大规模网站开发技术
(一)单机构建网站
关于系统负载
什么是系统负载?
系统负载(System Load)是系统CPU繁忙程度的度量,即有多少进程在等待被CPU调度(进程等待队列的长度)。
平均负载(Load Average)是一段时间内系统的平均负载,这个一段时间一般取1分钟、5分钟、15分钟。
如何查看系统的负载情况?
top、uptime、w等命令都可以查看系统负载。
(二)应用服务器与数据库分类
应用服务器需要处理大量的逻辑,所以需要强大的CPU;
文件服务器需要存储大量用户上传的文件,所以需要更大的硬盘;
数据库服务器需要快速磁盘检索和数据缓存,所以需要更大的内存和更快的硬盘
(三)应用服务器集群
负载均衡
什么是负载均衡?
负载均衡(Load Balance)是分布系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
负载均衡的工作方式
1. http重定向
当http代理(比如浏览器)向web服务器请求某个Url后,web服务器可通过Http响应头信息中的Location标记来返回一个新的URL。这意味着HTTP代理需要继续请求这个新的URL,完成自动跳转。
缺点:吞吐率限制
优点:不需要任何额外支持
适用场景:我们需要权衡转移请求的开销和处理实际请求的开销,前者相对于后者越小,那么重定向的意义就越大,例如下载,你可以去很多镜像下载网站,会发现基本下载都使用了Location做了重定向
2. DNS负载均衡
DNS负责提供域名解析服务,当访问某个站点的时候,实际上首先需要通过该站点域名的DNS服务器来获取域名指向的IP地址,这一个过程中,DNS服务器完成了域名到P地址的映射,同样,这样映射也可以是一对多的,这时候,DNS服务器便充当了负载均衡调度器。
使用命令:dig google.cn 查看DNS的配置
DNS服务器可以在所有可用的A记录中寻找离用户最近的一台服务器。
缺点:DNS记录缓存更新不及时、策略的局限性、不能做健康检查。
优点:可以寻找最近的服务器,加快请求速度。
适用场景:一般我们在多机房部署的时候,可以使用。
3.反向代理负载均衡
在用户请求到达反向代理服务器的时候(已经到达网站机房),由反向代理服务器根据算法转发到具体的服务器。常用的apache、nginx都可以充当反向代理服务器。反向代理的调度器扮演的是用户和实际服务器中间人的角色。
工作在HTTP层(第7层)
缺点:代理服务器成为性能的瓶颈,特别是一次上传大文件。
优点:配置简单,策略丰富、维持用户会话,可根据访问路径做转发。
适用场景:请求量不高的,简单负载均衡。后端开销大的应用。
4.IP负载均衡
工作在传输层(第4层)
通过操作系统内修改发过来的IP数据包,将数据包的目标地址修改为内部实际服务器地址,从而实现请求的转发,做到负载均衡。lvs的nat模式。
缺点:所有数据进出还是要过负载均衡的服务器,网络带宽成为瓶颈。
优点:内核完成转发,性能高。
适用场景:对性能要求高,但对带宽要求不高的应用。视频和下载等大带宽的应用,不适合。
5.数据链路层的负载均衡
工作在数据链路层(二层)
在请求到达负载均衡器后,通过配置所有集群机器的虚拟IP和负载均衡器相同,再通过修改请求的mac地址,从而做到请求的转发。与IP负载均衡不一样的是,当请求访问完服务器之后,直接返回客户。而无需再经过负载均衡器。LVS DR(Direct Routing)模式。
缺点:配置复杂
优点:由集群机器直接返回,提供了出口带宽。
适用场景:大型网站使用最广的一种负载均衡的方式。
负载均衡中如何维持用户的session会话?
