CMDB信息采集设计(基础未完成版)
-bin :可执行文件 ( start.py/run.py)
-conf:配置文件目录 config.py
-lib :第三方文件目录
-src/core: 核心的源代码文件目录
-db:省略,可以用数据库代替了
-log:省略,记录文件日志(注意:日志并不是存放在这,而是通过logging模块存放在/var/logs/中)
-test:测试文件目录
重点:反射,魔法方法很重要,django的请求流程
二.CMDB的高级配置文件的设置
目录设置


1.如何获取配置信息
lib/config/conf.py
# (3)导入自定义配置
from conf import config
# (4)导入全局配置
from . import global_settings
# (5)写__init__方法
class mySettings():
# (6)集成用户自定义的配置和全局配置在这里吗
def __init__(self):
# (7)获取全局配置信息,顺序是先全局后自定义,这样自定义的属性可以覆盖掉全局的属性
for k in dir(global_settings):
if k.isupper():
# 通过getattr获取到用户信息
v = getattr(global_settings, k)
# 通过setattr设置当前类的属性
setattr(self, k, v)
#(8)获取用户自定义信息
for k in dir(config):
if k.isupper():
# 通过getattr获取到用户信息
v = getattr(config,k)
# 通过setattr设置当前类的属性
setattr(self, k, v)
settings = mySettings()
bin/start.py
from lib.config.conf import settings
# 此时当我们执行settings就会实例化lib下面的config中conf里面的mySettings类,实例化即执行__init__方法,这样就能通过settings获取
# 自定义或者全局的配置属性,因此第一个重点就在写__init__方法
if __name__ == '__main__':
print(settings.EMAL_PORT)
2.如何实现两套架构方案并可以切换采集方法
2.1:如何实现控制采集与否
-
第一种方法
bin/start.py
from lib.config.conf import settings
# 此时当我们执行settings就会实例化lib下面的config中conf里面的mySettings类,实例化即执行__init__方法,这样就能通过settings获取
# 自定义或者全局的配置属性,因此第一个重点就在写__init__方法
if __name__ == '__main__':
# print(settings.EMAL_PORT)\
# 判断如果自定义配置中的MODE为agent则走第一套方案
if settings.MODE == 'agent':
import subprocess
res = subprocess.getoutput('hostname') # 否则走第二套
else:
import paramiko
# 创建ssh对象
ssh = paramiko.SSHClient()
# 允许链接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 链接服务器(虚拟机设置的地址)
ssh.connect(hostname='10.0.0.200', port=22, username='root', password='123456')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('hostname')
# 获取命令结果
result = stdout.red()
ssh.close()
如果上述代码这样写的话,会带来如下问题:
-
耦合度太高
-
结构混乱,导致查找问题的时候不方便
-
业务逻辑代码不能写在启动文件中
问:如何解决上述存在的问题? 答:将每一个功能都封装成一个文件,比如说采集磁盘的信息,可以搞一个disk.py文件,这个文件中所有的代码都是要和采集磁盘相关的,不能有其他 的相关代码。以此类推,采集CPU的信息,也要搞一个cpu.py文件. 这种思想就是高内聚低耦合思想(高内聚:即每一个代码文件都是有关与同一个内容的,不要有其他相关或无关的代码;低耦合:即代码拆分成多个文件)
-
第二种方法
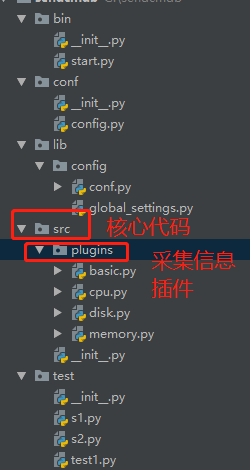
重点伪代码:
bin/start.py
from src.plugins.basic import Basic
from src.plugins.cpu import Cpu
from src.plugins.memory import Memory
from src.plugins.disk import Disk
# 此时当我们执行settings就会实例化lib下面的config中conf里面的mySettings类,实例化即执行__init__方法,这样就能通过settings获取
# 自定义或者全局的配置属性,因此第一个重点就在写__init__方法
if __name__ == '__main__':
src/plugins/basic
# 9.服务器基础信息,包括服务器的主机名,操作系统等
class Basic:
def __init__(self):
pass
# 自定义一个方法执行linux命名
def process(self):
return 'basic...'
