Java 集合补充
集合大致可以分List,Set,Queue,Map四种体系。
集合和数组不一样,数组元素可以是基本类型的值,也可以是对象(的引用变量),集合里只能保存对象(的引用变量)。
访问:如果访问List集合中的元素可以根据元素的索引,访问Map集合中的元素可以根据元素的key,访问Set集合中的元素只能根据元素本身来访问。
Collection操作:
public class CollectionTest { public static void main(String[] args) { Collection c = new ArrayList(); // 添加元素 c.add("孙悟空"); // 虽然集合里不能放基本类型的值,但Java支持自动装箱 c.add(6); System.out.println("c集合的元素个数为:" + c.size()); // 输出2 // 删除指定元素 c.remove(6); System.out.println("c集合的元素个数为:" + c.size()); // 输出1 // 判断是否包含指定字符串 System.out.println("c集合的是否包含\"孙悟空\"字符串:" + c.contains("孙悟空")); // 输出true c.add("轻量级Java EE企业应用实战"); System.out.println("c集合的元素:" + c); Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); System.out.println("c集合是否完全包含books集合?" + c.containsAll(books)); // 输出false // 用c集合减去books集合里的元素 c.removeAll(books); System.out.println("c集合的元素:" + c); // 删除c集合里所有元素 c.clear(); System.out.println("c集合的元素:" + c); // 控制books集合里只剩下c集合里也包含的元素 books.retainAll(c); System.out.println("books集合的元素:" + books); } }

注意:
JDK1.5以前系统吧集合所有的元素都当成Object类型,从1.5以后,可以使用泛型来限制集合元素的类型,并让集合记住所有集合元素的类型。
使用Lambda表达式遍历集合:
Java8为Iterable接口新增了一个foreach(Consumer action)默认方法,该方法所需参数的类型是一个函数式接口,而Iterable接口是Collection接口的父接口,因此Collection集合也可以直接调用该方法。
当程序调用Iterable的foreach遍历集合元素,程序会依次将集合元素传给Consumer 的accep(T t)(该接口唯一的抽象方法)方法,因为Consumer是函数式接口,可以使用Lambda表达式来遍历集合元素:
public class CollectionEach { public static void main(String[] args) { // 创建一个集合 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 调用forEach()方法遍历集合 books.forEach(obj -> System.out.println("迭代集合元素:" + obj)); } }
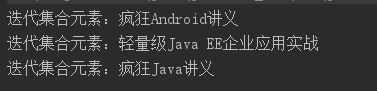
最后一行调用了forEach()方法,传给该方法的参数是一个Lambda表达式,该Lambda表达式的目标类型是Comsumer。
使用Java8增强的Iterator遍历集合元素:
Iterator接口主要用于遍历Collection集合中的元素,Iterator也被称为迭代器。
next()方法返回迭代器刚刚经过的元素。
hasNext()若返回True,则表明接下来还有元素,迭代器不在尾部。
remove()方法必须和next方法一起使用,功能是去除刚刚next方法返回的元素。
forEachRemaining(Consumer action)是Java8新增的方法,可以使用Lambda表达式来遍历集合元素。
public class IteratorTest { public static void main(String[] args) { // 创建集合、添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 获取books集合对应的迭代器 Iterator it = books.iterator(); while(it.hasNext()) { // it.next()方法返回的数据类型是Object类型,因此需要强制类型转换 String book = (String)it.next(); System.out.println(book); if (book.equals("疯狂Java讲义")) { // 从集合中删除上一次next方法返回的元素 it.remove(); } // 对book变量赋值,不会改变集合元素本身 book = "测试字符串"; //① } System.out.println(books); } }

注意:
使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有影响。
当使用Iterator迭代访问Collection集合元素时,Iterator集合里的元素不能被改变,只有通过Iterator的remove方法删除上一次next方法返回的集合元素才可以,否则异常。
public class IteratorErrorTest { public static void main(String[] args) { // 创建集合、添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 获取books集合对应的迭代器 Iterator it = books.iterator(); while(it.hasNext()) { String book = (String)it.next(); System.out.println(book); if (book.equals("疯狂Android讲义")) { // 使用Iterator迭代过程中,不可修改集合元素,下面代码引发异常 books.remove(book); } } } }

Iterator使用的时快速失败机制(fail-fast),一旦在迭代过程中检测到该集合已经被修改(通常是程序中的其他线程修改)程序立即引发异常,而不是显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
使用Lambda表达式遍历Iterator
Java8为Iterator新增的forEachRemaining(Consunmer action)方法,该方法所需的Consunmer 同样是函数式接口。
public class IteratorEach { public static void main(String[] args) { // 创建集合、添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 获取books集合对应的迭代器 Iterator it = books.iterator(); // 使用Lambda表达式(目标类型是Comsumer)来遍历集合元素 it.forEachRemaining(obj -> System.out.println("迭代集合元素:" + obj)); } }
使用Java8新增的Predicate操作集合
Java8起Collection集合新增了一个removeIf(Predicate filter)方法,该方法将会批量删除符合filter条件的所有元素。该方法需要一个Predicate(谓词)对象作为参数,Predicate也是函数式接口,因此可以用Lambda表达式作为参数。
public class PredicateTest { public static void main(String[] args) { // 创建一个集合 Collection books = new HashSet(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂iOS讲义")); books.add(new String("疯狂Ajax讲义")); books.add(new String("疯狂Android讲义")); // 使用Lambda表达式(目标类型是Predicate)过滤集合 books.removeIf(ele -> ((String)ele).length() < 10); System.out.println(books); } }

Predicate可以充分简化集合运算:
public class PredicateTest2 { public static void main(String[] args) { // 创建books集合、为books集合添加元素的代码与前一个程序相同。 Collection books = new HashSet(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂iOS讲义")); books.add(new String("疯狂Ajax讲义")); books.add(new String("疯狂Android讲义")); // 统计书名包含“疯狂”子串的图书数量 System.out.println(calAll(books , ele->((String)ele).contains("疯狂"))); // 统计书名包含“Java”子串的图书数量 System.out.println(calAll(books , ele->((String)ele).contains("Java"))); // 统计书名字符串长度大于10的图书数量 System.out.println(calAll(books , ele->((String)ele).length() > 10)); } public static int calAll(Collection books , Predicate p) { int total = 0; for (Object obj : books) { // 使用Predicate的test()方法判断该对象是否满足Predicate指定的条件 if (p.test(obj)) { total ++; } } return total; } }

