

如何建立DB2分区数据库?(转)
欢迎和大家交流技术相关问题:
邮箱: jiangxinnju@163.com
博客园地址: http://www.cnblogs.com/jiangxinnju
GitHub地址: https://github.com/jiangxincode
知乎地址: https://www.zhihu.com/people/jiangxinnju
原作:陈敏 2008-05-21
熟悉IBM DB2 UDB的都知道,构筑DB2数据库对象的层次关系,既每台物理机器可以配置多个实例,而每个实例是一个独立的运行环境,在每个实例下可以创建多个数据库,每个数据库可以有多个表空间,而数据库中的表会存放在这些表空间中。那分区数据库中他们的关系又如何,是如何分区的呢?本文就分区数据库的基本概念做简单介绍。
有了数据库分区后,在原来构筑DB2数据库对象的层次关系里发生了一些变化,实例增加了一个物理特性,就是实例所拥有的数据库分区,为了使使用者能够充分利用分区数据库的特性,在数据库和表空间之间增加了一层,——数据库分区组。与之相关的名词包括数据库分区,数据库分区组,分区映射,分区键,下面就详细解释一下:
数据库分区
首先说一下什么是数据库分区,数据库分区是DB2数据库的一部分,由它自己的数据、索引、配置文件和事务日志组成。分区数据库就是具有两个或多个分区的数据库。这样,表就可以位于一个或多个数据库分区中。与每个数据库分区相关联的处理器都用来满足表请求。数据检索和更新请求将自动分解为子请求,并在适当的数据库分区中并行执行。
数据库分区组
数据库分区组是一个或多个数据库分区的集合。想要为数据库创建表时,首先创建用来存储表空间的数据库分区组,然后创建用来存储表的表空间。
可以在数据库中定义一个或多个数据库分区组成的命名子集。您定义的每个子集称为 数据库分区组 。包含多个数据库分区的每个子集称为 多分区数据库分区组 。多分区数据库分区组只能使用属于相同实例的数据库分区定义。
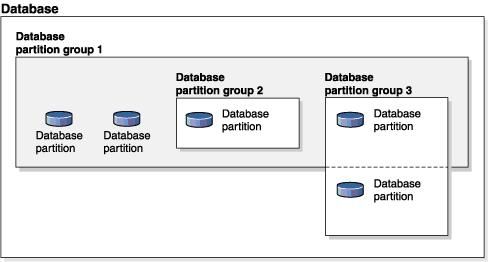
图 1 给出了一个含五个分区的数据库示例,在这个示例中:
- 数据库分区组横跨除一个数据库分区外的所有其它分区(数据库分区组 1)。
- 数据库分区组包含一个数据库分区(数据库分区组 2)。
- 数据库分区组包含两个数据库分区(数据库分区组 3)。
- 数据库分区组 2 中的数据库分区与数据库分区组 1 共享并与之相交。
- 数据库分区组 3 中存在单个数据库分区,该分区与数据库分区组 1 共享并与之相交。
可使用 CREATE DATABASE PARTITION GROUP 语句创建数据库分区组。此语句指定表空间容器和表数据将驻留其上的一组数据库分区。此语句还可以:
- 为数据库分区组创建分区映射。
- 生成分区映射标识。
- 将记录插入下列目录表:
- SYSCAT.DBPARTITIONGROUPS
- SYSCAT.PARTITIONMAPS
- SYSCAT.DBPARTITIONGROUPDEF
创建数据库时创建的缺省数据库分区组由数据库管理器使用。IBMCATGROUP 是包含系统目录的表空间的缺省数据库分区组,只在主节点上(主数据库分区)。IBMTEMPGROUP 是系统临时表空间的缺省数据库分区组,包含所有数据库分区。
IBMDEFAULTGROUP 是包含用户定义的表的表空间的缺省数据库分区组,包含所有数据库分区。
通过将表空间放置在多分区数据库分区组中,将该表空间内的所有表划分或分区到该数据库分区组的每个分区中。由此该表空间被创建到了一个数据库分区组中。一旦位于某个数据库分区组中,该表空间就必须保留在该处;而不能更改至另一数据库分区组。CREATE TABLESPACE 语句用于将表空间与数据库分区组关联。
建数据库分区组示例:
CREATE DATABASE PARTITION GROUP MAXGROUP ON ALL DBPARTITIONNUMS
