
Executors源码之线程池
Executors框架结构图

几种线程池的构造方法:
/** * Creates a thread pool that reuses a fixed number of threads * operating off a shared unbounded queue. At any point, at most * {@code nThreads} threads will be active processing tasks. * If additional tasks are submitted when all threads are active, * they will wait in the queue until a thread is available. * If any thread terminates due to a failure during execution * prior to shutdown, a new one will take its place if needed to * execute subsequent tasks. The threads in the pool will exist * until it is explicitly {@link ExecutorService#shutdown shutdown}. * * @param nThreads the number of threads in the pool * @return the newly created thread pool * @throws IllegalArgumentException if {@code nThreads <= 0} */ public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } /** * Creates a thread pool that maintains enough threads to support * the given parallelism level, and may use multiple queues to * reduce contention. The parallelism level corresponds to the * maximum number of threads actively engaged in, or available to * engage in, task processing. The actual number of threads may * grow and shrink dynamically. A work-stealing pool makes no * guarantees about the order in which submitted tasks are * executed. * * @param parallelism the targeted parallelism level * @return the newly created thread pool * @throws IllegalArgumentException if {@code parallelism <= 0} * @since 1.8 */ public static ExecutorService newWorkStealingPool(int parallelism) { return new ForkJoinPool (parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); } /** * Creates a work-stealing thread pool using all * {@link Runtime#availableProcessors available processors} * as its target parallelism level. * @return the newly created thread pool * @see #newWorkStealingPool(int) * @since 1.8 */ public static ExecutorService newWorkStealingPool() { return new ForkJoinPool (Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); } /** * Creates a thread pool that reuses a fixed number of threads * operating off a shared unbounded queue, using the provided * ThreadFactory to create new threads when needed. At any point, * at most {@code nThreads} threads will be active processing * tasks. If additional tasks are submitted when all threads are * active, they will wait in the queue until a thread is * available. If any thread terminates due to a failure during * execution prior to shutdown, a new one will take its place if * needed to execute subsequent tasks. The threads in the pool will * exist until it is explicitly {@link ExecutorService#shutdown * shutdown}. * * @param nThreads the number of threads in the pool * @param threadFactory the factory to use when creating new threads * @return the newly created thread pool * @throws NullPointerException if threadFactory is null * @throws IllegalArgumentException if {@code nThreads <= 0} */ public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory); } /** * Creates an Executor that uses a single worker thread operating * off an unbounded queue. (Note however that if this single * thread terminates due to a failure during execution prior to * shutdown, a new one will take its place if needed to execute * subsequent tasks.) Tasks are guaranteed to execute * sequentially, and no more than one task will be active at any * given time. Unlike the otherwise equivalent * {@code newFixedThreadPool(1)} the returned executor is * guaranteed not to be reconfigurable to use additional threads. * * @return the newly created single-threaded Executor */ public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } /** * Creates an Executor that uses a single worker thread operating * off an unbounded queue, and uses the provided ThreadFactory to * create a new thread when needed. Unlike the otherwise * equivalent {@code newFixedThreadPool(1, threadFactory)} the * returned executor is guaranteed not to be reconfigurable to use * additional threads. * * @param threadFactory the factory to use when creating new * threads * * @return the newly created single-threaded Executor * @throws NullPointerException if threadFactory is null */ public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); } /** * Creates a thread pool that creates new threads as needed, but * will reuse previously constructed threads when they are * available. These pools will typically improve the performance * of programs that execute many short-lived asynchronous tasks. * Calls to {@code execute} will reuse previously constructed * threads if available. If