10几行代码,用python打造实时截图识别OCR
你一定用过那种“OCR神器”,可以把图片中的文字提取出来,极大的提高工作效率。
今天,我们就来做一款实时截图识别的小工具。顾名思义,运行程序时,可以实时的把你截出来的图片中的文字识别出来。、

下次,当你想要复制“百度文库”中的内容时,不妨试试这个程序。
效果预览
源码解析
1)等待用户截图
此处需要借助贴图神器(Snipaste)
其中“f1”是截图的快捷键,“ctrl+c”是把截图保存到剪贴板的快捷键。
如果使用qq截图的话,需要把快捷键改为对应的“ctrl+alt+c”和“enter”
顺便安利一波Snipaste,
必备效率神器
importkeyboard
# 利用截图软件(Snipaste)截图到剪贴板
# 输入键盘的触发事件
keyboard.wait(hotkey="f1")
keyboard.wait(hotkey="ctrl+c")
time.sleep(0.1)
上面这段代码执行之后,现在已经有一张图片等待在剪贴板里了。
2)保存截图
windows安装PIL
打开cmd
进入python的安装目录中的Scripts目录:
输入pip install pillow
安装成功
利用PIL模块的ImageGrab,可以把剪贴板里的那张图片,保存到当前的目录下,并命名为“screen.png”
from PIL import ImageGrab
# 把图片从剪切板保存到当前路径
image = ImageGrab.grabclipboard()
