Disruptor并发框架 (二)核心概念场景分析
核心术语
- RingBuffer(容器): 被看作Disruptor最主要的组件,然而从3.0开始RingBuffer仅仅负责存储和更新在Disruptor中流通的数据。对一些特殊的使用场景能够被用户(使用其他数据结构)完全替代。
- Sequence(槽位置): Disruptor使用Sequence来表示一个特殊组件处理的序号。和Disruptor一样,每个消费者(EventProcessor)都维持着一个Sequence。大部分的并发代码依赖这些Sequence值的运转,因此Sequence支持多种当前为AtomicLong类的特性。
- Sequencer: 这是Disruptor真正的核心。实现了这个接口的两种生产者(单生产者和多生产者)均实现了所有的并发算法,为了在生产者和消费者之间进行准确快速的数据传递。
- SequenceBarrier(生产消费者冲突问题解决): 由Sequencer生成,并且包含了已经发布的Sequence的引用,这些的Sequence源于Sequencer和一些独立的消费者的Sequence。它包含了决定是否有供消费者来消费的Event的逻辑。
- WaitStrategy:决定一个消费者将如何等待生产者将Event置入Disruptor。
- Event:从生产者到消费者过程中所处理的数据单元。Disruptor中没有代码表示Event,因为它完全是由用户定义的。
- EventProcessor(生产线程):主要事件循环,处理Disruptor中的Event,并且拥有消费者的Sequence。它有一个实现类是BatchEventProcessor,包含了event loop有效的实现,并且将回调到一个EventHandler接口的实现对象。
- EventHandler(消费者):由用户实现并且代表了Disruptor中的一个消费者的接口。
- Producer:由用户实现,它调用RingBuffer来插入事件(Event),在Disruptor中没有相应的实现代码,由用户实现。
- WorkProcessor:确保每个sequence只被一个processor消费,在同一个WorkPool中的处理多个WorkProcessor不会消费同样的sequence。
- WorkerPool:一个WorkProcessor池,其中WorkProcessor将消费Sequence,所以任务可以在实现WorkHandler接口的worker吃间移交
- LifecycleAware:当BatchEventProcessor启动和停止时,于实现这个接口用于接收通知。
初看Disruptor,给人的印象就是RingBuffer是其核心,生产者向RingBuffer中写入元素,消费者从RingBuffer中消费元素,如下图:
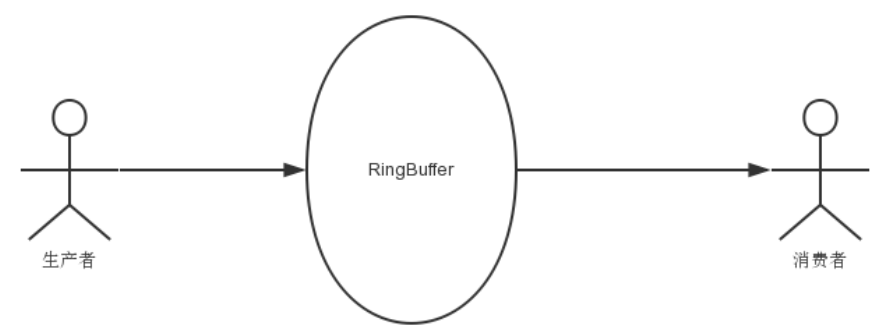
ringbuffer究竟是什么?
-
正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer
![]()
-
ringbuffer拥有一个序号,这个序号指向数组中下一个可用元素
![]()
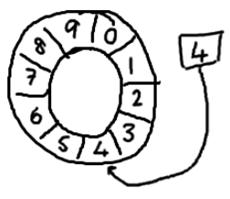
Disruptor说的是生产者和消费者的故事. 有一个数组.生产者往里面扔芝麻.消费者从里面捡芝麻. 但是扔芝麻和捡芝麻也要考虑速度的问题. 1 消费者捡的比扔的快 那么消费者要停下来.生产者扔了新的芝麻,然后消费者继续. 2 数组的长度是有限的,生产者到末尾的时候会再从数组的开始位置继续.这个时候可能会追上消费者,消费者还没从那个地方捡走芝麻,这个时候生产者要等待消费者捡走芝麻,然后继续.
进一步理解
1如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。
2我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠。
3因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。
4这是对CPU缓存友好的,也就是说在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。
5其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号