spark下载地址:http://spark.apache.org/downloads.html
hadoop下载地址:https://downloads.apache.org/hadoop/common/
博主spark版本选择的是2.4.5 所以对应的hadoop版本是2.7.7
下载之后直接上传到linux,解压之后就可以啦,不过首先要先配置java环境
jdk必须在1.8以上

配置好jdk后解压hadoop和spark

然后进入spark目录
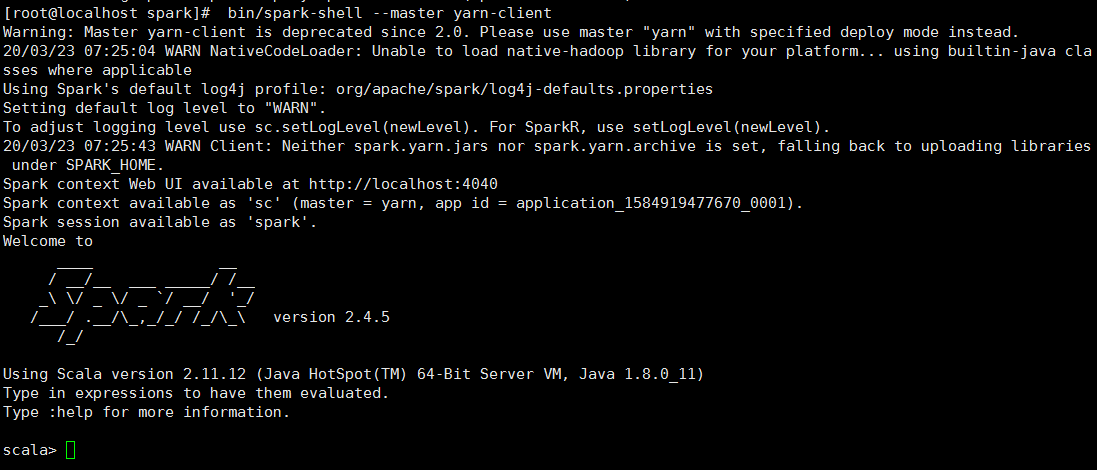
运行./bin/spark-shell
出现如上图所示边上spark环境部署好了
然后做一个小测试
在spark目录下创建两个文件,在文件中随便输入几个单词,然后统计下每个单词出现次数

然后输入
sc.textFile("in").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)

统计完成
然后退出spark-shell再运行下spark提供的案例
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --executor-memory 1G \ --total-executor-cores 2 \ ./examples/jars/spark-examples_2.11-2.4.5.jar \ 100
这是计算圆周率
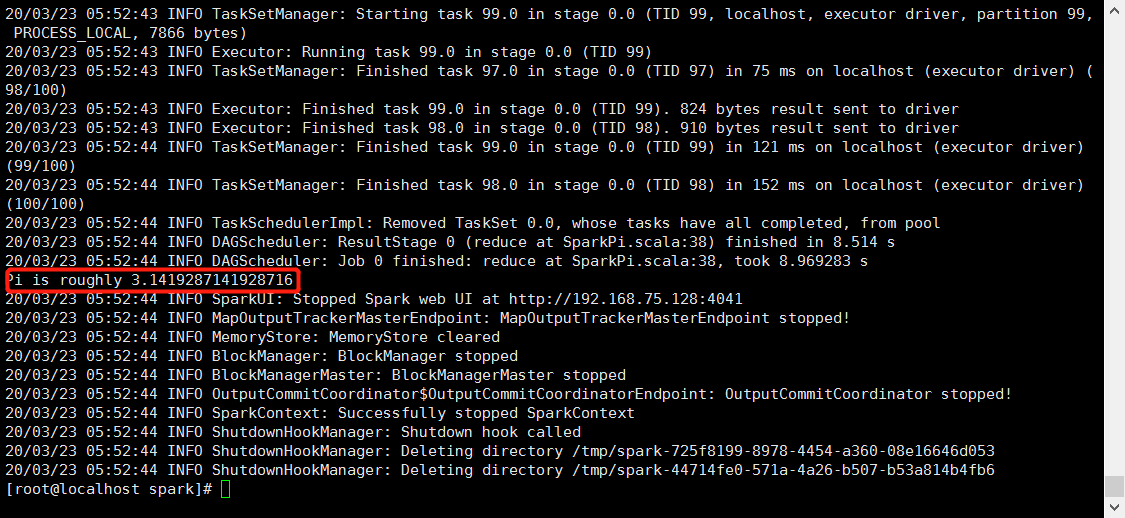
表示案例运行成功
上面是spark单独使用,但是spark要和hadoop一起使用,所以要把spark运行到yarn上
1.首先spark将应用提交各hadoop 的Resource Manager(资源管理器)
2.然后Resource Manager 创建ApplicationMastor(应用管理器)
3.Application Mastor向Resource Manager申请资源
4.Resource Manager 返会Data Manger列表(这个列表不包含包括Application Mastor 的Data Manager)
5.Application Mastor 选取Data Manager 创建Container(容器)
6.Container创建完成后反向注册到Application Mastor
7.Application Mastor 分解任务并且进行调度
先启动hadoop
1.修改hadoop的配置文件 /opt/module/hadoop/etc/hadoop/mapred-site.xml
cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml <configuration> <!-- 通知框架MR使用YARN --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
启动hadoop 然后运行 bin/spark-shell --master yarn-client
还是报错