CREATE DATABASE PARTITION GROUP MEDGROUP ON DBPARTITIONNUMS( 0 TO 2, 5, 8)
分区映射
在分区数据库环境中,数据库管理器必须具有弄清一个表的哪些行存储在哪些数据库分区上的方法。数据库管理器必须知道到哪里去查找所需的数据,并使用一个称为 分区映射 的映射来查找数据。
分区映射是一个内部生成的数组,对于多分区数据库分区组,它包含 4 096 个条目,对于单一分区数据库分区组,只包含一个条目。对于单一分区数据库分区组,分区映射只有一个条目,该条目包含存储数据库表的所有行的数据库分区的分区号。对于多分区数据库分区组,以循环方式指定数据库分区组的分区号。正如使用网格将城市地图划分为区一样,数据库管理器使用 分区键 来确定存储数据的位置(数据库分区)。
例如,假定您将一个数据库创建在四个数据库分区(编号为 0-3)上。此数据库的 IBMDEFAULTGROUP 数据库分区组的分区映射将是:
0 1 2 3 0 1 2 ...
若已使用数据库分区 1 和 2 在该数据库中创建了一个数据库分区组,则该数据库分区组的分区映射将是:
1 2 1 2 1 2 1 ...
若要装入数据库的一个表的分区键是一个可能在范围 1 至 500 000 之间的整数,则会将分区键散列至 0 至 4 095 之间的一个 分区号。将该编号用作分区映射中的索引,以选择用于该行的数据库分区。
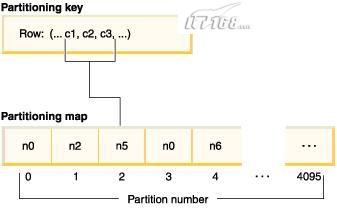
图 2 显示如何将具有分区键值 (c1, c2, c3) 的行映射至分区 2,然后引用数据库分区 n5。
分区映射可以灵活地控制将数据存储在分区数据库中的哪个位置。若将来需要更改数据库中各数据库分区上的数据分发,可以使用数据再分发实用程序。此实用程序允许重新平衡或调整数据分发的偏差。
分区键
分区键 是一列(或一组列),用于确定将某行数据存储在什么分区。分区键是使用 CREATE TABLE 语句在表上定义的。如果没有为分布在数据库分区组中的多个数据库分区中的表空间中的表定义分区键,在缺省情况下将会根据主键的第一列创建分区键。若未指定主键,则缺省分区键是在该表中定义的第一个非长型字段列。( 长型 包括所有长型数据类型和所有大对象(LOB)数据类型)。若没有列满足缺省分区键的要求,则不会不带键创建该表。
好的表分区键就是将数据均匀分布在数据库分区组中的所有数据库分区上的分区键。不适当的分区键会导致数据分发不均匀。数据分发不均匀的列和含有少数特异值的列不应选作分区键。特异值的数目必须足够大,才能确保将行均匀分布在数据库分区组中的所有数据库分区上。应用分区散列算法的成本与分区键的大小是成正比的。分区键不能超过 16 列,而且列越少,性能越好。不应将不需要的列包括在分区键中。
当定义分区键时,应该考虑下列几点:
- 不支持创建只包含长型数据类型(LONG VARCHAR、LONG VARGRAPHIC、BLOB、CLOB 或 DBCLOB)的多分区表。
- 不能改变分区键定义。
- 分区键应该包括最频繁连接的列。
- 分区键应该由经常参与 GROUP BY 子句的列组成。
- 任何唯一键或主键必须包含所有分区键列。
- 在联机事务处理(OLTP)环境中,分区键中的所有列都应该使用带常量或主机变量的等于(=)谓词来参与该事务。例如,假
定有一个在事务中经常使用的职员号 emp_no,如:
UPDATE emp_table SET ... WHERE
emp_no = host-variable
散列分区 是确定分区表中每一行的位置的方法。该方法的原理如下:
- 将散列算法应用于分区键的值,并生成介于 0 与 4095 之间的分区号。
- 创建数据库分区组时将创建分区映射。每个分区号依次以循环方式重复,以填写该分区映射。
- 该分区号用作分区映射中的一个索引。分区映射中该位置处的编号是存储该行的数据库分区的编号。
在分区数据库中跨越几个分区创建一个表在性能上有几个优点。与检索数据相关联的工作可分成几部分在各个数据库分区中进行。
