图像经典模型(二)
一、概述
本文主要聚焦在一些经典的轻量化模型上,从模型结构上实现模型的压缩和加速。
二、经典论文
论文:SqueezeNet(SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE)
SqueezeNet算是比较早的轻量化模型,模型设计思路也比较简单。在和AlexNet比较时,精度保证不变的情况下,模型参数量减少了50倍。SqueezeNet的核心是使用1x1的卷积对输入通道降维,从而减少接下来的3x3卷积的参数量。再者使用卷积层替换了最后的全连接层。
SqueezeNet中提出了Fire模块,使用1x1的卷积压缩通道,使用1x1和3x3的卷积放大通道。假定给定input channel,output channel,squeeze channel。如下图所示,首先使用1x1的卷积将input channel压缩到squeeze channel,然后同时使用1x1和3x3的卷积方法到output channel / 2,最后拼接到一块。
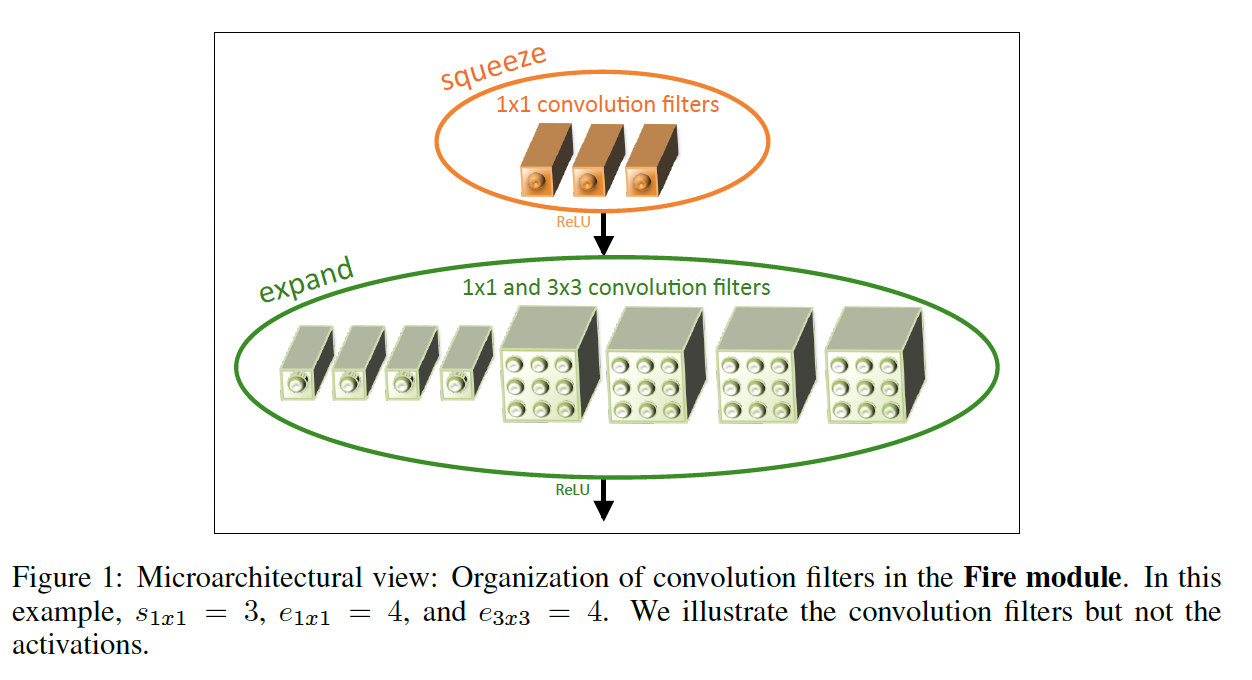
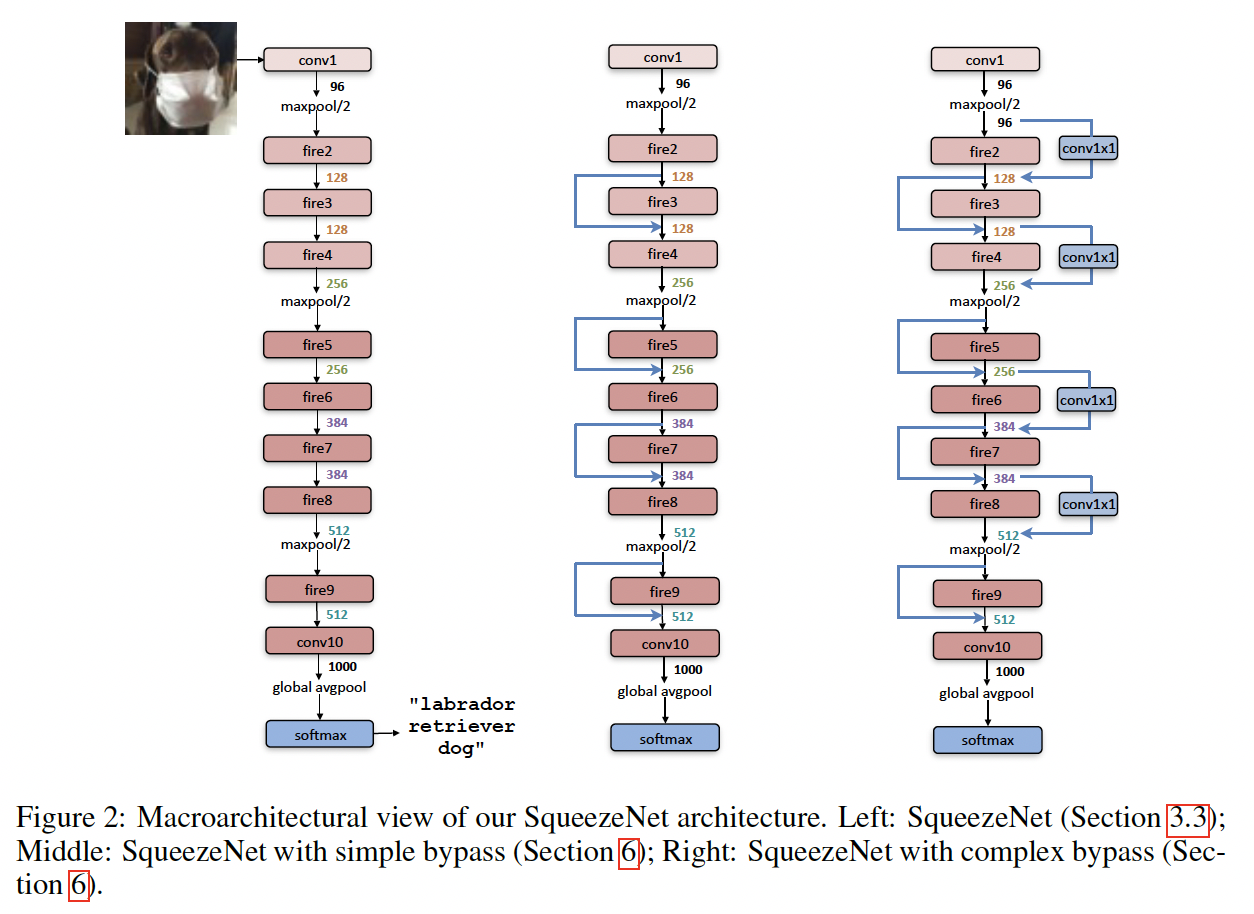
SqueezeNet中使用Fire模块作为基础模块,堆叠Fire模块,并且延后使用最大池化,以保证浅层卷积能看到更大的feature map。整体模型结构图如下:
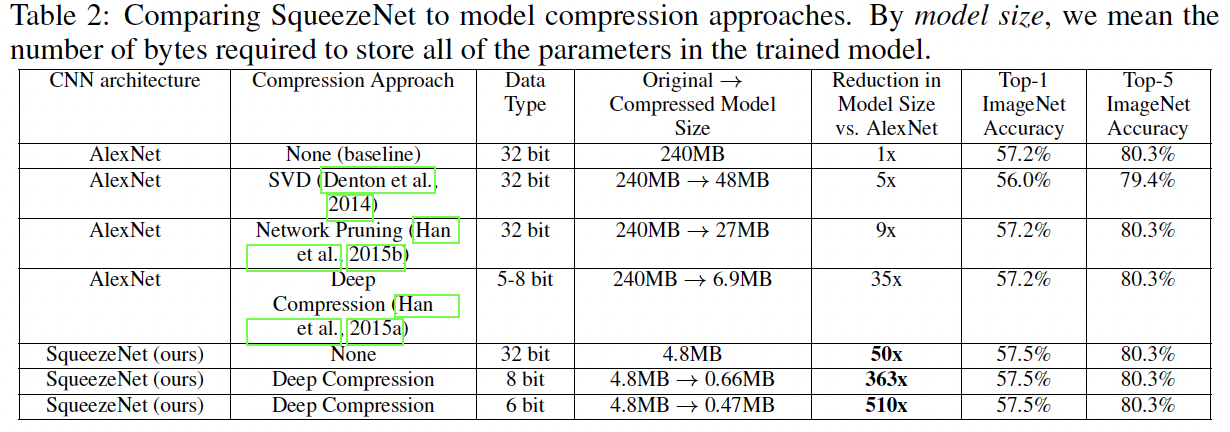
和AlexNet对比,整体效果如下,精度保持不变的情况下,模型参数大大地减少了。
论文:MobileNet(MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications)
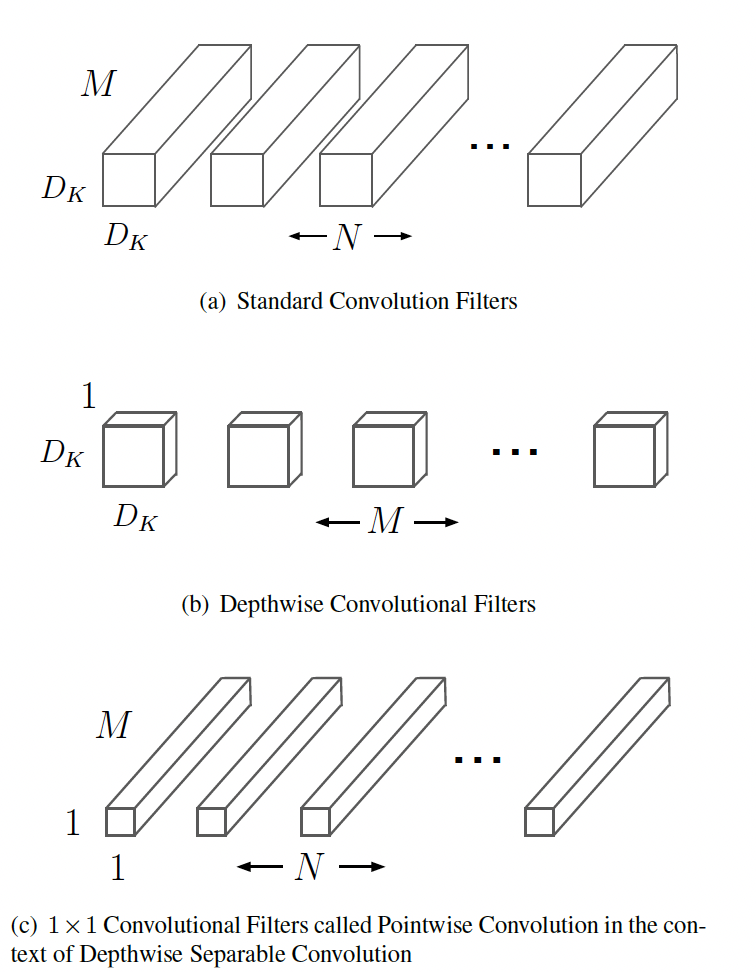
MobileNet是Google提出的轻量化网络,MobileNet中最核心的是深度可分离卷积(Depthwise separate convolutions),也是MobileNet中的基础单元,深度可分离卷积在Xception中也被用到,它将基础的卷积操作分解为depthwise 和 pointwise两个步骤来实现。