使用Java8新增的Stream操作集合
Java8新增了Stream、IntStream、LongStream、DoubleStream等流式API。这些API代表多个支持串行和并行聚集操作的元素。其中Stream是一个通用的流接口,其他代表元素类型的流。
Java8还为每个流式API提供了对应的Builder。
public class IntStreamTest { public static void main(String[] args) { IntStream is = IntStream.builder() .add(20) .add(13) .add(-2) .add(18) .build(); // 下面调用聚集方法的代码每次只能执行一个 System.out.println("is所有元素的最大值:" + is.max().getAsInt()); System.out.println("is所有元素的最小值:" + is.min().getAsInt()); System.out.println("is所有元素的总和:" + is.sum()); System.out.println("is所有元素的总数:" + is.count()); System.out.println("is所有元素的平均值:" + is.average()); System.out.println("is所有元素的平方是否都大于20:" + is.allMatch(ele -> ele * ele > 20)); System.out.println("is是否包含任何元素的平方大于20:" + is.anyMatch(ele -> ele * ele > 20)); // 将is映射成一个新Stream,新Stream的每个元素是原Stream元素的2倍+1 IntStream newIs = is.map(ele -> ele * 2 + 1); // 使用方法引用的方式来遍历集合元素 newIs.forEach(System.out::println); // 输出41 27 -3 37 } }
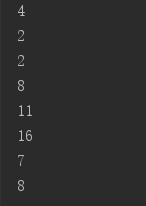
public class CollectionStream { public static void main(String[] args) { // 创建books集合、为books集合添加元素的代码与8.2.5小节的程序相同。 Collection books = new HashSet(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂iOS讲义")); books.add(new String("疯狂Ajax讲义")); books.add(new String("疯狂Android讲义")); // 统计书名包含“疯狂”子串的图书数量 System.out.println(books.stream() .filter(ele->((String)ele).contains("疯狂")) .count()); // 输出4 // 统计书名包含“Java”子串的图书数量 System.out.println(books.stream() .filter(ele->((String)ele).contains("Java") ) .count()); // 输出2 // 统计书名字符串长度大于10的图书数量 System.out.println(books.stream() .filter(ele->((String)ele).length() > 10) .count()); // 输出2 // 先调用Collection对象的stream()方法将集合转换为Stream, // 再调用Stream的mapToInt()方法获取原有的Stream对应的IntStream books.stream().mapToInt(ele -> ((String)ele).length()) // 调用forEach()方法遍历IntStream中每个元素 .forEach(System.out::println);// 输出8 11 16 7 8 } }
Set集合
set和Collection基本相同,实际上set就是Collection,只是行为略有不同(set不允许重复)。
如果把两个形同元素添加进set,会返回false,并元素不会被加入。
HashSet
HashSet是Set接口的典型实现,HasHSet按照Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
特点:
无序。不同步,如果多个线程访问同一个HashSet,有两个或以上线程修改了时,必须通过代码保证其同步。集合元素可以null。
原理:
当HashSet集合存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后给根据hashCode值决定该对象的存储位置。判断两个元素相等的标准是2个对象的equals()方法比较相等,hashCode()方法返回值也相等。
// 类A的equals方法总是返回true,但没有重写其hashCode()方法 class A { public boolean equals(Object obj) { return true; } } // 类B的hashCode()方法总是返回1,但没有重写其equals()方法 class B { public int hashCode() { return 1; } } // 类C的hashCode()方法总是返回2,且重写其equals()方法总是返回true class C { public int hashCode() { return 2; } public boolean equals(Object obj) { return true; } } public class HashSetTest { public static void main(String[] args) { HashSet books = new HashSet(); // 分别向books集合中添加两个A对象,两个B对象,两个C对象 books.add(new A()); books.add(new A()); books.add(new B()); books.add(new B()); books.add(new C()); books.add(new C()); System.out.println(books); } }
C类重写了equals()方法和hashCode()方法,返回相同的值,因此set集合中只有一个C类对象。
注意:
当一个对象放入Has和Set()集合时,如果需要重写该对象的equals()方法,则也应当重写该对象的hashCode()方法。规则是如果equals()返回true,则hashCode值也相等。
hash算法
散列算法(Hash Algorithm),又称哈希算法,杂凑算法,是一种从任意文件中创造小的数字「指纹」的方法。与指纹一样,散列算法就是一种以较短的信息来保证文件唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。因此,当原有文件发生改变时,其标志值也会发生改变,从而告诉文件使用者当前的文件已经不是你所需求的文件。散列算法最重要的用途在于给证书、文档、密码等高安全系数的内容添加加密保护。这一方面的用途主要是得益于散列算法的不可逆性,这种不可逆性体现在,你不仅不可能根据一段通过散列算法得到的指纹来获得原有的文件,也不可能简单地创造一个文件并让它的指纹与一段目标指纹相一致。
一个优秀的 hash 算法,将能实现:
- 正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
- 逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
- 输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
- 冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
hash算法的功能是,保证快速查找被检索的对象,hash算法的价值在于速度,,当需要查询集合中的元素时,hash算法可以根据该元素的hashCode值计算出该元素的存储位置,从而快速定位该元素。
HashSet和数组:
数组有索引可以快速定位,HashSet集合里的元素没有索引,实际上当程序向HashSet集合中添加元素时,HashSet会根据该元素的hashCode值计算他的存储位置,这样也可以快速定位该元素。
优势:
数组元素的索引是连续的,数组长度是固定的,无法自由增加数组长度。HashSet因为使用hashCode值计算存储位置,从而可以自由增加HashSet长度,并根据hashCode值访问元素。因此,当从HashSet中访问元素时,HashSet先计算该元素的hashCode值,然后到hashCode值对应的位置取出该元素,所以速度快。
HashSet中每个能存储元素的槽位通常称为桶,如果有多个元素的hashCode值相同,但他们通过equals方法返回false,就会在同一个桶里放多个元素,导致性能下降。
如果像HashSet中添加一个可变对象后,后面程序修改了该可变对象的实例变量,可能导致它与集合中其他元素相同,这就可能导致HashSet中包含两个相同的对象。
class R { int count; public R(int count) { this.count = count; } public String toString() { return "R[count:" + count + "]"; } public boolean equals(Object obj) { if(this == obj) return true; if (obj != null && obj.getClass() == R.class) { R r = (R)obj; return this.count == r.count; } return false; } public int hashCode() { return this.count; } } public class HashSetTest2 { public static void main(String[] args) { HashSet hs = new HashSet(); hs.add(new R(5)); hs.add(new R(-3)); hs.add(new R(9)); hs.add(new R(-2)); // 打印HashSet集合,集合元素没有重复 System.out.println(hs); // 取出第一个元素 Iterator it = hs.iterator(); R first = (R)it.next(); // 为第一个元素的count实例变量赋值 first.count = -3; // ① // 再次输出HashSet集合,集合元素有重复元素 System.out.println(hs); // 删除count为-3的R对象 hs.remove(new R(-3)); // ② // 可以看到被删除了一个R元素 System.out.println(hs); System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-3))); // 输出false System.out.println("hs是否包含count为-2的R对象?" + hs.contains(new R(-2))); // 输出false } }
LinkedHashSet类
LinkedHashSet集合也是根据hashCode值来决定元素存储的位置,同时他使用链表维护元素的次序。性能低于HashSet,但是在迭代访问Set里的全部元素时将有很好的性能,因为他以链表来维护内部顺序。
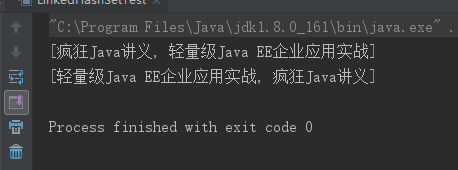
public class LinkedHashSetTest { public static void main(String[] args) { LinkedHashSet books = new LinkedHashSet(); books.add("疯狂Java讲义"); books.add("轻量级Java EE企业应用实战"); System.out.println(books); // 删除 疯狂Java讲义 books.remove("疯狂Java讲义"); // 重新添加 疯狂Java讲义 books.add("疯狂Java讲义"); System.out.println(books); } }
TreESet类
TreESet时SortedSet接口的实现类,TreeSet可以保证集合元素处于排序状态。
public class TreeSetTest { public static void main(String[] args) { TreeSet nums = new TreeSet(); // 向TreeSet中添加四个Integer对象 nums.add(5); nums.add(2); nums.add(10); nums.add(-9); // 输出集合元素,看到集合元素已经处于排序状态 System.out.println(nums); // 输出集合里的第一个元素 System.out.println(nums.first()); // 输出-9 // 输出集合里的最后一个元素 System.out.println(nums.last()); // 输出10 // 返回小于4的子集,不包含4 System.out.println(nums.headSet(4)); // 输出[-9, 2] // 返回大于5的子集,如果Set中包含5,子集中还包含5 System.out.println(nums.tailSet(5)); // 输出 [5, 10] // 返回大于等于-3,小于4的子集。 System.out.println(nums.subSet(-3 , 4)); // 输出[2] } }
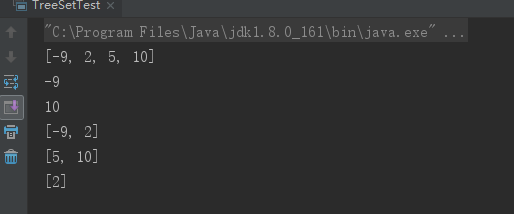
可以看出TreeSet是根据元素实际值大小排序的。
TreeSet采用红黑树的数据结构来存储集合元素。
自然排序:
TreeSet调用几何元素的compareTo(Object obj)方法比较元素的大小关系,然后升序排列。
Java提供了Comparable接口,里面提供了compareTo(Object obj)方法,该方法返回一个整数值,当返回0说明相等,正整数大于,负整数小于。
如果把一个对象添加到TreeSet时,该对象必须实现Comparable接口:
class Err{} public class TreeSetErrorTest { public static void main(String[] args) { TreeSet ts = new TreeSet(); // 向TreeSet集合中添加Err对象 // 自然排序时,Err没实现Comparable接口将会引发错误 ts.add(new Err()); } }