image.save("screen.png")
3)识别截图中的文本
法一
pytesseract模块
优点:免费,易用
缺点:识别效果很一般,准确率不高
使用方法介绍:
1)pip install pytesseract
2)安装 tesseract-ocr.exe 配置环境变量
3)修改pytesseract.py文件,将tesseract_cmd指向Tesseract-OCR的tesseract.exe的绝对路径。
参考文章
见评论第一条
importpytesseract
fromPILimportImage
# 法一:利用pytesseract模块
# 参数一:图片
# 参数二:简体中文
text = pytesseract.image_to_string(Image.open("screen.png"), lang='chi_sim')
print(text)
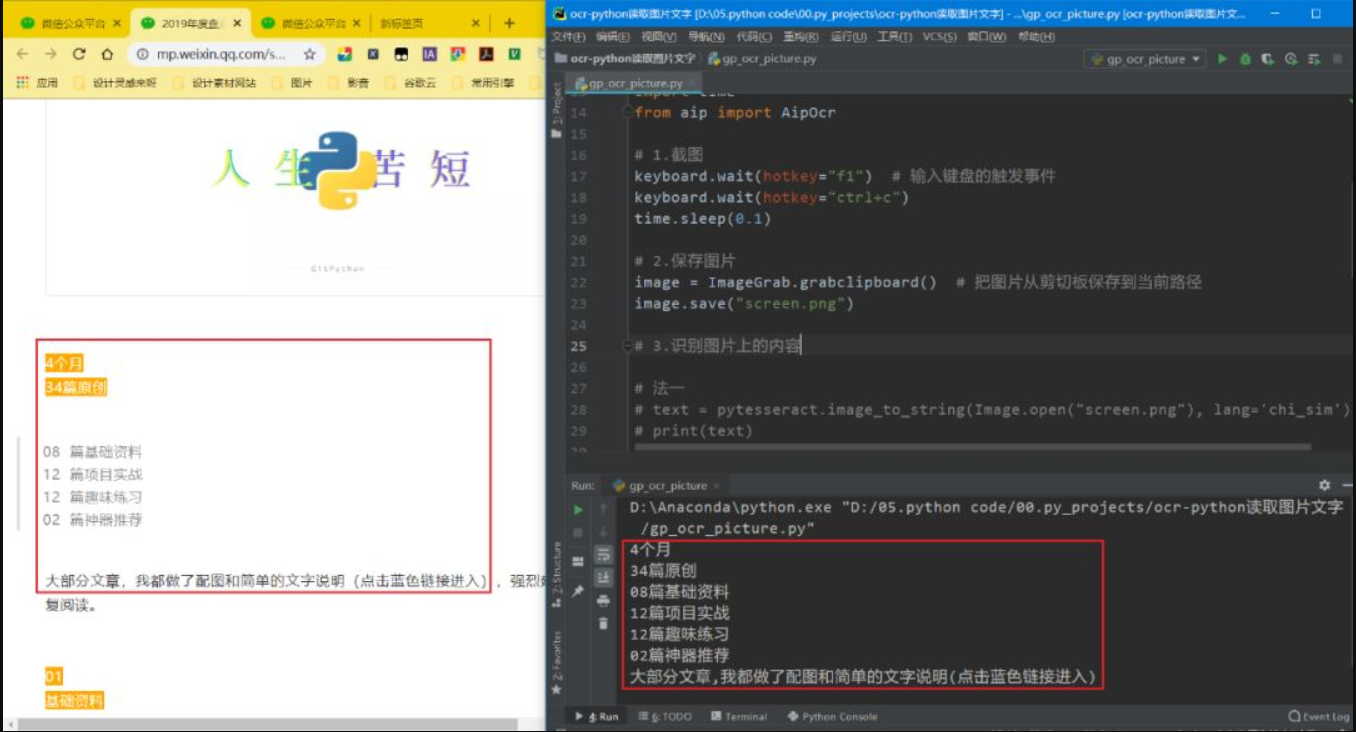
来看看效果:

low的不行
果然,要想精度高,还得用百度API
法二
百度API接口
AI开放平台文档中心
https://ai.baidu.com/ai-doc
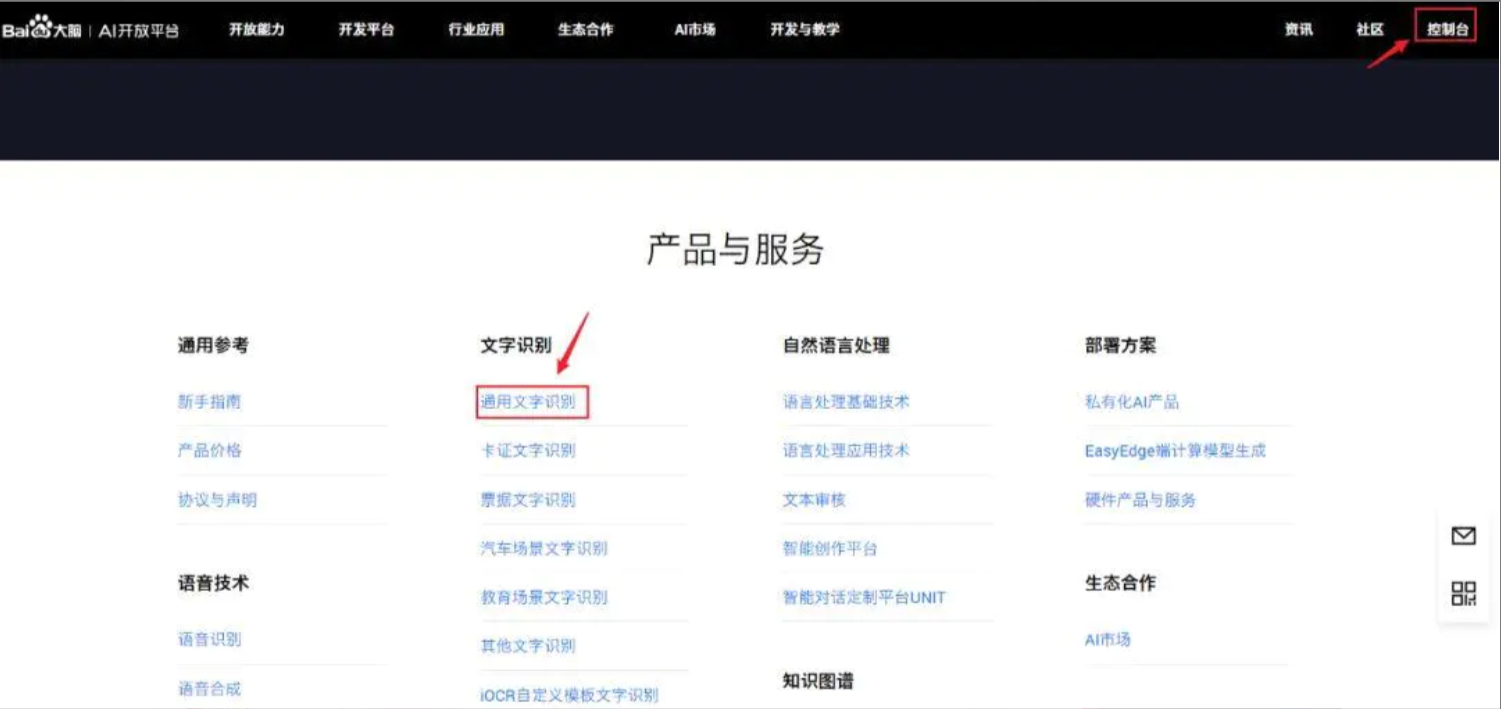
查看python语言的SDK文档
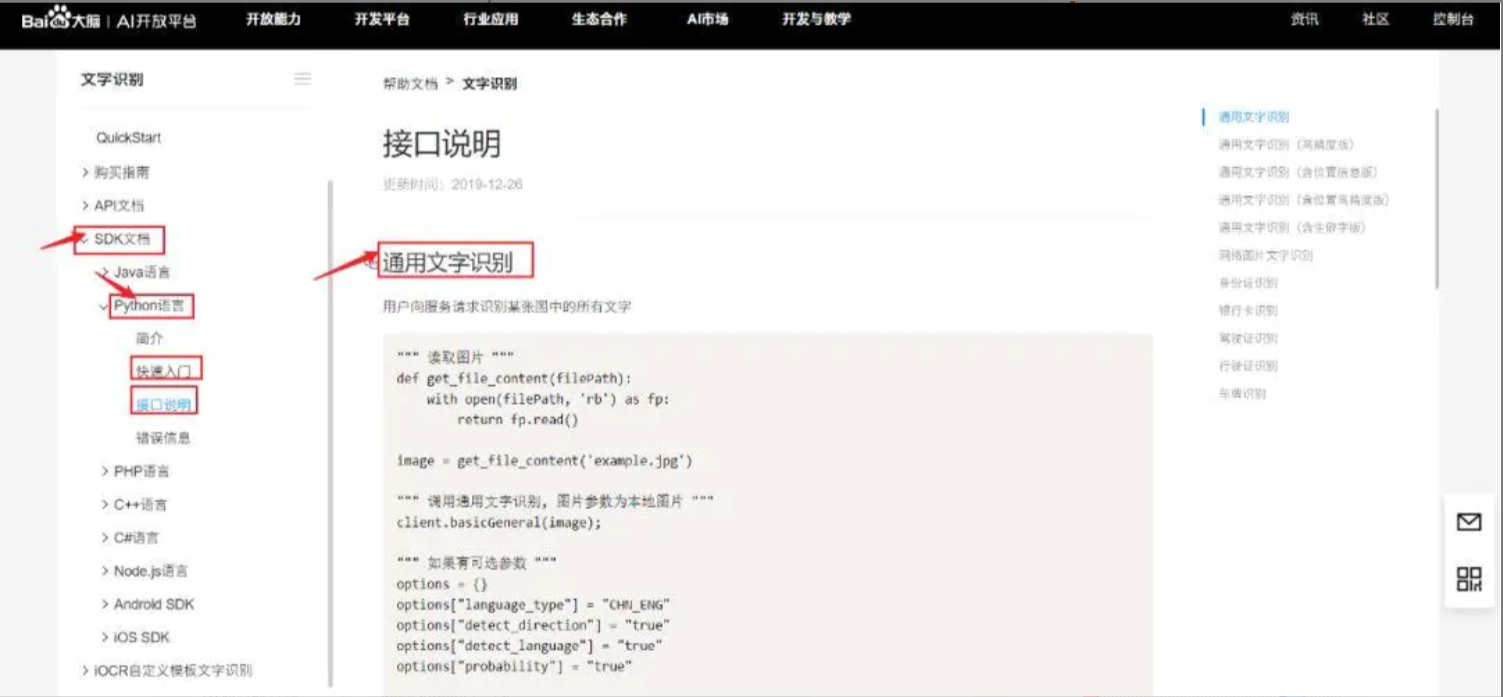