出现上图修改 vim /opt/module/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
启动hadoop
然后运行 bin/spark-shell --master yarn-client
出现Exception in thread "main" org.apache.spark.SparkException: When running with master 'yarn-client' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
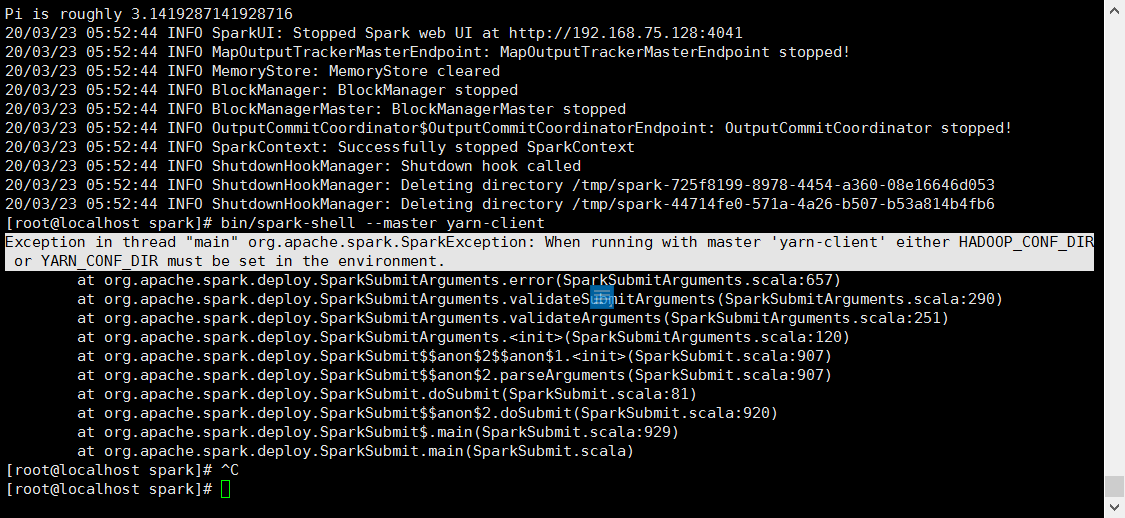
这是由于我们没有在spark中配置hadoop的地址
进入conf配置目录

复制一个spark-env.sh.template 命名为spark-env.sh
cp spark-env.sh.template spark-env.sh
然后 vi spark-env.sh
在最后一行添加hadoop的目录
YARN_CONF_DIR=/opt/module/hadoop
启动成功