

- full join 横向join ,不能map join 走shuffle
- row_number() over ( partition by 主键 order by $flag desc) rank ... where rank =1 ,走shufle
select
id,
order_datekey,
f_procurement_order,
from
(
select
id,
order_datekey,
f_procurement_order,
row_number() over (
partition by id
order by
b_flag_i desc
) rank
from
(
select
id,
order_datekey,
f_procurement_order,
0 b_flag_i
from
ods_pms_procurement_order_item_hm old
WHERE
c_t >= 1479916800
or u_t >= 1479916800
union all
select
id,
order_datekey,
f_procurement_order,
1 b_flag_i
from
ods_pms_procurement_order_item_hm_delta_64124FEADBFA9720 new
) t
) st
where
rank = 1;
- 差集 + 并集方式 效率最高 前提是增量数据较少,要不也要走shuffle
# semi_1 数据 id , name
1 jx
2 gj
# semi_2数据id, age
1 28
3 30
select a.id,a.name from semi_1 a left anti join semi_2 b on a.id = b.id;
left anti join 是以左表为主,如果join上就返回null,否则返回左表数据。
2 gj
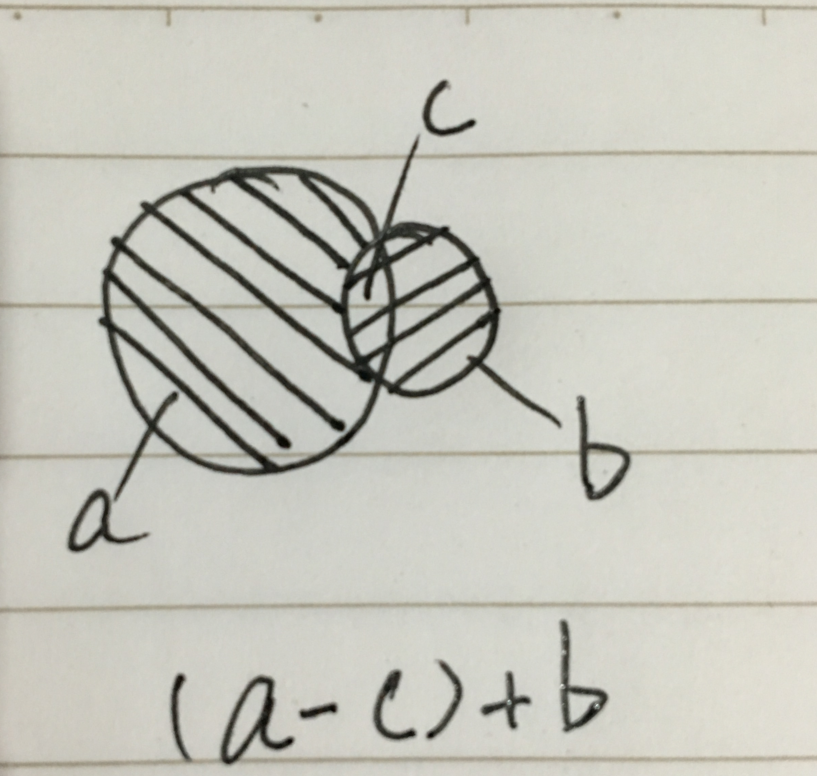
下图a代表完整old 全集,b代表完整new全集,c代表a与b join 上的交集部分(比如id相等的部分)所以思路就是(a-c)+b实现hive 的update
SET hive.mapred.mode=nonstrict;
INSERT overwrite TABLE $target.table
SELECT
$stream.format
FROM
$target.table old left anti
join ($delta) new on $stream.unique_keys
UNION ALL
SELECT
$stream.format
FROM
$target.table ;
fields = 'id,name'
new = 'new'
old = 'old'
and_str = ' AND '
cmd = []
for field in fields.split(','):
str = old + '.' + field + ' = ' + new + '.' + field
cmd.append(str)
print and_str.join(cmd)