想TreeSet添加的应该是同一个类的对象:
public class TreeSetErrorTest2 { public static void main(String[] args) { TreeSet ts = new TreeSet(); // 向TreeSet集合中添加两个对象 ts.add(new String("疯狂Java讲义")); ts.add(new Date()); // ① } }
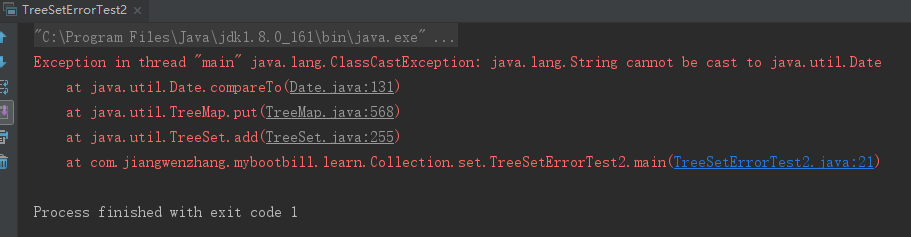
如果像TreeSet中添加的是自定义类,且自定义类实现了Comparable接口,且实现了compareTo(Object obj)方法没有进行强制转换,可以添加多种类型。
TreeSet判断相等的唯一标准是compareTo(Object obj)方法返回0。返回0则无法添加相同对象。
class Z implements Comparable { int age; public Z(int age) { this.age = age; } // 重写equals()方法,总是返回true public boolean equals(Object obj) { return true; } // 重写了compareTo(Object obj)方法,总是返回1 public int compareTo(Object obj) { return 1; } } public class TreeSetTest2 { public static void main(String[] args) { TreeSet set = new TreeSet(); Z z1 = new Z(6); set.add(z1); // 第二次添加同一个对象,输出true,表明添加成功 System.out.println(set.add(z1)); //① // 下面输出set集合,将看到有两个元素 System.out.println(set); // 修改set集合的第一个元素的age变量 ((Z)(set.first())).age = 9; // 输出set集合的最后一个元素的age变量,将看到也变成了9 System.out.println(((Z)(set.last())).age); } }