对于一个($D_F$ x $D_F$)的feature map,输入通道为M,输出通道为N,卷积核大小为($D_K$ x $D_K$),传统的做法是使用N个(M x $D_K$ x $D_K$)的卷积操作,depthwise是针对不同的通道使用不同的卷积核,具体做法是使用M个(1 x $D_K$ x $D_K$)的卷积对每个通道单独操作,但这样的做法会导致通道之间没有信息交互,为了解决这个问题,在depthwise后面又接了一个point wise的模块,point wise使用N个(M x 1 x 1)的卷积操作。具体的结构示意图如下:
从整体操作上来看depth wise 和 point wise和基础的卷积差不多,但从计算量上来看减少了很多。基础卷积的计算量为($D_K$ * $D_K$ * M * N * $D_F$ * $D_F$)。而深度可分离卷积的计算量为($D_K$ * $D_K$ * M * $D_F$ * $D_F$ + M * N * $D_F$ * $D_F$)。当N 比较大时,计算量约为基础卷积的 1 / $D_K$ ** 2。
MobileNet和基础卷积的对比如下:

模型和VGGNet,SqueezeNet的对比如下:
论文:MobileNetV2(MobileNetV2: Inverted Residuals and Linear Bottlenecks)
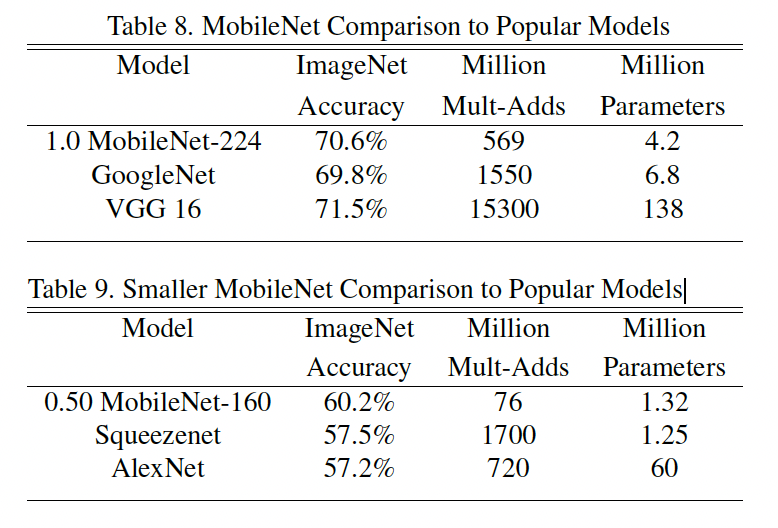
MobileNetV2是在MobileNet的基础上提出的,在MobileNet上作者发现有个问题,depthwise部分的kernel比较容易训废掉,核心原因是depthwise中kernel dim比较小,经过relu激活容易使得神经元输出变成0,所以直接使用线性变换取代Relu。此外深度卷积不会改变通道,如果来的通道很少的话,最后进入到relu时的输入维度也很低,所以在进入卷积前作者使用1x1 的卷积来扩张通道。基于此作者提出了深度可分离卷积的改进版 Linear Bottlenecks。