1.把同一个用户在某个会话中的请求,都分配到固定的某一台服务器中,常见的负载均衡算法有ip_hash法。
2.session数据集中存储。session数据集中存储就是利用数据库或者缓存来存储session数据,实现了session和应用服务器的解耦。
3.使用cookie来代替session的使用。
负载均衡的常见策略
轮询(Round Robin):能力比较弱的服务器导致能力较弱的服务器最先超载
加权轮询(Weighted Round Robin):这种算法解决了简单轮询调度算法的缺点:传入的请求按顺序被分配到集群中的服务器,但是会考虑提前为每台服务器分配的权重
最少连接数(Least Connection):最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有块有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前连接数最小的一台服务器来处理当前的请求,尽可能地提高后端服务器的利用效率,将负责合理地分流到每一台服务器。
加权最少连接数(Weighted Least Connection):如果服务器的资源容量各不相同,那么“加权最少连接”方法更合适:在考虑连接数的同时也权衡管理员根据服务器情况定制的权重。
源ip_hash(source Ip Hash):这种方式通过生成请求源ip的哈希值,并通过这个哈希值来找到正确的真实服务器,这意味着对于同一主机来说他对应的服务器总是相同。
随机:通过系统随机算法,根据后端服务器的列表大小值来随机选取其中一台服务器进行访问,实际效果接近轮询的结果。
常见的负载均衡方案
硬件:常见的硬件有比较昂贵的NetScaler、F5、Radware和Array等商用的负载均衡器。优点就是专业的维护团队维护、性能高。缺点就是昂贵,所以对于规模较小的网络服务来说暂时还没有需要使用。
软件:nginx、Haproxy、LVS等
| 负载均衡技术 | 优点 | 缺点 | 并发数 |
| LVS | 抗负载能力强、配置性比较低、工作稳定、应用范围广 | 不支持7层转发,配置较为繁琐 | 十多万的并发 |
| Haproxy | 4层和7层都支持,配置简单,有监控界面 | 性能没有LVS高 | 可以支持5到10万的并发 |
| Nginx | 只支持7层转发、配置简单、epoll模型能挡高并发 | 主要支持http和email应用范围小 | 1万次 |
| F5 BIG-IP | 性能非常强大,功能非常强大 | 需要专业维护人员,售价几十万,比较贵 | 几百万并发 |
LVS这么牛逼能不能只用它就够了?
不可以,假如现在每天并发数在1000W,应该怎么设计这个架构呢?
答案:域名一个,对应多个IP服务器(不同地区都是独立且相同的负载均衡器及服务器集群),通过DNS解析到用户临近的服务器。当DNS解析到某个负载均衡器后,受理业务。比如,现在一个负载均衡器可以并发10W,那么DNS可以映射10个,那么最大并发量就是100W。
(四)数据库读写分离化,扩展数据库读操作
随着访问量的提高,数据库的负载也在慢慢增大。大部分互联网的业务都是“读多写少”的场景,数据库层面,读性能往往成为瓶颈。业界通常采用“一主多从,读写分离,冗余多个读库”的数据库架构来提升数据库的读性能。
问题:
主从数据库之间数据同步怎么实现?
根据负载量,如何计算需要扩展的从库数量?
同步的延迟如何保证读数据的准确?
MYSQL复制原理
1.master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
2.slave将master的binary log events拷贝到它的中继日志(relay log);
3.slave重做中继日志中的事件,将改变反映它自己的数据。
负载容量的规划
例如:假设工作负载为20%的写以及80%的读。为了计算简单,假设有一些前提:
读和写查询包含同样的工作量。
所有的服务器都是等同的,每秒能进行1000次查询。
备库和主库有同样的性能特征。
可以把所有的读操作转移到备库。
如果当前有一个服务器能支持每秒1000次查询,那么应该增加多少备库才能处理当前两倍的负载,并将所有的读查询分配给备库?