no existing thread is available, a new * thread will be created and added to the pool. Threads that have * not been used for sixty seconds are terminated and removed from * the cache. Thus, a pool that remains idle for long enough will * not consume any resources. Note that pools with similar * properties but different details (for example, timeout parameters) * may be created using {@link ThreadPoolExecutor} constructors. * * @return the newly created thread pool */ public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); } /** * Creates a thread pool that creates new threads as needed, but * will reuse previously constructed threads when they are * available, and uses the provided * ThreadFactory to create new threads when needed. * @param threadFactory the factory to use when creating new threads * @return the newly created thread pool * @throws NullPointerException if threadFactory is null */ public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), threadFactory); }
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个可定期或者延时执行任务的定长线程池,支持定时及周期性任务执行。
newCachedThreadPool 创建一个可缓存线程池,线程池的线程数量不确定,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
四种线程池都是创建了ThreadPollExecutor对象,只是传递的参数不一样而已,观察传入的workQueue 都是默认,即最大可添加Integer.MAX_VALUE个任务,这也就是阿里巴巴java开发规范禁止直接使用java提供的默认线程池的原因了
newWorkStealingPool适合使用在很耗时的操作,但是newWorkStealingPool不是ThreadPoolExecutor的扩展
ThreadPoolExecutor构造参数
int corePoolSize, 核心线程大小
int maximumPoolSize,最大线程大小
long keepAliveTime, 超过corePoolSize的线程多久不活动被销毁时间
TimeUnit unit,时间单位
BlockingQueue<Runnable> workQueue 任务队列
ThreadFactory threadFactory 线程池工厂
RejectedExecutionHandler handler 拒绝策略
其中任务队列:
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列
DelayQueue: 一个使用优先级队列实现的无界阻塞队列
SynchronousQueue: 一个不存储元素的阻塞队列(常用)
LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列
线程池I的执行流程
当线程池小于corePoolSize时,新提交任务将创建一个新线程执行任务,即使此时线程池中存在空闲线程。
当线程池达到corePoolSize时,新提交任务将被放入workQueue中,等待线程池中任务调度执行
当workQueue已满,且maximumPoolSize>corePoolSize时,新提交任务会创建新线程执行任务
当提交任务数超过maximumPoolSize时,新提交任务由RejectedExecutionHandler处理
当线程池中超过corePoolSize线程,空闲时间达到keepAliveTime时,释放空闲线程
当设置allowCoreThreadTimeOut(true)时,该参数默认false,线程池中corePoolSize线程空闲时间达到keepAliveTime也将关闭
不同的使用场景
newFixedThreadPool:
- 底层:返回ThreadPoolExecutor实例,接收参数为所设定线程数量n,corePoolSize和maximumPoolSize均为n;keepAliveTime为0L;时间单位TimeUnit.MILLISECONDS;WorkQueue为:new LinkedBlockingQueue<Runnable>() 无界阻塞队列
- 通俗:创建可容纳固定数量线程的池子,每个线程的存活时间是无限的,当池子满了就不再添加线程了;如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:执行长期任务
newSingleThreadExecutor:
- 底层:FinalizableDelegatedExecutorService包装的ThreadPoolExecutor实例,corePoolSize为1;maximumPoolSize为1;keepAliveTime为0L;时间单位TimeUnit.MILLISECONDS;workQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
- 通俗:创建只有一个线程的线程池,当该线程正繁忙时,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:按顺序执行任务的场景
newCachedThreadPool:
- 底层:返回ThreadPoolExecutor实例,corePoolSize为0;maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为60L;时间单位TimeUnit.SECONDS;workQueue为SynchronousQueue(同步队列)
- 通俗:当有新任务到来,则插入到SynchronousQueue中,由于SynchronousQueue是同步队列,因此会在池中寻找可用线程来执行,若有可以线程则执行,若没有可用线程则创建一个线程来执行该任务;若池中线程空闲时间超过指定时间,则该线程会被销毁。
- 适用:执行很多短期的异步任务
NewScheduledThreadPool:
- 底层:创建ScheduledThreadPoolExecutor实例,该对象继承了ThreadPoolExecutor,corePoolSize为传递来的参数,maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为0;时间单位TimeUnit.NANOSECONDS;workQueue为:new DelayedWorkQueue() 一个按超时时间升序排序的队列
- 通俗:创建一个固定大小的线程池,线程池内线程存活时间无限制,线程池可以支持定时及周期性任务执行,如果所有线程均处于繁忙状态,对于新任务会进入DelayedWorkQueue队列中,这是一种按照超时时间排序的队列结构
- 适用:执行周期性任务
注:
- 一般如果线程池任务队列采用LinkedBlockingQueue队列的话,那么不会拒绝任何任务(因为其大小为Integer.MAX_VALUE),这种情况下,ThreadPoolExecutor最多仅会按照最小线程数corePoolSize来创建线程,也就是说线程池大小被忽略了。
- 如果线程池任务队列采用ArrayBlockingQueue队列,初始化设置了最大队列数。那么ThreadPoolExecutor的maximumPoolSize才会生效,那么ThreadPoolExecutor的maximumPoolSize才会生效会采用新的算法处理任务,
- 例如假定线程池的最小线程数为4,最大为8,ArrayBlockingQueue最大为10。随着任务到达并被放到队列中,线程池中最多运行4个线程(即核心线程数)直到队列完全填满,也就是说等待状态的任务小于等于10,ThreadPoolExecutor也只会利用4个核心线程线程处理任务。
- 如果队列已满,而又有新任务进来,此时才会启动一个新线程,这里不会因为队列已满而拒接该任务,相反会启动一个新线程。新线程会运行队列中的第一个任务,为新来的任务腾出空间。如果线程数已经等于最大线程数,任务队列也已经满了,则线程池会拒绝这个任务,默认拒绝策略是抛出异常。
- 这个算法背的理念是:该池大部分时间仅使用核心线程(4个),即使有适量的任务在队列中等待运行。这时线程池就可以用作节流阀。如果挤压的请求变得非常多,这时该池就会尝试运行更多的线程来清理;这时第二个节流阀—最大线程数就起作用了。
返回类ExecutorService extends Executor
new类ThreadPoolExecutor extends AbstractExecutorService implements ExecutorService extends Executor
超负载:拒绝策略
任务数量超过系统承载能力,就需要用到拒绝策略
默认策略:抛出异常,组织系统正常工作
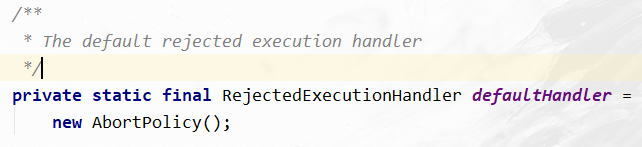
JDK内置的四种拒绝策略
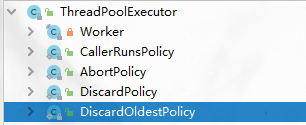
运行未被丢弃的任务;
抛出异常;
默默丢弃无法处理的任务;
丢弃最老的请求;
优化线程池线程数量
考虑CPU和内存大小等因素,公式:

程序中可以获取CPU数量,也可以在配置中,然后计算并传入

