
python爬虫入门
最近要用爬虫爬几张图片,花了一天时间从网上找了点代码,了解了一下,以下代码都是从网上下载,侵删。爬虫代码不少,但是涉及到软件版本问题,所以不是都能用,以下代码都是基于py3.6 。
爬虫入门不难,大致都遵循三个步骤:
1.扒下来(用网页下载器将网页源码全部下载下来)如requests
2.存起来(URL管理器将源码存储)可以存内存,也可以整个数据库
3.找出来(网页解析器找到其中感兴趣的内容,要下载图片就将图片链接找到)如正则表达式 、beautiful soup(推荐这个)等
代码中真正关键的只有一行
requests.get(url,params=i)
用参数params向url以GET方式请求数据,返回值就是需要的源码
话不多说,直接撸代码
1.单张图片下载
# -*- coding: utf-8 -*- import requests # 这是一个图片的url url = 'http://yun.itheima.com/Upload/Images/20170614/594106ee6ace5.jpg' response = requests.get(url) # 获取的文本实际上是图片的二进制文本 img = response.content # 将他拷贝到本地文件 w 写 b 二进制 wb代表写入二进制文本 with open( './Sinpic.jpg','wb' ) as f: f.write(img)
2.静态网页图片下载
# //引入小需要用到的模块 import requests import os from bs4 import BeautifulSoup def main(): url="http://www.duitang.com/search/?kw=%E6%96%87%E8%B1%AA%E9%87%8E%E7%8A%AC&type=feed" req = requests.get(url) # //将网页内容存储到html_doc变量中 html_doc = req.text soup = BeautifulSoup(html_doc, "lxml")#网页数组化 if not os.path.exists('./Stapic/'): # 新建文件夹 os.mkdir('./Stapic/') # 正则匹配的方法,不会用,麻烦,推荐用bs # listurl = re.findall(r'src=.+\.jpg',buf) # bs4 t = 1 # 记录图片张数 for myimg in soup.find_all('a', class_='a'): # pic_name = str(t) + '.jpg' img_src = myimg.find('img').get('src') ir = requests.get(img_src) open('./Stapic/%d.jpg' % t, 'wb').write(ir.content) print("正在下载第%d张图片"%t) t += 1 if __name__ == '__main__': main()
3.动态网站图片下载
import requests import os def getManyPages(keyword,pages): params=[] for i in range(30,30*pages+30,30): params.append({ 'tn': 'resultjson_com', 'ipn': 'rj', 'ct': 201326592, 'is': '', 'fp': 'result', 'queryWord': keyword, 'cl': 2, 'lm': -1, 'ie': 'utf-8', 'oe': 'utf-8', 'adpicid': '', 'st': -1, 'z': '', 'ic': 0, 'word': keyword, 's': '', 'se': '', 'tab': '', 'width': '', 'height': '', 'face': 0, 'istype': 2, 'qc': '', 'nc': 1, 'fr': '', 'pn': i, 'rn': 30, 'gsm': '1e', '1488942260214': '' }) url = 'https://image.baidu.com/search/acjson' # 下面几句是真正访问网站的 urls = [] for i in params: urls.append(requests.get(url,params=i).json().get('data')) #requests.get(url,params=i)用参数i,向url请求数据,;.json()将请求来的数据由<Response [200]>转化为文本,是一个字典;.get('data')将其中的key word为data的数据项其取出来,加入到数组url中 return urls def getImg(dataList, localPath): if not os.path.exists(localPath): # 新建文件夹 os.mkdir(localPath) x = 0 for list in dataList: for i in list: if i.get('thumbURL') != None: print('正在下载:%s' % i.get('thumbURL')) ir = requests.get(i.get('thumbURL')) open(localPath + '%d.jpg' % x, 'wb').write(ir.content) x += 1 else: print('图片链接不存在') if __name__ == '__main__': dataList = getManyPages('宠物猪',1) # 参数1:关键字,参数2:要下载的页数 getImg(dataList,'./Dynpic/') # 参数2:指定保存的路径
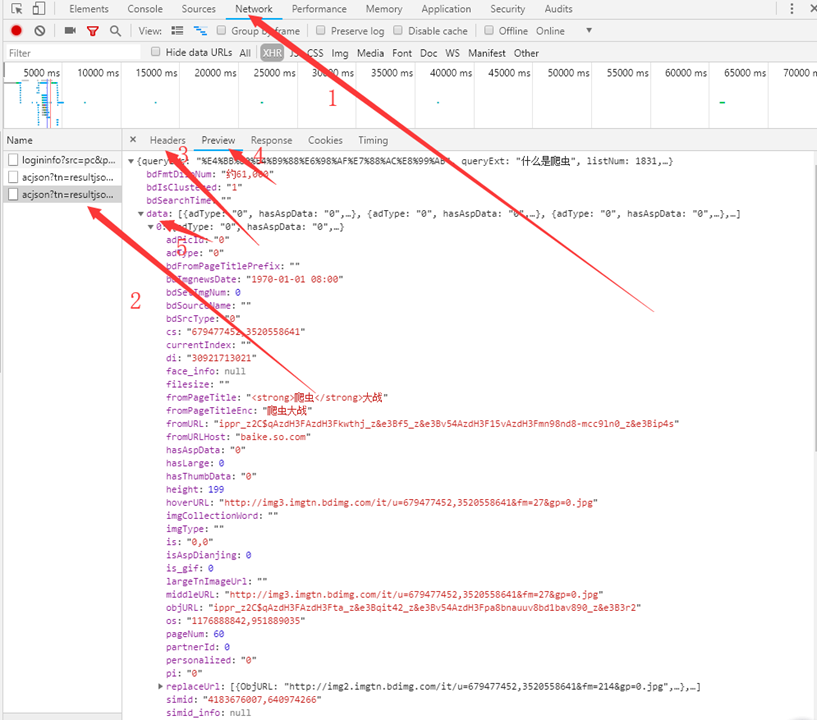
params的参数可能比较懵,那个不需要自己写的,如下图所示,在百度图片搜索一个关键字,然后F12,按照1.2.3的操作(找不到2可以刷新一下网页),可以在Header中看到需要的这些参数,按照4.5的操作就可以找到图片链接
这是基本入门,进阶推荐看一下https://cuiqingcai.com/5052.html讲的很详细。


