
OpenMP fortran 学习
参考自TAMU的PPThttps://people.math.umass.edu/~johnston/PHI_WG_2014/OpenMPSlides_tamu_sc.pdf
什么是OpenMP
在C、C++和FORTRAN中用于编写共享内存并行程序的事实上的标准API
OpenMP API 由以下组成:
-
编译器指令Compiler Directives
- 运行时 子程序/函数 Runtime subroutines/functions
- 环境变量 Environment variables
例子:
代码
PROGRAM HELLO
!$OMP PARALLEL
PRINT *,”Hello World”
!$ OMP END PARALLEL
STOP
END
编译指令
intel: ifort -openmp -o hi.x hello.f pgi: pgfortran -mp -o hi.x hello.f gnu: gfortran -fopenmp -o hi.x hello.f
运行指令
Export OMP_NUM_THREADS=4
./hi.x
FORTRAN指令格式:
!$ OMP PARALLEL [clauses]
:
!$OMP END PARALLEL
OpenMP 遵循Fork/Join模型
OpenMP程序从一个线程开始;主线程(线程0)
在并行区域开始时,master创建一组并行“worker”线程(FORK)
并行块中的语句由每个线程并行执行
在并行区域的末尾,所有线程同步(隐式屏障implicit barrier),并连接主线程(JOIN)

OpenMP线程与内核
- 线程是独立的程序代码执行序列
- 代码块只有一个入口和一个出口
- 与核心/CPU无关
- OpenMP的线程们都映射到物理核心们上
- 可以在一个核心上映射多个线程
- 实际上,线程和核心最好是一对一的映射。
OpenMP的线程数可通过如下方法设置:
-
环境变量 OMP_NUM_THREADS
-
运行时函数 omp_set_num_threads(n)
其它获取线程信息的有用的函数:
- 运行时函数 omp_get_num_threads()
- 返回并行域中线程数目
- 如果在并行域外返回1
- 运行时函数 omp_get_thread_num()
- 返回组中线程id
- 值为[0,n-1],其中n为线程总数
- 主线程的id是0
共享和私有变量
OpenMP在OpenMP块内,提供了一个声明变量是私有private还是共享shared的方法。这通过遵循如下OpenMP条款实现:
SHARED(list)
- 在list中的所有变量被认为是共享的
- 每一个openmp线程都可以访问所有这些变量
PRIVATE(list)
