Luogu P6269 [COCI2016-2017#1] Vještica 题解
题目描述
Matej 面临着一个难题。在此之前,我们必须熟悉一种称作前缀树(trie)的数据结构。前缀树以前缀的方式,储存单词:
- 前缀树的每一条边都用英文字母表中的字母表示。
- 前缀树的根节点表示空前缀。
- 前缀树的每个其他节点都表示一个非空前缀。依次连接根节点至该节点路径上所标有的字母,即可得到该前缀。
- 不存在从一个节点出发的、标有相同字母的两条边。
例如,这棵前缀树储存了 A,to,tea,ted,ten,i,in,inn:
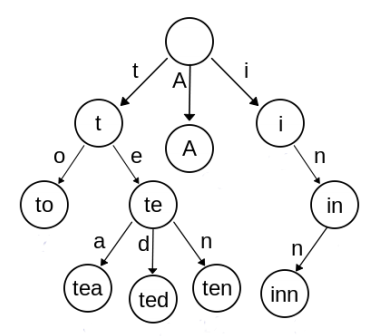
现在,Matej 获得了 nn 个单词,并可以将其中的一些单词重组。例如 abc 可以重组为 acb,bac,bca,cab,cba 。请你计算,将一些单词重组后,储存这些单词的前缀树节点数的最小值。
输入格式
第一行一个整数 。
接下来 行,每行一个字符串,表示 Matej 获得的单词。
输出格式
一行,一个整数,表示将一些单词重组后,储存这些单词的前缀树节点数的最小值。
输入输出样例
1 输入
3 a ab abc
1 输出
4
2 输入
3 a ab c
2 输出
4
3 输入
4 baab abab aabb bbaa
3 输出
5
说明/提示
样例 3 解释
所有单词均可以重组为 aabb。显然,前缀树最少的节点数应为 55(包含了表示空前缀的根节点)。
数据规模与约定
对于 的数据,保证 。
所有单词的长度和不超过 ,且只包含小写字母。
说明
题目译自 COCI2016-2017 CONTEST #1 T6 Vještica。
题目解析
首先,可以贪心,可以搜索,并且不需要输出路径,考虑DP。
,这么小肯定是状压DP。
令 代表状态为 时的答案,这里把 看做一个集合。
首先考虑的是 只有两项的时候,不难发现, ,其中 表示 的最长公共字串。
拓展一下,得出
这里需要注意一下循环的范围。
最后注意一下要把结果加上 ,因为还有一个空节点。
代码:
#include<cstdio> //luogu P6289 #include<cstring> #include<iostream> #define maxn 70039 using namespace std; inline int read(){ char c=getchar(); int sum=0,flag=0; while((c<'0'||c>'9')&&c!='-') c=getchar(); if(c=='-') c=getchar(),flag=1; while('0'<=c&&c<='9'){ sum=(sum<<1)+(sum<<3)+(c^48); c=getchar(); } if(flag) return -sum; return sum; } int f[maxn],pre[maxn][39]; int sum[39][39]; char s[100039]; int n,len; int main(){ cin>>n; memset(f,0x3f,sizeof(f)); memset(pre,0x3f,sizeof(pre)); for(int i=1;i<=n;i++){ cin>>s; len=strlen(s); for(int j=0;j<len;j++) sum[i][s[j]-'a'+1]++; sum[i][0]=strlen(s); f[1<<i-1]=sum[i][0]; } for(int i=1;i<(1<<n);i++){ for(int j=1;j<=n;j++){ if((i>>j-1)&1){ for(int k=1;k<=26;k++) pre[i][k]=min(pre[i][k],sum[j][k]); } } pre[i][0]=0; for(int k=1;k<=26;k++) pre[i][0]+=pre[i][k]; for(int j=(i-1)&i;j;j=(j-1)&i) f[i]=min(f[i],f[i^j]+f[j]-pre[i][0]); } printf("%d",f[(1<<n)-1]+1); return 0; }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具