注意:把一个对象放入TreeSet集合时,重写该对象的equals()方法时应保证该方法与compareTo()方法一致。
如果像TreeSet中添加一个可变对象并修改该对象的实例变量,导致它与其他对象的大小顺序发生了改变,但TreeSet不会再次调整他们的顺序,甚至可能他们的compareTo()结果返回0.
class R implements Comparable { int count; public R(int count) { this.count = count; } public String toString() { return "R[count:" + count + "]"; } // 重写equals方法,根据count来判断是否相等 public boolean equals(Object obj) { if (this == obj) { return true; } if(obj != null && obj.getClass() == R.class) { R r = (R)obj; return r.count == this.count; } return false; } // 重写compareTo方法,根据count来比较大小 public int compareTo(Object obj) { R r = (R)obj; return count > r.count ? 1 : count < r.count ? -1 : 0; } } public class TreeSetTest3 { public static void main(String[] args) { TreeSet ts = new TreeSet(); ts.add(new R(5)); ts.add(new R(-3)); ts.add(new R(9)); ts.add(new R(-2)); // 打印TreeSet集合,集合元素是有序排列的 System.out.println(ts); // ① // 取出第一个元素 R first = (R)ts.first(); // 对第一个元素的count赋值 first.count = 20; // 取出最后一个元素 R last = (R)ts.last(); // 对最后一个元素的count赋值,与第二个元素的count相同 last.count = -2; // 再次输出将看到TreeSet里的元素处于无序状态,且有重复元素 System.out.println(ts); // ② // 删除实例变量被改变的元素,删除失败 System.out.println(ts.remove(new R(-2))); // ③ System.out.println(ts); // 删除实例变量没有被改变的元素,删除成功 System.out.println(ts.remove(new R(5))); // ④ System.out.println(ts); } }
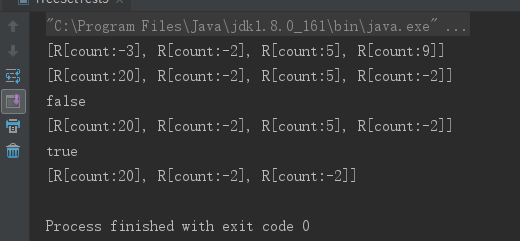
定制排序:
如果需要实现定制排序则需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。Comparator是函数式接口,可以使用Lambda代替Comparator对象。
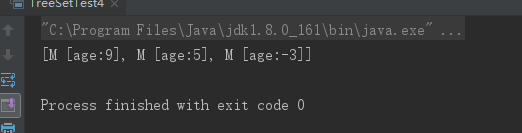
class M { int age; public M(int age) { this.age = age; } public String toString() { return "M [age:" + age + "]"; } } public class TreeSetTest4 { public static void main(String[] args) { // 此处Lambda表达式的目标类型是Comparator TreeSet ts = new TreeSet((o1 , o2) -> { M m1 = (M)o1; M m2 = (M)o2; // 根据M对象的age属性来决定大小,age越大,M对象反而越小 return m1.age > m2.age ? -1 : m1.age < m2.age ? 1 : 0; }); ts.add(new M(5)); ts.add(new M(-3)); ts.add(new M(9)); System.out.println(ts); } }
EnumSet类
EnumSet是一个专为枚举设计的集合类。EnumSet也是有序的,EnumSet以枚举值在EnumSet类内的定义顺序来决定集合元素的顺序。
EnumSet在内部以位向量的形式存储,紧凑高效,占内存小,效率高。
enum Season { SPRING,SUMMER,FALL,WINTER } public class EnumSetTest { public static void main(String[] args) { // 创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值 EnumSet es1 = EnumSet.allOf(Season.class); System.out.println(es1); // 输出[SPRING,SUMMER,FALL,WINTER] // 创建一个EnumSet空集合,指定其集合元素是Season类的枚举值。 EnumSet es2 = EnumSet.noneOf(Season.class); System.out.println(es2); // 输出[] // 手动添加两个元素 es2.add(Season.WINTER); es2.add(Season.SPRING); System.out.println(es2); // 输出[SPRING,WINTER] // 以指定枚举值创建EnumSet集合 EnumSet es3 = EnumSet.of(Season.SUMMER , Season.WINTER); System.out.println(es3); // 输出[SUMMER,WINTER] EnumSet es4 = EnumSet.range(Season.SUMMER , Season.WINTER); System.out.println(es4); // 输出[SUMMER,FALL,WINTER] // 新创建的EnumSet集合的元素和es4集合的元素有相同类型, // es5的集合元素 + es4集合元素 = Season枚举类的全部枚举值 EnumSet es5 = EnumSet.complementOf(es4); System.out.println(es5); // 输出[SPRING] } }
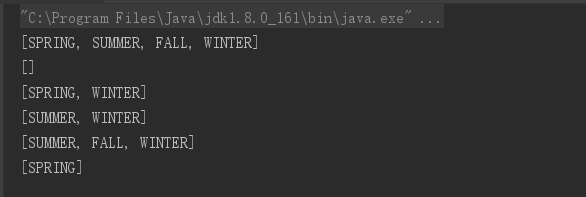
public class EnumSetTest2 { public static void main(String[] args) { Collection c = new HashSet(); c.clear(); c.add(Season.FALL); c.add(Season.SPRING); // 复制Collection集合中所有元素来创建EnumSet集合 EnumSet enumSet = EnumSet.copyOf(c); // ① System.out.println(enumSet); // 输出[SPRING,FALL] c.add("疯狂Java讲义"); c.add("轻量级Java EE企业应用实战"); // 下面代码出现异常:因为c集合里的元素不是全部都为枚举值 enumSet = EnumSet.copyOf(c); // ② } }

Set分析:
HashSet性能比TreeSet好,因为TreeSet需要额外的红黑树维护集合的次序。只有需要一个保持排序的Set时才使用TreeSet。
LikedHashSet对于普通的插入删除操作比HasHSet慢,这是维护链表所带来的额外开销造成的,因为有了链表,遍历会更快。
EnumSet是性能最好的,但他只能保存同一个枚举类型的枚举值作为集合元素。
Set的单个实现类都是线程不安全的,手动保证同步性,通常通过Collections工具类的方法类包装Set集合,最好在集合创建时进行。
List集合
List常用方法:
public class ListTest { public static void main(String[] args) { List books = new ArrayList(); // 向books集合中添加三个元素 books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂Android讲义")); System.out.println(books); // 将新字符串对象插入在第二个位置 books.add(1 , new String("疯狂Ajax讲义")); for (int i = 0 ; i < books.size() ; i++ ) { System.out.println(books.get(i)); } // 删除第三个元素 books.remove(2); System.out.println(books); // 判断指定元素在List集合中位置:输出1,表明位于第二位 System.out.println(books.indexOf(new String("疯狂Ajax讲义"))); //① //将第二个元素替换成新的字符串对象 books.set(1, new String("疯狂Java讲义")); System.out.println(books); //将books集合的第二个元素(包括) //到第三个元素(不包括)截取成子集合 System.out.println(books.subList(1 , 2)); } }

class A { public boolean equals(Object obj) { return true; } } public class ListTest2 { public static void main(String[] args) { List books = new ArrayList(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂Android讲义")); System.out.println(books); // 删除集合中A对象,将导致第一个元素被删除 books.remove(new A()); // ① System.out.println(books); // 删除集合中A对象,再次删除集合中第一个元素 books.remove(new A()); // ② System.out.println(books); } }
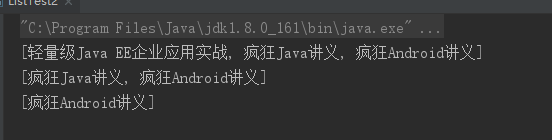
public class ListTest3 { public static void main(String[] args) { List books = new ArrayList(); // 向books集合中添加4个元素 books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂Android讲义")); books.add(new String("疯狂iOS讲义")); // 使用目标类型为Comparator的Lambda表达式对List集合排序 books.sort((o1, o2)->((String)o1).length() - ((String)o2).length()); System.out.println(books); // 使用目标类型为UnaryOperator的Lambda表达式来替换集合中所有元素 // 该Lambda表达式控制使用每个字符串的长度作为新的集合元素 books.replaceAll(ele->((String)ele).length()); System.out.println(books); // 输出[7, 8, 11, 16] } }

public class ListIteratorTest { public static void main(String[] args) { String[] books = { "疯狂Java讲义", "疯狂iOS讲义", "轻量级Java EE企业应用实战" }; List bookList = new ArrayList(); for (int i = 0; i < books.length ; i++ ) { bookList.add(books[i]); } ListIterator lit = bookList.listIterator(); while (lit.hasNext()) { System.out.println(lit.next()); lit.add("-------分隔符-------"); } System.out.println("=======下面开始反向迭代======="); while(lit.hasPrevious()) { System.out.println(lit.previous()); } } }

