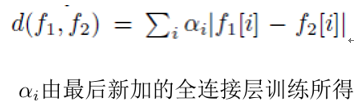FaceBook CVPR2014: DeepFace解读
DeepFace是Facebook在2014年的CVPR上提出来的,后续出现的DeepID和FaceNet也都体现DeepFace的身影,可以说DeepFace是CNN在人脸识别的奠基之作,目前深度学习在人脸识别中也取得了非常好的效果。下边介绍DeepFace的基本框架。
一、网络架构

DeepFace的架构并不复杂,层数也不深。网络架构由6个卷积层 + 2个全连接层构成。

二、从实现过程,理解网络
(一)图片的3D对齐
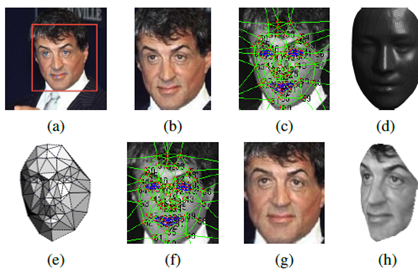
输入原始图片,讲过3D对齐后,使人脸的正面朝前(图g)

3D对齐技术可以将图像从2D空间,映射到3维空间,得到人脸特征3维空间的分布,进而可以得到人脸在2D空间下,各种角度的特征分布。
Recongnition任务中,正面照片的分辨效果最好,图g输出人脸的正面图片用来做识别的input,图h输出人脸在45度角下的2D图,用来展示3D对齐的在各个角度下的2D的输出样例。
(二)前3层采用传统的conv提取信息
通过3层共享权值的卷积,每一层在整张图片上,提取本层的特征(同一层内,提取的是同一维度上的特征,因为filter一样)


在这里,介绍下共享权重卷积和非共享权重卷积。
1、共享权重
1个卷积核,提取1个特征,卷积核在input图上滑动,提取不同区域的同1种特征(叫做卷积层的参数共享),不同的卷积核,在不同特征的维度上,对input进行特征提取。大部分我们看到的卷积都是这种结构。参数量少,计算速度快。
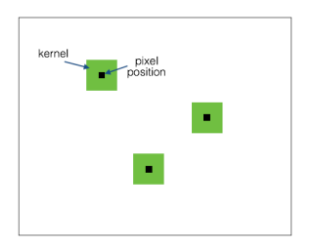
如果1个卷积核大小是“5*5*1”,一个图对应的参数是5*5*1, feature map上输出的是,不同部位,同一维度上的特征。
2、非共享权重( Local-Conv),也叫局部连接卷积
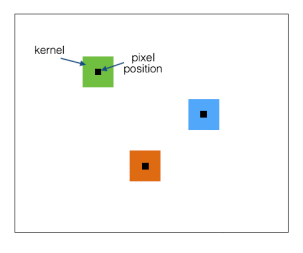
如果1个卷积核大小是“5*5*1”,则1个128*128大小的图上,会有124*124个这样的filter,对应的参数数量是124*124*5*5*1,参数量剧增。因为不同的filter提取的是不同维度上的特征,所以feature map上输出的是不同部位,不同维度上的特征。
这样做的理由是,因为input里面人脸经过了3D对齐和2D映射,输入的图片是矫正后的正面人脸,各特征点的position都固定下来了,人脸部不同位置(鼻子,嘴巴,....)的特征不同,用不同的filter来学习效果更好。
(三)后3层conv,采用局部连接层,提取不同维度上的特征。
后3层,采用Local-Conv,提人脸不同位置上的各种不同特征,因为Local-Conv参数量巨大,所以需要使用超大的数据库进行训练。DeepFace采用的是Facebook自己做的SFC数据集,有4030个人的440万张人脸数据。所以用在这里正好~


(四)过全连接层,获取图像全局信息
1、过卷积生成的feature map送入第7层,第7层为全连接层,可以感受到上一层传过来的图像的所有信息。
之所以人脸识别的各种架构里面,大部分都含有这一层,原因是,全连接层可以捕捉到人脸距离较远区域的特征之间的关联性。比如,眼睛的位置和形状,与嘴巴的位置和形状之间的关联性,这种关联性,可以contribute to最后一步的recognition score.
2. 在第7层对所有特征进行了L2归一化,使其值域落在【0,1】之间,以减弱图像对光照的敏感性.为什么归一化之后就可以减少图像对光照的敏感性?


我的是这样理解的,归一化之前,光照强的图像(如右图)对应的值高,比如左图中某一点a的像素值为100,左图上像素值最大的是200,右图的光线更强,与a点相对应的点a’像素值为110,右图上像素值最大的是220,经过归一化后,左图右图同一点的值,也就相同了。
(五)输出4030类的识别结果。
用softmax输出4030种人物的分类信息
三、网络特点
(1)提出了3D对齐
3D对齐和3D-2D映射在这里不敷述,paper中觉得这样做,对最后的准确率提升帮助较大。但是现在的网络,在没有采用3D对齐的前提下,也取得漂亮的score.
3D对齐这一块可以先放一放。
(2)局部卷积。
局部连接的思想,就跟上面分析的一样,比较好理解。至于这种方法在别的网路中work不work,后面paper看多了应该能有个更清楚的认识。
四、网络成绩
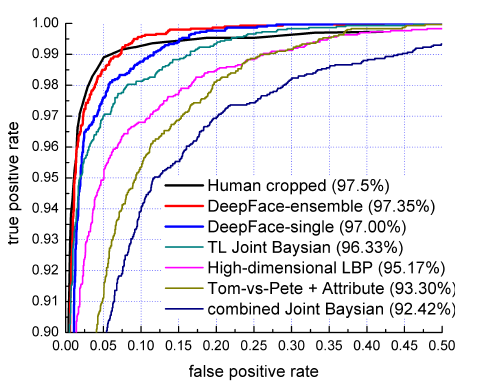
DeepFace在LFW数据集中进行人脸识别中取得了97.35%的好成绩,该成绩相对于传统方法中依靠人工显式的提取特征,再进行分类的method,识别准确性获得明显提高,再次证实了CNN在特征提取方面的威力,此外该成绩已经逼近人类在LFW数据集中97.5%的识别成绩,性能卓越。

五、特征度量
虽然网络的output是个4030维的分类结果,paper中还是提出了另外的度量2个图片相似性的方法。
(一)内积
文中直接计算两个经过归一化后的特征之间的内积来计算2个图像过backbone后的vector之间的距离,一开始有点不太懂,两个图片相同的话,内积是大还是小?感觉看内积大小分不出来2个图片相似性啊?
后来想了想,这样之所以work,是因为本网络的特殊性。过第7层的fc层后,输出的vector是个4096维的数据,网络架构中采用了relu激活,这4096维中有75%的数据是0,4096维的vector构成了1个稀疏向量。基于这样的前提,两个不同的图片,对应的不同位置上的0和非0元素相乘抵消,内积趋近于0,而相似的2个图片,由于0存在于2个vector相同的位置,非0元素也存在于2个vector相同的位置,0没有和非零元素相抵消,对应的值较大。这样就实现了图片相似性的区分。
Paper中提到的另外2个距离度量算法。
(二)X² similarity
按照下面公式乘就可以了,比较简单,没啥好说的

权重参数是由SVM学来的
(三)Siamese network孪生网络
当神经网络训练完成后,将其除了L8外的其他层复制为两份,分别输入两张人脸图像,得到特征后,先计算两个feature的绝对差值,然后将其输入给一个新的全连接层(注意不是原来的L8,其只有一个神经元)来进行二分类,判断两张人脸是否身份相同