
K-匿名算法研究
12月的最后几天,研究了下k匿名算法,在这里总结下。
提出背景
Internet 技术、大容量存储技术的迅猛发 展以及数据共享范围的逐步扩大,数据的自动采集 和发布越来越频繁,信息共享较以前来得更为容易 和方便;但另一方面,以信息共享与数据挖掘为目的的数据发布过程中隐私泄露问题也日益突出,因此如何在实现信息共享的同时,有效地保护私有敏感信息不被泄漏就显得尤为重要。数据发布者在发布数据前需要对数据集进行敏感信息的保护处理工作,数据发布中隐私保护对象主要是用户敏感信息与个体间的关联关系,因此,破坏这种关联关系是数据发布过程隐私保护的主要研究问题。
传统处理办法
(一)匿名。
对姓名,身份证号等能表示一个用户的显示标识进行删除
弊端:攻击者可以通过用户的其他信息,例如生日、性别、年龄等从其他渠道获取的个人 信息进行链接,从而推断出用户的隐私数据。 如下图的表:

先引入2个概念
1.标识符(explicit identifiers):可以直接确定一个个体。如:id,姓名等。
2.准标识符集(quasi-identifler attribute set ):可以和外部表连接来识别个体的最小属性集,如表1中的 {省份,年纪,性别,邮编}。攻击者可以通过这4个属性,确定一个个体。
为了保护用户隐私,不让患者的患病信息泄露,在发布信息时,删去患者姓名,试图达到保护隐私的目的。但是攻击者手上还有选民登记表。攻击者根据准标识符进行链接,就可以推断出李青患有肺炎这一敏感信息。这就是链式攻击。
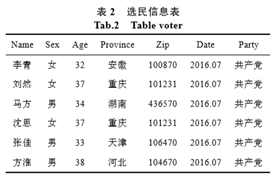
通过这个例子,我们也发现,使用删除标识符的方式发布数据无法真正阻止隐私泄露,攻击者可以通过链接攻击获取个体的隐私数据
(二)数据扰乱。
对初始数据进行扭曲、扰乱、随机化之后再进行挖掘,
弊端:尽管这种方法能够保证结果的整体统 计性,但一般是以破坏数据的真实性和完整性为代价。
(三)数据加密。
利用非对称加密机制形成交互计算的协议,实现无信息泄露的分布式安全计算,以支持分布式环境中隐私保持的挖掘工作,例如安全两方或多方计算问题,但该方法需要过多的计算资源。
K匿名的基本概念
为解决链接攻击所导致的隐私泄露问题,引入k-匿名 (k-anonymity) 方法。k-匿名通过概括(对数据进行更加概括、抽象的描述)和隐匿(不发布某些数据项)技术,发布精度较低的数据,使得同一个准标识符至少有k条记录,使观察者无法通过准标识符连接记录。
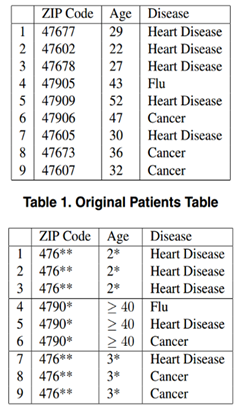