- 每一个openmp线程,对于list中的变量,都有一个自己“私有的”副本
- 其它的openmp线程不能访问这个“私有的”副本
例如 !$OMP PARALLEL PRIVATE(a,b,c) (fortran)
在OpenMP中,默认情况下,大多数变量都认为是共享的。以下情况例外:指针变量(Fortran, C/C++)和在parallel region区内声明的变量(C/C++)
TIPS:实际问题
- openmp为每个工作线程创建单独的数据堆栈以存储私有变量的副本(主线程使用常规堆栈)
- OpenMP标准未定义这些堆栈的大小
- 英特尔编译器:默认堆栈为4MB
- gcc/gfortran:默认堆栈为2mb
- 超出堆栈空间时,程序的行为未定义
- 尽管大多数编译器/RT都会抛出seg fault
- 要增加堆栈大小,请使用环境变量OMP_STACKSIZE,例如
- export OMP_STACKSIZE=512M
- export OMP_STACKSIZE=1GB
- 确保主线程有足够大的堆栈空间使用
- ulimit-s命令(unix/linux)
作业共享(手动方法)
到目前为止,只讨论了在所有并行区域中做同样的工作,这不是很有用。我们想要的是在所有线程之间共享工作,这样我们就能更快地解决问题。


作业共享(OpenMP 方法)
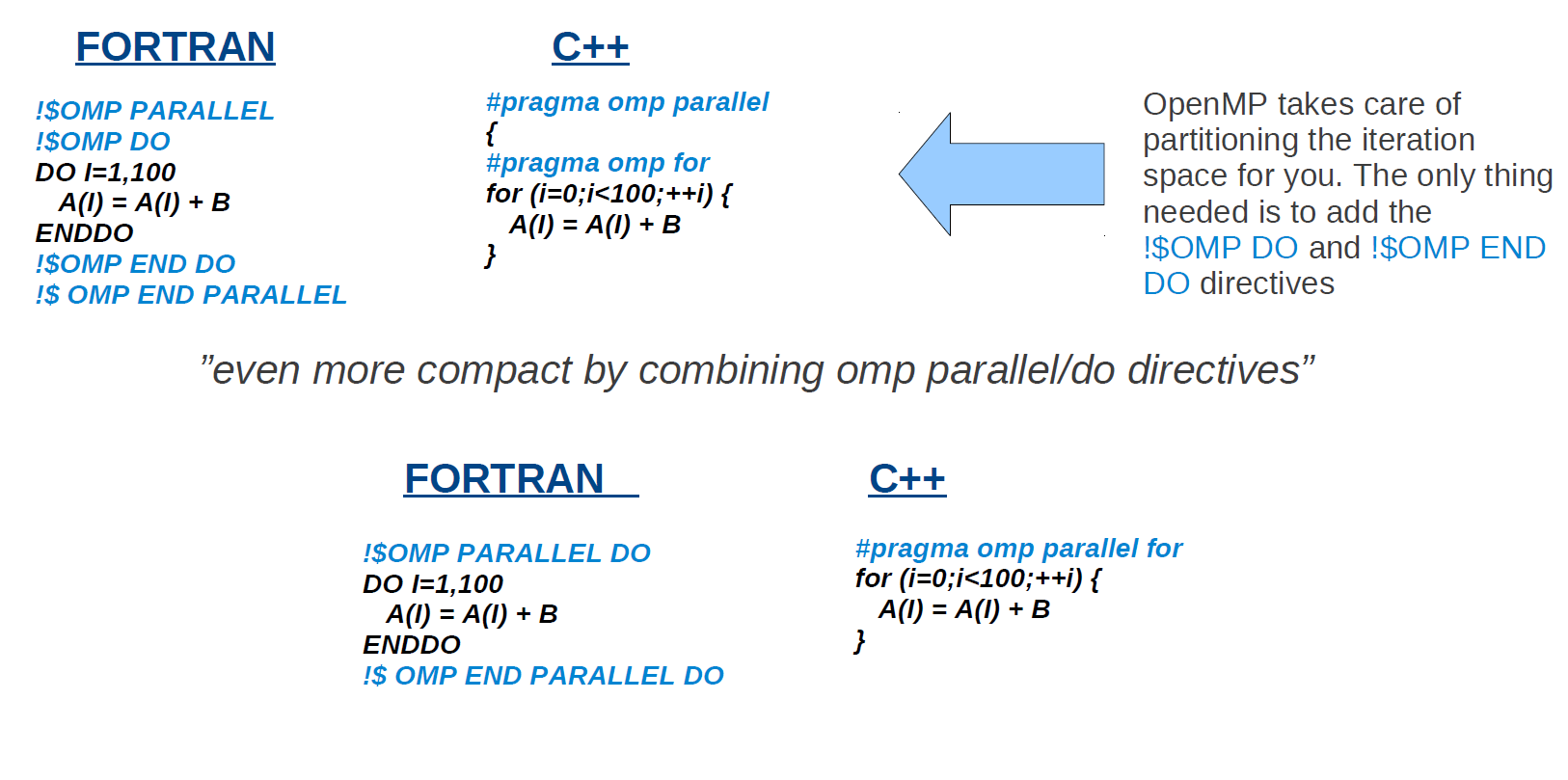
OpenMP帮你划分好了迭代空间。你唯一需要做的就是添加!$OMP DO 和!$OMP END DO指令
“可以通过使用 !$OMP PARALLEL DO 指令 使得命令更加紧凑”
规约 Reductions
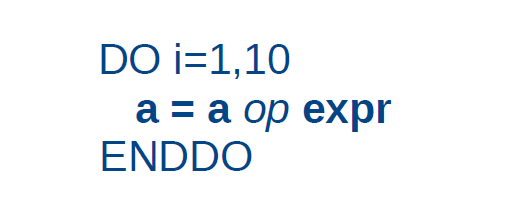 或者
或者
a = a 运算符 表达式 称为归约运算。显然,变量“a”带有一个 流依赖关系(稍后将讨论),它阻碍了了并行化。
对于此类情况,openmp提供了规约语句 REDUCTION(op:list)。语句适用于满足下列限制条件时:
- a是列表中的标量变量
- expr是一个标量表达式,它不引用a
- 只允许某些类型的运算符;例如,+,*,。-
- 在fortran中,运算符也可以是内置函数的;例如MAX,MIN,IOR
- 列表中的变量必须是共享的
提示:openmp作用域规则
到目前为止,所有指令都嵌套在同一个例程中(最外层的!$OMP PARALLEL)。然而,OpenMP提供了更灵活的范围规则。它只允许有例行程序!$OMP DO在这种情况下,我们调用!$OMP DO执行孤立指令orphaned directive。
注意:有一些规则(例如,当遇到一个!$OMP DO directive,程序应在parallel部分)
OMP如何安排迭代?
