
深度学习经典网络总结
深度学习经典网络总结
最近看的4篇经典深度学习的paper,总结一下。
一、AlexNet
(一)成绩
多伦多大学alex团队ILSVRC-2012冠军网络
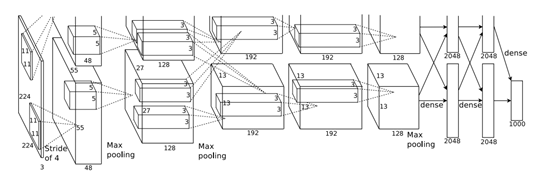
(二)网络结构
5层卷积 + 3层全连接
(三)网络特色
1、局部响应归一化(LRN:Local Response Normalization)
当前通道当前点的像素值/(相邻 通道数/2 的不同特征图上对应的同一点,像素值的平方和)
当该通道和邻近通道像素绝对值都比较大的时候,归一化后值变得更小。
采用这种方法,在ImageNet数据集1000分类的测试上,top-1错误率降低了 1.4%,top-5错误率降低了 1.2%(其他网络上发现这种方法好像没多少用处)
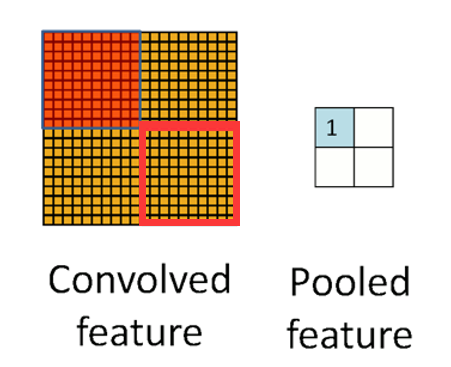
2. 重叠池化
(1)常规池化
(2)重叠池化
相邻池化窗口之间会有重叠区域
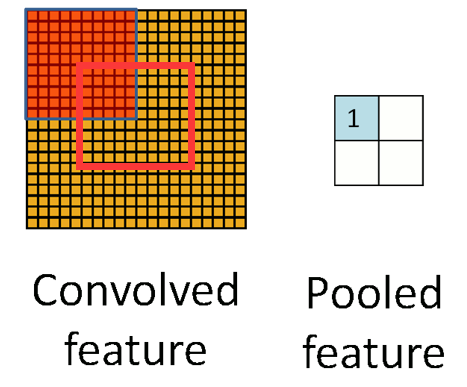
练过程中通常观察采用重叠池化的模型,发现它更难过拟合。
3.减少过拟合
(1)数据增强
在GPU训练模型时,用cpu 随机裁剪 + 翻转 + 旋转原始图像 + RGB替换,产生新的数据,GPU + CPU并行工作,没有占用额外的时间。
(2)采用dropout
随机忽略一部分神经元,(以0.5的概率对每个隐层神经元的输出设为0。那些“失活的”的神经元不再进行前向传播并且不参与反向传播)
思想是利用集成法,计算多个模型,综合考虑结果(MAX,MEAN,etc)。只不过实现方式在一个模型内部实现,而不是真的训练了多个模型。
二、VGG
Visual Geometry Group牛津大学计算机视觉组
(一)成绩
ILSVRC-2014亚军
1.单网络分类精度方面最优。
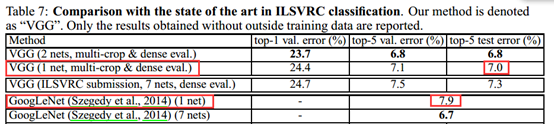
2.多网络( 融合了VGG16和VGG19两个模型,相比于融合了7个模型的googlenet仅仅落后0.1%)
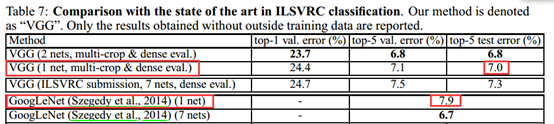
(二)网络结构
1.网络配置
评估有6个网络,层数依次加深
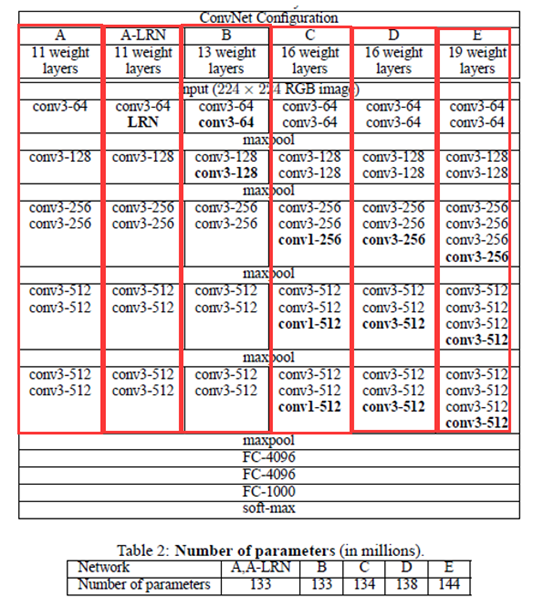
2.网络示例图