原表虽然隐去了姓名,但是攻击者通过邮编和年纪,依然可以定位一条记录,经过k匿名后,对邮编和年纪做以抽象,攻击者即使知道某一用户的具体邮编为47906,年龄47,也无法确定用户患哪一种病。上图的同一个准标识符{邮编,年纪}至少有3条记录,所以为3匿名模型。
k-anonymity模型的实施,使得观察者无法以高于1/k的置信度通过准标识符来识别用户。
K匿名算法实践
(一)泛化技术分类
K匿名算法按照泛化范围,可以分为全局算法和局部算法。
全局算法:在整个属性列上进行泛化,如把邮编最后3位数隐匿,这种泛化会带来很高的信息损失,因为原始数据表中的数据的分布不平均,存在一些有孤 立的数据,要想满足匿名化的条件,就要把整个数据表一遍又一遍的泛化,直到所有的 准标示符属性泛化之后得到的组合能够在相对应的泛化层次中找到,因此造成了数据表的泛化过度,产生不必要的泛化,信息失真度较大。为了解决这一问题,减少数据的损失量,学术界将研究目标全域重新编码算法转移到了局部重新编码算法。
局部算法:将同属性列中的元素泛化到不同的等级,在单个元组上对,准标示符属性值进行泛化处理的,它将同一个准标示符属性列之中,不同个体的属性值泛化到相对独立的不同泛化层次结构中,这样就不会造成数据表的过度泛化, 将匿名表中的数据损失量控制到最小。
减少了数据损失量。
(二)Datafly算法
算法实施:
1.对每个准标识符属性的取值个数进行统计,取出统计值最大的准标识符进行一个层级的泛化。
2.对泛化后的表格进行k匿名检测。
3.如果泛化后的数据表符合k匿名检测,则输出,如果不符合,goto 1
以下图为例:
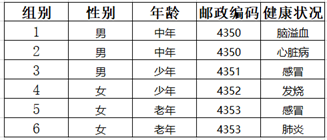
Step1:邮编属性个数为4,对其进行泛化
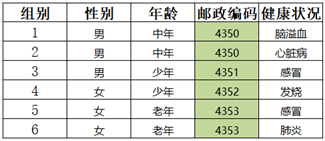
Step2:泛化结果如图所示,对其进行匿名检测,不符合匿名规则, goto 1
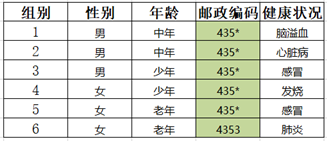
Step3:年龄属性个数为3,对其进行泛化
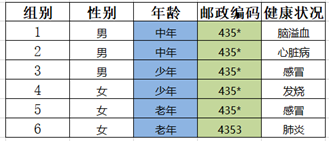
Step4:泛化结果如图所示,对其进行匿名检测,第4条记录可以唯一确定一条信息,不符合匿名规则 goto 1
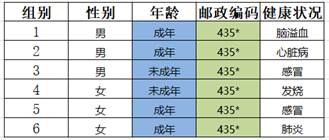
Step5:年龄属性个数为2,对其进行泛化
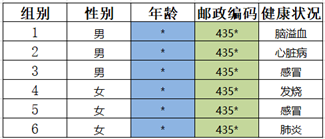
符合2-匿名规则,输出次表格。
(三)KACA算法
(k-Anonymity by Clustering in Attribute)
基本概念
(1)数值之间的距离