必须小心地选择适当的分区键,因为 以后再也不能更改它 。再者,必须将任何唯一索引(因此也是唯一键或主键)定义为分区键的一个超集。即,若定义了分区键,则唯一键和主键必须包括所有与分区键相同的列(它们可能有多列)。
表的一个分区大小不能超过 64 GB 和可用的磁盘空间中较小的那一个。(假设表空间具有 4 KB 的页大小。)该表的最大大小可以是 64 GB(或可用磁盘空间)乘以数据库分区数之积。若该表空间的页大小为 8 KB,则该表最大的大小可以为 128 GB(或可用的磁盘空间)乘以数据库分区数之积。若该表空间的页大小为 16 KB,则该表的最大大小可为 256 GB(或可用的磁盘空间)乘以数据库分区数之积。若该表空间的页大小为 32 KB,则该表的最大大小可为 512 GB(或可用的磁盘空间)乘以数据库分区数之积。
以下是一个示例:
CREATE TABLE MIXREC (MIX_CNTL INTEGER NOT NULL,
MIX_DESC CHAR(20) NOT NULL,
MIX_CHR CHAR(9) NOT NULL,
MIX_INT INTEGER NOT NULL,
MIX_TMSTMP TIMESTAMP NOT NULL)
IN MIXTS12
PARTITIONING KEY (MIX_INT) USING HASHING
在上一个示例中,表空间是 MIXTS12,而分区键是 MIX_INT。若未显式指定分区键,则它是 MIX_CNTL。(若未指定主键且未定义分区键,则分区键是该列表中的第一个非长型字段的列。)
建立分区数据库
有了上述了解,就可以建一个分区数据库了,示例如下:
1) 了解分区定义
分区定义可以从节点配置文件(db2nodes.cfg)得到,其位于实例所有者的主目录中,它包含一些配置信息,告诉 DB2 有哪些服务器参与分区数据库环境的实例。分区数据库环境中的每个实例都有一个 db2nodes.cfg 文件。对于每个参与实例的服务器,db2nodes.cfg 文件必须包含一个条目。当创建实例时,会自动创建 db2nodes.cfg 文件并对拥有实例的服务器添加条目。这里我们假设有4个分区。
2) 创建数据库
create db dpfdb;
默认会创建3个分区组IBMCATGROUP(只在0号分区上)
IBMTEMPGROUP ,IBMDEFAULTGROUP(在所有分区上),如果用户没有创建其他分区组,所创建的表空间会默认放在IBMDEFAULTGROUP上
3) 创建分区组
我们在 1到3号分区建立一个分区组
CREATE DATABASE PARTITION GROUP USERGROUP ON DBPARTITIONNUMS(1,2,3);
4) 创建表空间
CREATE TABLESPACE TS IN USERGROUP MANAGED BY DATABASE USING (file '/DB2containers/TScontainer $N' 10000)
有4个containers被创建
/DB2containers/TScontainer0 - on DATABASE PARTITION 0
/DB2containers/TScontainer1 - on DATABASE PARTITION 1
/DB2containers/TScontainer2 - on DATABASE PARTITION 2
/DB2containers/TScontainer3 - on DATABASE PARTITION 3
5) 创建表
CREATE TABLE DPFTABLE (ID INTEGER NOT NULL,
NAME CHAR(20) NOT NULL)
IN TS
PARTITIONING KEY (ID) USING HASHING;
如果想了解如何配置分区数据库环境,请参考
http://www.ibm.com/developerworks/cn/aix/library/au-db2-dpf/index.html#N100A7

