
大模型入门(八)—— Llama2论文简读
一、背景介绍
大语言模型 (LLM) 作为功能强大的人工智能助手展现出了巨大的前景,它们擅长完成需要跨领域专业知识的复杂推理任务,包括编程和创意写作等专业领域。 它们通过简单直观的聊天界面与人类互动,让大预言模型快速地被推广。
大语言模型的模型架构和训练方法相对比较统一,大多数都是在大规模的语料上通过自我监督的方法预训练自回归transformer模型。当前的大语言模型以OpenAI为领先者,先后推出了ChatGPT,GPT4等效果显著的大语言模型,但OpenAI选择了模型闭源、以API对外服务的模式,这些闭源模型虽然效果好、易使用,但也容易受到OpenAI的限制,因此开源社区也一直在寻找它们的“平替”。
Meta一直在致力于大语言模型的开源,虽然不是最早开源大语言模型的,但却是影响力最大的,早在今年2月份,Meta开源了LLaMA-7B、LLaMA-13B、LLaMA-33B和LLaMA-65B 四种参数的大语言模型,其中的LLaMA-65B在当时已经达到了PaLM-540B(谷歌开发的闭源大语言模型)的同等水平,而之后以LLaMA为基座模型,通过SFT微调得到的Alpaca,Vicuna等一系列模型进一步推动了大语言模型开源社区的发展,其中Vicuna基于GPT4的评测,其效果已达到ChatGPT的90%。
LLaMA2是今年7月Meta推出的LLaMA优化版本,在LLaMA的基础上通过引入更多的预训练数据、增大上下文长度等技术进一步提升模型的效果。LLaMA2开源了7B、13B、70B 三种参数的模型,并同时开源了同等参数的LLaMA2-chat(以LLaMA2为基础,在对话用例上指令微调)模型。经人工评测LLaMA2-cha-70B的效果已经超过了ChatGPT,且所有开源的LLaMA2和LLaMA2-chat都可以商用。
二、能力评测
Meta对LLaMA2(预训练模型)和LLaMA2-Chat(微调模型)在公开的测试数据上进行了大量的评测,总的来说,LLaMA2基本超越了所有的开源模型,和闭源模型对比,除了编码能力外,其他能力基本达到了GPT3.5同等水平;LLaMA2-Chat已经超过了ChatGPT。
2.1、LLaMA2评测
Meta在常识推理、世界知识、阅读理解、数学能力、专业知识综合评测、编码能力等多个维度上评测了LLaMA2和开源模型,以及闭源模型的能力。从评测结果来看,如下表3所示,LLaMA2-70B全面领先于其他开源模型,如MPT、Falcon、LLaMA1,同等参数下也要更优。

在和闭源模型对比上,如下表4所示,基本上和PaLM持平,和GPT3.5相比除了在HumanEval(编码能力)还有较大差距,在MMLU(专业综合能力)和GSM8K(数学能力)上也基本持平。但较GPT4和PaLM-2-L还有较大的差距,尤其是GPT4,差距还是非常明显。

数据集备注:
MMLU:包含了57个学科的综合知识能力测试数据集。现主流的大模型评测数据集。
TriviaQA:世界知识的阅读理解数据集。
Natural Questions:世界知识的问答数据集。
GSM8K:多语言的小学数据测试集。
HumanEval:代码生成数据集,测试编码能力。
BIG-Bench Hard:包含多个领域的综合能力测试数据集。
2.2、LLaMA2-Chat评测
Meta也对LLaMA2-Chat和当前开源、以及闭源的模型做了评测对比,如下图12所示,让两个对比的模型在约4000个helpfulness prompts上生成回复,人工判断哪个模型的效果更好,用win/tie/loss表示LLaMA2-Chat是赢/持平/输。由于Meta在LLaMA2-Chat投入了大量的成本来微调,也让LLaMA2-Chat的效果要显著优于开源的模型(如MPT-chat,Vicuna等等),和ChatGPT对比也有略微的优势。在多轮对话的测试上,LLaMA2-Chat也展现出了类似的优势。

