Java I/O流输入输出,序列化,NIO,NIO.2
Java IO流
File类:
File类是java.io包下代表和平台无关的文件和目录,File不能访问文件内容本身。
File类基本操作:
System.out.println("判断文件是否存在:"+file.exists());//判断文件是否存在,返回Boolean值
System.out.println("创建文件夹:"+file.mkdir());//创建文件夹,只能创建一层,返回Boolean值
System.out.println("文件目录:"+file.getParent());//返回文件最后一级子目录
System.out.println("创建文件夹:"+file2.mkdirs());//创建文件夹,创建多层,返回Boolean值
System.out.println("创建新文件:"+file3.createNewFile());//创建新文件,此处需处理异常,返回Boolean值
System.out.println("删除文件:"+file3.delete());//删除文件,返回Boolean值
System.out.println("文件改名:"+file.renameTo(file4));//文件改名,传入另一个文件
System.out.println("文件名:"+file.getName());//返回名
System.out.println("文件路径:"+file.getPath());//返回文件路径
System.out.println("绝对路径:"+file.getAbsolutePath());//返回绝对路径
System.out.println("文件夹:"+file.isDirectory());//返回是否文件夹
System.out.println("是否文件:"+file.isFile());//返回是否文件
System.out.println("是否文件夹:"+file.isDirectory());//返回是否文件夹
System.out.println("是否绝对路径:"+file.isAbsolute());//返回是否绝对路径
System.out.println("文件长度:"+file.length());//返回文件长度
System.out.println("最后修改时间:"+file.lastModified());//返回最后修改时间

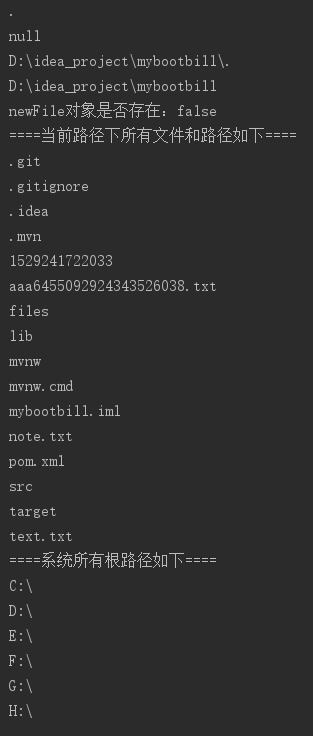
// 以当前路径来创建一个File对象 File file = new File("."); // 直接获取文件名,输出一点 System.out.println(file.getName()); // 获取相对路径的父路径可能出错,下面代码输出null System.out.println(file.getParent()); // 获取绝对路径 System.out.println(file.getAbsoluteFile()); // 获取上一级路径 System.out.println(file.getAbsoluteFile().getParent()); // 在当前路径下创建一个临时文件 File tmpFile = File.createTempFile("aaa", ".txt", file); // 指定当JVM退出时删除该文件 tmpFile.deleteOnExit(); // 以系统当前时间作为新文件名来创建新文件 File newFile = new File(System.currentTimeMillis() + ""); System.out.println("newFile对象是否存在:" + newFile.exists()); // 以指定newFile对象来创建一个文件 newFile.createNewFile(); // 以newFile对象来创建一个目录,因为newFile已经存在, // 所以下面方法返回false,即无法创建该目录 newFile.mkdir(); // 使用list()方法来列出当前路径下的所有文件和路径 String[] fileList = file.list(); System.out.println("====当前路径下所有文件和路径如下===="); for (String fileName : fileList) { System.out.println(fileName); } // listRoots()静态方法列出所有的磁盘根路径。 File[] roots = File.listRoots(); System.out.println("====系统所有根路径如下===="); for (File root : roots) { System.out.println(root); }
文件过滤器:
File类的list()方法中可以接受一个FilenameFilter参数,通过该参数可以只列出符合条件的文件。FilenameFilter接口里包含了一个accept(**)方法,该方法将一次对指定File的所有子目录或者文件进行迭代,如果该方法返回true,则list()方法会列出该子目录或者文件。
File file = new File("."); // 使用Lambda表达式(目标类型为FilenameFilter)实现文件过滤器。 // 如果文件名以.java结尾,或者文件对应一个路径,返回true String[] nameList = file.list((dir, name) -> name.endsWith(".java") || new File(name).isDirectory()); for(String name : nameList) { System.out.println(name); }
FilenameFilter接口内只有一个抽象方法,因此改接口也是一个函数式接口,可使用Lambda表达式创建实现该接口的对象。
Java的IO流概念
Java的IO流是实现输入输出的基础,在Java中把不同的输入输出源抽象表述为流,通过流的方式允许Java使用相同的方式来访问不同的输入输出源。
stream是从起源(source)到接收(sink)的有序数据。

IO(in / out)流的分类
流向:
输入流 读取数据
输出流 写出数据
数据类型:
字节流
一个字节占8位, 以一个字节为单位读数据
八大数据类型所占字节数:
byte(1), short(2), int(4), long(8),float(4), double(8),boolean(1),char(2)
字节输入流 读取数据 InputStream

字节输出流 写出数据 OutputStream

字符流
一个字符占两个字节, 以一个字符为一个单位
字符输入流 读取数据 Reader

字符输出流 写出数据 Writer

字节流的基本抽象类
InputStream OutputStream
字符流的基本抽象类
Reader Writer
功能:
节点流: 只有一个根管道套在文件上进行传输
处理流: 将节点流处理一下, 增强管道的功能, 相当于在管道上套一层
字节流和字符流:
InputStream和Reader是所有输入流的抽象基类,本身并不能创建实例来执行输入,但它们将成为所有输入流的模板,他们的方法是有输入流都可以使用的方法。
这两个基类的功能基本是一样的。
他们分别有一个用于读取文件的输入流:FileInputStream和FileReader,他们都是节点流,会直接和指定文件关联。
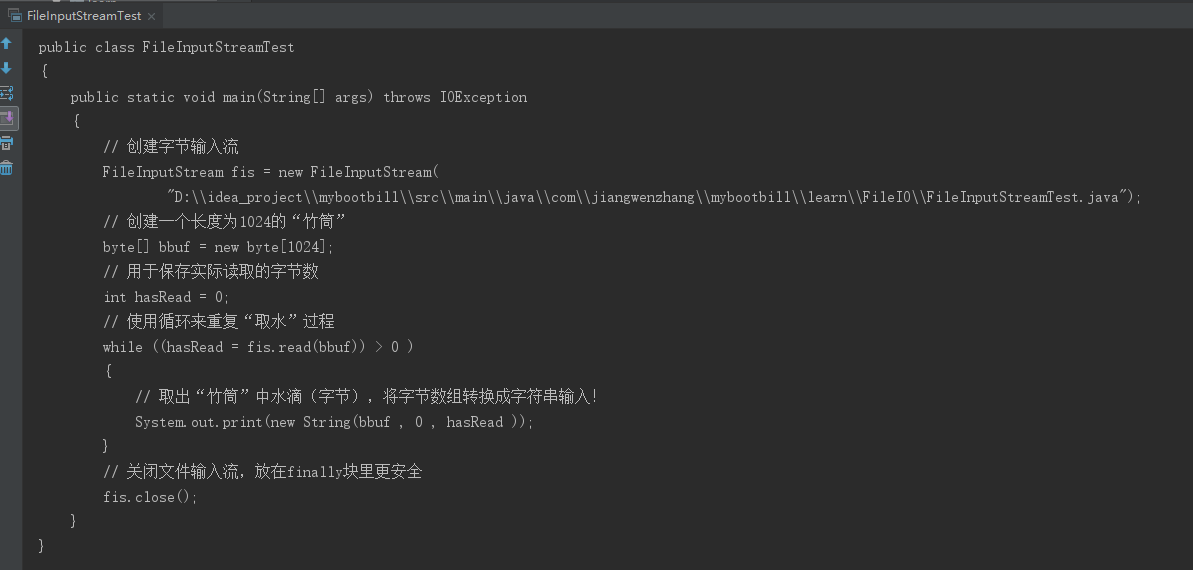
使用FileInputStream读取文件自身:
public static void main(String[] args) throws IOException { // 创建字节输入流 FileInputStream fis = new FileInputStream( "D:\\idea_project\\mybootbill\\src\\main\\java\\com\\jiangwenzhang\\mybootbill\\learn\\FileIO\\FileInputStreamTest.java"); // 创建一个长度为1024的“竹筒” byte[] bbuf = new byte[1024]; // 用于保存实际读取的字节数 int hasRead = 0; // 使用循环来重复“取水”过程 while ((hasRead = fis.read(bbuf)) > 0 ) { // 取出“竹筒”中水滴(字节),将字节数组转换成字符串输入! System.out.print(new String(bbuf , 0 , hasRead )); } // 关闭文件输入流,放在finally块里更安全 fis.close(); }
需要注意,如果bbuf字节数组的长度较小,遇到中文时可能会乱码,因为如果文件本身保存时采用GBK编码方式,在这种方式下,每个中文字符占两个字节,如果read方法读取时只读取到了半个中文就会乱码。
程序里打开的文件IO资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以要显示关闭文件IO资源。
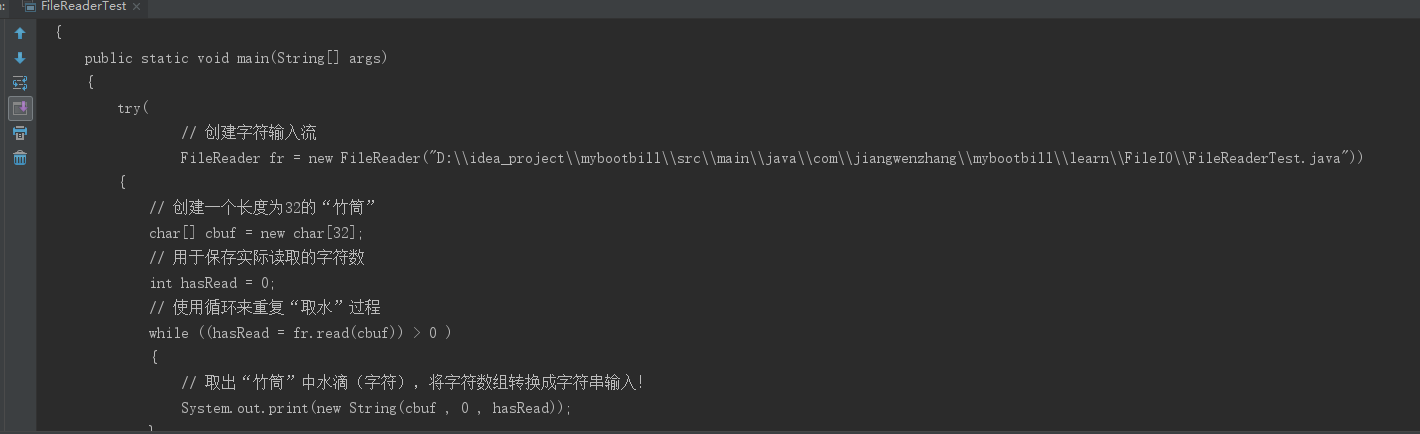
使用FileReader:
public static void main(String[] args) { try( // 创建字符输入流 FileReader fr = new FileReader("D:\\idea_project\\mybootbill\\src\\main\\java\\com\\jiangwenzhang\\mybootbill\\learn\\FileIO\\FileReaderTest.java")) { // 创建一个长度为32的“竹筒” char[] cbuf = new char[32]; // 用于保存实际读取的字符数 int hasRead = 0; // 使用循环来重复“取水”过程 while ((hasRead = fr.read(cbuf)) > 0 ) { // 取出“竹筒”中水滴(字符),将字符数组转换成字符串输入! System.out.print(new String(cbuf , 0 , hasRead)); } } catch (IOException ex) { ex.printStackTrace(); } }
InputStream和Reader还支持如下几个方法来移动记录指针:
| 方法 | 释义 |
|---|---|