尽管openmp标准没有指定循环应该如何分区,但默认情况下,大多数编译器在N/p(N 迭代数,p线程数)块中分割循环。这称为静态调度(块大小为N/p)
为了显式地告诉编译器使用静态调度(或者我们稍后将看到的其他调度),openmp提供了SCHEDULE子句
$!OMP DO SCHEDULE (STATIC,n) (n是分块的大小)
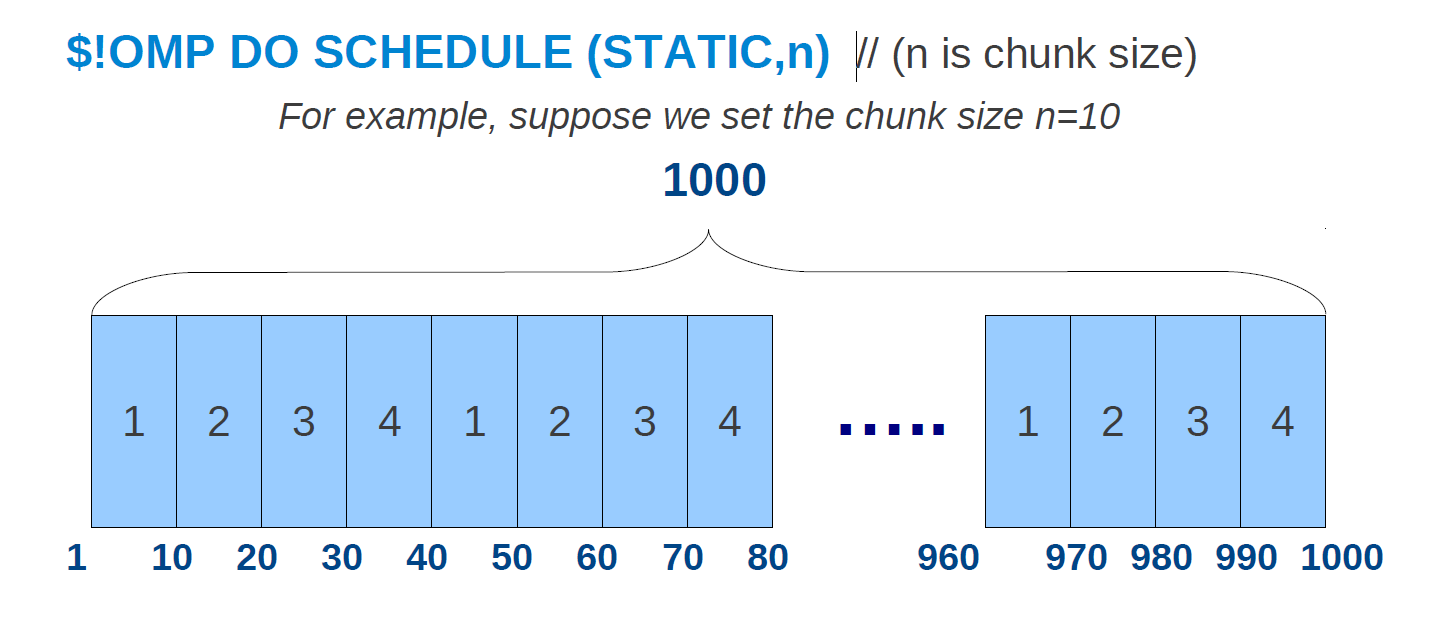
静态调度的问题
在静态调度中,迭代次数在所有openmp线程中均匀分布(即每个线程将被分配相似的迭代次数)。这并不总是分割的最佳方式。这是为什么?