ArrayList和Vector实现类
都是基于数组,ArrayList是线程不安全的,Vector是线程安全的。Vector提供了一个子类Stack,用于模拟数据结构“栈”。 Stack线程安全,性能较差,因此尽量避免使用。
固定长度的List:
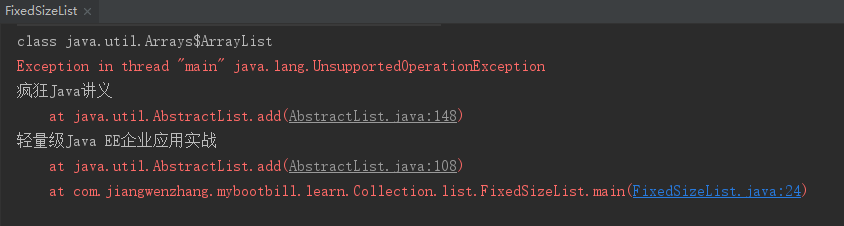
public class FixedSizeList { public static void main(String[] args) { List fixedList = Arrays.asList("疯狂Java讲义" , "轻量级Java EE企业应用实战"); // 获取fixedList的实现类,将输出Arrays$ArrayList System.out.println(fixedList.getClass()); // 使用方法引用遍历集合元素 fixedList.forEach(System.out::println); // 试图增加、删除元素都会引发UnsupportedOperationException异常 fixedList.add("疯狂Android讲义"); fixedList.remove("疯狂Java讲义"); } }
Queue集合
Queue用于模拟数据结构“队列”。通常指先进先出FIFO容器。头部保存存放时间最长的元素,尾部保存存放时间最短的元素。
PriorityQueue实现类
PriorityQueue是一个比较标准的队列实现类,而不是绝对标准,是因为PriorityQueue保存队列元素的顺序并不是按加入队列顺序。PriorityQueue已经违反了队列基本规则先进先出。
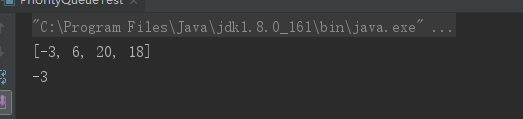
public class PriorityQueueTest { public static void main(String[] args) { PriorityQueue pq = new PriorityQueue(); // 下面代码依次向pq中加入四个元素 pq.offer(6); pq.offer(-3); pq.offer(20); pq.offer(18); // 输出pq队列,并不是按元素的加入顺序排列 System.out.println(pq); // 输出[-3, 6, 20, 18] // 访问队列第一个元素,其实就是队列中最小的元素:-3 System.out.println(pq.poll()); } }
PriorityQueue元素有两种排序,自然排序和定制排序。
Deque和ArrayDeque
Deque是Queue的子接口,它代表一个双端队列。ArrayDeque是Duque的典型实现类。基于数组实现。
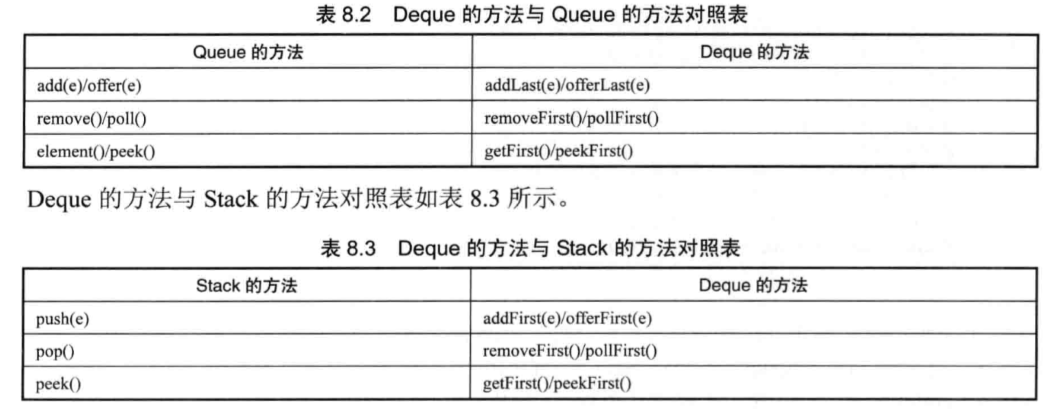
把ArrayDeque当做栈来使用:
public class ArrayDequeStack { public static void main(String[] args) { ArrayDeque stack = new ArrayDeque(); // 依次将三个元素push入"栈" stack.push("疯狂Java讲义"); stack.push("轻量级Java EE企业应用实战"); stack.push("疯狂Android讲义"); // 输出:[疯狂Android讲义, 轻量级Java EE企业应用实战, 疯狂Java讲义] System.out.println(stack); // 访问第一个元素,但并不将其pop出"栈",输出:疯狂Android讲义 System.out.println(stack.peek()); // 依然输出:[疯狂Android讲义, 疯狂Java讲义, 轻量级Java EE企业应用实战] System.out.println(stack); // pop出第一个元素,输出:疯狂Android讲义 System.out.println(stack.pop()); // 输出:[轻量级Java EE企业应用实战, 疯狂Java讲义] System.out.println(stack); } }
程序中需要使用栈时,尽量使用ArrayDeque,不推荐使用Stack,Stack性能较差。
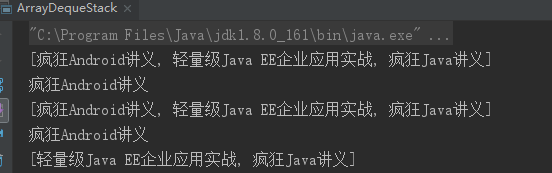
ArrayDeque也可以当做队列使用:
public class ArrayDequeQueue { public static void main(String[] args) { ArrayDeque queue = new ArrayDeque(); // 依次将三个元素加入队列 queue.offer("疯狂Java讲义"); queue.offer("轻量级Java EE企业应用实战"); queue.offer("疯狂Android讲义"); // 输出:[疯狂Java讲义, 轻量级Java EE企业应用实战, 疯狂Android讲义] System.out.println(queue); // 访问队列头部的元素,但并不将其poll出队列"栈",输出:疯狂Java讲义 System.out.println(queue.peek()); // 依然输出:[疯狂Java讲义, 轻量级Java EE企业应用实战, 疯狂Android讲义] System.out.println(queue); // poll出第一个元素,输出:疯狂Java讲义 System.out.println(queue.poll()); // 输出:[轻量级Java EE企业应用实战, 疯狂Android讲义] System.out.println(queue); } }
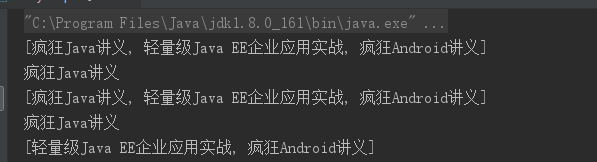
LinkedList实现类:
LinkedList是List接口的实现类,可以根据索引随机访问集合元素,还实现了Deque接口,可以被当作双端队列来使用,因此即可当做栈,也可以当做队列。
public class LinkedListTest { public static void main(String[] args) { LinkedList books = new LinkedList(); // 将字符串元素加入队列的尾部 books.offer("疯狂Java讲义"); // 将一个字符串元素加入栈的顶部 books.push("轻量级Java EE企业应用实战"); // 将字符串元素添加到队列的头部(相当于栈的顶部) books.offerFirst("疯狂Android讲义"); // 以List的方式(按索引访问的方式)来遍历集合元素 for (int i = 0; i < books.size() ; i++ ) { System.out.println("遍历中:" + books.get(i)); } // 访问、并不删除栈顶的元素 System.out.println(books.peekFirst()); // 访问、并不删除队列的最后一个元素 System.out.println(books.peekLast()); // 将栈顶的元素弹出“栈” System.out.println(books.pop()); // 下面输出将看到队列中第一个元素被删除 System.out.println(books); // 访问、并删除队列的最后一个元素 System.out.println(books.pollLast()); // 下面输出:[轻量级Java EE企业应用实战] System.out.println(books); } }