解:
两倍负载: 1000 * 2 = 2000
写负载: 2000 * 20% = 400
读负载: 2000 * 80% = 1600
每个从库的可以承受负载: 由于每个从库都需要从中继日志中同步400次,所以原本1000的负载,每个从库服务器变成 1000 - 400 = 600
从库数量: 1600 / 600 约等于 3,所以需要三台从库
DB主从架构一致性优化方法
半同步复制(同步)
1.系统对DB-master进行了一个写操作
2.写主库等主从同步完成,写主库的请求才返回
3.读从库,读到最新的数据(如果读请求先完成,写请求后完成,读取到的是“当时最新的”)
写操作的脚本读主库,可借助数据库代理实现(异步)
将统一脚本中的后续读操作都从主库读取。可以配置数据库代理自动实现。比如db_proxy等。
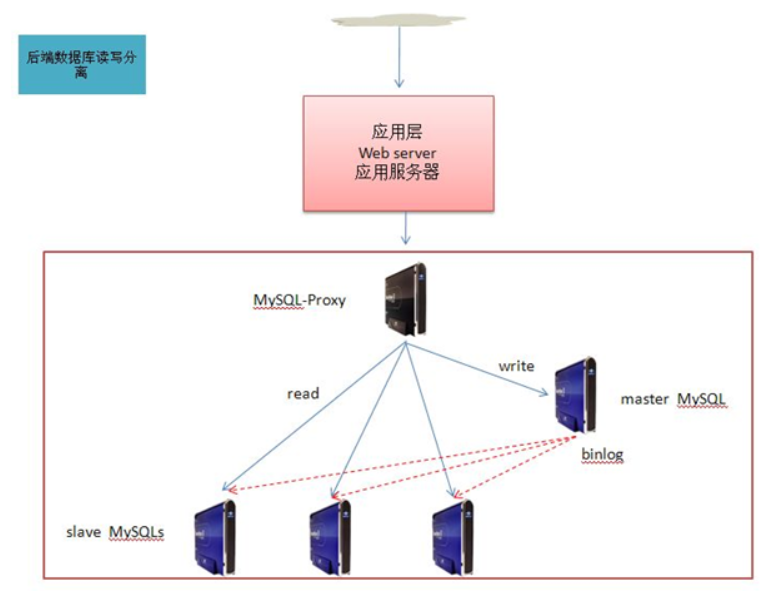
通过使用MySQL-Proxy来作为代理服务器,配置MySQL Proxy,将所有的写操作,分流到master MySQL上,所有的读操作分流到slave MySQLs。
缓存记录写key法
1.将某个库上的某个key要发生写操作,记录在cache里,并设置“经验主从同步时间”的cache超时时间,例如500ms
2.修改数据库
3.读库时先到cache里面查看,对应库的对应key有没有相关数据,如果cache hit,有相关数据,说明这个Key上刚发生过写操作,此时需要将请求路由到主库读最新的数据
4.如果cache miss,说明这个key上近期发生过写操作,此时将请求路由到从库,继续读写分离。
(五)数据库水平拆分与垂直拆分,扩展数据库的写操作
我们的网站演进到现在,交易、商品、用户的数据都还在同一个数据库。尽管采取了增加缓存,读写分离的方式。但随着数据库的压力继续增加,数据库的写瓶颈越来越突出,此时,我们可以有数据垂直拆分和水平拆分两种选择。
问题:
1.什么是垂直和水平拆分?
2.垂直拆分以后如何跨库join?
3.垂直拆分后,跨库事务(分布式事务)的问题,应该如何解决
4.水平切分以后非patition key上的查询可能就需要扫描多个表了,我们应如何优化?
垂直和水平拆分
拆分的方式分两种:
垂直拆分:按功能或业务将原来一个表中内容拆分多个表,或者一个库拆分成多个库。例如:对于数据库而言,在一个大的db库里面,有论坛数据,新闻数据,用户中心数据,那么就需要将它们拆分成不同db。对于数据表而言,可以做冷热表拆分,避免频繁查询的表中有text字段。
水平拆分:将同类型的数据分别存放与相同结构的多个表中。例如:如果要将用户表拆分8个表,那么id的计算可以使用取模的方式,这里就是user_id % 8 = 0、1、2、3、4、5、6、7,这里的0~7就是将数据存放的哪一个表中。一个好的分表键通常是数据库中非常重要的核心实体主键。比如用户ID。除开水平拆表,那还可以水平拆库,将某个表水平拆分多个子表,将每个子表分别放入不同的数据库中。
跨库join的问题
在拆分之前,系统中很多列表和详情页所需的数据是可以通过sql join来完成的。而拆分后,数据库可能是分布式在不同实例和不同的主机上,join变得非常麻烦。
全局表:系统中所有模块都可能会依赖的一些表在各个库中都保存。
字段冗余:“订单表”中保存“卖家ID”的同时,将卖家的“Name”字段也冗余,这样查询订单详情的时候就不需要再去查询“卖家用户表”。当然更新卖家“Id”对应的卖家“Name”,这边也更新下。
数据同步:定时A库的tbl_a表和B库中tbl_b关联,可以定时将指定的表做主从同步。
如果join很复杂,数显需要考虑分库的设计是否合理,其次考虑使用hadoop或者spark来解决。
分布式事务的实现:二阶段提交
问题:支付宝转账1万块钱到余额宝如何确保事务?