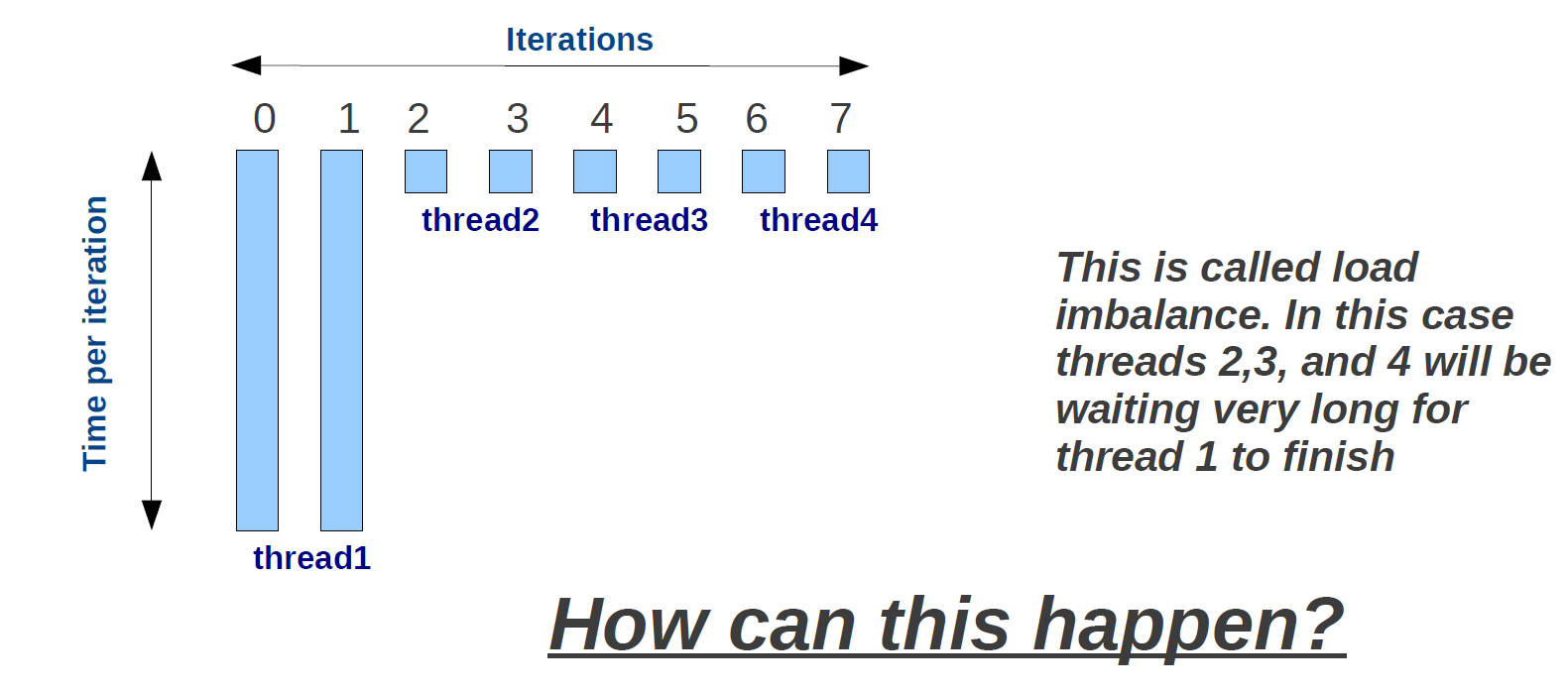
动态调度
有了动态调度,新的块在线程可用时被分配给它们。OpenMP提供两个动态调度:
- $!OMP DO SCHEDULE(DYNAMIC,n) // n is chunk size
循环迭代被分成大小块。当一个线程完成一个块时,它被动态地分配给另一个块。
- $!OMP DO SCHEDULE(GUIDED,n) // n is chunk size
类似于DYNAMIC,但块大小是相对于剩余迭代次数的
请记住:虽然在某些情况下,动态调度可能是防止负载不平衡的首选,但与静态调度相比,这涉及到很大的开销。
OMP SINGLE
openmp提供的另一个共享作业指令是!$OMP SINGLE。当遇到单个指令时,只有一个团队成员将执行块中的代码
- 一个线程(不一定是主线程)执行块
- 其他线程将等待
- 对线程不安全代码有用
- 对I/O操作有用
数据的依赖
并非所有的循环都可以并行化。在添加openmp指令之前,需要检查是否存在任何依赖项:
我们将依赖项分为三类:
- 流依赖性:在写之后读Read after Write (RAW)
- 反依赖:读后写Write after Read (WAR)
- 输出依赖性:写后写Write after Write (WAW)

对于我们的目的(openmp并行循环),我们只关心循环携带的依赖(循环的不同迭代中指令之间的依赖)

1. S3→S2 anti(B) 变量B反依赖。对于变量B,写第i个的数据(S2),读第i+1个的数据(S3) (先写后读)
2. S3→S4 flow(A) 变量A流依赖。对于变量A,写第i+1个的数据(S3),读第i个的数据(S4)(先读后写)
3. S4→S2 flow(B) 变量temp流依赖。对于变量temp,先读取它的数据(S2),然后再写入数据(S4)(先读后写)
4. S3→S4 flow(B) 变量temp输出依赖。对于变量temp,先向它写入数据(S4),然后向它写入数据(下一个S4)(写后写)
循环携带的反依赖项和输出依赖项不是真正的依赖项(重复使用相同的名称),在许多情况下可以相对容易地解决。
流依赖项是真正的依赖项(有一个从定义到使用的流),在许多情况下不容易删除。可能需要重写算法(如果可能)
处理反/输出依赖
使用 PRIVATE语句: 见hello_threads (略)
变量重命名(如果可能):
示例:原地左移

除了openmp之前描述的子句之外,一些非常有用的附加datascope子句:
- FIRSTPRIVATE ( list ):
与private相同,但变量“x”的每个私有副本都是用“x”的原始值(在omp区域开始之前)初始化 - LASTPRIVATE ( list ):