src/plugins/cpu
# 10.采集cpu信息的文件
class Cpu:
def __init__(self):
pass
def process(self):
return 'cpu...'
src/plugins/disk
# 11.采集磁盘信息的文件
class Disk:
def __init__(self):
pass
# 自定义一个方法执行linux命名
def process(self):
return 'disk...'
src/plugins/memory
# 12.采集内存所有的信息
class Memory:
def __init__(self):
pass
def process(self):
return 'memory...'
但是上述第二种方法并不完美,结构冗余繁杂,
解决的方案是:将这些采集的插件写到配置文件中统一管理,参考django的中间件, 注释中间件就不会起作用,做成可插拔式的采集
第三种方法:
重点伪代码:
conf/config.py
在自定义配置文件中将采集插件做成类似于中间件的格式
# 模仿django的中间件
PLUGIN_DICT = {
'basc':'src.plugins.basic.Basic',
'cpu':'src.plugins.cpu.Cpu',
'disk':'src.plugins.disk.Disk',
'memory':'src.plugins.memory.Memory',
}
在核心文件夹的插件文件夹下的init文件中设置管理插件的类
src/plugins/_ _init__.py
from lib.config.conf import settings
# importlib下面有一个import_module方法能够导入字符串路径
import importlib
# 13 设置管理插件的类
class PluginsManager:
def __init__(self):
self.plugins_dict = settings.PLUGIN_DICT
# 管理配置文件插件,采集数据,会从conf/config.py这个配置文件里面读取中间件配置,
# 循环导入模块进而获取中间件中的插件方法,process来获取数据信息
def execute(self):
# 循环读取配置
response = {}
for k, v in self.plugins_dict.items():
'''
k: basic
v: src.plugins.basic.Basic
'''
# 循环导入配置,获取路径和方法名
'''
modul_path:src.plugins.basic
class_name:Basic
'''
modul_path, class_name = v.rsplit('.', 1)
# 此时modul_path是字符串,不是真的路径,无法直接导入
# importlib下面有一个import_module方法能够导入字符串路径
m = importlib.import_module(modul_path)
# print(m)
# print(type(m))
'''
打印结果
<module 'src.plugins.basic' from 'G:\\sendcmdb\\src\\plugins\\basic.py'>
<class 'module'>
<module 'src.plugins.cpu' from 'G:\\sendcmdb\\src\\plugins\\cpu.py'>
<class 'module'>
<module 'src.plugins.disk' from 'G:\\sendcmdb\\src\\plugins\\disk.py'>
<class 'module'>
<module 'src.plugins.memory' from 'G:\\sendcmdb\\src\\plugins\\memory.py'>
<class 'module'>
'''
# 反射获取类
cls = getattr(m, class_name)
# print(cls)
'''
打印结果:
<class 'src.plugins.basic.Basic'>
<class 'src.plugins.cpu.Cpu'>
<class 'src.plugins.disk.Disk'>
<class 'src.plugins.memory.Memory'>
'''
# 实例化类中,执行process方法(这就是鸭子方法,为什么都要设置相同的process方法)
ret = cls().process()
# print(ret)
'''
# 打印结果:
basic...
cpu...
disk...
memory...