1.支付宝扣除1万块
2.余额宝增加1万块
在同一个库中利用Mysql事务可以很简单解决,在分布式数据库中,可以参考二阶段提交解决。
两阶段提交协议(Two-phase Commit,2PC)经常被用来实现分布式事务。一般分为事务协调器TC和资源管理SI两种角色,这里的资源管理就是具体的数据库。
二阶段提交具体细节:
1.应用程序发起的一个开始请求到TC;
2.向所有的SI发起<prepare>消息。
TC给B的prepare消息是通知余额宝数据库相应账户增加1W
TC给A的prepare消息是通知支付宝数据库相应账户扣除1W
3.SI收到<prepare>消息后,执行具体本机事务,但不会进行commit,锁定资源等待提交,成功返回<yes>,失败返回<no>。
4.TC收集所有执行器返回的消息。
1)如果所有执行器都返回yes,那么给所有执行器发送commit消息,执行器收到commit后执行本地事务的commit操作
2)如果任意一个执行器返回no,那么给所有执行器发送rollback消息,执行器收到rollback消息后执行事务rollback操作
从上述流程中思考:
二阶段提交满足了CAP中的那两个?
二阶段提交的缺点有哪些?并发性差,不推荐
使用消息队列来避免分布式事务
我们也可以选择牺牲一致性(保证最终一致性)来获取高性能的可用性。
1.支付宝在扣款事务提交之前,向实时消息服务请求发送数据,实时消息服务只记录消息数据,而不真正发送,只有消息发送成功后才会提交事务
2.当支付宝扣款事务被提交之后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才正在发送该消息
3.当支付宝扣款事务提交失败回滚后,向实时消息服务取消发送。在得到取消发送指令后,该消息将不会被发送。
4.对于那些未确认的消息或者取消的消息,需要有一个消息状态确认系统定时去支付宝系统查看这个消息的状态并进行更新。为什么需要这一步骤,举个例子:假设在第2步支付宝扣款事务被成功提交后,系统挂了,此时消息状态并未被更新为“确认发送”,从而导致消息不能被发送。
这种实现方式的思路,其实是源于ebay,后来通过支付宝等公司的布道,在业内广泛使用。其基本的设计思想是将远程分布式事务拆分成一系列的本地事务。
非patition key的查询问题
场景:
例如订单表,业务上对买家和卖家都有订单查询需求:
Order(oid, info_detail)订单表
T(buyer_id,seller_id,oid)关联表
如果用buyer_id来分库,seller_id的查询就需要扫描多库。
如果用seller_id来分库,buyer_id的查询就需要扫描多库。
问:如何解决?
答:没有解决方案,一般采用冗余表的方式解决。都用,即用卖家ID来拆分,也用买家ID来拆分,把两种拆分冗余起来,需要用到卖家ID来查询或者买家ID来查询都比较快捷。
(六)应用的拆分与服务化
随着业务的发展,应用越来越大。我们需要考虑如何避免让应用越来越臃肿。这就需要把应用拆分,从一个应用编程两个甚至更多。
我们把公共的服务拆分出来,形成一种服务化模式,简称SOA。
问题:
1.SOA的优点是什么?
2.SOA之间如何通信。
微服务架构
为什么要服务化(优点)?
1.防止代码到处拷贝,提高复用性。
2.减少系统的复杂度,管理方便。
服务化SOA的通信时通过RPC框架进行的。
所以RPC框架时服务化首要解决的问题。
RPC?
PRC(Remote Procedure Call Protocol),远程过程调用。
让调用方“像调用本地函数一样调用远程函数(服务)”。
1.首先A与B之间建立一个TCP连接
2.然后A把需要调用的方法名(这里时remoteAdd)以及方法参数(10,20)序列化成字节流发送出去。
3.B接受A发送过来的字节流,然后反序列化得到目标方法名,方法参数,接着执行相应的方法调用(可能是loacalAdd)并把结果30返回。
4.A接受远程调用结果
场景的PRC框架:Thrift、Hessian、Yar、...