void mark(int readlimit) |
Marks the current position in this input stream. |
boolean markSupported() |
Tests if this input stream supports the mark and reset methods. |
void reset() |
Repositions this stream to the position at the time the mark method was last called on this input stream. |
long skip(long n) |
Skips over and discards n bytes of data from this input stream. |
OuputStream和Writer:
public static void main(String[] args) { try( // 创建字节输入流 FileInputStream fis = new FileInputStream( "D:\\idea_project\\mybootbill\\src\\main\\java\\com\\jiangwenzhang\\mybootbill\\learn\\FileIO\\FileOutputStreamTest.java"); // 创建字节输出流 FileOutputStream fos = new FileOutputStream("newFile.txt"))//文件在项目根 { byte[] bbuf = new byte[32]; int hasRead = 0; // 循环从输入流中取出数据 while ((hasRead = fis.read(bbuf)) > 0 ) { // 每读取一次,即写入文件输出流,读了多少,就写多少。 fos.write(bbuf , 0 , hasRead); } } catch (IOException ioe) { ioe.printStackTrace(); } }
注意:使用IO流执行输出时,不要忘记关闭输出流,关闭输出流处可以保证流的物流自愿被回收,还可以将输出流缓冲区的数据flush到物理节点里。
如果希望直接输出字符串内容,使用Writer更好:
public static void main(String[] args) { try( FileWriter fw = new FileWriter("poem.txt")) { fw.write("锦瑟 - 李商隐\r\n"); fw.write("锦瑟无端五十弦,一弦一柱思华年。\r\n"); fw.write("庄生晓梦迷蝴蝶,望帝春心托杜鹃。\r\n"); fw.write("沧海月明珠有泪,蓝田日暖玉生烟。\r\n"); fw.write("此情可待成追忆,只是当时已惘然。\r\n"); } catch (IOException ioe) { ioe.printStackTrace(); } }
输入输出流体系:
使用处理流的典型思路是,使用处理流来包装节点流,程序通过处理流来执行输入输入,让节点流与底层设备、文件交互。
使用PrintStream处理流包装OutStream:
public static void main(String[] args) { try( FileOutputStream fos = new FileOutputStream("test.txt"); PrintStream ps = new PrintStream(fos)) { // 使用PrintStream执行输出 ps.println("普通字符串"); // 直接使用PrintStream输出对象 ps.println(new PrintStreamTest()); } catch (IOException ioe) { ioe.printStackTrace(); } }
通常如果要输出文本内容,都应将输出流包装成PrintStream后输出。
注意,在使用处理流包装了底层节点之后,关闭输入输出流资源是,只要关闭最上层的处理流即可,关闭最上层处理流时,系统会自动关闭被该处理流包装的节点流。
Java输入输出流体系常用流分类:
| 流分类 | 使用分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
| 抽象基类 | InputStream |
OutputStream |
Reader | Writer | |
| 节点流 | 访问文件 | FileInputStream | FileOutStream | FileReader | FileWriter |
| 访问数值 | ByteArrayInputStream | ByteArrayOutStream | CharArrayReader | CharArrayWriter | |
| 访问管道 | PipedInputStream | PipedOutStream | PipedReader | PipedWriter | |
| 访问字符串 | StringReader | StringWriter | |||
| 处理流 | 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | |||
| 对象流 | ObjectInputStream | ObjectOutputStream | |||
| 抽象基类(过滤) | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter | |
| 打印流 | PrintStream | PrintWriter | |||
| 推回输入流 | PushbackInputStream | PushbackReader | |||
| 特殊流 | DataInputStream | DataOutputStream | |
通常来说,字节流的功能比字符流强大,因为计算机所有数据都是二进制的,字节流可以处理所有的二进制文件,但是需要使用合适的方式把这些字节转换成字符,通常:如果进行输入输出的内容是文本内容,则应该考虑使用字符流,如果是二进制内容,则使用字节流。
使用字符串作为物理节点:
public static void main(String[] args) { String src = "从明天起,做一个幸福的人\n" + "喂马,劈柴,周游世界\n" + "从明天起,关心粮食和蔬菜\n" + "我有一所房子,面朝大海,春暖花开\n" + "从明天起,和每一个亲人通信\n" + "告诉他们我的幸福\n"; char[] buffer = new char[32]; int hasRead = 0; try( StringReader sr = new StringReader(src)) { // 采用循环读取的访问读取字符串 while((hasRead = sr.read(buffer)) > 0) { System.out.print(new String(buffer ,0 , hasRead)); } } catch (IOException ioe) { ioe.printStackTrace(); } try( // 创建StringWriter时,实际上以一个StringBuffer作为输出节点 // 下面指定的20就是StringBuffer的初始长度 StringWriter sw = new StringWriter()) { // 调用StringWriter的方法执行输出 sw.write("有一个美丽的新世界,\n"); sw.write("她在远方等我,\n"); sw.write("哪里有天真的孩子,\n"); sw.write("还有姑娘的酒窝\n"); System.out.println("----下面是sw的字符串节点里的内容----"); // 使用toString()方法返回StringWriter的字符串节点的内容 System.out.println(sw.toString()); } catch (IOException ex) { ex.printStackTrace(); } }
和前面使用FileReader和FileWriter相似,只是创建对象时传入的是字符串节点,用于String是不可变得字符串对象,所以StringWriter使用StringBuffer作为输出节点。
转换流
InputStreamReader将字节输入流转换成字符输入流,OutputStreamWriter将字节输出流转换成字符输出流。
以键盘输入为例,java使用System.in代表标准输入也就是键盘输入,但这个标准输入流是InputStream类的实例,可以使用InputStreamReader将其转换成字符输入流,再讲普通的Reader再次包装成BufferedReader:
public static void main(String[] args) { try( // 将Sytem.in对象转换成Reader对象 InputStreamReader reader = new InputStreamReader(System.in); // 将普通Reader包装成BufferedReader BufferedReader br = new BufferedReader(reader)) { String line = null; // 采用循环方式来一行一行的读取 while ((line = br.readLine()) != null) { // 如果读取的字符串为"exit",程序退出 if (line.equals("exit")) { System.exit(1); } // 打印读取的内容 System.out.println("输入内容为:" + line); } } catch (IOException ioe) { ioe.printStackTrace(); } }

推回输入流:
PushbackInputStream和PushbackReader
推回输入流都带有一个推回缓冲区,当程序调用推回输入流的unread()方法,系统将会把指定数组内容推回到该缓冲区,而推回输入流每次调用read()方法总是先从推回缓冲区读取,只有完全读取了推回缓冲区的内容后,但还没有装满read()所需的数组时才会从原输入流读取。
