

PyTables 教程(二)多维表单元格和自动健全性检查,使用链接更方便地访问节点
翻译自http://www.pytables.org/usersguide/tutorials.html
多维表单元格和自动健全性检查
现在是一个更真实的例子(即代码中有错误)的时候了。我们将创建两个直接从根节点分支的组,Particles和Events。然后,我们将在每个组中创建三个表。在Particle中,我们将根据Particle 类创建表,在Events中根据Event类创建表。
之后,我们将为这些表提供许多记录。最后,我们将读取新创建的表 /Events/TEvent3 ,并利用复杂列表的方法从中选择一些值。
查看下一个脚本(您可以在examples/tutorial2.py 中找到它)。它似乎可以完成上述所有操作,但它包含一些bugs。请注意,此 Particle 类与上一教程中定义的类没有直接关系;这个类更简单(请注意,多维列名为pressure和temperature)。
我们还引入了一种新方式来将 Table 描述为结构化的 NumPy dtype(甚至是字典),如您在Event的描述符所见。有关可以传递给此方法的不同类型的描述符对象,请参阅 File.create_table():
import tables as tb import numpy as np # Describe a particle record class Particle(tb.IsDescription): name = tb.StringCol(itemsize=16) # 16-character string lati = tb.Int32Col() # integer longi = tb.Int32Col() # integer pressure = tb.Float32Col(shape=(2,3)) # array of floats (single-precision) temperature = tb.Float64Col(shape=(2,3)) # array of doubles (double-precision) # Native NumPy dtype instances are also accepted Event = np.dtype([ ("name" , "S16"), ("TDCcount" , np.uint8), ("ADCcount" , np.uint16), ("xcoord" , np.float32), ("ycoord" , np.float32) ]) # And dictionaries too (this defines the same structure as above) # Event = { # "name" : tb.StringCol(itemsize=16), # "TDCcount" : tb.UInt8Col(), # "ADCcount" : tb.UInt16Col(), # "xcoord" : tb.Float32Col(), # "ycoord" : tb.Float32Col(), # } # Open a file in "w"rite mode fileh = tb.open_file("tutorial2.h5", mode="w") # Get the HDF5 root group root = fileh.root # Create the groups: for groupname in ("Particles", "Events"): group = fileh.create_group(root, groupname) # Now, create and fill the tables in Particles group gparticles = root.Particles # Create 3 new tables for tablename in ("TParticle1", "TParticle2", "TParticle3"): # Create a table table = fileh.create_table("/Particles", tablename, Particle, "Particles: "+tablename) # Get the record object associated with the table: particle = table.row # Fill the table with 257 particles for i in range(257): # First, assign the values to the Particle record particle['name'] = f'Particle: {i:6d}' particle['lati'] = i particle['longi'] = 10 - i ########### Detectable errors start here. Play with them! particle['pressure'] = np.array(i * np.arange(2 * 3)).reshape((2, 4)) # Incorrect #particle['pressure'] = np.array(i * np.arange(2 * 3)).reshape((2, 3)) # Correct ########### End