(七)避免系统中的单点
要保证系统7X24小时不间断服务,必须考虑高可用,避免系统中的单点。
问题:
如何保证高可用?
keepalive
PHP高并发接口平台限流实现
算法:令牌桶算法
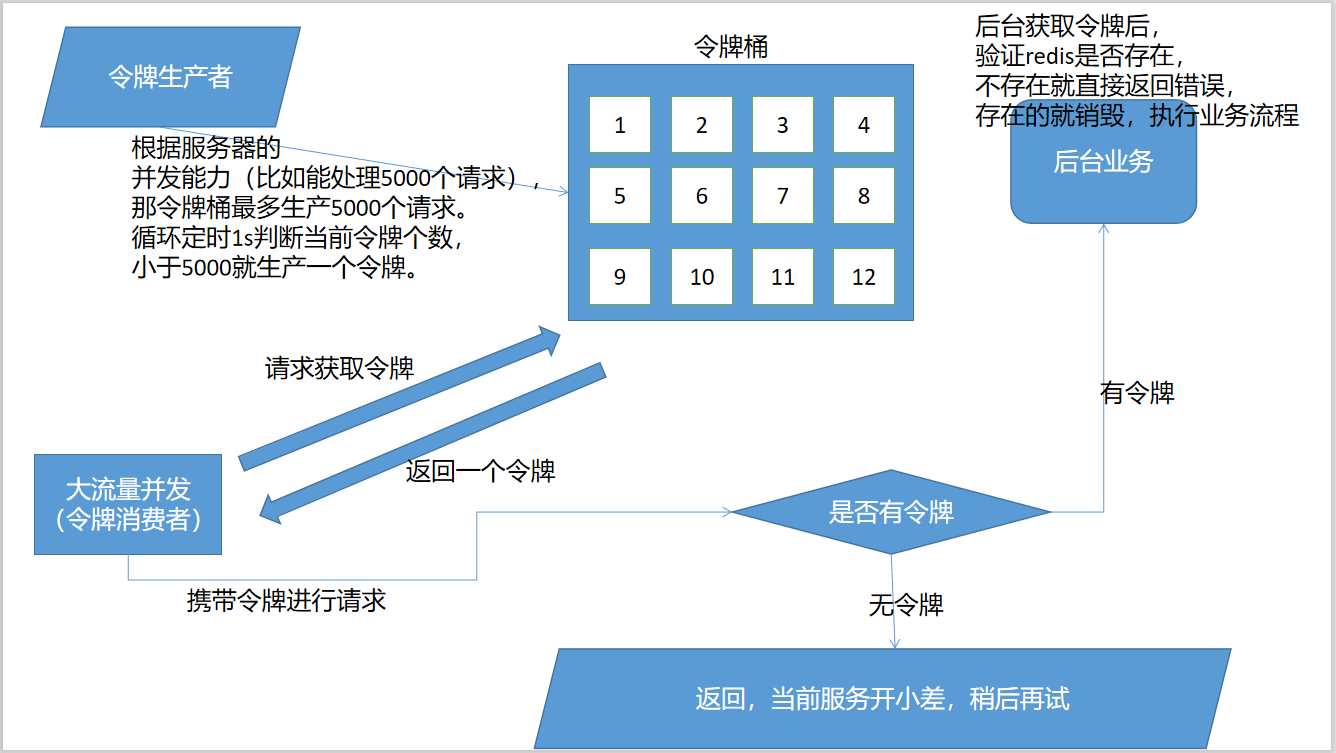
算法流程:
分成两个部分:
第一部分:定时产生令牌的业务编写
1. 可以使用一些压测工具,测试服务器的并发能力,比如QPS = 5000
2. 编写代码定时1秒或者500ms脚本产生相关的令牌桶,这里令牌桶的上限必须小于5000,比如4500
第二部分:请求
1.请求真实业务前,必须请求获取令牌桶的某个令牌key
2.成功获取令牌key后,携带令牌请求真实的业务服务
3.如果没有携带令牌或者令牌在令牌桶不存在,直接响应错误信息,拒绝本次请求,不处理当前业务流程。如果携带令牌并验证在令牌桶存在,那么先销毁令牌桶中的这个令牌,进行正常业务服务,并返回成功需要的数据。
具体实现...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号