LinkedList是以链表的形式保存元素,所以查慢该快。
各种线性表性能分析:
List就是一个线性表接口。ArrayList和LinkedList是线性表的两种典型表现:基于数组和基于链。Queue代表队列,Deque代表双端队列。
如果需要遍历List,对于ArrayList,Vector集合,应使用随机访问,对于LinkedList应使用迭代器。
如果需要经常执行插入删除操作来改变大量数据的List集合的大小,可以考虑LinkedList。
有多个线程访问可以考虑使用Collection是将集合包装成线程安全的集合。
Java增强的Map集合
Map的key和value,Map的key不允许重复,同一个Map的任何两个key通过equals方法比较总是返回false。
如果把Map的所有的key放在一起,就是一个Set集合。keySet()方法,用于返回Map所有key组成的集合。
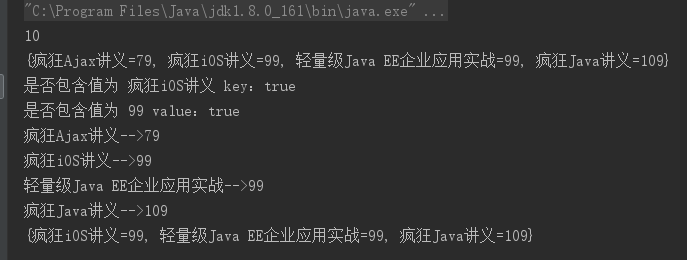
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); // 成对放入多个key-value对 map.put("疯狂Java讲义" , 109); map.put("疯狂iOS讲义" , 10); map.put("疯狂Ajax讲义" , 79); // 多次放入的key-value对中value可以重复 map.put("轻量级Java EE企业应用实战" , 99); // 放入重复的key时,新的value会覆盖原有的value // 如果新的value覆盖了原有的value,该方法返回被覆盖的value System.out.println(map.put("疯狂iOS讲义" , 99)); // 输出10 System.out.println(map); // 输出的Map集合包含4个key-value对 // 判断是否包含指定key System.out.println("是否包含值为 疯狂iOS讲义 key:" + map.containsKey("疯狂iOS讲义")); // 输出true // 判断是否包含指定value System.out.println("是否包含值为 99 value:" + map.containsValue(99)); // 输出true // 获取Map集合的所有key组成的集合,通过遍历key来实现遍历所有key-value对 for (Object key : map.keySet() ) { // map.get(key)方法获取指定key对应的value System.out.println(key + "-->" + map.get(key)); } map.remove("疯狂Ajax讲义"); // 根据key来删除key-value对。 System.out.println(map); // 输出结果不再包含 疯狂Ajax讲义=79 的key-value对 } }
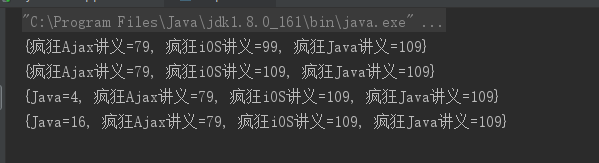
public class MapTest2 { public static void main(String[] args) { Map map = new HashMap(); // 成对放入多个key-value对 map.put("疯狂Java讲义" , 109); map.put("疯狂iOS讲义" , 99); map.put("疯狂Ajax讲义" , 79); // 尝试替换key为"疯狂XML讲义"的value,由于原Map中没有对应的key, // 因此对Map没有改变,不会添加新的key-value对 map.replace("疯狂XML讲义" , 66); System.out.println(map); // 使用原value与参数计算出来的结果覆盖原有的value map.merge("疯狂iOS讲义" , 10 , (oldVal , param) -> (Integer)oldVal + (Integer)param); System.out.println(map); // "疯狂iOS讲义"的value增大了10 // 当key为"Java"对应的value为null(或不存在时),使用计算的结果作为新value map.computeIfAbsent("Java" , (key)->((String)key).length()); System.out.println(map); // map中添加了 Java=4 这组key-value对 // 当key为"Java"对应的value存在时,使用计算的结果作为新value map.computeIfPresent("Java", (key , value) -> (Integer)value * (Integer)value); System.out.println(map); // map中 Java=4 变成 Java=16 } }
Java8改进的HashMap和Hashtable
HashMap和Hashtable都是Map接口的典型实现类,他们之间的关系完全类似于ArrayList和Vector的关系,Hashtable从JDK 1.0就出现了,当时还没有Map接口,所以它包含了两个繁琐的方法:elements()和keys()。
Hashtable和HashMap的两点典型区别:
Hashtable是一个线程安全的Map实现,但HashMap线程不安全。所以HashMap性能高,如果多个线程访问同一个Map,使用Hashtable会更好。
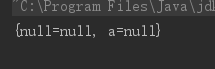
Hashtable不允许null作为key和value,如果试图null放进Hashtable中报空指针,HashMap可以。
public class NullInHashMap { public static void main(String[] args) { HashMap hm = new HashMap(); // 试图将两个key为null的key-value对放入HashMap中 hm.put(null , null); hm.put(null , null); // ① // 将一个value为null的key-value对放入HashMap中 hm.put("a" , null); // ② // 输出Map对象 System.out.println(hm); } }
为了成功的在HashMaori和Hashtable中存储获取对象,用作key的对象必须实现hashCode方法和equals方法。HashMap和Hashtable中判断两个key相同也是hashCode方法和equals方法都相等。
class A { int count; public A(int count) { this.count = count; } // 根据count的值来判断两个对象是否相等。 public boolean equals(Object obj) { if (obj == this) return true; if (obj != null && obj.getClass() == A.class) { A a = (A)obj; return this.count == a.count; } return false; } // 根据count来计算hashCode值。 public int hashCode() { return this.count; } } class B { // 重写equals()方法,B对象与任何对象通过equals()方法比较都返回true public boolean equals(Object obj) { return true; } } public class HashtableTest { public static void main(String[] args) { Hashtable ht = new Hashtable(); ht.put(new A(60000) , "疯狂Java讲义"); ht.put(new A(87563) , "轻量级Java EE企业应用实战"); ht.put(new A(1232) , new B()); System.out.println(ht); // 只要两个对象通过equals比较返回true, // Hashtable就认为它们是相等的value。 // 由于Hashtable中有一个B对象, // 它与任何对象通过equals比较都相等,所以下面输出true。 System.out.println(ht.containsValue("测试字符串")); // ① 输出true // 只要两个A对象的count相等,它们通过equals比较返回true,且hashCode相等 // Hashtable即认为它们是相同的key,所以下面输出true。 System.out.println(ht.containsKey(new A(87563))); // ② 输出true // 下面语句可以删除最后一个key-value对 ht.remove(new A(1232)); //③ System.out.println(ht); } }

public class HashMapErrorTest { public static void main(String[] args) { HashMap ht = new HashMap(); // 此处的A类与前一个程序的A类是同一个类 ht.put(new A(60000) , "疯狂Java讲义"); ht.put(new A(87563) , "轻量级Java EE企业应用实战"); // 获得Hashtable的key Set集合对应的Iterator迭代器 Iterator it = ht.keySet().iterator(); // 取出Map中第一个key,并修改它的count值 A first = (A)it.next(); first.count = 87563; // ① // 输出{A@1560b=疯狂Java讲义, A@1560b=轻量级Java EE企业应用实战} System.out.println(ht); // 只能删除没有被修改过的key所对应的key-value对 ht.remove(new A(87563)); System.out.println(ht); // 无法获取剩下的value,下面两行代码都将输出null。 System.out.println(ht.get(new A(87563))); // ② 输出null System.out.println(ht.get(new A(60000))); // ③ 输出null } }

