Design Challenges and Misconceptions in Neural Sequence Labeling 论文阅读
1,简介
序列标注算是NLP中最基本的任务,主要有分词,词性标注,实体识别三类任务。分词通常是中文任务的模型最基本的组件,词性标注通常也是用来辅助其他的任务,用于提升任务的性能,而实体识别算是可以直接应用的任务。NLP发展到今天,预训练模型通常能取得较其他模型更优的效果,然预训练模型体量庞大,在直接任务中使用需要压缩,所以预训练模型之前的深度学习方法依然在实际应用场景中占有不小的地位。本文就是针对预训练模型之前的深度学习模型在序列标注任务上的总结。
2,论文解读
本文属于综述性论文,而且是比较全面的实验性综述论文,论文中的模型都是之前被提出来的,作者将这些模型划为12类,实验对比了在分词,词性标注,实体识别三类任务上的性能。12类模型描述如下:

模型基本由三层组成,字符嵌入层(外加词嵌入层),词编码层,推断层。如上面表格所示,行分为无字符嵌入,lstm的字符嵌入,cnn的字符嵌入;列为lstm词编码,cnn词编码,以及是否使用crf解码。如下图所示:
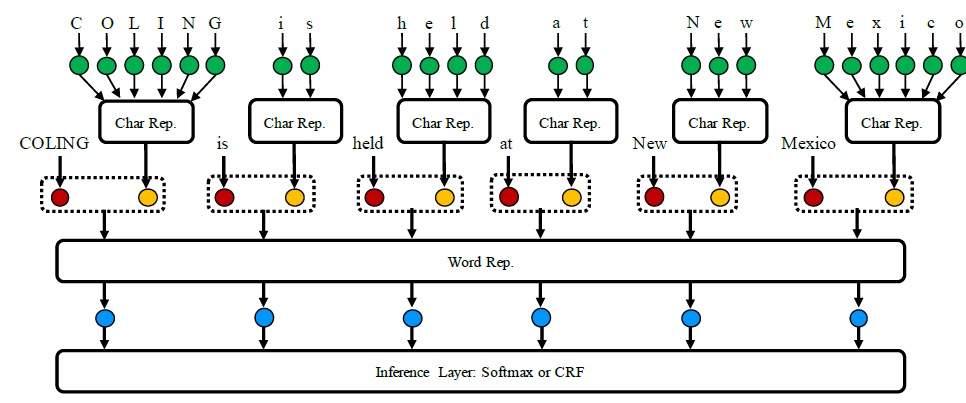
像这类结构适用于英文数据,中文数据并不适应,因为英文中有意义的最小是单个词,而中文是是分词的词,然分词本身就会引入错误信息,所以中文的序列标注都是基于字的,但是在实体识别任务中可以尝试使用词性标注或分词的信息来提升模型精度,算是引入一些人工特征。
实验数据和超参设计如下:


超参设计可以参考,如这里的学习速率,lstm和cnn的学习速率是不一样的,cnn如果使用较大的学习速率,收敛是会比较差的。
结果分析

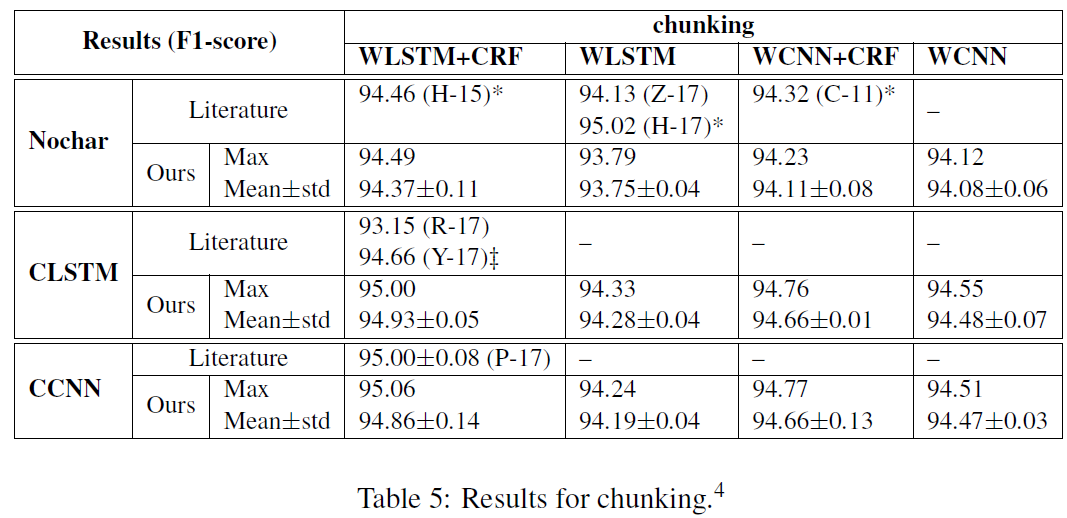

通过实验对比可以得到几个结论:
1)引入字符特征效果会提升不少,无论是用cnn,还是lstm嵌入字符,都有差不多的提升效果。
2)对词的编码使用lstm的效果要优于cnn,主要是lstm的长距离上下文信息的编码能力要优于cnn,cnn更擅长于捕获局部特征,而序列标注这类任务通常依赖于上下文信息。
3)crf解码器在分词和实体识别的效果上要优于softmax,但词性标注上两者没太大差别。
4)引入预训练好的词向量比随机的效果要好很多(这是必然,尤其是实验中的数据集并不大)
5)BIOES的标注效果要优于BIO,但差距不大,这种我觉得还是看自己的任务上的表现吧,有不少论文表明这两种没啥区别
6)优化器的影响,实验证明SGD的效果最好,而ADAM的效果最差,这种还是看自己的调参能力吧,SGD使用相对要难一些。

在实际的工业应用中,除了要考虑模型的精度,还需要考虑模型的大小,模型的推断速度,尤其是移动端的应用,对这两点要求极为苛刻。以上述作者给的12类模型中用到的组件,lstm是比cnn要耗时的,但cnn的参数量通常会多于lstm(因为cnn通常需要多层和多个kernel)。crf全局解码要比softmax耗时。作者对比了12类模型的推断速度。

从上面图中可以看到,引入crf速度要慢了一半,所以手机端上应用序列标注模型时可以考虑去掉crf层,字符嵌入可以使用cnn,至于词编码层看序列的长度考虑,lstm这种循环解码还是比较慢的,尤其是序列长度比较长的时候,所以可以考虑用cnn,如果想要尽可能的提取长距离的上下文特征,可以考虑多层膨胀卷积来处理这类问题,另外就是序列截断也算是一种解决序列过长而导致解码过慢的方法。总之推荐char-cnn + word-lstm + softmax,或char-cnn + word-cnn + softmax。标注尽量使用BIO,这样可以减少softmax的计算量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号