与private相同,但列表中上次工作共享的变量的私有副本将复制到共享版本。与!$OMP DO指令一起使用。 - DEFAULT (SHARED | PRIVATE | FIRSTPRIVATE | LASTPRIVATE ):
指定omp区域中所有变量的默认范围。
例子学习:去除流依赖
Y=prefix(X) 前缀和(数列前n项的和)
求法:
串行:
Y[1]=X[1] Do i=2,n Y[i]=Y[i-1]+X[i] END DO
但这种算法不能用于并行运算

改写算法
第一步:将X根据线程数分割,每一个线程计算自己的前缀和。
第二步:创建数组T,收集各个分隔段的最后一个元素,并计算前缀和到T。
第三步:每一个线程的结果的加上T[theadid]。
第四部:完成。

前缀和的实现Prefix Sum Implementation
三个独立步骤
- 步骤1和3可以并行完成
- 步骤2必须按顺序执行
- 步骤1必须在步骤2之前执行
- 步骤2必须在步骤3之前执行
注意:为了便于说明,我们可以假设数组长度是线程数目的倍数
这个案例研究展示了一个具有实际(流)依赖关系的算法示例
- 有时我们可以重写algorightm来并行运行
- 大多数时候这不是小事
- 加速(通常)不那么令人印象深刻
OpenMP Sections
假设您有可以并行执行的代码块(即没有依赖项)。要并行执行它们,openmp提供了!$OMP SECTIONS指令。语法如下:

这将并行执行“WROK1”和“WORK2”
NOWAIT 指令
每当作业共享结构中的线程(例如!$OMP DO)比其他线程更快地完成工作,它将等待所有参与线程完成各自的工作。所有线程将在作业共享结构结束时同步。
对于不需要或不想在末尾同步的情况,OpenMP 提供了NOWAIT 指令

关于作业共享总结
我们讨论了OMP 作业共享结构
- !$OMP DO
- !$OMP SECTIONS
- !$OMP SINGLE
可与这些结构一起使用的有用指令(不完整列表,并非所有指令都可与每个指令一起使用)
- SHARED (list)
- PRIVATE (list)
- FIRSTPRIVATE (list)
- LASTPRIVATE(list)
- SCHEDULE (STATIC | DYNAMIC | GUIDED, chunk)
- REDUCTION(op:list)
- NOWAIT
同步化
OpenMP程序使用共享变量进行通信。我们需要确保不同的线程不会同时访问这些变量(会导致争用情况,为什么?)。OpenMP提供了许多同步指令。
- !$OMP MASTER
- !$OMP CRITICAL
- !$OMP ATOMIC
- !$OMP BARRIER
!$OMP MASTER
此指令确保只有主线程超出块中的指令。没有隐式屏障,因此其他线程不会等待master完成
与!$OMP SINGLE DIRECTIVE 有什么不同?