public static void main(String[] args) { try( // 创建一个PushbackReader对象,指定推回缓冲区的长度为64 PushbackReader pr = new PushbackReader(new FileReader( "D:\\idea_project\\mybootbill\\src\\main\\java\\com\\jiangwenzhang\\mybootbill\\learn\\FileIO\\PushbackTest.java") , 64)) { char[] buf = new char[32]; // 用以保存上次读取的字符串内容 String lastContent = ""; int hasRead = 0; // 循环读取文件内容 while ((hasRead = pr.read(buf)) > 0) { // 将读取的内容转换成字符串 String content = new String(buf , 0 , hasRead); int targetIndex = 0; // 将上次读取的字符串和本次读取的字符串拼起来, // 查看是否包含目标字符串, 如果包含目标字符串 if ((targetIndex = (lastContent + content) .indexOf("new PushbackReader")) > 0) { // 将本次内容和上次内容一起推回缓冲区 pr.unread((lastContent + content).toCharArray());// 重新定义一个长度为targetIndex的char数组 if(targetIndex > 32) { buf = new char[targetIndex]; } // 再次读取指定长度的内容(就是目标字符串之前的内容) pr.read(buf , 0 , targetIndex); // 打印读取的内容 System.out.print(new String(buf , 0 ,targetIndex)); System.exit(0); } else { // 打印上次读取的内容 System.out.print(lastContent); // 将本次内容设为上次读取的内容 lastContent = content; } } } catch (IOException ioe) { ioe.printStackTrace(); } }

粗体下划线部分实现了将制定内容推回到推回缓冲区,于是程序再次调用read()方法时,实际上只是读取了推回缓冲区的部分内容,从而实现了只打印目标字符串前面内容的功能。
重定向标准输入输出:
一般情况下,System.in代表的是键盘、System.out是代表的控制台(显示器)。当程序通过System.in来获取输入的时候,默认情况下,是从键盘读取输入;当程序试图通过System.out执行输出时,程序总是输出到显示器。如果我们想对这样的情况做一个改变,例如获取输入时,不是来自键盘,而是来自文件或其他的位置;输出的时候,不是输出到显示器上显示,而是输出到文件或其他位置,怎么实现?于是,java重定标准输入输出应运而生。
static void setErr(PrintStream err)、重定向标准错误输出流
static void setIn(InputStream in)、重定向标准输入流
static void setOut(PrintStream out) 重定向标准输出流
public static void main(String[] args) { try( // 一次性创建PrintStream输出流 PrintStream ps = new PrintStream(new FileOutputStream("out.txt"))) { // 将标准输出重定向到ps输出流 System.setOut(ps); // 向标准输出输出一个字符串 System.out.println("普通字符串"); // 向标准输出输出一个对象 System.out.println(new RedirectOut()); } catch (IOException ex) { ex.printStackTrace(); } }
public static void main(String[] args) { try( FileInputStream fis = new FileInputStream("RedirectIn.java")) { // 将标准输入重定向到fis输入流 System.setIn(fis); // 使用System.in创建Scanner对象,用于获取标准输入 Scanner sc = new Scanner(System.in); // 增加下面一行将只把回车作为分隔符 sc.useDelimiter("\n"); // 判断是否还有下一个输入项 while(sc.hasNext()) { // 输出输入项 System.out.println("键盘输入的内容是:" + sc.next()); } } catch (IOException ex) { ex.printStackTrace(); } }
Java虚拟机读写其他进程数据
读取其他进程的输出信息:
public static void main(String[] args) throws IOException { // 运行javac命令,返回运行该命令的子进程 Process p = Runtime.getRuntime().exec("javac"); try( // 以p进程的错误流创建BufferedReader对象 // 这个错误流对本程序是输入流,对p进程则是输出流 BufferedReader br = new BufferedReader(new InputStreamReader(p.getErrorStream()))) { String buff = null; // 采取循环方式来读取p进程的错误输出 while((buff = br.readLine()) != null) { System.out.println(buff); } } }
在Java程序中启动Java虚拟机运行另一个Java程序,并像另一个Java程序中输入数据:
package com.jiangwenzhang.mybootbill.learn.FileIO; import java.io.*; import java.util.*; public class WriteToProcess { public static void main(String[] args) throws IOException { // 运行java ReadStandard命令,返回运行该命令的子进程 Process p = Runtime.getRuntime().exec("java ReadStandard"); try( // 以p进程的输出流创建PrintStream对象 // 这个输出流对本程序是输出流,对p进程则是输入流 PrintStream ps = new PrintStream(p.getOutputStream())) { // 向ReadStandard程序写入内容,这些内容将被ReadStandard读取 ps.println("普通字符串"); ps.println(new WriteToProcess()); } } } // 定义一个ReadStandard类,该类可以接受标准输入, // 并将标准输入写入out.txt文件。 class ReadStandard { public static void main(String[] args) { try( // 使用System.in创建Scanner对象,用于获取标准输入 Scanner sc = new Scanner(System.in); PrintStream ps = new PrintStream( new FileOutputStream("out.txt"))) { // 增加下面一行将只把回车作为分隔符 sc.useDelimiter("\n"); // 判断是否还有下一个输入项 while(sc.hasNext()) { // 输出输入项 ps.println("键盘输入的内容是:" + sc.next()); } } catch(IOException ioe) { ioe.printStackTrace(); } } }
RandomAccessFile
随机流(RandomAccessFile)不属于IO流,支持对文件的读取和写入随机访问。
RandomAccessFile允许自由定位文件记录指针,RandomAccessFile可以不从开始的地方开始输出,因为RandomAccessFile可以向已存在的文件后追加内容。
RandomAccessFile最大的局限就是只能读写文件,不能读写其他IO节点。
RandomAccessFile对象包含了一个记录指针,用以标识当前读写位置。RandomAccessFile可以自由移动该记录指针。
使用RandomAccessFile来访问指定的中间部分数据:
public static void main(String[] args) { try( RandomAccessFile raf = new RandomAccessFile( "D:\\idea_project\\mybootbill\\src\\main\\java\\com\\jiangwenzhang\\mybootbill\\learn\\FileIO\\RandomAccessFileTest.java" , "r")) { // 获取RandomAccessFile对象文件指针的位置,初始位置是0 System.out.println("RandomAccessFile的文件指针的初始位置:" + raf.getFilePointer()); // 移动raf的文件记录指针的位置 raf.seek(300); byte[] bbuf = new byte[1024]; // 用于保存实际读取的字节数 int hasRead = 0; // 使用循环来重复“取水”过程 while ((hasRead = raf.read(bbuf)) > 0 ) { // 取出“竹筒”中水滴(字节),将字节数组转换成字符串输入! System.out.print(new String(bbuf , 0 , hasRead )); } } catch (IOException ex) { ex.printStackTrace(); } }

该方法以只读方式打开文件,从300字节处开始读取。
像文件中追加内容,为了追加内容,程序应该先将记录指针移动到文件最后,然后项文件中输出内容。
