
第 52 讲:论一只爬虫的自我修养

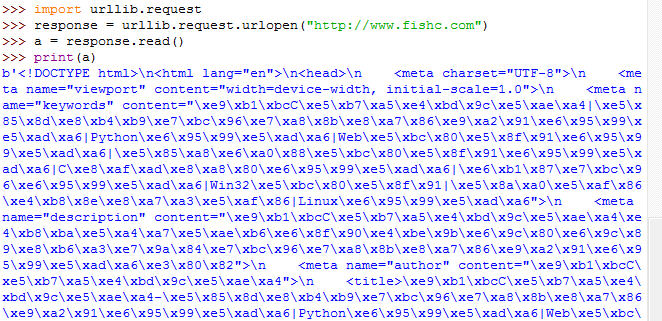
>>> import urllib.request
>>> response = urllib.request.urlopen("http://www.fishc.com")
>>> a = response.read()
>>> a = a.decode("utf-8")
>>> print(a)
课后作业:
0. 请问 URL 是“统一资源标识符”还是“统一资源定位符”?
统一资源标识符
1. 什么是爬虫?
网络爬虫是一种程序,主要用于搜索引擎,它将一个网站的所有内容与链接进行阅读,并建立相关的全文索引到数据库中,然后跳到另一个网站.样子好像一只大蜘蛛.
当人们在网络上(如google)搜索关键字时,其实就是比对数据库中的内容,找出与用户相符合的.网络爬虫程序的质量决定了搜索引擎的能力,如google的搜索引擎明显要比百度好,就是因为它的网络爬虫程序高效,编程结构好.
fAb-Hk5%2h4W`N}@3Gq~&Zipu
2. 设想一下,如果你是负责开发百度蜘蛛的攻城狮,你在设计爬虫时应该特别注意什么问题?
禁止别的爬虫访问网站中的敏感内容。
3. 设想一下,如果你是网站的开发者,你应该如何禁止百度爬虫访问你网站中的敏感内容?(课堂上没讲,可以自行百度答案)qgI"?Z .A
安全,加密https://www.cnblogs.com/junrong624/p/5533655.html
4. urllib.request.urlopen() 返回的是什么类型的数据?'JpH6<^
w
对象。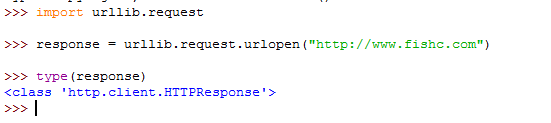
5. 如果访问的网址不存在,会产生哪类异常?(虽然课堂没讲过,但你可以动手试试)3 kta
-
6. 鱼C工作室(http://www.fishc.com)的主页采用什么编码传输的?@a}UL"
=
utf=8
7. 为了解决 ASCII 编码的不足,什么编码应运而生?G7j Y
动动手:
下载鱼C工作室首页(http://www.fishc.com),并打印前三百个字节
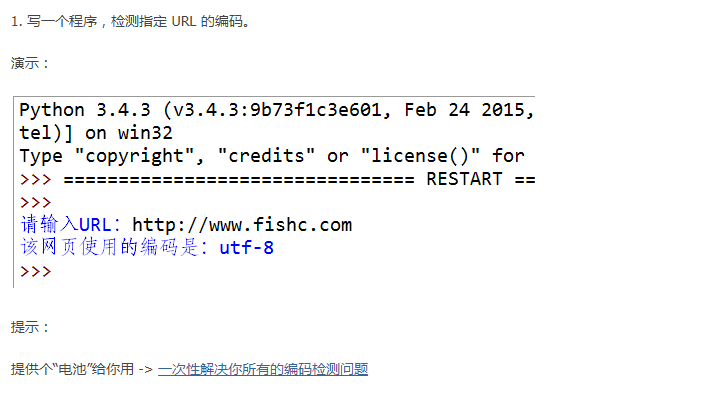
答案:
动动手1:
一次性解决你所有的编码检测问题
https://fishc.com.cn/thread-66086-1-1.html
import urllib.request
response = urllib.request.urlopen('http://www.fishc.com')
print(response.read())
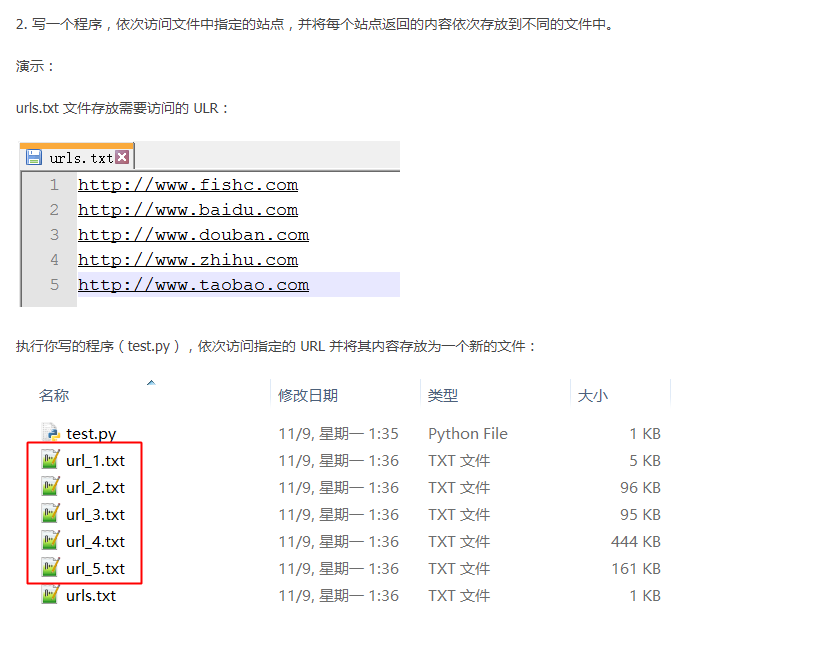
2.

import urllib.request
import chardet
def main():
i = 0
with open("urls.txt", "r") as f:
# 读取待访问的网址
# 由于urls.txt每一行一个URL
# 所以按换行符'\n'分割
urls = f.read().splitlines()
for each_url in urls:
response = urllib.request.urlopen(each_url)
html = response.read()
# 识别网页编码
encode = chardet.detect(html)['encoding']
if encode == 'GB2312':
encode = 'GBK'
i += 1
filename = "url_%d.txt" % i
with open(filename, "w", encoding=encode) as each_file:
each_file.write(html.decode(encode, "ignore"))
if __name__ == "__main__":
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号