
3)leveldb特性笔记
https://wiesen.github.io/post/leveldb-introduction/
1)写放大
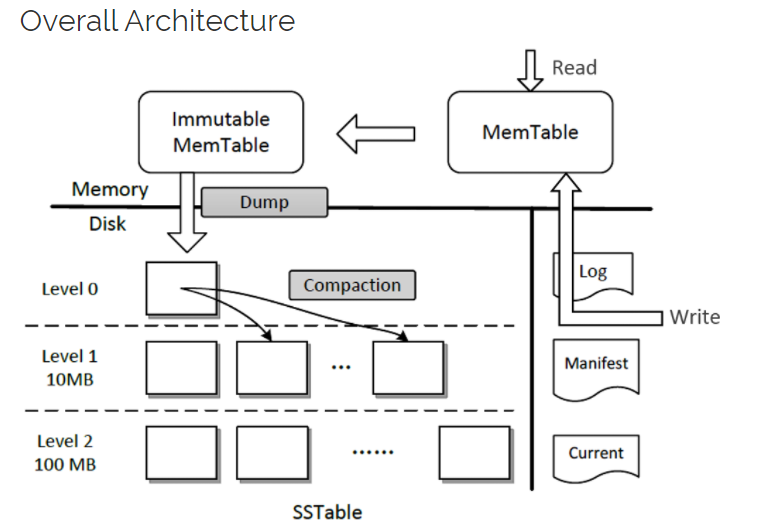
Compaction:当某一层的总大小超过了它的限制时,合并线程就会从该层选择一个文件将其和下一层的所有重叠的文件进行归并排序产生一个新的 SSTable 文件放在下一层中
当把 i-1 层中的一个文件合并到 i 层中时,LevelDB 需要读取 i 层中的文件的数量多达10个,排序后再将他们写回到 i 层中去。所以这个时候的写放大是10
对于一个很大的数据集,生成一个新的 table 文件可能会导致 L0-L6 中相邻层之间发生合并操作,这个时候的写放大就是50(L1-L6中每一层是10)。
2)读放大
a)查找一个 key-value 对时,LevelDB 可能需要在多个层中去查找。在最坏的情况下,LevelDB 在 L0 中需要查找8个文件,在 L1-L6 每层中需要查找1个文件,累计就需要查找14个文件
b)在一个 SSTable 文件中查找一个 key-value 对时,LevelDB 需要读取该文件的多个元数据块。所以实际读取的数据量应该是:index block + bloom-filter blocks + data block。
例如,当查找 1KB 的 key-value 对时,LevelDB 需要读取 16KB 的 index block,4KB的 bloom-filter block 和 4KB 的 data block,总共要读取 24 KB 的数据。在最差的情况下需要读取 14 个 SSTable 文件,所以这个时候的读放大就是 24*14=336。较小的 key-value 对会带来更高的读放大
3)bloomFilter
https://izualzhy.cn/leveldb-bloom-filter
a)算法
4个hash函数,映射到值空间4个字段都为1