public static void main(String[] args) { try( //以读、写方式打开一个RandomAccessFile对象 RandomAccessFile raf = new RandomAccessFile("out.txt" , "rw")) { //将记录指针移动到out.txt文件的最后 raf.seek(raf.length()); raf.write("追加的内容!\r\n".getBytes()); } catch (IOException ex) { ex.printStackTrace(); } }
指定文件,指定位置插入内容:
package com.jiangwenzhang.mybootbill.learn.FileIO; import java.io.*; public class InsertContent { public static void insert(String fileName , long pos , String insertContent) throws IOException { File tmp = File.createTempFile("tmp" , null); tmp.deleteOnExit(); try( RandomAccessFile raf = new RandomAccessFile(fileName , "rw"); // 使用临时文件来保存插入点后的数据 FileOutputStream tmpOut = new FileOutputStream(tmp); FileInputStream tmpIn = new FileInputStream(tmp)) { raf.seek(pos); // ------下面代码将插入点后的内容读入临时文件中保存------ byte[] bbuf = new byte[64]; // 用于保存实际读取的字节数 int hasRead = 0; // 使用循环方式读取插入点后的数据 while ((hasRead = raf.read(bbuf)) > 0 ) { // 将读取的数据写入临时文件 tmpOut.write(bbuf , 0 , hasRead); } // ----------下面代码插入内容---------- // 把文件记录指针重新定位到pos位置 raf.seek(pos); // 追加需要插入的内容 raf.write(insertContent.getBytes()); // 追加临时文件中的内容 while ((hasRead = tmpIn.read(bbuf)) > 0 ) { raf.write(bbuf , 0 , hasRead); } } } public static void main(String[] args) throws IOException { insert("InsertContent.java" , 45 , "插入的内容\r\n"); } }
Java9改进的对象序列化
对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象。所有分布式应用常常需要跨平台,跨网络,因此要求所有传的参数、返回值都必须实现序列化。
序列化:把Java对象转换为字节序列的过程。
反序列化:把字节序列恢复为Java对象的过程。
对象的序列化是指将一个Java对象写入IO流中,对象的反序列化则是是指从IO流中恢复该Java对象。
Java9增强了对象序列化机制,他允许对读入的序列化数据进行过滤,这种过滤可以在反序列化之前对数据执行校验,从而提高安全性和健壮性。
让某个类可序列化,必须实现如下两个接口之一:
Serializable
Externailzable
Java的很多类已经实现了Serializable,这是一个标记接口,无需实现任何方法,只是表明该类的实例是可以序列化的。
所有可能在网络上传输的对象的类都应该是可序列化的。
使用对象流实现序列化:
public class Person implements java.io.Serializable { private String name; private int age; // 注意此处没有提供无参数的构造器! public Person(String name , int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 // name的setter和getter方法 public void setName(String name) { this.name = name; } public String getName() { return this.name; } // age的setter和getter方法 public void setAge(int age) { this.age = age; } public int getAge() { return this.age; } }
public class WriteObject { public static void main(String[] args) { try( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("object.txt"))) { Person per = new Person("孙悟空", 500); // 将per对象写入输出流 oos.writeObject(per); } catch (IOException ex) { ex.printStackTrace(); } } }
从而二进制流中恢复Java对象:
public class ReadObject { public static void main(String[] args) { try( // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream( new FileInputStream("object.txt"))) { // 从输入流中读取一个Java对象,并将其强制类型转换为Person类 Person p = (Person)ois.readObject(); System.out.println("名字为:" + p.getName() + "\n年龄为:" + p.getAge()); } catch (Exception ex) { ex.printStackTrace(); } } }
注意:反序列化读取的仅仅是Java对象的数据,而不是Java类,因此采用反序列化恢复Java对象必须提供Java对象所属类的class文件。
反序列化机制无需通过构造器来初始化Java对象。
如果使用序列化机制向文件中写入了多个Java对象,使用反序列化机制恢复对象必须按实际写入的顺序读取。
对象引用的序列化
如果某个类的成员变量的类型不是基本类型或String而是引用类型,那么这个引用类必须是可序列化的,否则拥有该类型成员变量的的类也是不可序列化的。
public class Teacher implements java.io.Serializable { private String name; private Person student; public Teacher(String name , Person student) { this.name = name; this.student = student; } // 此处省略了name和student的setter和getter方法 // name的setter和getter方法 public void setName(String name) { this.name = name; } public String getName() { return this.name; } // student的setter和getter方法 public void setStudent(Person student) { this.student = student; } public Person getStudent() { return this.student; } }
特殊情况:
Person per = new Person("孙悟空", 500); Teacher t1 = new Teacher("唐僧" , per); Teacher t2 = new Teacher("菩提祖师" , per);
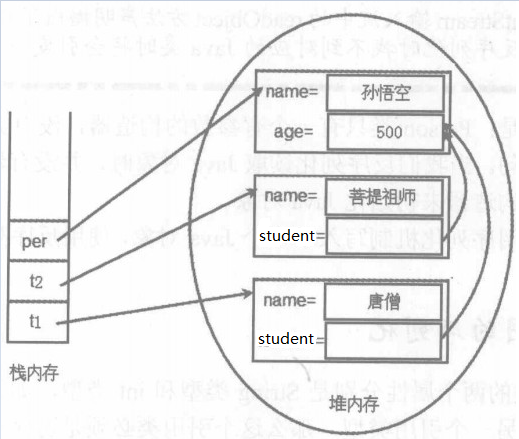
两种对象互相引用,这样如果先序列化t1,系统将t1对象引用的Person对象一起序列化,在序列化t2,程序将一样会序列化该t2对象,并且再次序列化Person对象,如果程序在显示序列化per对象,系统又一次序列化person对象。这个过程向输出流中输出三个Person对象。
这样程序从输入流中反序列化这些对象,将会得到三个person对象,从而引起t1和t2所引用的Person对象不是同一个对象。
Java序列化机制采用了一种特殊的序列化算法:
1、所有保存到磁盘中的对象都有一个序列化编号。
2、当程序试图序列化一个对象时,会先检查该对象是否已经被序列化过,只有该对象从未(在本次虚拟机中)被序列化,系统才会将该对象转换成字节序列并输出。
3、如果对象已经被序列化,程序将直接输出一个序列化编号,而不是重新序列化。
通过以上算法,当第二次第三次序列化,程序不会再次将Person对象转换成字节序列并输出,而是仅仅输出一个序列化编号。
当多次调用wirteObject()方法输出同一个对象时,只有第一次调用wirteObject()方法才会将该对象转换成字节序列并输出。
public static void main(String[] args) { try( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("teacher.txt"))) { Person per = new Person("孙悟空", 500); Teacher t1 = new Teacher("唐僧" , per); Teacher t2 = new Teacher("菩提祖师" , per); // 依次将四个对象写入输出流 oos.writeObject(t1); oos.writeObject(t2); oos.writeObject(per); oos.writeObject(t2); } catch (IOException ex) { ex.printStackTrace(); } }