of errors particle['temperature'] = i ** 2 # Broadcasting # This injects the Record values particle.append() # Flush the table buffers table.flush() # Now, go for Events: for tablename in ("TEvent1", "TEvent2", "TEvent3"): # Create a table in Events group table = fileh.create_table(root.Events, tablename, Event, "Events: "+tablename) # Get the record object associated with the table: event = table.row # Fill the table with 257 events for i in range(257): # First, assign the values to the Event record event['name'] = f'Event: {i:6d}' event['TDCcount'] = i % (1<<8) # Correct range ########### Detectable errors start here. Play with them! event['xcoor'] = float(i ** 2) # Wrong spelling #event['xcoord'] = float(i ** 2) # Correct spelling event['ADCcount'] = "sss" # Wrong type #event['ADCcount'] = i * 2 # Correct type ########### End of errors event['ycoord'] = float(i) ** 4 # This injects the Record values event.append() # Flush the buffers table.flush() # Read the records from table "/Events/TEvent3" and select some table = root.Events.TEvent3 e = [ p['TDCcount'] for p in table if p['ADCcount'] < 20 and 4 <= p['TDCcount'] < 15 ] print(f"Last record ==> {p}") print("Selected values ==> {e}") print("Total selected records ==> {len(e)}") # Finally, close the file (this also will flush all the remaining buffers!) fileh.close()
1. 形状检查
如果您仔细查看代码,您会发现它不起作用。将返回以下错误:
$ python3 tutorial2.py
Traceback (most recent call last):
File "tutorial2.py", line 60, in <module>
particle['pressure'] = array(i * arange(2 * 3)).reshape((2, 4)) # Incorrect
ValueError: total size of new array must be unchanged
Closing remaining open files: tutorial2.h5... done
此错误表明您正尝试将形状不兼容的数组分配给表格单元格。查看源代码,我们看到我们试图将形状 (2,4) 的数组分配给pressure元素,而该元素定义的形状是 (2,3)。
通常,这些类型的操作是被禁止的,只有一个例外:当您将标量值分配给多维列单元格时,所有单元格元素都填充有标量值。例如:
particle['temperature'] = i ** 2 # Broadcasting
值 i**2 分配给温度表单元格的所有元素。此功能由 NumPy 包提供,称为广播。
2. 字段名检查
修复上一个错误并重新运行程序后,我们又遇到了另一个错误。
$ python3 tutorial2.py
Traceback (most recent call last):
File "tutorial2.py", line 73, in ?
event['xcoor'] = float(i ** 2) # Wrong spelling
File "tableextension.pyx", line 1094, in tableextension.Row.__setitem__
File "tableextension.pyx", line 127, in tableextension.get_nested_field_cache
File "utilsextension.pyx", line 331, in utilsextension.get_nested_field
KeyError: 'no such column: xcoor'