'''
# 需要对ret做一下处理,改为字典格式,新建一个response空字典在上面
response[k] = ret
return response
start.py
# 因为是写在init里面,可以直接导入过来
from src.plugins import PluginsManager
if __name__ == '__main__':
# 第三种方法
res = PluginsManager().execute()
print(res)
'''
打印结果:
{'basc': 'basic...', 'cpu': 'cpu...', 'disk': 'disk...', 'memory': 'memory...'}
'''
这样只需要通过修改配置文件中的PLUGIN_DICT就可以控制信息的采集,叫做可插拔式采集
2.2.如何采集信息
伪代码:采用if判断采集信息用那种方法
src/plugins/basic
# 9.服务器基础信息,包括服务器的主机名,操作系统等
from lib.config.conf import settings
class Basic:
def __init__(self):
pass
def process(self):
# 判断如果MODE为agent则走第一套方案
if settings.MODE == 'agent':
import subprocess
res = subprocess.getoutput('hostname') # 否则走第二套
else:
import paramiko
# 创建ssh对象
ssh = paramiko.SSHClient()
# 允许链接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 链接服务器(虚拟机设置的地址)
ssh.connect(hostname='10.0.0.200', port=22, username='root', password='123456')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('hostname')
# 获取命令结果
result = stdout.red()
ssh.close()
return 'basic...'
缺点:插件代码,判断方案冗余,
解决方案: 1.继承 每一个子类都要继承父类的方法,通过传参的方式执行不一样的命令 2.将函数名当成一个参数传给另一个函数,从而执行此函数
from lib.config.conf import settings
# importlib下面有一个import_module方法能够导入字符串路径
import importlib
# 13 设置管理插件的类
class PluginsManager:
def __init__(self):
self.plugins_dict = settings.PLUGIN_DICT
# 设置debug属性
self.debug = settings.DEBUG
# 管理配置文件插件,采集数据,会从conf/config.py这个配置文件里面读取中间件配置,
# 循环导入模块进而获取中间件中的插件方法,process来获取数据信息
def execute(self):
# 循环读取配置
response = {}
for k, v in self.plugins_dict.items():
'''
k: basic
v: src.plugins.basic.Basic
'''
# 循环导入配置,获取路径和方法名
'''
modul_path:src.plugins.basic
class_name:Basic
'''
modul_path, class_name = v.rsplit('.', 1)
# 此时modul_path是字符串,不是真的路径,无法直接导入
# importlib下面有一个import_module方法能够导入字符串路径
m = importlib.import_module(modul_path)
# print(m)
# print(type(m))
'''
打印结果
<module 'src.plugins.basic' from 'G:\\sendcmdb\\src\\plugins\\basic.py'>
<class 'module'>
<module 'src.plugins.cpu' from 'G:\\sendcmdb\\src\\plugins\\cpu.py'>
<class 'module'>
<module 'src.plugins.disk' from 'G:\\sendcmdb\\src\\plugins\\disk.py'>
<class 'module'>
<module 'src.plugins.memory' from 'G:\\sendcmdb\\src\\plugins\\memory.py'>
<class 'module'>
'''
# 反射获取类
cls = getattr(m, class_name)
# print(cls)
'''
打印结果:
<class 'src.plugins.basic.Basic'>
<class 'src.plugins.cpu.Cpu'>
<class 'src.plugins.disk.Disk'>
<class 'src.plugins.memory.Memory'>
'''
# 实例化类中,执行process方法(这就是鸭子方法,为什么都要设置相同的process方法)
# 将command_func函数名传过来,即在process函数中执行command_func函数
ret = cls().process(self.command_func,self.debug)
# print(ret)
'''
# 打印结果:
basic...
cpu...
disk...
memory...
'''
# 需要对ret做一下处理,改为字典格式,新建一个response空字典在上面
response[k] = ret
return response
# 定义一个函数,接收需要查询的命令,以及判断那种采集方式
def command_func(self,cmd):
# 判断如果MODE为agent则走第一套方案
if settings.MODE == 'agent':
import subprocess
res = subprocess.getoutput(cmd) # 否则走第二套
return res
else:
import paramiko
# 创建ssh对象
ssh = paramiko.SSHClient()
# 允许链接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 链接服务器(虚拟机设置的地址)
ssh.connect(hostname='10.0.0.200', port=22, username='root', password='123456')