public static void main(String[] args) { try( // 创建一个ObjectInputStream输出流 ObjectInputStream ois = new ObjectInputStream( new FileInputStream("teacher.txt"))) { // 依次读取ObjectInputStream输入流中的四个对象 Teacher t1 = (Teacher)ois.readObject(); Teacher t2 = (Teacher)ois.readObject(); Person p = (Person)ois.readObject(); Teacher t3 = (Teacher)ois.readObject(); // 输出true System.out.println("t1的student引用和p是否相同:" + (t1.getStudent() == p)); // 输出true System.out.println("t2的student引用和p是否相同:" + (t2.getStudent() == p)); // 输出true System.out.println("t2和t3是否是同一个对象:" + (t2 == t3)); } catch (Exception ex) { ex.printStackTrace(); } }
上面代码依次读取了序列化文件中的4个Java对象,通过比较可以看出t2和t3是同一个对象。
注意:
由于Java序列化机制使然,多次序列化同一个Java对象时,只有第一次序列化该对象才会把该Java对象转换成字节序列并输出,因此程序序列化一个可变对象之后,后面改变了对象的实例变量值,再次序列化也只是输出前面的序列化编号,改变的实例变量值也不会输出。
public static void main(String[] args) { try( // 创建一个ObjectOutputStream输入流 ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("mutable.txt")); // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream( new FileInputStream("mutable.txt"))) { Person per = new Person("孙悟空", 500); // 系统会per对象转换字节序列并输出 oos.writeObject(per); // 改变per对象的name实例变量 per.setName("猪八戒"); // 系统只是输出序列化编号,所以改变后的name不会被序列化 oos.writeObject(per); Person p1 = (Person)ois.readObject(); //① Person p2 = (Person)ois.readObject(); //② // 下面输出true,即反序列化后p1等于p2 System.out.println(p1 == p2); // 下面依然看到输出"孙悟空",即改变后的实例变量没有被序列化 System.out.println(p2.getName()); } catch (Exception ex) { ex.printStackTrace(); } }
Java9增加的过滤功能:
Java9为ObjectInputStream增加了setObjectInputFilter()和getObjectInputFilter()两个方法,其中第一个方法用于为对象输入流设置过滤器。当程序通过ObjectInputStream反序列化时,过滤器的checkInput()方法会被自动激发,用于检查序列化数据是否有效。
public static void main(String[] args) { try( // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream( new FileInputStream("object.txt"))) { ois.setObjectInputFilter((info) -> { System.out.println("===执行数据过滤==="); ObjectInputFilter serialFilter = ObjectInputFilter.Config.getSerialFilter(); if (serialFilter != null) { // 首先使用ObjectInputFilter执行默认的检查 ObjectInputFilter.Status status = serialFilter.checkInput(info); // 如果默认检查的结果不是Status.UNDECIDED if (status != ObjectInputFilter.Status.UNDECIDED) { // 直接返回检查结果 return status; } } // 如果要恢复的对象不是1个 if(info.references() != 1) { // 不允许恢复对象 return ObjectInputFilter.Status.REJECTED; } if (info.serialClass() != null && // 如果恢复的不是Person类 info.serialClass() != Person.class) { // 不允许恢复对象 return ObjectInputFilter.Status.REJECTED; } return ObjectInputFilter.Status.UNDECIDED; }); // 从输入流中读取一个Java对象,并将其强制类型转换为Person类 Person p = (Person)ois.readObject(); System.out.println("名字为:" + p.getName() + "\n年龄为:" + p.getAge()); } catch (Exception ex) { ex.printStackTrace(); } }
自定义序列化
通过在实例变量前使用transient关键字修饰,可以指定Java序列化时无需理会该实例变量。
public class Person implements java.io.Serializable { private String name; private transient int age; // 注意此处没有提供无参数的构造器! public Person(String name , int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 // name的setter和getter方法 public void setName(String name) { this.name = name; } public String getName() { return this.name; } // age的setter和getter方法 public void setAge(int age) { this.age = age; } public int getAge() { return this.age; } }
public class TransientTest { public static void main(String[] args) { try( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("transient.txt")); // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream( new FileInputStream("transient.txt"))) { Person per = new Person("孙悟空", 500); // 系统会per对象转换字节序列并输出 oos.writeObject(per); Person p = (Person)ois.readObject(); System.out.println(p.getAge()); } catch (Exception ex) { ex.printStackTrace(); } } }
程序将输出0
被transient修饰的的实例变量被完全隔离在序列化机制之外,这导致在反序列化恢复Java对象时无法取得该实例变量值。
Java提供了一种自定义序列化机制:
public class Person implements java.io.Serializable { private String name; private int age; // 注意此处没有提供无参数的构造器! public Person(String name , int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 // name的setter和getter方法 public void setName(String name) { this.name = name; } public String getName() { return this.name; } // age的setter和getter方法 public void setAge(int age) { this.age = age; } public int getAge() { return this.age; } private void writeObject(java.io.ObjectOutputStream out) throws IOException { // 将name实例变量的值反转后写入二进制流 out.writeObject(new StringBuffer(name).reverse()); out.writeInt(age); } private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException { // 将读取的字符串反转后赋给name实例变量 this.name = ((StringBuffer)in.readObject()).reverse() .toString(); this.age = in.readInt(); } }
还有一种更彻底的自定义机制,他可以在序列化对象时将该对象替换成其他对象。