Linear Bottlenecks 先使用1x1 的卷积扩大通道数,然后再接一层3x3 的depth wise,最后接1x1 的point wise,但是在point wise后是去掉了relu函数。模块结构如下:
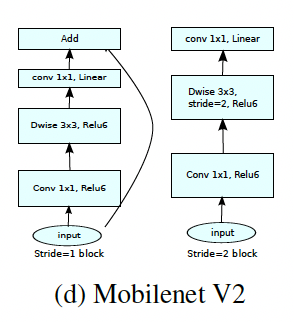
在MobileNetV2中引入了残差连接,Linear Bottleneck相当于resnet 中的残差块,不同的是resnet 中的残差块是先降通道后升通道,而这里是先升通道后降通道。所以在MobileNetV2中被称为Inverted residuals。
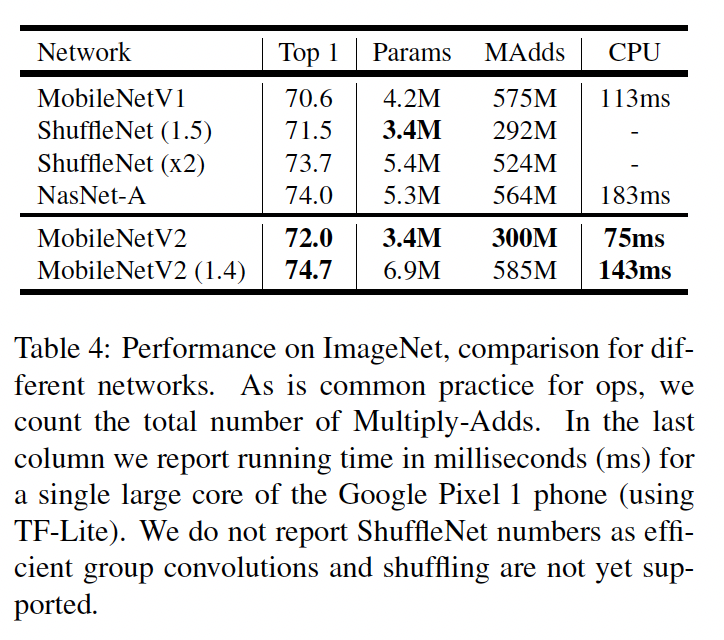
和MobileNet,ShuffleNet的对比如下:
论文:ShuffleNet(ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices)
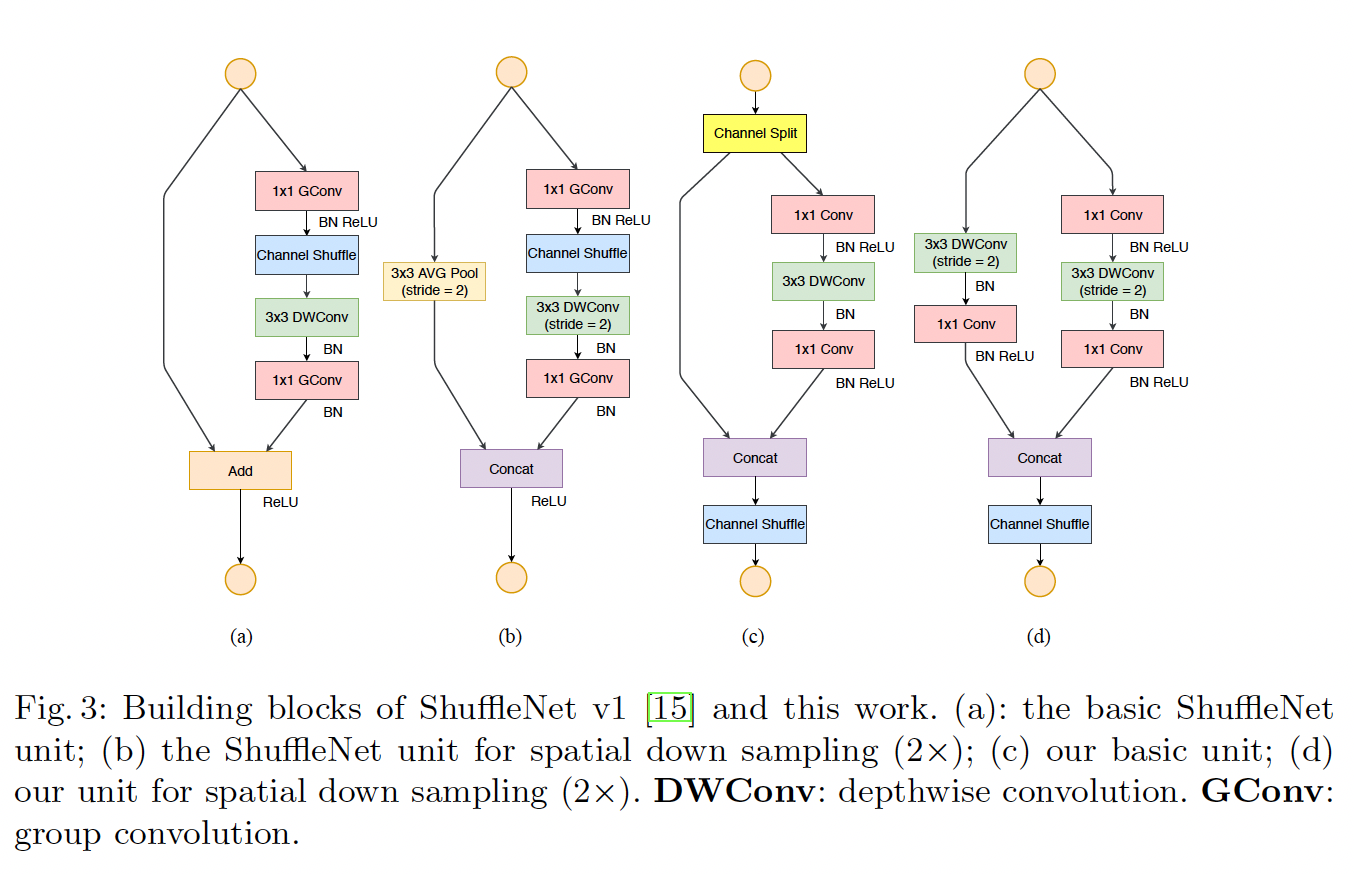