同时也对模型的安全性和开源、闭源模型进行了对比。如下图15所示,左图展示了模型违规比例(越低越好),右图展示了模型综合有用性和安全性的得分(越高越好)。得益于Meta在模型安全性上大量的工作,LLaMA2-Chat表现除了极高的安全性,而综合得分来看,也优于MPT、Vicuna、Falcon等开源模型,以及PaLM、ChatGPT等闭源模型。

2.3、评测总结
1)LLaMA2预训练模型在自然语言理解、逻辑推理、编码等能力上要显著优于当前的开源模型,基本持平GPT3.5(编码能力除外),但较GPT4,PaLM-2还有不小的差距。
2)LLaMA2-chat微调模型在有用性和安全性上要显著优于当前的开源模型,较ChatGPT也有微弱的优势。且在多轮对话的能力上保持着类似的竞争力。
总得来说在当前的开源社区中,LLaMA2和LLaMA2-chat可以作为首要选择。
三、训练流程
LLaMA2的训练流程包括预训练和指令微调两个部分。
3.1、预训练
Meta的训练语料库包括来自公开来源的新数据组合,其中不包括来自 Meta 产品或服务的数据。Meta努力剔除某些已知的包含大量个人隐私信息的网站数据。并让其在 2 万亿个Token 的数据上进行了训练,因为这样可以更好地权衡性能和成本,对最真实的数据源进行上采样,以增加知识和减少幻觉。
LLaMA2采用了LLaMA1的大部分预训练设置和模型架构。使用了标准的Transformer Decoder架构,应用了RMSNorm进行pre-normalization,使用了SwiGLU激活函数,以及旋转位置嵌入(RoPE)。与LLaMA1相比,主要的优化点有:1、预训练数据增加了40%;2、上下文长度由2048增大到4096;3、在34B和70B两种参数的模型中引入了GQA(grouped-query attention)提升模型的推理速度。具体的细节如下表1所示:

3.2、指令微调
LLaMA2-Chat中的指令微调采用了和ChatGPT相同的RLHF三阶段式的微调,且公开了大量的指令微调的技术细节。LLaMA2-Chat中的RLHF分为三个阶段:Supervised Fine-Tuning(SFT);训练Reward Model;Iterative Fine-Tuning。
3.2.1、SFT
SFT是通过构造prompt-response问答对微调模型,将模型的输出和人类的表达形式对齐。Meta的SFT训练数据主要从有用性和安全性这两个维度标注,如下表5所示的例子:

Meta首先从开源的SFT数据集中筛选出百万级的数据样例冷启动微调LLaMA2-Chat,再使用人工标注的高质量数据进一步微调LLaMA2-Chat。Meta总共标注了27540个数据样例,Meta认为高质量且多样性的少量标注数据就可以取得非常好的效果。
在SFT中,每个样本由一个prompt和一个response组合而成,prompt和response之间由特殊字符间隔,采用自回归的方式训练,训练过程中prompt的loss输出置0。
3.2.2、Reward Model
奖励模型(Reward Model)依赖大量的用户偏好数据训练,Meta在偏好数据的标注上投入了大量的成本,总共标注了约140万条偏好数据(有人预估成本约在2000万美金左右)。Meta让标注员编写一个prompt,然后通过不同的模型变体生成两个response,标注员从有用性和安全性两个维度上衡量去选择更偏好的response。在标注的过程中除了选择偏好的response之外,还会标注4个偏好等级,分别为“明显更好/更好/好/差不多”,同时判定每个response是否是安全的回复。最终剔除掉“偏好的response不安全”但“不偏好的renponse安全”的数据,因为作者认为人类偏好的response就应该是更安全的。
奖励模型接受一个“prompt-response”的问答对,会输出一个分数,用于指示生成的response的质量。在奖励模型的训练过程中是输入一个偏好数据对(一个prompt,对应一个偏好的response和一个不偏好的response),训练目标是让“prompt-偏好的response”得分要大于“prompt-不偏好的response”。
Meta在奖励模型上按照有用性和安全性单独训练了两个奖励模型,因为有研究表明有用性和安全性之间存在trade-off,很难同时集成到一个模型中。针对有用性和安全性两个奖励模型,也设计了不同的训练数据配比。模型的训练目标是让偏好的response得分要大于不偏好的response,公式表示如下:
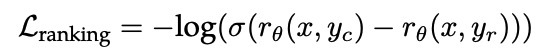
$y_c$是偏好的response,$y_r$是不偏好的response。但前面也提到偏好数据的标注中,Meta还标注的偏好等级,在训练目标中如果引入偏好等级可以进一步提升奖励模型的效果,因此最终的训练目标公式如下:

m(r)是偏好等级的数值化,可以作为超参数预先设置好,偏好等级越高,m(r)设置的就越大。
Meta自己训练的奖励模型在多份偏好数据上测试都要优于GPT4,具体的结果如下表7,Meta在实际测试中发现,随着奖励模型的规模增大,以及偏好数据的增多,模型的效果也会越来越好,而且奖励模型的效果和最终的LLaMA2-chat的效果是正相关的,通过提升奖励模型的效果,LLaMA2-chat的效果也会得到进一步提升。

3.2.3、Iterative Fine-Tuning
Meta在RLHF的第三阶段并没有直接使用PPO算法直接微调,而是设计了多轮迭代的方式,并结合拒绝采样和PPO算法共同微调。Meta将迭代式微调(Iterative Fine-Tuning)分成了5轮,每一轮都会得到对应版本的模型,分别命名为RLHF-V1 ,..., RLHF-V5。Meta的偏好数据是随着训练的进行不断地去标注的,因此每一轮使用的奖励模型都会增加新的偏好数据进行更新,这也能保证奖励模型的数据分布和当前要微调的模型数据分布基本保持一致。
在RLHF-V1,...,RLHF-V4只使用拒绝采样微调,在RLHF-V5先使用拒绝采样微调,再使用PPO微调。拒绝采样微调是使用奖励模型辅助标注prompt-response的问答对数据,然后通过SFT的方式微调模型,举个例子,在开始微调RLHF-V3模型时,标注人员先给定一个prompt,然后用RLHF-V2模型生成不同的response,接着用奖励模型对所有的response打分,取得分最高的response作为该prompt的回复,通过这样一套流程构造大量的prompt-response问答对数据,基于这些数据采用SFT的方式微调RLHF-V3模型。
PPO算法是基于AC架构的策略梯度算法,其训练目标是最大化价值最大的序列发生的概率,其训练目标公式如下:

PPO算法训练过程中依赖奖励模型输出的奖励值辅助训练,但同时为了避免微调的模型过度拟合奖励模型的表现,同时引入了KL散度约束微调的模型输出结果的变化,结合这两个值构成了PPO算法中的奖励值,其表达公式如下:

Meta的奖励模型的分数是由有用性奖励模型和安全性奖励模型共同输出得到的,通过分段函数结合两个模型的输出结果,当prompt是不安全的或者安全性奖励模型输出的分数小于0.15,则使用安全性奖励模型的输出作为奖励分数,否则就使用有用性奖励模型的输出作为奖励分数,最终还会对奖励模型输出的结果归一化处理,以确保奖励模型输出的分数和KL散度约束值能在一个度量范围内。其表达式如下:

Meta也评测了随着不断地迭代微调,模型的表现也越来越好,如下图11所示,Meta基于自己的奖励模型和GPT4打分,分别对比了SFT-V1, SFT-V2, RLHF-V1, ..., RLHF-V5和ChatGPT在有用性和安全性上的表现。左图展示的是Meta的奖励模型评测结果,可以看到SFT-V2就基本达到了ChatGPT同等的效果,右图展示的是GPT4的评测结果,可以看到RLHF-V4就基本和ChatGPT效果持平。而RLHF-V5无论是在Meta的奖励模型还是GPT4的测试结果下都优于ChatGPT。