public class Person implements java.io.Serializable { private String name; private int age; // 注意此处没有提供无参数的构造器! public Person(String name , int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 // name的setter和getter方法 public void setName(String name) { this.name = name; } public String getName() { return this.name; } // age的setter和getter方法 public void setAge(int age) { this.age = age; } public int getAge() { return this.age; } // 重写writeReplace方法,程序在序列化该对象之前,先调用该方法 private Object writeReplace()throws ObjectStreamException { ArrayList<Object> list = new ArrayList<>(); list.add(name); list.add(age); return list; } }
Java的序列化机制保证在序列化某个对象之前,先调用该对象的writeReplace()方法,如果方法返回的是另一个对象,则系统转为序列化另一个对象,
public class ReplaceTest { public static void main(String[] args) { try( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("replace.txt")); // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream( new FileInputStream("replace.txt"))) { Person per = new Person("孙悟空", 500); // 系统将per对象转换字节序列并输出 oos.writeObject(per); // 反序列化读取得到的是ArrayList ArrayList list = (ArrayList)ois.readObject(); System.out.println(list); } catch (Exception ex) { ex.printStackTrace(); } } }
序列化机制里还有一个特殊的方法,他可以实现保护整个对象,
public class Orientation implements java.io.Serializable { public static final Orientation HORIZONTAL = new Orientation(1); public static final Orientation VERTICAL = new Orientation(2); private int value; private Orientation(int value) { this.value = value; } // 为枚举类增加readResolve()方法 private Object readResolve()throws ObjectStreamException { if (value == 1) { return HORIZONTAL; } if (value == 2) { return VERTICAL; } return null; } }
Java的另一种自定义序列化机制:
Java还提供了另一种自定义序列化机制,这种序列化机制完全由程序员存储和恢复对象数据。需要实现Externalizable接口。
public class Person implements java.io.Externalizable { private String name; private int age; // 注意必须提供无参数的构造器,否则反序列化时会失败。 public Person(){} public Person(String name , int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 // name的setter和getter方法 public void setName(String name) { this.name = name; } public String getName() { return this.name; } // age的setter和getter方法 public void setAge(int age) { this.age = age; } public int getAge() { return this.age; } public void writeExternal(java.io.ObjectOutput out) throws IOException { // 将name实例变量的值反转后写入二进制流 out.writeObject(new StringBuffer(name).reverse()); out.writeInt(age); } public void readExternal(java.io.ObjectInput in) throws IOException, ClassNotFoundException { // 将读取的字符串反转后赋给name实例变量 this.name = ((StringBuffer)in.readObject()).reverse().toString(); this.age = in.readInt(); } }
NIO
NIO(新IO)和传统的IO具有相同的目的,都用于进行输入输出,但新IO采用了不同的方式来处理,NIO采用内存映射文件的方式来处理,NIO将文件或文件的一段区域映射到内存中,从而像访问内存一样访问文件。就像操作系统的虚拟内存概念。
Channel(通道)和Buffer(缓冲)是NIO的两个核心对象,Channel是对传统输入输出系统的模拟,在NIO中所有的数据都需要通过通道传输,Channel和传统的输入输出最大的区别在于它提供了一个map()方法,该方法可以直接将一块数据映射到内存中。
IO是面向流的,NIO是面向快(缓冲区)的。
Buffer可以被理解成一个容器,他的本质是数组,发送到Channel中的所有对象都必须首相放到Buffer中,从Channel中取出的数据也必须先放到Buffer中,Buffer可以一次次去Channel中取数据,也允许用Channel将文件的某块数据映射成Buffer。
NIO还提供了用于将Unicode字符串映射成字节序列以及逆映射操作的Charset累和用于支持非阻塞式输入输出的Selector类。
Buffer
Buffer就像一个数组可以保存多个类型相同的数据,Buffer是一个抽象类,最常用的子类是ByteBuffer,他可以在底层字节数组上进行getset操作。其他基本数据类型除了boolean都有相应的Buffer类。
在Buffer中有几个重要概念
| 属性 | 描述 |
|---|---|
| Capacity | 容量,即可以容纳的最大数据量;在缓冲区创建时被设定并且不能改变 |
| Limit | 上界,缓冲区中当前数据量 |
| Position | 位置,下一个要被读或写的元素的索引 |
| Mark | 标记,调用mark()来设置mark=position,再调用reset()可以让position恢复到标记的位置即position=mark |
并遵循:capacity>=limit>=position>=mark>=0
Buffer的主要作用是装入数据然后输出数据,开始时Buffer的postiton为0,limit为capatity,程序通过put()方法像Buffer装入数据,或者从Channel中获取数据,Buffer的postion相应的后移。
Buffer装入数据后,调用Buffer的flip()方法,将limit位置设为postiton所在位置,并将postiton设为0,是的Buffer的读写指针移动到了开始的位置,为输出数据做好准备,当BUffer输出数据结束后,Buffer调用clear方法,不是清空数据,仅仅将postiton设置为0,两limit设置为capatity,为再次向Buffer中装入数据做好了准备。
Buffer常规操作:
ByteBuffer buffer=ByteBuffer.allocate(1024); //非直接 大小为1024个字节 此时它的position=0 limit=1024 capacity=1024
ByteBuffer buf =ByteBuffer.allocateDirect(1024); //直接 大小为1024个字节
buffer.put("abcde".getBytes()); //将一个字节数组写入缓冲区 此时它的position=5 limit=1024 capacity=1024
buffer.put("abcde".getBytes()); //该数组会在之前position开始写 写完后 position=10 limit=1024 capacity=1024
buffer.flip(); //这一步的作用是 使position=0 limit为可以操作的最大字节数 这里limit=10 capacity不变 还是1024
System.out.println(new String(byteBuffer.array(),0,2)); //它的结果在这里是:ab
这个方法的作用是什么呢?回到属性,执行下面语句:
System.out.println(byteBuffer.position());
System.out.println(byteBuffer.limit());
System.out.println(byteBuffer.capacity());
输出的结果是(以空格代替换行): 0 1024 1024
也就是说,现在这个缓冲区现在可以从索引0位置开始操作了。那就put试一试:
byteBuffer.put("hhh".getBytes()); //注意这里只put3个字节
那么如果put之后的position、limit、capacity又是多少呢?
此时position=3 limit=1024 capacity=1024
对于上面的结果?也许会有疑问?先保留吧,接下来我们读取该buffer的内容:
byteBuffer.flip(); //读之前先翻转 翻转后position=3 limit=3 capacity=1024
System.out.println(new String(buffer.array(),0,buffer.limit()));
结果是:hhh
不知道小伙伴有没有疑问,不是说之前的数据还在吗?它去哪了呢?