ShuffleNet中引入了组卷积(MobileNet中的depth wise是一种组数等于输入通道数的特殊组卷积)作为构建基本单元的卷积块,组卷积是将输入通道分组,组内的通道之间会交互,而组间之间的通道是不交互的。在MobileNet中是使用point wise来使得所有的通道之间产生交互,但point wise本身是密集连接,占据网络中大部分计算量。因此在这里作者使用channel shuffle来实现通道之间的交互,shuffle时是均匀打乱的,确保所有的通道都能发生交互行为。具体如下图所示:
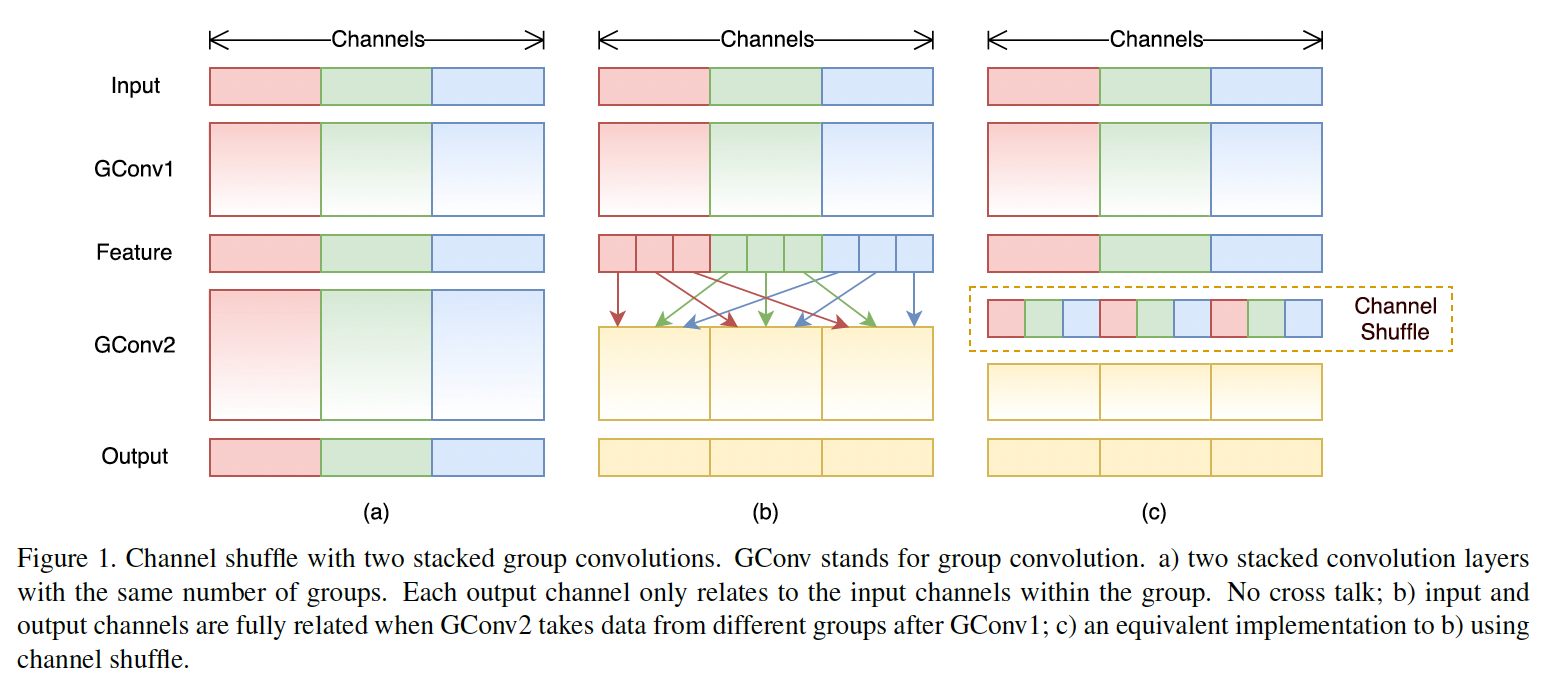
ShuffleNet中的基本单元是在残差单元上改造的,不同的是第一层使用1x1 的组卷积降维后接channel shuffle,第二层使用3x3 的组卷积,最后一层使用1x1 的组卷积升维,具体结构图如下:
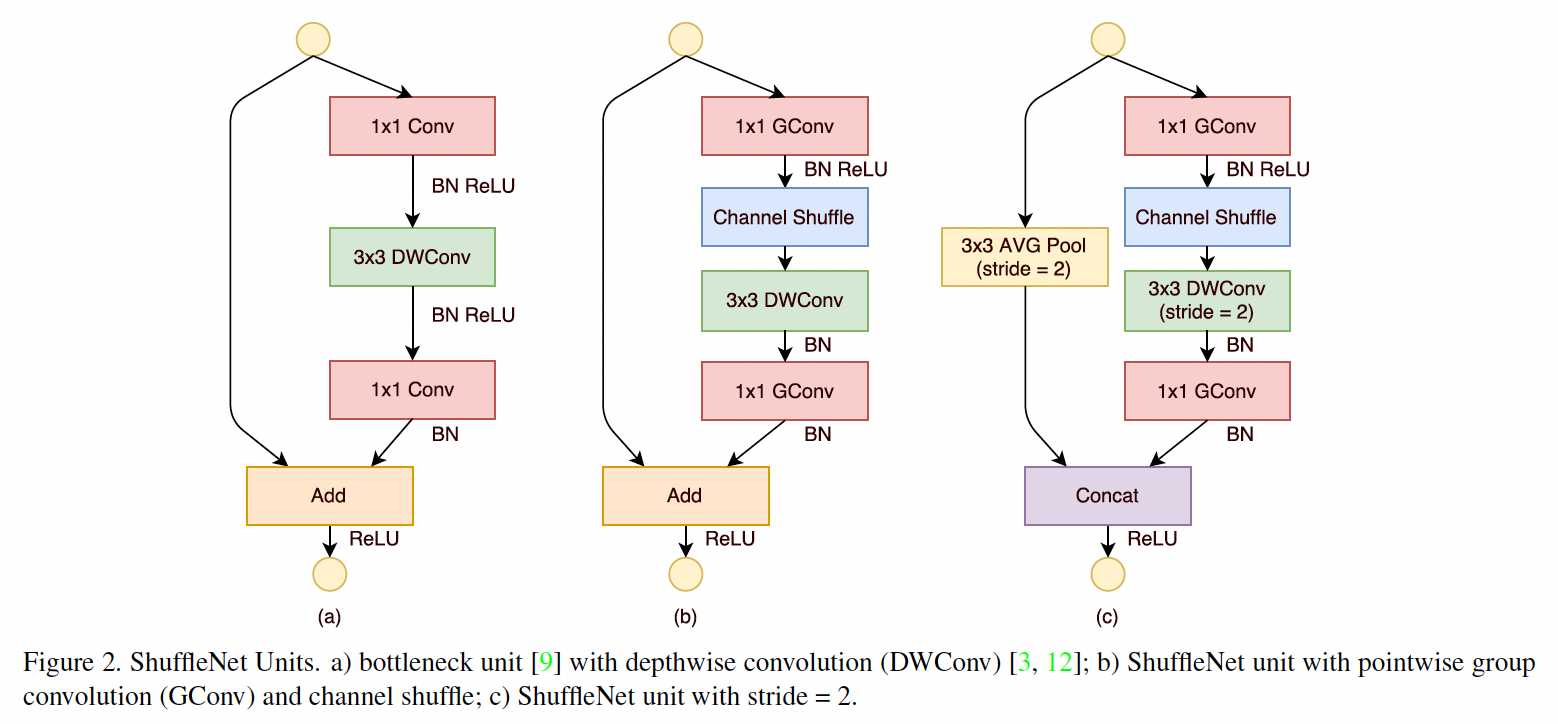
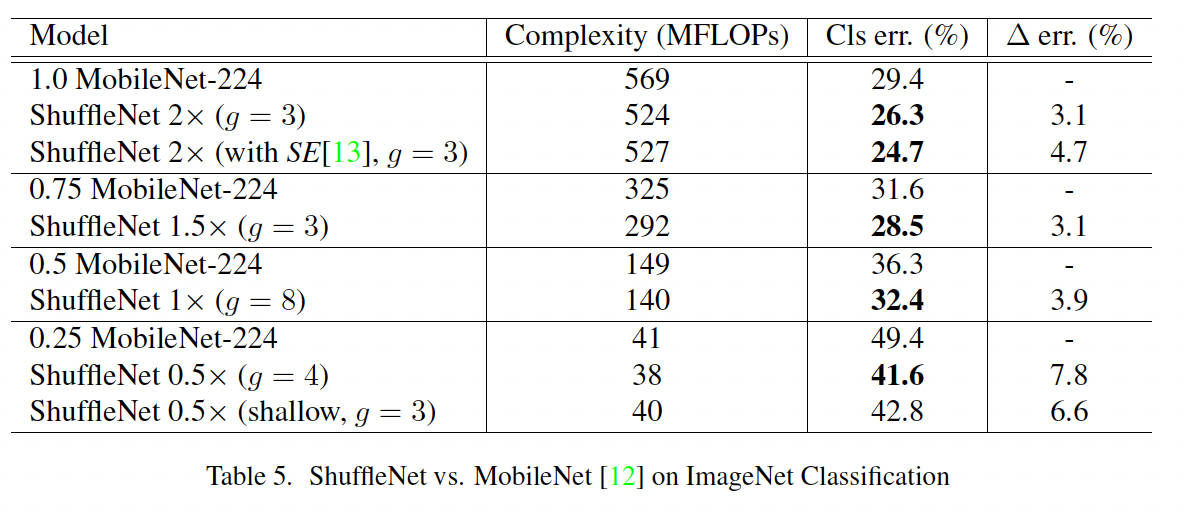