如:最大号码123456,最小号码1*****,电话号码123456,与电话号码123455之间的距离为
(123456-123455)/ 123456 == 1/123456,可以看出123456与123455之间距离很小

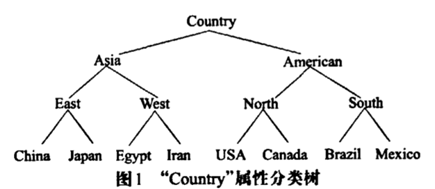
其中A(vi,vj)代表分类树中以vi和vj的最小公共祖先为根的子树,H(T)表示分类树T的高度。
图中Asia,与American的距离为1/3,china和Mexico的距离为3/3,显然Asia与American的距离更近。
(2)泛化的加权层次距离
泛化的加权层次距离:Weighted hierarchical distance,反应不同的泛化层级之间的距离。
设h为属性A可能泛化的最高层次,D1为值域,D2………Dn为泛化域,Wj,j-1为Dj与Dj-l(2 <= j <= h)之间的泛化权重。由Dp中的值泛化到Dq(p>q)中的值的距离定义为下,称之为泛化的加权层次距离。

如生日的泛化层级:
D/M/Y---->M/Y ---->Y---->*
对应的泛化域
D4---->D3---->D2---->D1
当权值都为1时,D/M/Y层泛化到Y层的加权层次距离为: WHD(4,2)=(1+1)/1+1+1=0.67,67。但是,它没有反映出不同泛化层的泛化的差异,如“1970/02/28”泛化成“1970/02/*”,对应的加权层次距离为0.33, “1970/02/*’泛化成“1970/*/*”,加权层次距离仍为0.33,而后一种的失真程度显然比前一种的大。
重新定义泛化权重Wj,j-1=1/(j-1)^β,可以简单的定义β=1,
此时W4,3=1/3,W3,2=1/2,W2,1=1,
这种定义则能反映不同泛化层的泛化的差异。比如:生日属性的泛化层次为D/M/Y---->M/Y ---->Y---->*,从D/M/Y层泛 化到M/Y层的加权层次距离WHD(4,3)=(1/3)/(1/3+1/2+1)=0.18。而从Y泛化到*的加权层级距离
WHD(2,1)=(1/1)/(1/3+1/2+1)=0.55。
(3)元组之间的失真度:
例如元组{china,少年,男性},对应的属性泛化级分别为{国家,东西半球,大洲,地球}和{少年,青少年,人},则元组t={china,青年,男性}与其泛化元组t´={East,青少年,男性}之间的失真度为
Distortion = WHD(level(v1), level(v1´)) + WHD(level(v2), level(v2´))
=1/3 + 1/2 = 5/6
(4)数据表之间的失真度:
将每个元组与其最终的泛化表之间求加权层次距离WHD,再累加求和,即为数据表之间的失真度。

(5)元组之间的距离
即两个元组与离他们最近的泛化集之间的距离的和
KACA算法
(1)步骤

(2)实例
以KACA的2-匿名为例,数据集如下图所示。
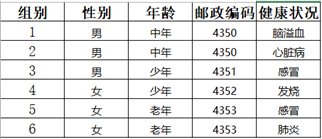
Step1:将数据集D分成4个等价类,等价类各元组在准标识符上值相等
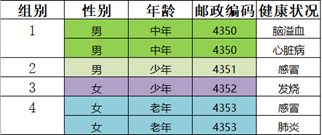
Step2:随机选取一个大小 < 2的等价类,取第2组,距离第2组最近的等价类是第3组,将第2组和第3组合并为一类,并泛化。
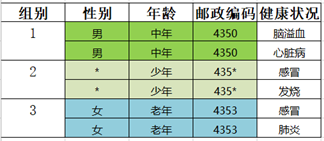
Step3:循环,不存在元组个数小于2的等价类。程序返回处理后的匿名表
全局算法 VS 局部算法
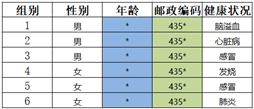
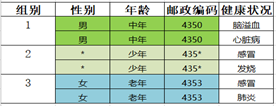
可见,局部算法的失真度更小。
k-anonymity存在的缺陷
k-anonymity 可以阻止身份公开,但无法防止属性公开。无法抵抗同质攻击攻击和背景知识攻击。
(一)同质攻击(homogeneity attack)

指某个k-匿名组内对应的敏感属性的值也完全相同,这使得攻击者可以轻易获取想要的信息。如在在上图中,第1-2条记录的敏感数据是一致的,因此这时候k-anonymity就失效了。观察者只要知道表中某一用户的ZIP Code是435*,性别为男,就可以确定他有脑溢血。
(二)背景攻击(background knowledge attack)
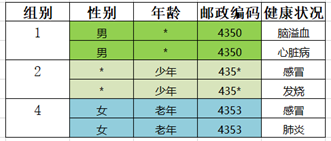
k-匿名组内的敏感属性值并不相同,攻击者也有可能依据其已有的背景知识以高概率获取到其隐私信息
如果观察者通过ZIP Code和性别确定用户Carl在上图等价类1中,如果没有额外的信息,攻击者无法确定carl患的是心脏病还是脑溢血。但是攻击者知道carl在日本,而日本地区的心脏病发病率很低,那么他就可以确定Carl有脑溢血。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号