NLP新范式(Prompt/Instruct)
NLP的四范式
NLP发展到今天已经进入到了LLM的时代,随着模型越来越大,在zero-shot/few-shot的情形下也表现的越来越好,NLP也进入到了新的研究范式里面。学术界按发展时间线将NLP归纳到四个范式:

1),传统的基础学习范式。
2),基于word2vec,cnn,rnn的全监督深度学习范式。
3),基于预训练 + fine-tune的范式。
4),基于预训练 + Prompt + 预测的范式。
第一范式需要加工tf-idf等特征,应用机器学习模型建模。第二范式引入了word2vec将词的稀疏向量转换成稠密向量表征,应用CNN、RNN等深度学习模型建模。第三范式由Elmo、GPT、BERT等预训练模型引入的基于预训练 + 下游任务fine-tune模式。第四范式在预训练语言模型越来越大之后,模型突破了一些边界,涌现出在能直接作用于下游任务上的能力,只不过需要给定一些提示将模型的这些能力激发出来,因此也就进入到预训练 + Prompt的zero-shot或者few-shot learning时代。而在Prompt之后,为了朝AGI的方向发展,预训练 + Prompt模式被进一步升级到预训练 + Instruct的模式。
预训练语言模型的框架
在预训练语言模型的发展中,出现了四类框架,而现在更多地朝着Decoder-Only发展。
1)Encoder-Only,以BERT为代表的自编码模型。
2)Decoder-Only,以GPT为代表的自回归模型。
3)Encoder-Decoder,以T5为代表的seq2seq模型。
4)Prefix-LM,一种Encoder-Decoder的变种,以UniLM。
虽然GPT比BERT出来的更早,但在预训练模型的发展初期,BERT取得了更多的关注和更好的效果,一是NLU的任务有更多的关注度,而BERT在NLU的任务上表现效果更好,二是预训练 + Fine-tune的模式可以解决预训练任务和下游任务不一致的问题。所以一开始各种模型都是在BERT的基础上迭代优化。但在T5出来之后,将所有的NLU任务都统一成NLG任务,用一个NLG的模型同时解决NLU和NLG的任务(这也是因为NLU任务容易转换成NLG任务,但NLG任务无法转换成NLU任务)。随着GPT3的出现,超大规模参数的模型突破了一些边界,涌现出了新的能力,GPT3 + Prompt(In-Context leanring)在很多zero-shot场景下取得了sota的结果,从此就实现了任务和模型的收敛。将所有的NLP任务都转换成生成式,模型就朝着Decoder-Only的方向发展。
Decoder-Only的趋势有很多原因,Decoder-Only相比Encoder训练成本更低,而自回归的训练数据也更容易构造,在下游任务都统一成NLG的模型,自回归的训练方法和下游任务也更贴合。
Prompt到Instruct
Prompt的本质是在将下游任务和预训练任务统一,充分挖掘预训练模型的能力。
Prompt从模板的形式上可以分成hard Prompt和soft Prompt:
hard Prompt:人工定义模板,模板中的answer可以是在句子前面,中间或者后面,通常在中间(MLM形式)和后面(NLG形式)比较多。人工定义模板很依赖模板的形式是否和预训练时的数据分布一致,分布一致才能取得较好的效果。
soft Prompt:人工定义模板难度较高,需要较多的尝试才有可能取得好的效果,soft Prompt旨在解决这个问题,典型的如P-tuning,将模板转换成一些可以学习的特殊token,在特定的下游任务,使用少量的样本去训练这些token(预训练模型的参数被固定住)。
在GPT3中大放异彩的In-Context learning本质上也属于Prompt,而且是hard Prompt,GPT3中通过给一些提示(zero-shot),或者给一些训练数据(few-shot)作为前缀提示,就能在很多任务上取得sota的效果,这也说明大模型在给定一些提示下能涌现出能处理下游任务的能力。
In-Context learning 本质上学到的是什么,在Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?这篇论文中有做详细的分析,In-Context learning在few-shot(即给定了少量训练数据)场景下,并没有像fine-tune那样去学习x到y的映射关系,学到的只是x和y的数据分布,相当于理解了下游任务的特点之后就能很好的预测下游任务。
对于更复杂的推理问题,如解数学题,可以通过思维链(CoT, Chain of Thought)的方式指定模板,也就是给定一些示例,并把人工的解题/推理思路写出来,以此作为输入到模型中的提示信息。能极大地提升模型的推理能力。
In-Context learning是给定一些更具像的示例或符合机器理解的模板,而Instruct是用人类习惯的表述去指示模型预测下游任务,以ChatGPT为代表,引入更多符合人类表达的训练数据,或者是通过RLHF的方式直接和人交互去微调模型,让模型能更适应人的表述指示来处理下游任务。
ChatGPT/InstructGPT
ChatGPT是InstructGPT的兄弟模型,不同的点主要在于ChatGPT引入了人类的对话数据。相比于GPT3,一是可以通过更符合人类表达的指示去让模型处理下游任务;二是模型的有用、可信和无害的特点。
ChatGPT除了继承了GPT的模型结构和预训练任务之外,核心还是引入了人类反馈的强化学习进行训练。这种训练模型加强了人类对模型输出结果的把控,并且给模型提供更符合人类认知的排序结果。
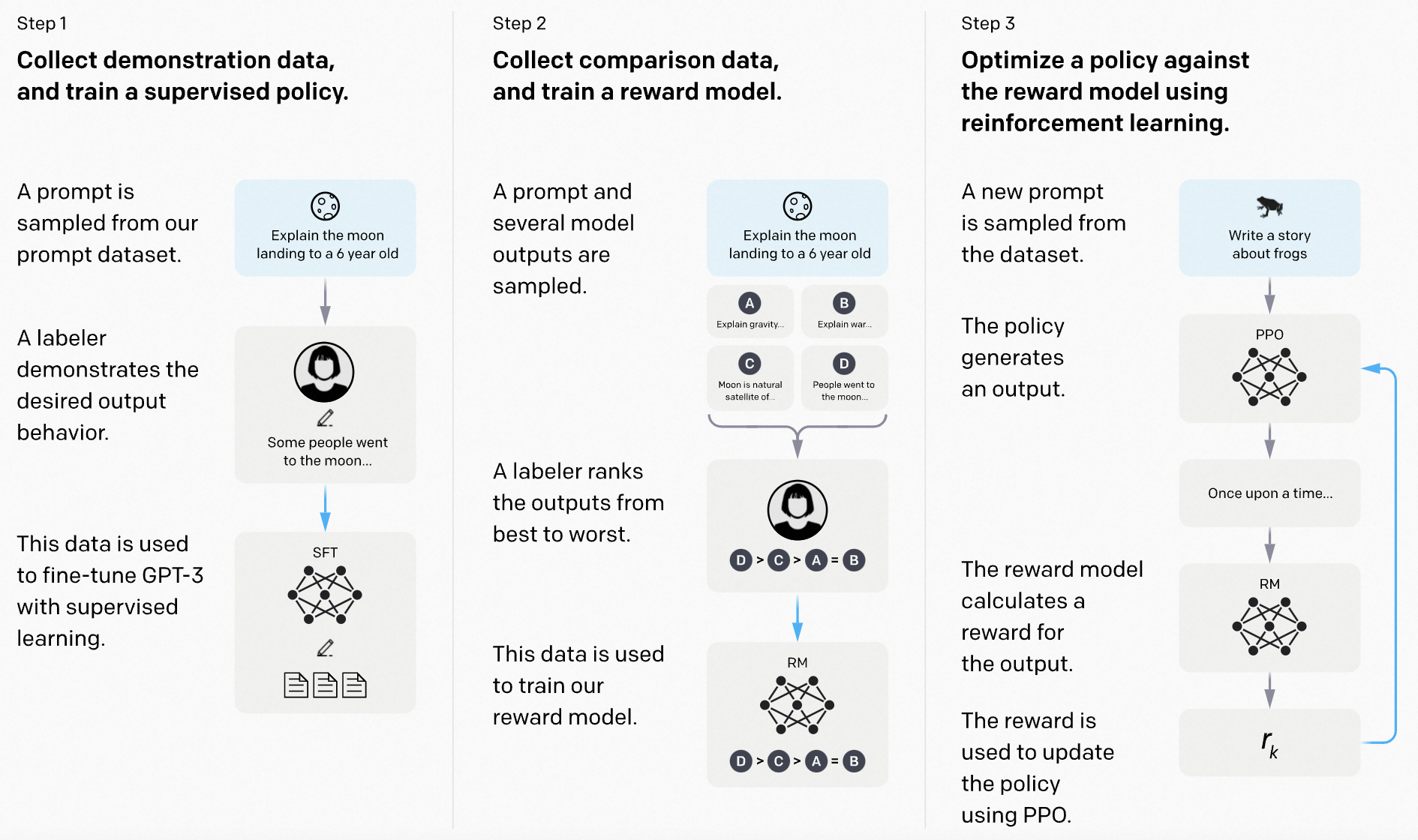
ChatGPT的训练过程可以分为三个阶段,如下图所示:
1)训练SFT(Supervised Fine-Tuning)模型
收集API产出或者人工标注的提示-答复对数据集,监督式微调GPT3,得到一个SFT模型。
2)训练RM(Reward Model)模型
在数据集中随机抽取一些提示,并使用STF模型产出多个答复,标注人员对答复的相关性进行排序,通过这种方式给模型的预测结果生成奖励来训练奖励模型,奖励模型类似于排序模型。
3)训练强化学习(PPO)模型
强化学习模型的训练数据全部来自于API产出的数据,也就是真实的用户生成的数据。使用RM模型作为奖励函数来继续微调SFT模型(策略函数),得到PPO模型。