值得注意的是图c中在下采样层,使用平均池化来改变输入的feature map的尺寸,并且将残差连接中的加和改成了拼接。看下ShuffleNet和MobileNet的实验对比:
论文:ShuffleNetV2(ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design)
目前通常用FLOPs(浮点运算数)来作为衡量模型复杂度的指标,但这却是个间接指标,并不能直接等价于模型的速度。模型的速度还受内存读写速度的影响,此外模型的并行度也会影响模型的速度,不同的平台,不同的加速库等同样都会导致相同的FLOPs的模型有着不一样的速度。基于此作者通过理论和实验总结出4条网络设计指南:
G1)同等通道大小能最小化内存访问成本
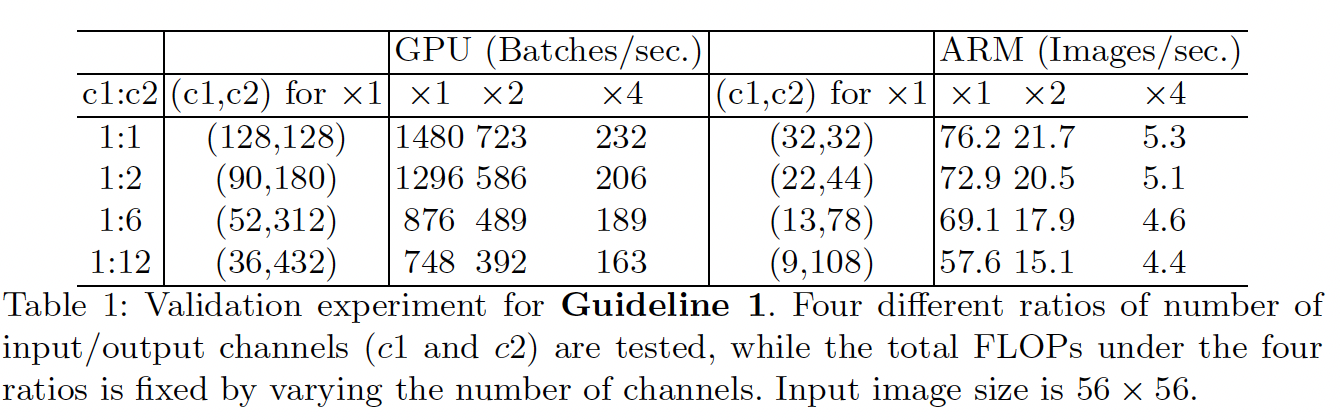
G2)过量使用组卷积会增大内存访问成本
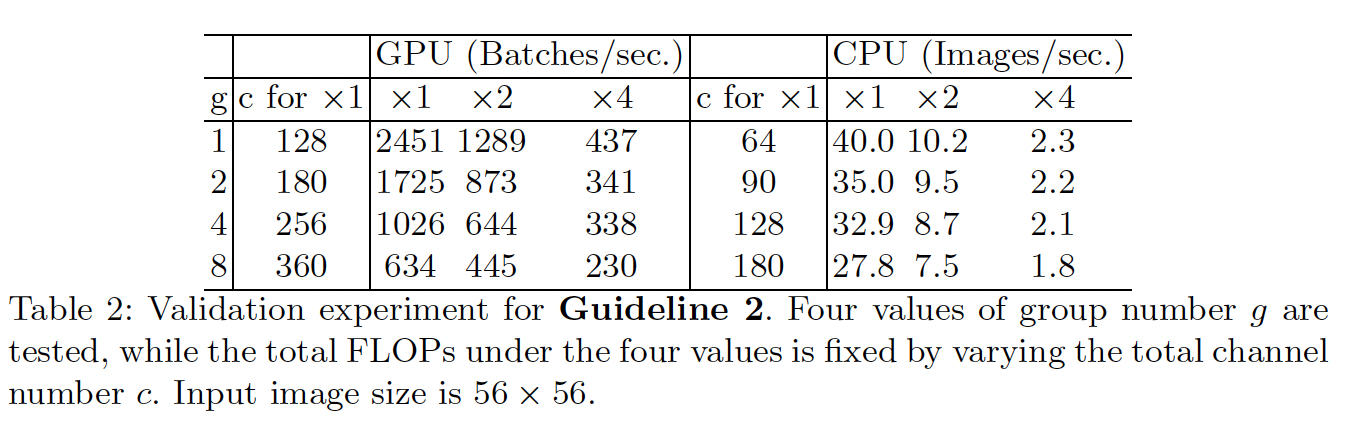 G3)网络碎片化会降低并行度
G3)网络碎片化会降低并行度
如Inception结构或者一些Nas生成的网络中的“多路并行”结构就会降低网络的并行度
G4)元素级操作不可忽略
如网络中的ReLu,AddTensor,AddBias等操作,虽然FLOPs很低,但是内存访问成本会很高。
基于以上4点,作者首先分析了ShuffleNetV1,大量使用了1x1 组卷积违背了G2,采用了类似ResNet中的瓶颈层(bottleneck layer),导致输入和输出通道数不同,违背了G1。同时使用过多的组,违背了G3。残差连接中大量的元素级Add运算,违背了G4。
为了解决上述的问题,作者引入了channel split操作,在输入时将通道split成两部分,通常是对半分,一半做同等映射,另一半经过1x1,3x3,1x1三层卷积,在这里1x1 不使用组卷积,并且输入的通道和输入的通道保持一致,最后的残差连接也不使用求和,而是直接拼接,具体的网络结构如下图:
性能对比如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号