


Spatial Transformer Networks
需要两个先验知识:
1.attention的实现原理:在没有额外监督信息的情况下,attention怎么实现对关键部位的注意
2.如何通过矩阵操作来实现图片的仿射变换
整体结构:
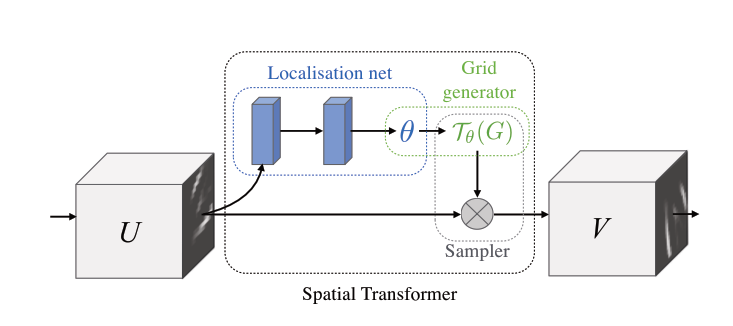
stn包含三个模块:
1.Localisation net
用来预测仿射变换需要的6个参数,实质上就是一个普通卷积网络,最后全连接输出6个值。
2.Grid generator
这一步在原论文中是这样叙述的:the predicted transformation parameters are used to create a sampling grid, which is a set of points where the input map should be sampled to produce the transformed output.
用第一步预测的参数来生成sampling grid,这个sampling grid就是输出特征图V上的每个点在输入特征图U上的对应点的坐标。如下图所示
这里有几个问题要注意:
1.预测的参数是空间变换的参数,是STN网络的中间输出结果(不是STN网络的参数),因此每一张图片都有不同的参数
2.为什么是V向U映射的坐标而不是反之(按照逻辑思维,似乎U到V更好理解)?这是因为V上的每个点都要在U上找到对应点(不是整数的问题在下一步解决),U上的点却不是都有对应,映射公式如下图所示
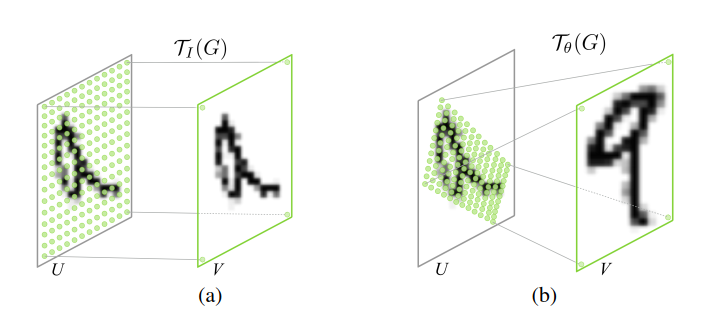

(s=source,源域,,t=target,目标域)
代码的运行结果也印证了这一问题:pytorch中的sampling grid的大小是torch.Size([28, 28, 2]),而且是小数,是特征图V在特征图U上的对应点。
3.Differentiable Image Sampling
the feature map and the sampling grid are taken as inputs to the sampler, producing the output map sampled from the input at the grid points
也就是说:将特征图U和2中得到的sampling grid输入到sampler中,得到变换后的特征图V
映射原理上很好理解,主要处理的问题是2中得到的小数如何变成整数。取整过程还要可导(要参与网络反向传播),因此直接取整的方法就行不通了,文中作者采用的是双线性插值方法。(双线性插值的过程就不赘述,可以参考高数相关资料或者看本文下方的李宏毅老师的视频)
Q:双线性插值用周围4个点来对sampling grid上的点取整操作,也就是说sampling grid上的点不会跑出周围四个点范围,那么如何实现整幅图像大范围的变化(网络经过一次迭代图像发生线性变换,图片上对应点跑过大半张图片)
A:双线性插值的过程是不可学习的,我们通过反向传播学习的是预测6个变换参数的STN网络,网络参数更新后,6个参数值会发生较大变化,导致新的sampling grid值发生更大的变化,那样sampling grid上的每个点会落在新的4个整数点之间
(空间、通道)attention、STN、可变形卷积,这三者思想很像,都是通过不增加额外监督信息的可插入模块实现对网络局部信息的attention
这也间接的反映出cnn网络的旋转缩放平移的不变性很弱,甚至对输入图片的关键信息也不能够很好的把握。
CNN远非完美,诸君大有可为
原论文:https://arxiv.org/pdf/1506.02025.pdf
pytorch代码:https://github.com/pytorch/tutorials/blob/master/intermediate_source/spatial_transformer_tutorial.py
代码解读(略):http://studyai.com/pytorch-1.4/intermediate/spatial_transformer_tutorial.html
李宏毅视频:https://www.bilibili.com/video/BV1xb411C7Qi?p=5
优秀bolg:https://blog.csdn.net/qq_39422642/article/details/78870629
为什么选用双线性插值:https://zhuanlan.zhihu.com/p/46751261


