

推荐系统相关数据集下载
这些数据集在可作为基准的推荐系统中非常流行。
- Douban:http://socialcomputing.asu.edu/datasets/Douban 这是一个匿名的豆瓣数据集,包含129,490个独立用户和58,541个独立电影条目。
- Epinions:http://www.trustlet.org/epinions.html Epinions是一个人们可以评论产品的网站。
- Flixster:http://socialcomputing.asu.edu/datasets/Flixster Flixster是一个社交电影网站,允许用户分享电影评级,发现新电影,并与其他有类似电影品味的人见面。
- CiaoDVD:https://www.librec.net/datasets.html CiaoDVD是从dvd.ciao.co.中抓取的2013年12月英国网站整个dvd类别的数据集。
- MACLab:http://mac.citi.sinica.edu.tw/LJ#.VRGYfOHlZ40 这个项目的目的是研究用户的情绪和音乐情绪。
- DEAPdataset:http://www.eecs.qmul.ac.uk/mmv/datasets/deap/index.html 使用脑电图、生理和视频信号进行情绪分析的数据集。
- MyPersonalityDataset:http://mypersonality.org/wiki/doku.php myPersonality是一个很受欢迎的Facebook应用程序,它允许用户进行真实的心理测试,并允许我们(在征得同意的情况下)记录他们的心理和Facebook资料。目前,我们的数据库包含超过600万个测试结果,以及超过400万个Facebook个人简介。
- Bibsonomy:http://www.kde.cs.uni-kassel.de/bibsonomy/dumps 社交书签系统中的标签推荐。
- Delicious:http://www.dai-labor.de/en/competence_centers/irml/datasets/ plista新闻推荐数据集,美味可口。
- Movielens:https://grouplens.org/datasets/movielens/ 稳定的基准数据集。2000万个评分和46.5万个标签应用程序被13.8万用户应用于2.7万部电影。包括标签基因组数据,1100个标签的1200万个相关性得分。
- Jester:http://eigentaste.berkeley.edu/dataset/ 来自小丑在线笑话推荐系统的匿名评级。
- BookCrossing:http://www2.informatik.uni-freiburg.de/~cziegler/BX/ Book-Crossing数据集。
- LastFM:https://grouplens.org/datasets/hetrec-2011/ 来自1892个用户的92,800张艺术家录音。
- Wikipedia:https://en.wikipedia.org/wiki/Wikipedia:Database_download#English-language_Wikipedia 维基百科向感兴趣的用户提供所有可用内容的免费拷贝。这些数据库可用于镜像、个人使用、非正式备份、脱机使用或数据库查询。
- OpenStreetMap:http://planet.openstreetmap.org/planet/full-history/ 这里找到的文件是OpenStreetMap.org数据库的完整副本,包括编辑历史。这些都是在Open Data Commons Open Database License 1.0许可下发布的。
- PythonGitCode:https://github.com/lab41/hermes Hermes是Lab41对推荐系统的一次尝试。通过分析多种推荐系统算法在不同数据集上的性能,探讨了如何为新的应用选择推荐系统。
- Gist:https://gist.github.com/entaroadun/1653794 为机器学习推荐和评级的公共数据集。
- Yelp:https://www.yelp.com/dataset Yelp数据集是用于个人、教育和学术目的的业务、评论和用户数据的子集。可以在JSON和SQL文件中使用,在你学习如何制作移动应用程序时,可以使用它来教学生关于数据库、学习NLP或示例生产数据。
- AmazonReviews:http://jmcauley.ucsd.edu/data/amazon/ 该数据集包含来自Amazon的产品评论和元数据,包括1996年5月至2014年7月期间的1.428亿个评论。这个数据集包括评论(评级、文本、帮助投票)、产品元数据(描述、类别信息、价格、品牌和图像特性)和链接(也查看/购买图表)。
- CiteULike:http://www.citeulike.org/faq/data.adp CiteULike数据库对不同领域的研究人员都有潜在的用处。物理学家和计算机科学家对分析数据结构表示了兴趣,并经常要求提供数据集。以前,这是在一个特别的基础上完成的,它依赖于我们记住更新数据文件。现在,有一个自动的过程,每天晚上运行,生成一个快照摘要,说明用哪些标签发布了哪些文章。
- Taobao:https://tianchi.aliyun.com/datalab/dataSet.htm?spm=5176.100073.888.13.62f83f62aOlMEI&id=1 该数据集包含了匿名用户在“双十一”前后6个月的购物记录,以及表明他们是否重复购买的标签信息。由于隐私问题,数据采集存在偏差,因此该数据集的统计结果会与天猫的实际情况相背离。
下面是上述数据集的一些统计数据.
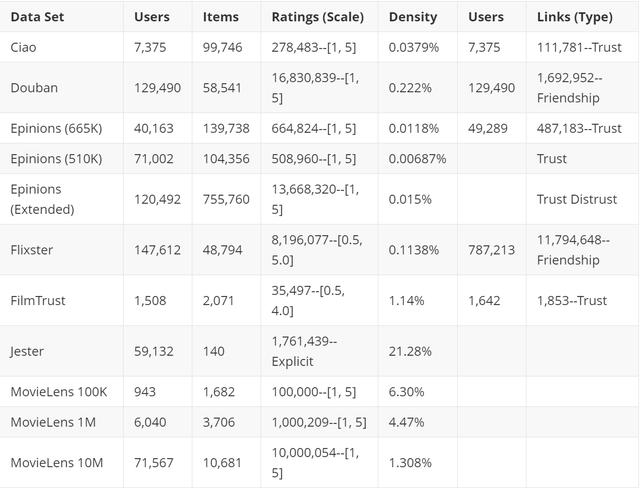
英文原文:https://github.com/daicoolb/RecommenderSystem-DataSet