此错误表明我们正在尝试为Event表对象中不存在的字段赋值。通过仔细查看 Event 类属性,我们发现我们拼错了 xcoord 字段(我们改写了 xcoor)。这对于 Python 来说是不寻常的行为,因为通常当您为不存在的实例变量赋值时,Python 会创建一个具有该名称的新变量。在处理包含固定字段名称列表的对象时,这样的功能可能很危险。 PyTables 检查该字段是否存在并在检查失败时引发 KeyError。
3. 数据类型检查
最后,我们将在这里找到的最后一个问题是 TypeError 异常。
$ python3 tutorial2.py
Traceback (most recent call last):
File "tutorial2.py", line 75, in ?
event['ADCcount'] = "sss" # Wrong type
File "tableextension.pyx", line 1111, in tableextension.Row.__setitem__
TypeError: invalid type (<type 'str'>) for column ``ADCcount``
而且,如果我们将受影响的行更改为:
event.ADCcount = i * 2 # Correct type
我们将看到脚本顺利结束。
您可以在Figure 4 中看到使用此(更正的)脚本创建的结构。特别要注意表 /Particles/TParticle2 中的多维列单元格。
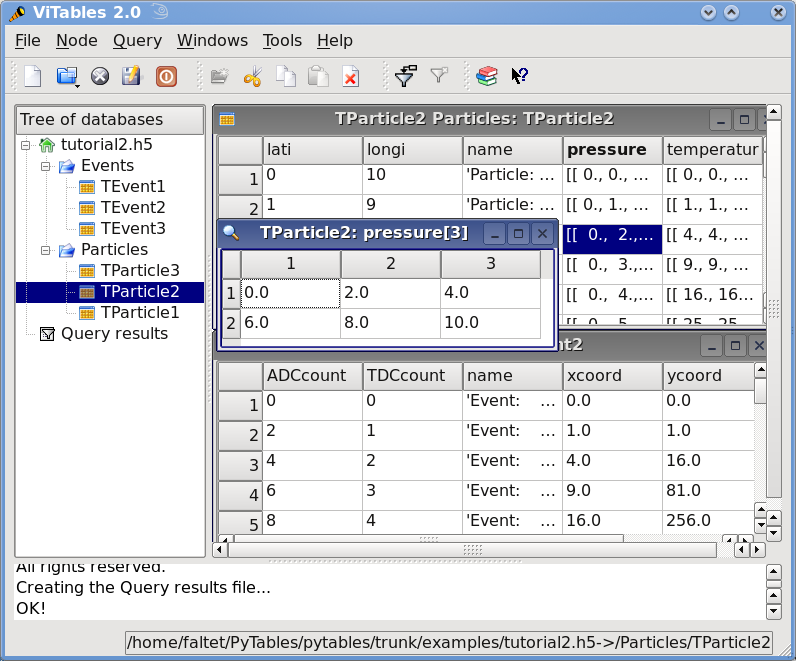
图 4. 教程 2 的表层次结构。
使用链接更方便地访问节点
链接是特殊节点,可用于创建到现有节点的额外路径。 PyTables 支持三种链接:硬链接、软链接(又名符号链接)和外部链接。
硬链接让用户创建额外的路径来访问同一文件中的另一个节点,一旦创建,它们就与引用的节点对象没有区别,只是它们在对象树中具有不同的路径。例如,如果引用的节点是一个 Table 对象,那么新的硬链接本身将成为一个 Table 对象。从这一点开始,您将能够从两个不同的路径访问同一个 Table 对象:原始路径和新的硬链接路径。如果您删除表的一条路径,您将能够通过另一条路径到达它。
软链接类似于硬链接,但它们保持自己的个性。当您创建到另一个节点的软链接时,您将获得一个指向该节点的新 SoftLink 对象。但是,为了访问指向的节点,您需要对它dereference(间接引用) 。
最后,外部链接就像软链接,不同之处在于它们指向外部文件中的节点,而不是同一文件中的节点。它们由 ExternalLink 类表示,并且与软链接一样,您需要dereference 它们才能访问指向的节点。
交互式的例子
现在我们将学习如何处理链接。您可以在examples/links.py中找到本节中使用的代码。
首先,让我们创建一个具有一些组结构的文件:
>>> import tables as tb
>>> f1 = tb.open_file('links1.h5', 'w')
>>> g1 = f1.create_group('/', 'g1')
>>> g2 = f1.create_group(g1, 'g2')
现在,我们将在 /g1 和 /g1/g2 组上放置一些数据集:
>>> a1 = f1.create_carray(g1, 'a1', tb.Int64Atom(), shape=(10000,))
>>> t1 = f1.create_table(g2, 't1', {'f1': tb.IntCol(), 'f2': tb.FloatCol()})
现在,我们可以开始嗨了。我们将创建一个新组,比如 /gl,我们将在其中放置我们的链接并开始创建一个硬链接:
>>> gl = f1.create_group('/', 'gl')
>>> ht = f1.create_hard_link(gl, 'ht', '/g1/g2/t1') # ht points to t1
>>> print(f"``{ht}`` is a hard link to: ``{t1}``")
``/gl/ht (Table(0,)) `` is a hard link to: ``/g1/g2/t1 (Table(0,)) ``
您可以看到我们如何在 /gl/ht 中创建指向 /g1/g2/t1 中现有表的硬链接。看看硬链接是如何表示的;它看起来像一个表,实际上,它是一个真正的表。我们有两种不同的路径来访问该表,原始的 /g1/g2/t1 和新的 /gl/ht。
如果我们删除原始路径,我们仍然可以使用新路径到达表:
>>> t1.remove()
>>> print(f"table continues to be accessible in: ``{f1.get_node('/gl/ht')}``")
table continues to be accessible in: ``/gl/ht (Table(0,)) ``
到现在为止还挺好。现在,让我们创建几个软链接:
>>> la1 = f1.create_soft_link(gl, 'la1', '/g1/a1') # la1 points to a1
>>> print(f"``{la1}`` is a soft link to: ``{la1.target}``")
``/gl/la1 (SoftLink) -> /g1/a1`` is a soft link to: ``/g1/a1``