LinkedHashMap实现类
LinkedHashMap使用双向链表来维护key-value的次序(key的次序),该链表负责维护Map的迭代熟悉怒,迭代熟悉怒和key-value插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序,同时又可以避免使用TreeMap增加的成本。
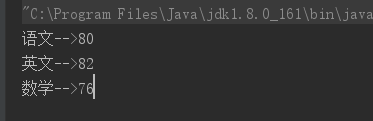
public class LinkedHashMapTest { public static void main(String[] args) { LinkedHashMap scores = new LinkedHashMap(); scores.put("语文" , 80); scores.put("英文" , 82); scores.put("数学" , 76); // 调用forEach方法遍历scores里的所有key-value对 scores.forEach((key, value) -> System.out.println(key + "-->" + value)); } }
使用Properties读写属性文件
Properties是Hashtable的子类,该对象在处理属性文件时特别方便。Properties可以吧Map对形象和属性文件关联起来,从而可以吧Map对象中的keyvalue对写入属性文件中,也可以吧文件中的属性名-属性值加载到Map中。由于属性文件里的属性名属性值只能是字符串类型,所以Properties里的key、value都是字符串类型。
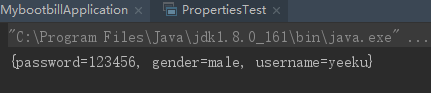
public class PropertiesTest { public static void main(String[] args) throws Exception { Properties props = new Properties(); // 向Properties中增加属性 props.setProperty("username" , "yeeku"); props.setProperty("password" , "123456"); // 将Properties中的key-value对保存到a.ini文件中 props.store(new FileOutputStream("a.ini") , "comment line"); //① // 新建一个Properties对象 Properties props2 = new Properties(); // 向Properties中增加属性 props2.setProperty("gender" , "male"); // 将a.ini文件中的key-value对追加到props2中 props2.load(new FileInputStream("a.ini") ); //② System.out.println(props2); } }
SortedMap接口和TreeMap实现类
Map接口派生出SortedMap子接口,SortedMap接口有一个TreeMap实现类。
TreeMap是一个红黑树结构,每个key-value对即作为一个红黑树节点,TreeMap可以保证所有的key-value对处于有序状态,TreeMap也有两种排序方式,自然排序和定制排序。
TreeMap基本用法:
class R implements Comparable { int count; public R(int count) { this.count = count; } public String toString() { return "R[count:" + count + "]"; } // 根据count来判断两个对象是否相等。 public boolean equals(Object obj) { if (this == obj) return true; if (obj != null && obj.getClass() == R.class) { R r = (R)obj; return r.count == this.count; } return false; } // 根据count属性值来判断两个对象的大小。 public int compareTo(Object obj) { R r = (R)obj; return count > r.count ? 1 : count < r.count ? -1 : 0; } } public class TreeMapTest { public static void main(String[] args) { TreeMap tm = new TreeMap(); tm.put(new R(3) , "轻量级Java EE企业应用实战"); tm.put(new R(-5) , "疯狂Java讲义"); tm.put(new R(9) , "疯狂Android讲义"); System.out.println(tm); // 返回该TreeMap的第一个Entry对象 System.out.println(tm.firstEntry()); // 返回该TreeMap的最后一个key值 System.out.println(tm.lastKey()); // 返回该TreeMap的比new R(2)大的最小key值。 System.out.println(tm.higherKey(new R(2))); // 返回该TreeMap的比new R(2)小的最大的key-value对。 System.out.println(tm.lowerEntry(new R(2))); // 返回该TreeMap的子TreeMap System.out.println(tm.subMap(new R(-1) , new R(4))); } }

WeakHashMap实现类
WeakHashMap和HashMap相似,区别在于HashMap的key保留了对实际对象的强引用,这意味着只要改HashMap对象不被销毁,所有的key所引用的对象就不会被回收,HashMap也不会自动删除这些key所对应的key-valuue对,但WeakHashMap的key只保留了对实际对象的的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收。WeakHashMap也可能自动删除这些key所对应的keyvalue对。

IdentityHashMap实现类
IdentityHashMap实现机制和HashMap相似,但她在处理两个key相等时只有两个key严格相等(key1 == key2)IdentityHashMap才认为两个key相等,普通HashMap是判断两个key的equals和hashCode。
public class IdentityHashMapTest { public static void main(String[] args) { IdentityHashMap ihm = new IdentityHashMap(); // 下面两行代码将会向IdentityHashMap对象中添加两个key-value对 ihm.put(new String("语文") , 89); ihm.put(new String("语文") , 78); // 下面两行代码只会向IdentityHashMap对象中添加一个key-value对 ihm.put("java" , 93); ihm.put("java" , 98); System.out.println(ihm); } }

EnumMap实现类
EnumMap是一个与枚举类一起使用的Map实现。EnumMap所有的key必须是单个枚举类的枚举值。创建EnumMap必须显示或隐式的指定它对应的枚举类。
EnumMap在内部以数组姓氏保存,实现形式紧凑高效。
EnumMap根据key的自然顺序来维护key-value的顺序。
EnumMap不允许null作为key,允许null作为value。
enum Season { SPRING,SUMMER,FALL,WINTER } public class EnumMapTest { public static void main(String[] args) { // 创建EnumMap对象,该EnumMap的所有key都是Season枚举类的枚举值 EnumMap enumMap = new EnumMap(Season.class); enumMap.put(Season.SUMMER , "夏日炎炎"); enumMap.put(Season.SPRING , "春暖花开"); System.out.println(enumMap); } }

