
windows/linux 页面编码区别导致 python 乱码
http://blog.csdn.net/haiross/article/details/36189103 可以先看下这篇文章。。写的比较用心和详细并且高深。。我只是记流水账的。
直到今天我才注意到 shell 采用不同编码会导致这么蛋疼的问题。。这半天时间算是认栽了吧。。
首先,Windows的默认编码为GBK,Linux的默认编码为UTF-8。看图:
这个是 Linux shell 的活动代码页编码:
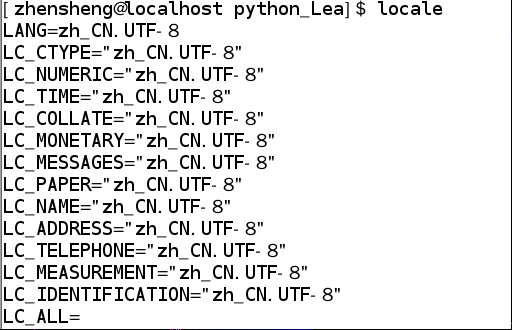
这个是 windows powershell 的:

936 既是 GBK。
而在 Scrapy 中抓取页面然后提取出的信息是以 unicode字符串 的形式保存下来的。在python中print即可正常显示文字。但在 powershell 中会出以下问题:

其实,在这里的问题是,scrapy使用unicode类型封装了gbk/utf-8转码后的字符串,导致无法正常解码。这里应该做的,就是去掉unicode类型,此时,codecs.unicode_escape_encode(str)则满足要求
注意,unicode类型转换为其他类型(使用a.encode("utf-8/gbk"))时,则会将该字符串在编码一边,显然不可行。

这里我强调下,unicode是字符集, utf-8 和 gbk 是编码集。至于这俩有什么不同,可以这么说:unicode 定义了所有的字符(目前看来是的),用来展示给你看的,而编码集utf-8是一种字符集的实现,用来面向计算机的,主要用来存储为字节,以及网络传输的。
附:Python 编码使用
# 定义时,使用 u 前缀表示 unicode 类型。
# 其他情况下,默认是 utf-8/gbk 等编码: powershell 下默认为gbk编码。linux终端下默认为utf-8,文件看其编码属性
# 输出时,需要什么编码, encode 成什么编码就OK了。unicoe编码不能直接输出
# 但是,在 print [u'\u6211'] 数组时,输出不会有改变。猜测原因是,输出数组时,print并不对其做处理,只是原样输出,而输出string时,会对其进行 encode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号