被遗忘了,这里还是要把clear()方法再次提出来,之前说过,它并不会将缓冲区中的数据清空,也就是说缓冲区中之前的数据还在。执行clear后我们可以像操作一个空的缓冲区
一样从索引0位置开始来操作这个缓冲区。但是之前的数据还存在,只是被遗忘了。如果上面我们没有执行byteBuffer.flip(); 那么,结果就会是:hhhdeworld
所以啊,flip()一定不要忘了。
mark() :标记当前position
reset() :恢复position到mark标记的位置
hasRemaining :判断缓冲区中是否含有元素
get() :从缓冲区中读取单个字节
get(byte[] dst) :批量读取多个字节到dst数组
get(int index) : 读取指定位置的字节(position不会改变)
put(byte b) :将单个字节写入缓冲区position位置
put(byte[] dst) :将多个字节从缓冲区position位置开始写入
put(int index,byte b) : 将指定字节写入缓冲区索引位置,不会移动position
public class BufferTest { public static void main(String[] args) { // 创建Buffer CharBuffer buff = CharBuffer.allocate(8); // ① System.out.println("capacity: " + buff.capacity()); System.out.println("limit: " + buff.limit()); System.out.println("position: " + buff.position()); // 放入元素 buff.put('a'); buff.put('b'); buff.put('c'); // ② System.out.println("加入三个元素后,position = " + buff.position()); // 调用flip()方法 buff.flip(); // ③ System.out.println("执行flip()后,limit = " + buff.limit()); System.out.println("position = " + buff.position()); // 取出第一个元素 System.out.println("第一个元素(position=0):" + buff.get()); // ④ System.out.println("取出一个元素后,position = " + buff.position()); // 调用clear方法 buff.clear(); // ⑤ System.out.println("执行clear()后,limit = " + buff.limit()); System.out.println("执行clear()后,position = " + buff.position()); System.out.println("执行clear()后,缓冲区内容并没有被清除:" + "第三个元素为:" + buff.get(2)); // ⑥ System.out.println("执行绝对读取后,position = " + buff.position()); } }
Buffer的创建成本很高,所以直接Buffer适用于长期生存的Buffer。
只有ByteBuffer提供allocateDirect()方法,所以只能在ByteBuffer级别上创建直接ByteBuffer,如果希望使用其他类型,将该Buffer转换成其他类型Buffer。
Channel
channel类似于传统流对象,区别:
channel可以直接将指定文件的部分或者全部映射成Buffer。
程序不能直接访问channel中的数据,channel只能和Buffer进行交互。
所有的channel都不应该通过构造器直接创建,而是通过传统节点InputStream、outPutstream的getChannel()方法返回对应的channel,不同的节点流获得的channel也不一样。
channel中最常用的三类方法map() , read() , write() 。map()用于将数据映射成ByteBuffer,另外两个有一系列重载,用于对Buffer读写数据。
将FileChannel的全部数据映射成ByteBuffer:
public class FileChannelTest { public static void main(String[] args) { File f = new File("FileChannelTest.java"); try( // 创建FileInputStream,以该文件输入流创建FileChannel FileChannel inChannel = new FileInputStream(f).getChannel(); // 以文件输出流创建FileBuffer,用以控制输出 FileChannel outChannel = new FileOutputStream("a.txt") .getChannel()) { // 将FileChannel里的全部数据映射成ByteBuffer MappedByteBuffer buffer = inChannel.map(FileChannel .MapMode.READ_ONLY , 0 , f.length()); // ① // 使用GBK的字符集来创建解码器 Charset charset = Charset.forName("GBK"); // 直接将buffer里的数据全部输出 outChannel.write(buffer); // ② // 再次调用buffer的clear()方法,复原limit、position的位置 buffer.clear(); // 创建解码器(CharsetDecoder)对象 CharsetDecoder decoder = charset.newDecoder(); // 使用解码器将ByteBuffer转换成CharBuffer CharBuffer charBuffer = decoder.decode(buffer); // CharBuffer的toString方法可以获取对应的字符串 System.out.println(charBuffer); } catch (IOException ex) { ex.printStackTrace(); } } }
FileInputStream获取的 channel只能读,FileOutputStream获取的 channel只能写。RandomAccessFile中也包含getChannel方法,他是只读的还是读写的,取决于RandomAccessFile打开文件的模式。
public class RandomFileChannelTest { public static void main(String[] args) throws IOException { File f = new File("a.txt"); try( // 创建一个RandomAccessFile对象 RandomAccessFile raf = new RandomAccessFile(f, "rw"); // 获取RandomAccessFile对应的Channel FileChannel randomChannel = raf.getChannel()) { // 将Channel中所有数据映射成ByteBuffer ByteBuffer buffer = randomChannel.map(FileChannel .MapMode.READ_ONLY, 0 , f.length()); // 把Channel的记录指针移动到最后 randomChannel.position(f.length()); // 将buffer中所有数据输出 randomChannel.write(buffer); } } }
使用Channel和Buffer使用传统的IO的多次获取数据的方式:
public class ReadFile { public static void main(String[] args) throws IOException { try( // 创建文件输入流 FileInputStream fis = new FileInputStream("ReadFile.java"); // 创建一个FileChannel FileChannel fcin = fis.getChannel()) { // 定义一个ByteBuffer对象,用于重复取水 ByteBuffer bbuff = ByteBuffer.allocate(256); // 将FileChannel中数据放入ByteBuffer中 while( fcin.read(bbuff) != -1 ) { // 锁定Buffer的空白区 bbuff.flip(); // 创建Charset对象 Charset charset = Charset.forName("GBK"); // 创建解码器(CharsetDecoder)对象 CharsetDecoder decoder = charset.newDecoder(); // 将ByteBuffer的内容转码 CharBuffer cbuff = decoder.decode(bbuff); System.out.print(cbuff); // 将Buffer初始化,为下一次读取数据做准备 bbuff.clear(); } } } }
字符集和Charset
Java默认采用Unicode字符集。JDK1.4提供了Charset来处理字节序列和字符序列之间的转换关系。该类提供了创建解码器和编码器的方法。
获取JDK支持的全部字符集:
public class CharsetTest { public static void main(String[] args) { // 获取Java支持的全部字符集 SortedMap<String,Charset> map = Charset.availableCharsets(); for (String alias : map.keySet()) { // 输出字符集的别名和对应的Charset对象 System.out.println(alias + "----->" + map.get(alias)); } } }
知道了字符集别名,可以调用Charset的forName方法创建对应的Charset对象,forName方法的参数是字符集别名。
获得了Charset对象之后,可以获得Charset的编码器和解码器,然后可以实现字节序列和字符序列的转换。
public class CharsetTransform { public static void main(String[] args) throws Exception { // 创建简体中文对应的Charset Charset cn = Charset.forName("GBK"); // 获取cn对象对应的编码器和解码器 CharsetEncoder cnEncoder = cn.newEncoder(); CharsetDecoder cnDecoder = cn.newDecoder(); // 创建一个CharBuffer对象 CharBuffer cbuff = CharBuffer.allocate(8); cbuff.put('孙'); cbuff.put('悟'); cbuff.put('空'); cbuff.flip(); // 将CharBuffer中的字符序列转换成字节序列 ByteBuffer bbuff = cnEncoder.encode(cbuff); // 循环访问ByteBuffer中的每个字节 for (int i = 0; i < bbuff.capacity() ; i++) { System.out.print(bbuff.get(i) + " "); } // 将ByteBuffer的数据解码成字符序列 System.out.println("\n" + cnDecoder.decode(bbuff)); } }
Charset本身也提供了编码解码方法,如果仅需编码解码操作,可以直接使用,不必创建编码器和解码器对象。
String的getBytes方法也是使用指定字符集将字符串转换成字节序列。
文件锁
如果多个程序需要并发修改同一个文件,程序需要某种机制来进行通信,使用文件锁可以有效地阻止多个进程并发修改同一个文件。
文件锁控制文件的全部或部分字节的访问。在NIO中Java提供FileLock来支持文件锁定功能。
lock():对文件从position开始,长度为size的内容加锁,阻塞。
tryLock():非阻塞。
当穿的shared参数是true时,表示这是共享锁,允许多个进程读取文件,但阻止其他进程获得对该文件的排它锁。
直接使用lock() tryLock()获取文件锁就是排它锁。