各类Map实现类性能分析
Hashtable古老地,线程安全的。比HashMap慢。
TreeMap通常比HashMap和Hashtable慢,因为底层采用红黑树管理key-value对。TreeMap中的key-value对总是处于有序状态,无需专门排序。
LinkedHashMap比HashMap慢,因为他需要维护链表来保持Map中添加顺序。
IdentHashMap性能没有出色支出,只是它使用==判断key相等。
EnumMap性能最好,但他只能使用同一个枚举类的枚举值作为key。
Collections
排序操作:
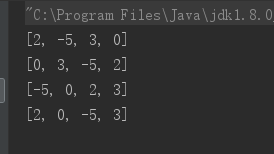
public class SortTest { public static void main(String[] args) { ArrayList nums = new ArrayList(); nums.add(2); nums.add(-5); nums.add(3); nums.add(0); System.out.println(nums); // 输出:[2, -5, 3, 0] Collections.reverse(nums); // 将List集合元素的次序反转 System.out.println(nums); // 输出:[0, 3, -5, 2] Collections.sort(nums); // 将List集合元素的按自然顺序排序 System.out.println(nums); // 输出:[-5, 0, 2, 3] Collections.shuffle(nums); // 将List集合元素的按随机顺序排序 System.out.println(nums); // 每次输出的次序不固定 } }
public class ShowHand { // 定义该游戏最多支持多少个玩家 private final int PLAY_NUM = 5; // 定义扑克牌的所有花色和数值. private String[] types = {"方块" , "草花" ,"红心" , "黑桃"}; private String[] values = {"2" , "3" , "4" , "5" , "6" , "7" , "8" , "9", "10" , "J" , "Q" , "K" , "A"}; // cards是一局游戏中剩下的扑克牌 private List<String> cards = new LinkedList<String>(); // 定义所有的玩家 private String[] players = new String[PLAY_NUM]; // 所有玩家手上的扑克牌 private List<String>[] playersCards = new List[PLAY_NUM]; /** * 初始化扑克牌,放入52张扑克牌, * 并且使用shuffle方法将它们按随机顺序排列 */ public void initCards() { for (int i = 0 ; i < types.length ; i++ ) { for (int j = 0; j < values.length ; j++ ) { cards.add(types[i] + values[j]); } } // 随机排列 Collections.shuffle(cards); } /** * 初始化玩家,为每个玩家分派用户名。 */ public void initPlayer(String... names) { if (names.length > PLAY_NUM || names.length < 2) { // 校验玩家数量,此处使用异常机制更合理 System.out.println("玩家数量不对"); return ; } else { // 初始化玩家用户名 for (int i = 0; i < names.length ; i++ ) { players[i] = names[i]; } } } /** * 初始化玩家手上的扑克牌,开始游戏时每个玩家手上的扑克牌为空, * 程序使用一个长度为0的LinkedList来表示。 */ public void initPlayerCards() { for (int i = 0; i < players.length ; i++ ) { if (players[i] != null && !players[i].equals("")) { playersCards[i] = new LinkedList<String>(); } } } /** * 输出全部扑克牌,该方法没有实际作用,仅用作测试 */ public void showAllCards() { for (String card : cards ) { System.out.println(card); } } /** * 派扑克牌 * @param first 最先派给谁 */ public void deliverCard(String first) { // 调用ArrayUtils工具类的search方法, // 查询出指定元素在数组中的索引 int firstPos = ArrayUtils.search(players , first); // 依次给位于该指定玩家之后的每个玩家派扑克牌 for (int i = firstPos; i < PLAY_NUM ; i ++) { if (players[i] != null) { playersCards[i].add(cards.get(0)); cards.remove(0); } } // 依次给位于该指定玩家之前的每个玩家派扑克牌 for (int i = 0; i < firstPos ; i ++) { if (players[i] != null) { playersCards[i].add(cards.get(0)); cards.remove(0); } } } /** * 输出玩家手上的扑克牌 * 实现该方法时,应该控制每个玩家看不到别人的第一张牌,但此处没有增加该功能 */ public void showPlayerCards() { for (int i = 0; i < PLAY_NUM ; i++ ) { // 当该玩家不为空时 if (players[i] != null) { // 输出玩家 System.out.print(players[i] + " : " ); // 遍历输出玩家手上的扑克牌 for (String card : playersCards[i]) { System.out.print(card + "\t"); } } System.out.print("\n"); } } public static void main(String[] args) { ShowHand sh = new ShowHand(); sh.initPlayer("电脑玩家" , "孙悟空"); sh.initCards(); sh.initPlayerCards(); // 下面测试所有扑克牌,没有实际作用 sh.showAllCards(); System.out.println("---------------"); // 下面从"孙悟空"开始派牌 sh.deliverCard("孙悟空"); sh.showPlayerCards(); /* 这个地方需要增加处理: 1.牌面最大的玩家下注. 2.其他玩家是否跟注? 3.游戏是否只剩一个玩家?如果是,则他胜利了。 4.如果已经是最后一张扑克牌,则需要比较剩下玩家的牌面大小. */ // 再次从"电脑玩家"开始派牌 sh.deliverCard("电脑玩家"); sh.showPlayerCards(); } }
查找替换:
public class SearchTest { public static void main(String[] args) { ArrayList nums = new ArrayList(); nums.add(2); nums.add(-5); nums.add(3); nums.add(0); System.out.println(nums); // 输出:[2, -5, 3, 0] System.out.println(Collections.max(nums)); // 输出最大元素,将输出3 System.out.println(Collections.min(nums)); // 输出最小元素,将输出-5 Collections.replaceAll(nums , 0 , 1); // 将nums中的0使用1来代替 System.out.println(nums); // 输出:[2, -5, 3, 1] // 判断-5在List集合中出现的次数,返回1 System.out.println(Collections.frequency(nums , -5)); Collections.sort(nums); // 对nums集合排序 System.out.println(nums); // 输出:[-5, 1, 2, 3] //只有排序后的List集合才可用二分法查询,输出3 System.out.println(Collections.binarySearch(nums , 3)); } }

同步控制:
Collections中提供了多个synchrondXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时线程的安全问题。
public class SynchronizedTest { public static void main(String[] args) { // 下面程序创建了四个线程安全的集合对象 Collection c = Collections .synchronizedCollection(new ArrayList()); List list = Collections.synchronizedList(new ArrayList()); Set s = Collections.synchronizedSet(new HashSet()); Map m = Collections.synchronizedMap(new HashMap()); } }
设置不可变集合
Collections提供了三类方法返回一个不可变集合:

public class UnmodifiableTest { public static void main(String[] args) { // 创建一个空的、不可改变的List对象 List unmodifiableList = Collections.emptyList(); // 创建一个只有一个元素,且不可改变的Set对象 Set unmodifiableSet = Collections.singleton("疯狂Java讲义"); // 创建一个普通Map对象 Map scores = new HashMap(); scores.put("语文" , 80); scores.put("Java" , 82); // 返回普通Map对象对应的不可变版本 Map unmodifiableMap = Collections.unmodifiableMap(scores); // 下面任意一行代码都将引发UnsupportedOperationException异常 unmodifiableList.add("测试元素"); //① unmodifiableSet.add("测试元素"); //② unmodifiableMap.put("语文" , 90); //③ } }

繁琐的Enumeration接口
Enumeration时迭代器Iterator的老版本。
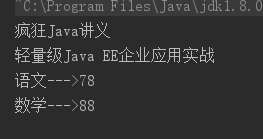
public class EnumerationTest { public static void main(String[] args) { Vector v = new Vector(); v.add("疯狂Java讲义"); v.add("轻量级Java EE企业应用实战"); Hashtable scores = new Hashtable(); scores.put("语文" , 78); scores.put("数学" , 88); Enumeration em = v.elements(); while (em.hasMoreElements()) { System.out.println(em.nextElement()); } Enumeration keyEm = scores.keys(); while (keyEm.hasMoreElements()) { Object key = keyEm.nextElement(); System.out.println(key + "--->" + scores.get(key)); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号