点击右上角(控制台),登录自己的百度账号,创建“文字识别”的应用
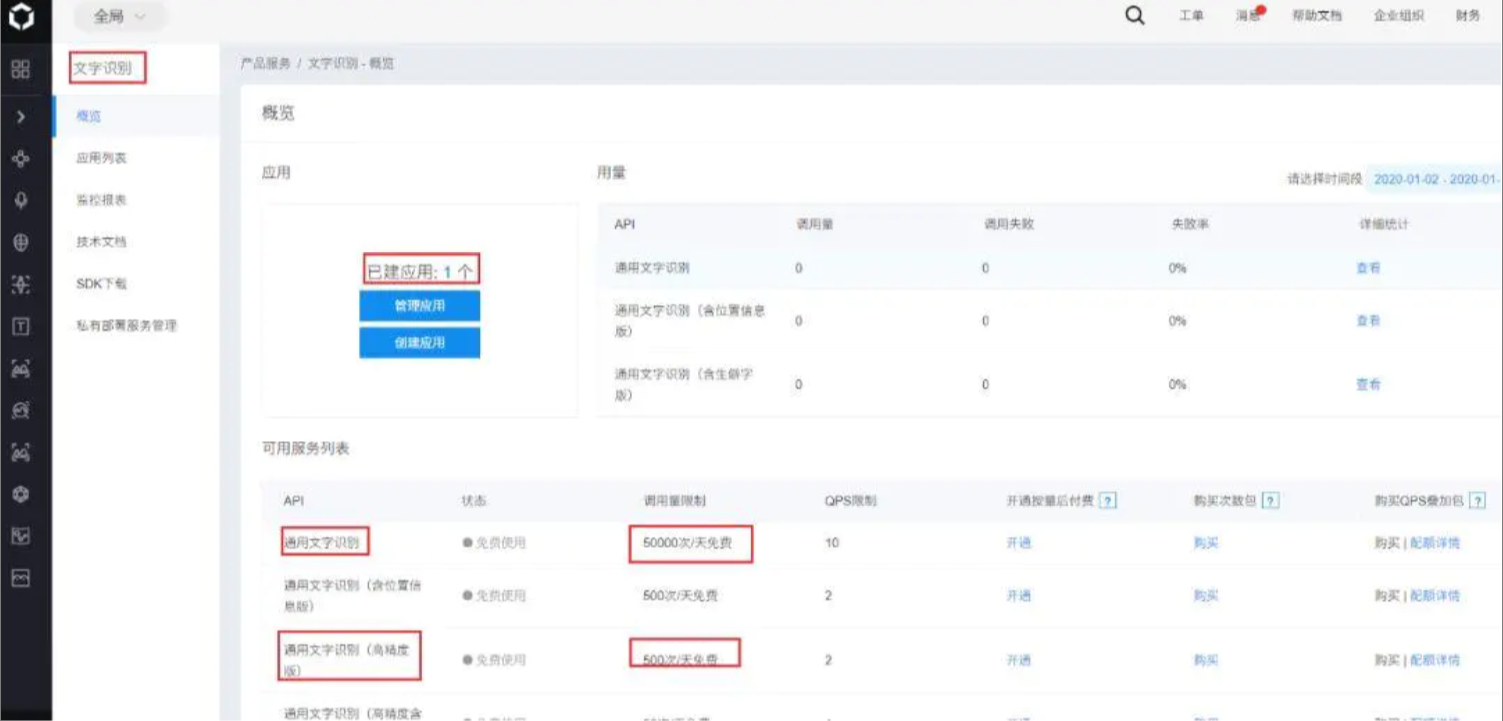
importpytesseract
fromaipimportAipOcr
fromPILimportImageGrab
# 法二:利用百度API
APP_ID ='你的 App ID'
API_KEY ='你的 Api Key'
SECRET_KEY ='你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
withopen("screen.png",'rb')asf:
image = f.read()
# 调用百度API通用文字识别(高精度版),提取图片中的内容
text = client.basicAccurate(image)