public class FileLockTest { public static void main(String[] args) throws Exception { try( // 使用FileOutputStream获取FileChannel FileChannel channel = new FileOutputStream("a.txt") .getChannel()) { // 使用非阻塞式方式对指定文件加锁 FileLock lock = channel.tryLock(); // 程序暂停10s Thread.sleep(10000); // 释放锁 lock.release(); } } }
NIO.2
Java7 NIO.2对NIO进行了重大改进,主要包括:
提供了全文见IO和文件系统访问支持。
基于异步的Channel的IO。
Path、Paths、Files
Path接口代表和平台无关的平台路径。
public class PathTest { public static void main(String[] args) throws Exception { // 以当前路径来创建Path对象 Path path = Paths.get("."); System.out.println("path里包含的路径数量:" + path.getNameCount()); System.out.println("path的根路径:" + path.getRoot()); // 获取path对应的绝对路径。 Path absolutePath = path.toAbsolutePath(); System.out.println(absolutePath); // 获取绝对路径的根路径 System.out.println("absolutePath的根路径:" + absolutePath.getRoot()); // 获取绝对路径所包含的路径数量 System.out.println("absolutePath里包含的路径数量:" + absolutePath.getNameCount()); System.out.println(absolutePath.getName(3)); // 以多个String来构建Path对象 Path path2 = Paths.get("g:" , "publish" , "codes"); System.out.println(path2); } }
Files是一个操作文件的工具类:
public class FilesTest { public static void main(String[] args) throws Exception { // 复制文件 Files.copy(Paths.get("FilesTest.java") , new FileOutputStream("a.txt")); // 判断FilesTest.java文件是否为隐藏文件 System.out.println("FilesTest.java是否为隐藏文件:" + Files.isHidden(Paths.get("FilesTest.java"))); // 一次性读取FilesTest.java文件的所有行 List<String> lines = Files.readAllLines(Paths .get("FilesTest.java"), Charset.forName("gbk")); System.out.println(lines); // 判断指定文件的大小 System.out.println("FilesTest.java的大小为:" + Files.size(Paths.get("FilesTest.java"))); List<String> poem = new ArrayList<>(); poem.add("水晶潭底银鱼跃"); poem.add("清徐风中碧竿横"); // 直接将多个字符串内容写入指定文件中 Files.write(Paths.get("pome.txt") , poem , Charset.forName("gbk")); // 使用Java 8新增的Stream API列出当前目录下所有文件和子目录 Files.list(Paths.get(".")).forEach(path -> System.out.println(path)); // 使用Java 8新增的Stream API读取文件内容 Files.lines(Paths.get("FilesTest.java") , Charset.forName("gbk")) .forEach(line -> System.out.println(line)); FileStore cStore = Files.getFileStore(Paths.get("C:")); // 判断C盘的总空间,可用空间 System.out.println("C:共有空间:" + cStore.getTotalSpace()); System.out.println("C:可用空间:" + cStore.getUsableSpace()); } }
使用FileVisitor遍历文件和目录:
FileVisitor代表一个文件访问器,
public class FileVisitorTest { public static void main(String[] args) throws Exception { // 遍历g:\publish\codes\15目录下的所有文件和子目录 Files.walkFileTree(Paths.get("D:", "idea_project", "mybootbill" /*, "15"*/) , new SimpleFileVisitor<Path>() { // 访问文件时候触发该方法 @Override public FileVisitResult visitFile(Path file , BasicFileAttributes attrs) throws IOException { System.out.println("正在访问" + file + "文件"); // 找到了FileInputStreamTest.java文件 if (file.endsWith("D:\\idea_project\\mybootbill\\src\\main\\java\\com\\jiangwenzhang\\mybootbill\\learn\\FileIO\\NIO\\FileVisitorTest.java")) { System.out.println("--已经找到目标文件--"); return FileVisitResult.TERMINATE; } return FileVisitResult.CONTINUE; } // 开始访问目录时触发该方法 @Override public FileVisitResult preVisitDirectory(Path dir , BasicFileAttributes attrs) throws IOException { System.out.println("正在访问:" + dir + " 路径"); return FileVisitResult.CONTINUE; } }); } }

使用WatchService监控文件变化
以前的Java中,需要监控文件变化,可以考虑启动一个后台线程,每隔一段时间遍历一次指定目录,如果发现遍历结果和上次不同则认为文件发生了变化。
WatchService
public class WatchServiceTest { public static void main(String[] args) throws Exception { // 获取文件系统的WatchService对象 WatchService watchService = FileSystems.getDefault() .newWatchService(); // 为C:盘根路径注册监听 Paths.get("C:/").register(watchService , StandardWatchEventKinds.ENTRY_CREATE , StandardWatchEventKinds.ENTRY_MODIFY , StandardWatchEventKinds.ENTRY_DELETE); while(true) { // 获取下一个文件改动事件 WatchKey key = watchService.take(); //① for (WatchEvent<?> event : key.pollEvents()) { System.out.println(event.context() +" 文件发生了 " + event.kind()+ "事件!"); } // 重设WatchKey boolean valid = key.reset(); // 如果重设失败,退出监听 if (!valid) { break; } } } }
启动项目后,在C盘根目录新建文件夹,然后删除文件夹
访问文件属性
NIO.2中提供了大量工具类,可以简单的读取修改文件属性
public class AttributeViewTest { public static void main(String[] args) throws Exception { // 获取将要操作的文件 Path testPath = Paths.get("AttributeViewTest.java"); // 获取访问基本属性的BasicFileAttributeView BasicFileAttributeView basicView = Files.getFileAttributeView( testPath , BasicFileAttributeView.class); // 获取访问基本属性的BasicFileAttributes BasicFileAttributes basicAttribs = basicView.readAttributes(); // 访问文件的基本属性 System.out.println("创建时间:" + new Date(basicAttribs .creationTime().toMillis())); System.out.println("最后访问时间:" + new Date(basicAttribs .lastAccessTime().toMillis())); System.out.println("最后修改时间:" + new Date(basicAttribs .lastModifiedTime().toMillis())); System.out.println("文件大小:" + basicAttribs.size()); // 获取访问文件属主信息的FileOwnerAttributeView FileOwnerAttributeView ownerView = Files.getFileAttributeView( testPath, FileOwnerAttributeView.class); // 获取该文件所属的用户 System.out.println(ownerView.getOwner()); // 获取系统中guest对应的用户 UserPrincipal user = FileSystems.getDefault() .getUserPrincipalLookupService() .lookupPrincipalByName("guest"); // 修改用户 ownerView.setOwner(user); // 获取访问自定义属性的FileOwnerAttributeView UserDefinedFileAttributeView userView = Files.getFileAttributeView( testPath, UserDefinedFileAttributeView.class); List<String> attrNames = userView.list(); // 遍历所有的自定义属性 for (String name : attrNames) { ByteBuffer buf = ByteBuffer.allocate(userView.size(name)); userView.read(name, buf); buf.flip(); String value = Charset.defaultCharset().decode(buf).toString(); System.out.println(name + "--->" + value) ; } // 添加一个自定义属性 userView.write("发行者", Charset.defaultCharset() .encode("疯狂Java联盟")); // 获取访问DOS属性的DosFileAttributeView DosFileAttributeView dosView = Files.getFileAttributeView(testPath , DosFileAttributeView.class); // 将文件设置隐藏、只读 dosView.setHidden(true); dosView.setReadOnly(true); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号