
大模型入门(二)—— PEFT
PEFT(Parameter-Efficient Fine-Tuning)是hugging face开源的一个参数高效微调大模型的工具,里面集成了4中微调大模型的方法,可以通过微调少量参数就达到接近微调全量参数的效果,使得在GPU资源不足的情况下也可以微调大模型。
1)LORA:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
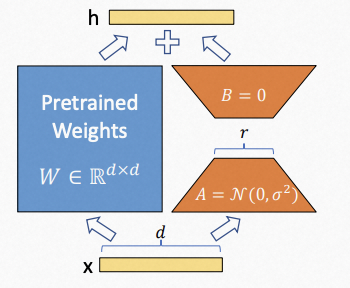
LORA是PEFT中最常用的方法,LORA认为过参数的模型权重其实存在低内在维度,那么模型适应过程中的权重变化也存在低内在维度,因此模型在微调的过程中实际上可以通过微调低秩矩阵来微调模型。LORA的微调过程如下:在Linear层增加一个“旁路”, “旁路”用A、B两个矩阵组合表示,维度分别是d × r和 r × d,其中r远小于d,A随机初始化,B初始化为0,在微调模型的过程中,左边的W不更新,只更新右边的A和B的参数。前向传播时是左右的输出和,反向传播时只更新右边,因此计算的梯度以及优化器的中间值也只和右边有关,最终右边的参数会单独保存下来。LORA这种训练方式不会改变大模型的参数,且针对每个下游任务生成自己的LORA参数,在预测阶段只要将大模型的参数和LORA参数叠加在一起即可。
LORA还提供了单独的库loralib,可以结合pytorch一起使用。
2)P-tuning:GPT Understands, Too
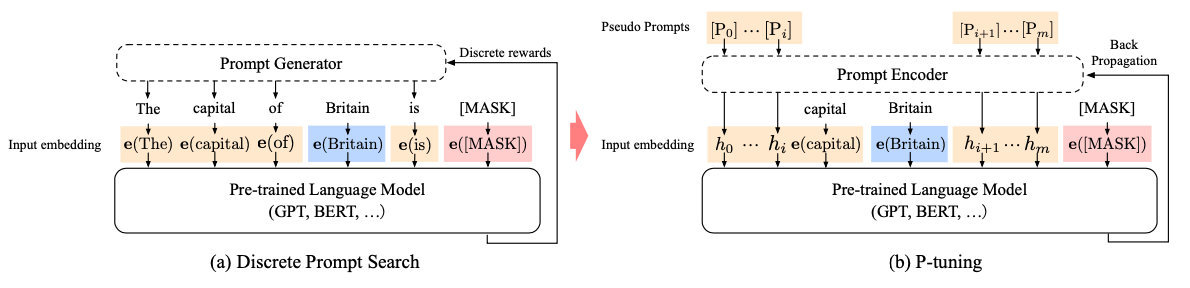
一般在通过Prompt的方式使用大模型时,通常需要人工构造一些模板,P-tuning将自然语言模板的构建转换成连续参数优化的问题,用一些特殊的token替代人工构造的自然语言模板,让模型自己去学习这些连续的token,在学习的过程中只微调这些token的embedding参数,并且为了保证token之间的联系,并不是随机初始化embedding,而是通过lstm层学习这些token的embedding。
3)Prefix Tuning:Optimizing Continuous Prompts for Generation
Prefix Tuning针对不同的模型结构有设计不同的模式,以自回归的模型为例,不再使用token去作为前缀,而是直接使用参数作为前缀,比如一个l × d的矩阵P作为前缀,但直接使用这样的前缀效果不稳定,因此使用一个MLP层重参数化,并放大维度d,除了在embedding层加入这个前缀之外,还在其他的所有层都添加这样一个前缀。最后微调时只调整前缀的参数,大模型的参数保持不变。保存时只需要为每个任务保存重参数的结果即可。

4)Prompt tuning:The Power of Scale for Parameter-Efficient Prompt Tuning
像GPT3中那种,通过人工构造一些token作为前缀输入到模型中,因为这些token是从vocab中选择的,因此会受到大模型的参数的影响,所以要取得好的结果的话,人工构造的提示语必须要符合模型训练语料的特性。而Prompt tuning是为Prompt单独生成一份参数,在微调的过程中大模型的参数冻结不变,只更新Prompt的参数。且文章实验表明对于Prompt的参数使用大模型的vocab中的一些token 的embedding初始化,或者使用标签词的嵌入(当标签词的token数大于1时,对所有token取平均,即将一个标签词看作一个整体)初始化要比随机初始化的效果要好。此外Prompt的长度对结果也会有影响,长度越长效果会越好,但随着模型的规模变大,不同长度或者不同初始化的Prompt之间的差距会被缩小。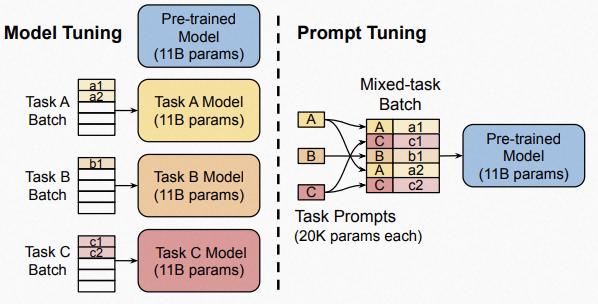

 浙公网安备 33010602011771号
浙公网安备 33010602011771号