result = text["words_result"]
foriinresult:
print(i["words"])
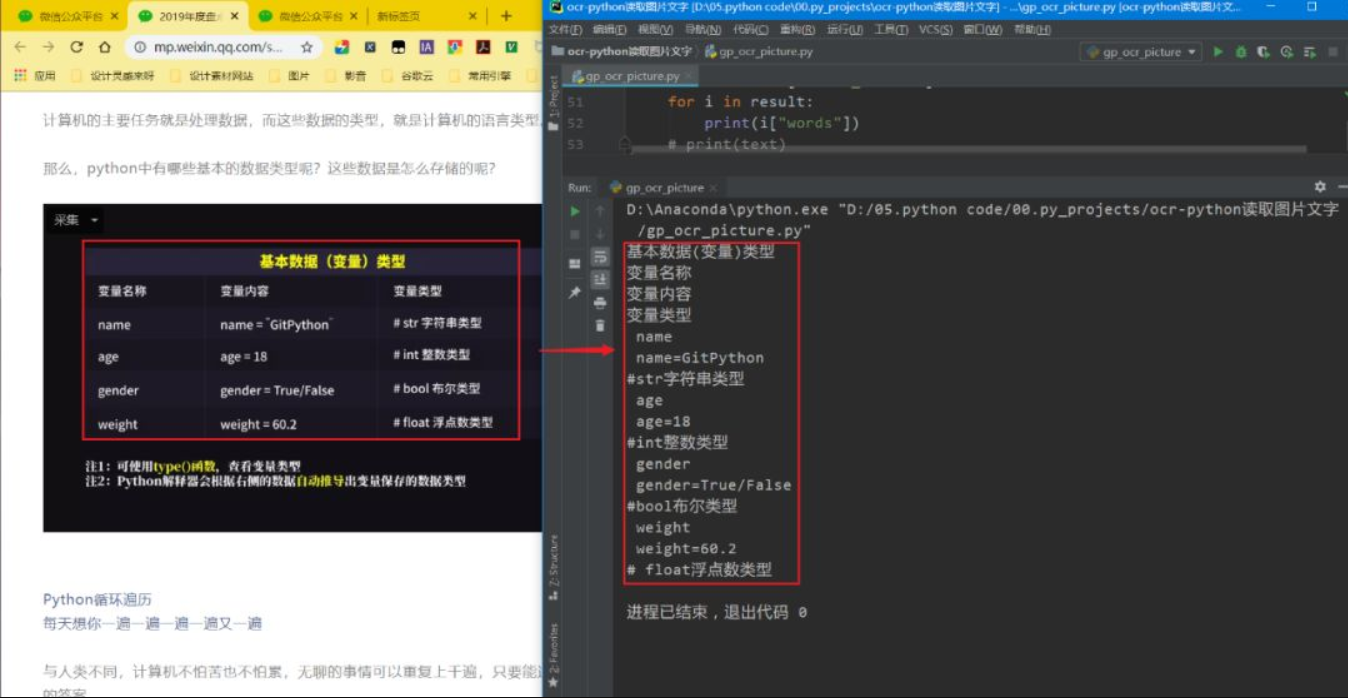
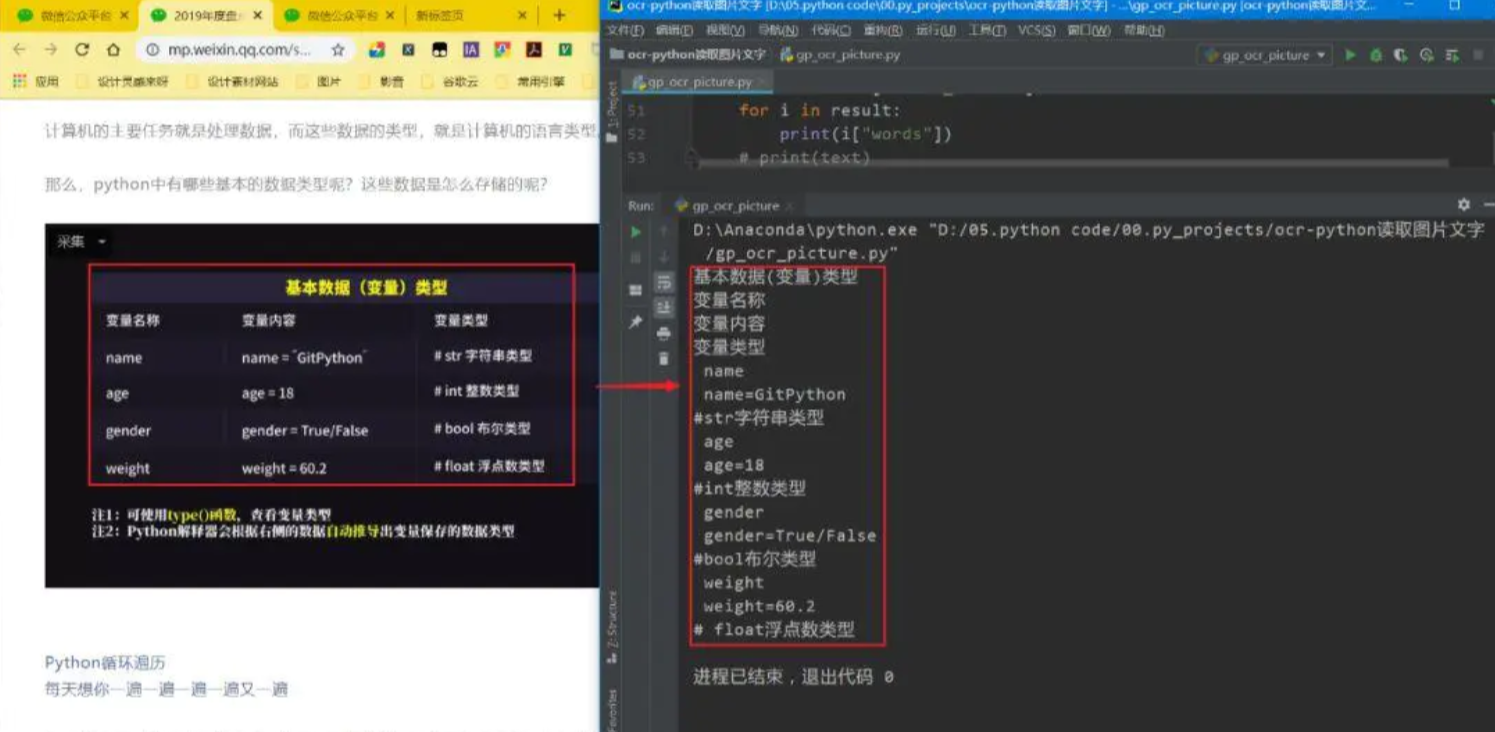
结果
如文章首图:
我是总结
1)等待用户截图
2)保存截图到当前目录
3)识别截图中的文本
其中识别截图文本,有两种方法:
1)利用 pytesseract 模块
2)利用百度API接口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号