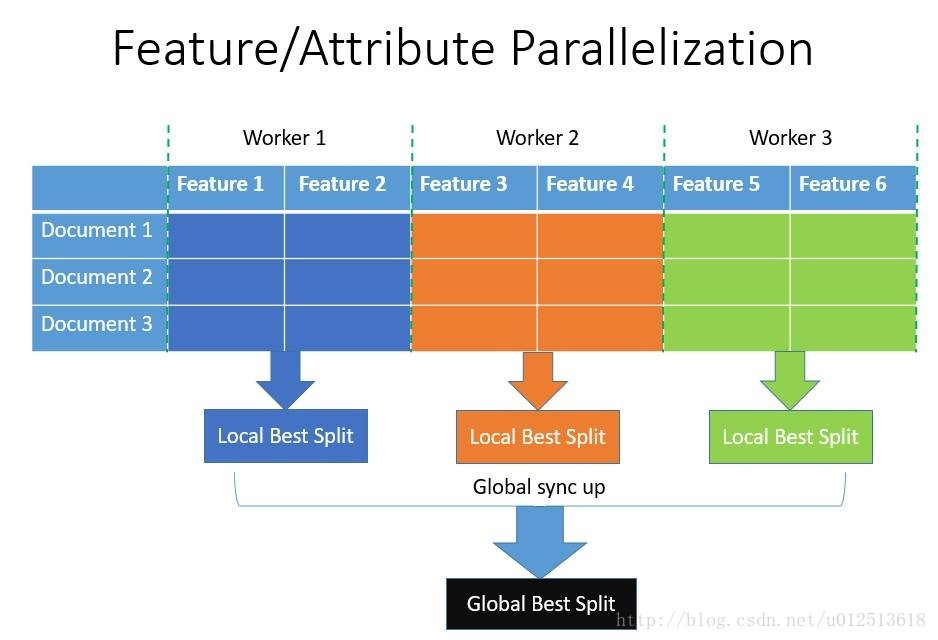
1)特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
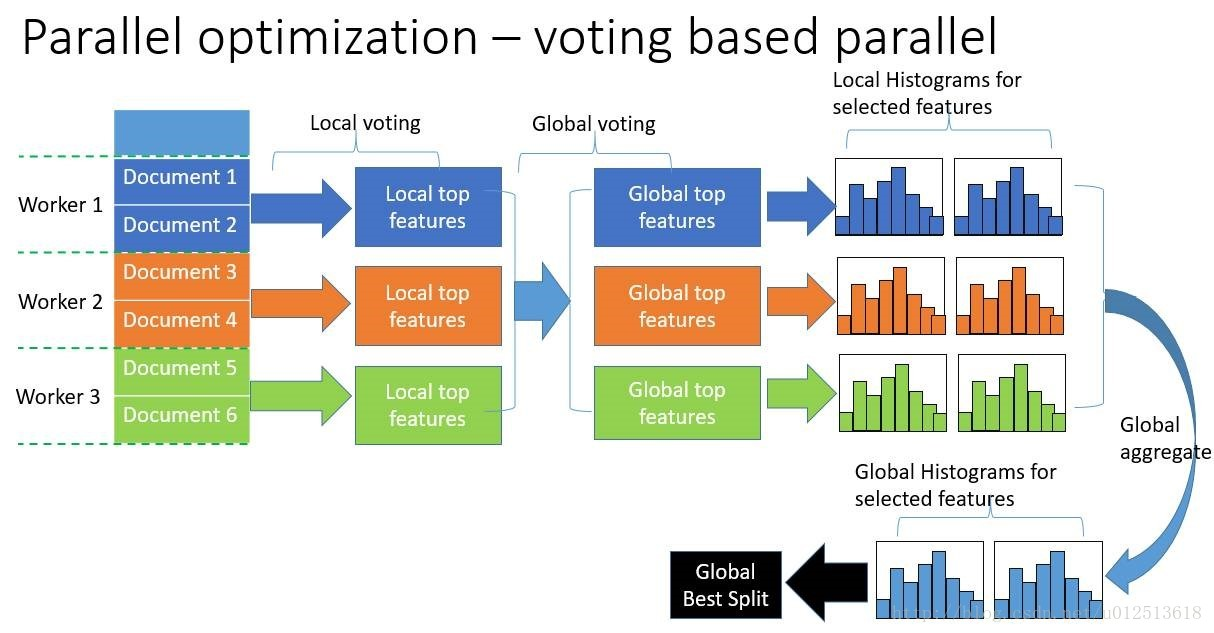
2)数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约
(Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
4、LightGBM参数调优
下面几张表为重要参数的含义和如何应用
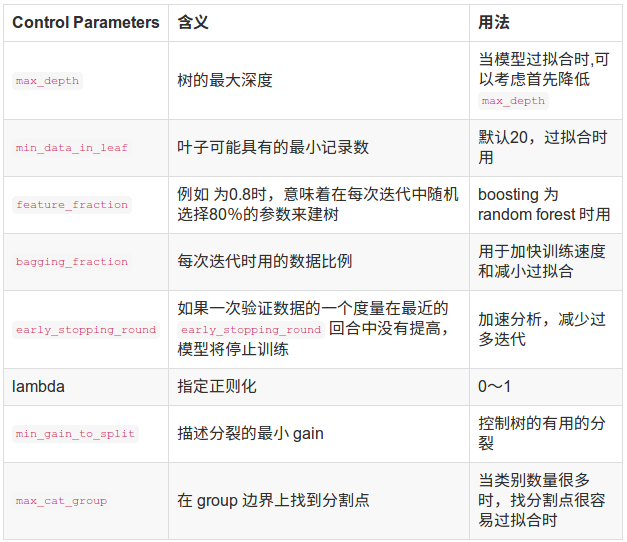


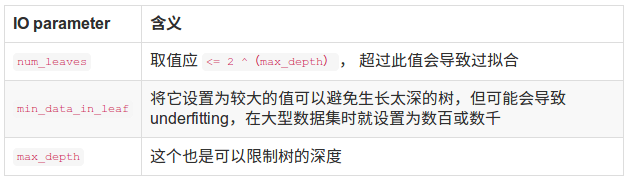
接下来是调参
下表对应了Faster Spread,better accuracy,over-fitting三种目的时,可以调整的参数

参考文献:
https://zhuanlan.zhihu.com/p/25308051

 浙公网安备 33010602011771号
浙公网安备 33010602011771号