(三)网络特色
1.采用更小的卷积核,网络层数更深
VGG相比于AlexNet的改动在于,VGG采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)
VGG发现,同样感受野的情况下,小的conv filter优于具有大filter的网络,在网络B中进行实测,2个3*3的conv与 1个5 * 5的conv具有相同的感受野。
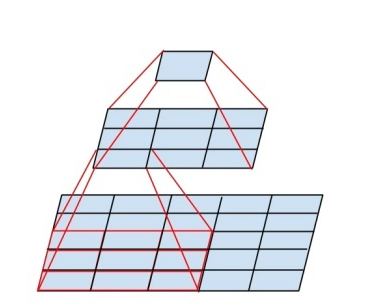
但是前者性能高于后者7%。堆积的小卷积核优于采用大的卷积核, 因为每过1个小的卷积核,后面接着一个RELU非线性激活层。这可以学习到更复杂的模式。 而且代价还比较小(参数更少5x5 > 2 * 3x3)
2.采用Network In Network1*1结构
传统网络一般是由:线性卷积池化层+全连接层堆叠起来。卷积层通过线性滤波器进行线性卷积运算,然后在接个非线性激活函数,传给下一层
NIN在原来的卷积层后面加一个1*1的卷积层,而不改变输出的size。每一个1*1卷积层后面都会跟上ReLU。所以,相当于网络变深了,可以学习到更复杂的模式.
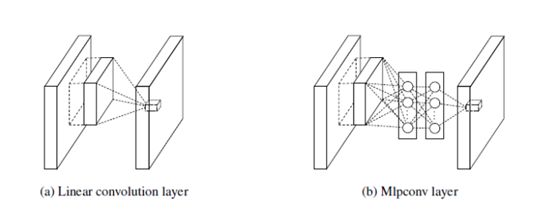
全连接层相当于1*1卷积层
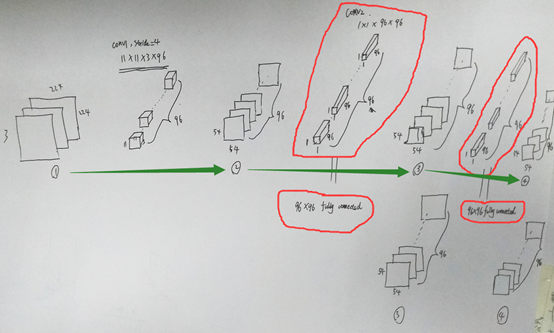
3. ps
(1)VGGNet的结构简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。验证了通过不断加深网络结构可以提升性能。
(2)A-LRN验证了局部均一化作用不大
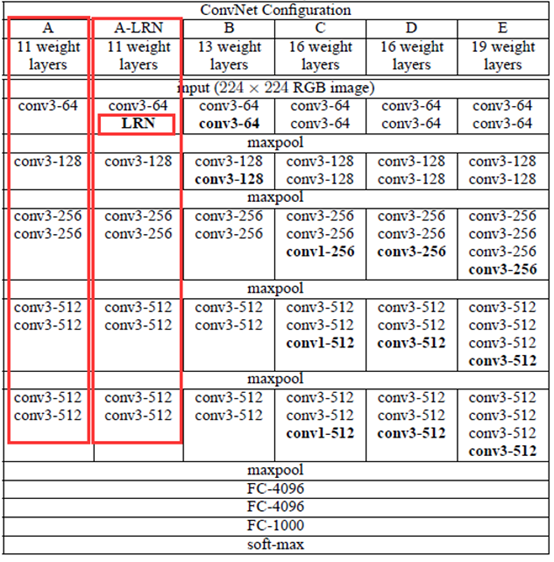
A与A_LRN网络测试结果。

(3)网络参数过多,计算量大(并不是小卷积核的锅,3个全连接层占据了80%的参数)
三、GoogleNet
(一)网络成绩
ILSVRC-2014冠军

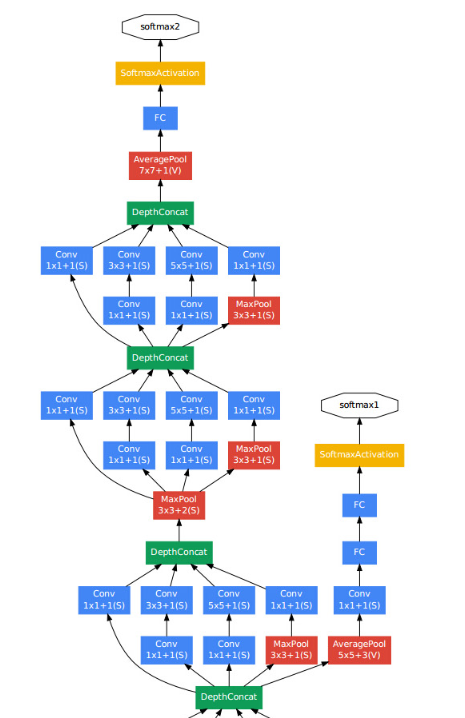
(二)网络结构

(三)网络特色
1. inception结构
采用不同大小的卷积核,意味着不同大小的感受野,将不同尺度特征的融合可以取得更好的学习效果。

2.shotcut直连
改善了梯度消失问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号