!$OMP CRITICAL
此指令确保只有一个线程可以执行块中的代码。如果另一个线程到达临界区,它将等待直到当前线程完成此临界区。每个线程都将执行关键块,并且它们将在CRITICAL部分的末尾同步。
- 引入开销
- 序列化关键块
- 如果临界区的时间相对较大→加速可忽略不计
!$OMP ATOMIC
这个指令非常类似于上一张幻灯片上的 !$OMP CRITICAL 指令。不同的是 !$OMP ATOMIC仅用于更新内存位置。有时 !$OMP ATOMIC被称为mini 临界区。
- 块仅由一个语句组成
- 原子语句必须遵循特定语法
- 在前面的示例中,可以将“critical”替换为“atomic”
!$OMP BARRIER
!$OMP BARRIER 将强制每个线程在该屏障处等待,直到所有线程都达到该屏障为止。!$OMP BARRIER 可能是最著名的同步机制;显式或隐式地。我们之前讨论过的以下omp指令包含一个隐式屏障:
- !$ OMP END PARALLEL
- !$ OMP END DO
- !$ OMP END SECTIONS
- !$ OMP END SINGLE
- !$ OMP END CRITICAL
潜在的加速
理想情况下,我们希望有完美的加速(即使用n个处理器时n的加速)。然而,这在大多数情况下并不切实可行,原因如下:
- 并非所有的执行时间都花在并行区域(例如循环)上
例如,并非所有循环都是并行的(数据依赖关系) - 使用openmp线程有一个固有的开销
让我们看一个例子,它显示了由于程序的非并行部分,加速将如何受到影响(略)
TIP: IF 指令
OpenMP提供了另一个有用的指令,用于在运行时确定并行区域是实际并行运行(多线程)还是仅由主线程运行:
IF (logical expr)
例如:
$!OMP PARALLEL IF(n > 100000) (fortran)
#pragma omp parallel if (n>100000) (C/C++)
这将只在n>100000时运行并行区域
Amdahl法则
每个程序由两部分组成::
- 串行部分
- 并行部分
显然,无论有多少个处理器,串行部分只在一个处理器执行。假设,程序花费总时间的p(0<p<1)部分在并行区域,(相对于串行的)运行时间将是:
((1-p)+p/N)/1
这意味着加速倍数将是:
1/((1-p)+p/N)
例如:假设80%的程序可以并行执行,且有用不限制的CPU数目,则最大加速将仅仅是5倍

OpenMP开销/可扩展性
启动并行OpenMP 区域不是免费的。这涉及相当多的开销。在循环周围放置openmp pragmas之前,请考虑以下内容:
- 记住阿姆达定律
- 尽可能并行化大多数外部循环(在某些情况下,即使迭代次数较少)
- 确保并行区域的加速足以克服开销
循环中的迭代次数足够大吗?
每次迭代的工作量是否足够? - 不同机器/操作系统/编译器的开销可能不同
OpenMP 程序的伸缩性并不总是很好。即,当openmp线程数增加时,加速将受到以下影响
- 更多线程竞争可用带宽
- 缓存问题
嵌套并行
OpenMP允许嵌套并行(例如 在!$OMP DO里面嵌套!$OMP DO)
- 设置环境变量OMP_NESTED以启用/禁用嵌套
- omp_get_nested(), omp_set_nested() 运行时函数
- 编译器仍然可以选择序列化嵌套的并行区域(即只使用一个线程的team )
- 大量开销。为什么?
- 会导致额外的负载不平衡。为什么?
OpenMP循环折叠
当您拥有完全嵌套的循环时,可以使用OpenMP 命令 collapse(n)来折叠内部循环。折叠循环:
- 循环需要完全嵌套perfectly nested
- 循环需要有矩形迭代空间
- 使迭代空间更大
- 比嵌套的并行循环需要更少的同步
例子:
!$OMP PARALLEL DO PRIVATE (i,j) COLLAPSE(2) DO i = 1,2 DO j=1,2 call foo(A,i,j) ENDDO ENDDO !$OMP END PARALLEL DO
提示:使用的线程数
OpenMP有两种模式来确定在并行区域中实际使用的线程数:
- 动态模式DYNAMIC MODE
- 每个并行区域使用的线程数可能不同
- 设置线程数只设置最大线程数(实际数量可能更少)
- 静态模式STATIC MODE
- 线程数是固定的,由程序员决定
- 通过改变环境变量 OMP_DYNAMIC 来设置模式
- 运行时函数 omp_get_dynamic/omp_set_dynamic
数学库
数学库具有许多函数的非常专业化和优化版本,其中许多函数已使用OpenMP并行化。在EOS上,我们有英特尔数学内核库(MKL)
有关mkl的更多信息:
http://sc.tamu.edu/help/eos/mathlib.php
因此,在实现自己的OpenMP数学函数之前,请检查MKL中是否已经有一个版本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号