>>> lt = f1.create_soft_link(gl, 'lt', '/g1/g2/t1') # lt points to t1
>>> print(f"``{lt}`` is a soft link to: ``{lt.target}``")
``/gl/lt (SoftLink) -> /g1/g2/t1 (dangling)`` is a soft link to: ``/g1/g2/t1``
好的,我们看到第一个链接 /gl/la1 指向数组 /g1/a1。请注意链接的是SoftLink,以及引用节点如何存储在目标实例属性中。
指向 /g1/g2/t1 的第二个链接 (/gt/lt) 也已成功创建,但检查它的字符串后,我们发现它被标记为(dangling)’。为什么是这样?因为我们最近删除了访问表 t1 的 /g1/g2/t1 路径。当打印它时,对象知道它指向nowhere并报告这一点。这是快速了解软链接是否指向现有节点的好方法。
因此,让我们重新创建已删除的 t1 表路径:
>>> t1 = f1.create_hard_link('/g1/g2', 't1', '/gl/ht')
>>> print(f"``{lt}`` is not dangling anymore")
``/gl/lt (SoftLink) -> /g1/g2/t1`` is not dangling anymore
软链接现在指向现有节点了。
当然,要使软链接服务于任何实际目的,我们需要一种获取指向节点的方法。碰巧软链接是可调用的,这就是获取被引用节点的方法:
>>> plt = lt()
>>> print(f"dereferred lt node: ``{plt}``")
dereferred lt node: ``/g1/g2/t1 (Table(0,)) ``
>>> pla1 = la1()
>>> print(f"dereferred la1 node: ``{pla1}``")
dereferred la1 node: ``/g1/a1 (CArray(10000,)) ``
现在, plt 是对 t1 表的 Python 引用,而 pla1 是指 a1 数组。容易吧?
现在让我们假设 a1 是一个数组,其访问速度对我们的应用程序至关重要。一种可能的解决方案是将整个文件移动到速度更快的磁盘中,例如固态磁盘,以便可以大大减少访问延迟。然而,碰巧我们的文件太大而无法放入我们新买的(尽管容量很小)SSD 磁盘。一种解决方案是仅将 a1 数组复制到适合我们的 SSD 磁盘的单独文件中。但是,我们的应用程序将能够处理两个文件而不是一个文件,这显着增加了复杂性,这不是一件好事。
解决办法就是外部链接!正如我们已经说过的,外部链接类似于软链接,但它们旨在链接外部文件中的对象。回到我们的问题,让我们将 a1 数组复制到另一个文件中:
>>> f2 = tb.open_file('links2.h5', 'w')
>>> new_a1 = a1.copy(f2.root, 'a1')
>>> f2.close() # close the other file
现在,我们可以删除现有的软链接并在其位置创建外部链接:
>>> la1.remove()
>>> la1 = f1.create_external_link(gl, 'la1', 'links2.h5:/a1')
>>> print(f"``{la1}`` is an external link to: ``{la1.target}``")
``/gl/la1 (ExternalLink) -> links2.h5:/a1`` is an external link to: ``links2.h5:/a1``
让我们尝试dereferring它:
>>> new_a1 = la1() # dereferrencing la1 returns a1 in links2.h5
>>> print(f"dereferred la1 node: ``{new_a1}``")
dereferred la1 node: ``/a1 (CArray(10000,)) ``
好吧,看来我们可以访问外部节点了。但只是为了确保节点在另一个文件中:
>>> print("new_a1 file:", new_a1._v_file.filename)
new_a1 file: links2.h5
好的,节点肯定在外部文件中。因此,您不必担心您的应用程序:无论链接是内部(软)还是外部链接,它的工作方式都完全相同。
最后,这里是最终文件中对象的转储,只是为了更好地了解我们的结尾:
>>> f1.close()
>>> exit()
$ ptdump links1.h5
/ (RootGroup) ''
/g1 (Group) ''
/g1/a1 (CArray(10000,)) ''
/gl (Group) ''
/gl/ht (Table(0,)) ''
/gl/la1 (ExternalLink) -> links2.h5:/a1
/gl/lt (SoftLink) -> /g1/g2/t1
/g1/g2 (Group) ''
/g1/g2/t1 (Table(0,)) ''
本教程到此结束。我希望它可以帮助您了解链接的有用性。我相信您会找到其他方式来使用更适合您自己需求的链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号