12.编码问题讨论
编码问题是个头疼的问题,相信不少人都被坑过。
1.编码的种类:
(1)ASCII:占用1个字节,只支持英文
(2)GB2312:英文占用1个字节,中文占用两个字节,支持6000多个汉字
(3)GBK:是GB2312的升级版本,支持20000多个汉字
(4)一些其它国家的语言支持编码
(5)由于很多国家的语言都不一样,如果每个国家都是用自己的编码方式就太混乱了,所以出现了万国码--unicode
(6)Unicode:占2-4个字节,目前包括13万多个字符
2.unicode的作用与缺陷
(1)作用:支持全球所有的语言,并且有与所有国家编码的映射关系
(2)缺陷:对于一些字符,比如英文,原来只需要1个字节就可以表示的,现在变成了2个字节,在网络传输与存储上比原来多了1倍,所以为了解决这个问题出现了utf系列,如下
3.utf编码系列,解决unicode的缺陷
(3)utf8:使用1-4个字节来表示所有字符,英文占用1个字节,欧洲那边一些国家语言占用2个字节,亚洲这边一些国家占用3个字节(中文),一些特殊的字符占用4个字节,utf8是现在项目中使用最为频繁的一种编码方式
(4)utf16:使用2个或者4个字节
(5)utf32:使用4个字节
4.编码之间的相互转换
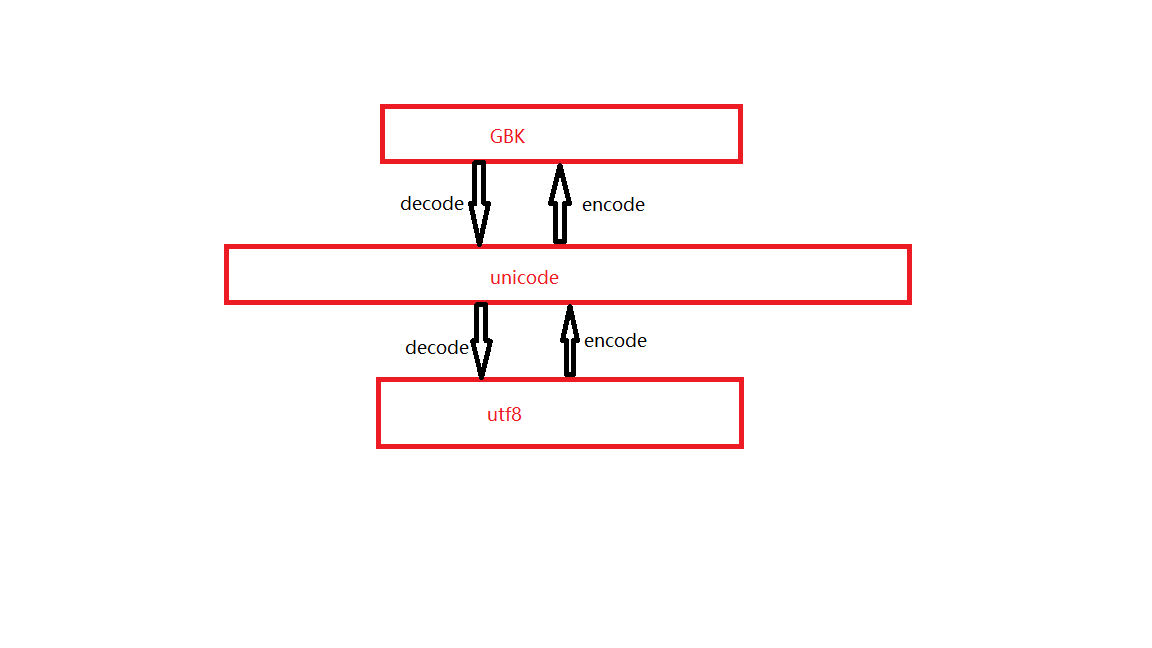
如图所示:unicode到GBK或者utf8的过程称为编码,而GBK和utf8到unicode的过程叫解码,GBK和utf8之间不能直接转换,只能以unicode为中介进行转换。
5.python中的编码问题
(1)先来说一说python2,它的默认编码是ASCII,如果要写中文,需要在代码的开头声明编码格式是GBK或者UTF8,在python2的解释器进行解释执行时,就会根据头声明的编码进行解释,如果没有声明则使用默认的ASCII
(2)python3中默认编码的格式是utf8,如果需要改成其它编码可以在代码的开头声明,在解释器进行解释执行时会转化成unicode,这里跟python2解释时有所区别,好好体会下面代码和执行结果
# -*- coding: utf-8 -*- #__author:jiangjing #date:2018/2/8 print('测试')
python2和python3分别执行这个测试代码的结果,如下所示:(windows的cmd窗口默认的编码格式是GBK的)
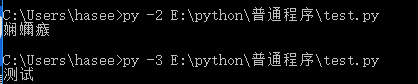
分析:代码声明的是utf8编码,造成这个结果的原因是:在python2中,解释器解释执行时就是按照声明的utf8编码执行的,但是因为windows下cmd窗口是GBK编码格式,utf8编码不能直接转化成GBK所以造成乱码,但是在python3中解释器解释执行时是会转化成unicode编码,然后unicode是可以解码成GBK的,所以不会乱码。
(3)python2中的str和bytes是同一个概念,如图,s就是一个字节串

(4)到了python3中,str与bytes是不同的概念,如下图
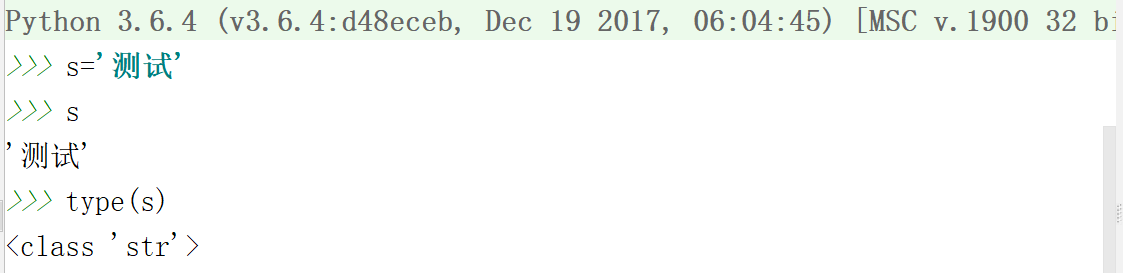
posted on 2018-02-08 22:20 后端bug开发工程师 阅读(239) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号