6.线程、进程、协程基础篇
1.进程是资源分配的最小单位,拥有自己独立的栈和堆,进程间资源不共享,进程是由操作系统调度,一个进程可以开启多个线程;
在python中multiprocess模块提供了Process类,实现进程相关功能。
简单实现:
# -*- coding: utf-8 -*- #__author:jiangjing #date:2018/2/3 from multiprocessing import Process def func(index): print('Process %d' % index) if __name__ == '__main__': for i in range(4): p = Process(target=func, args=(i,)) p.start()
2.线程是cpu调度的最小单位,拥有自己独立的栈和共享的堆,也是由操作系统调度;
python中的 GIL(Global Interpreter Lock),全局解释器锁,首先需要明确的是:GIL并不是python这门语言的特性,它是在CPython解释器引入的一个概念,而python又有很多解释器,CPython解释器是其中最流行的一个,看下图,当python解释器是 CPython时,执行流程为:
(1)线程1获得GIL,线程2没有获得GIL则不能继续执行;
(2)线程1往下走经过操作系统,操作系统经过调度,让cpu1执行;
(3)线程1释放GIL,线程2获得,则线程2按照上面步骤走,循环往复。
结论:当python解释器是CPython时,由于GIL的存在,所以只会有一个线程在执行,不能利用多核cpu,CPython的GIL是历史遗留的一个问题。
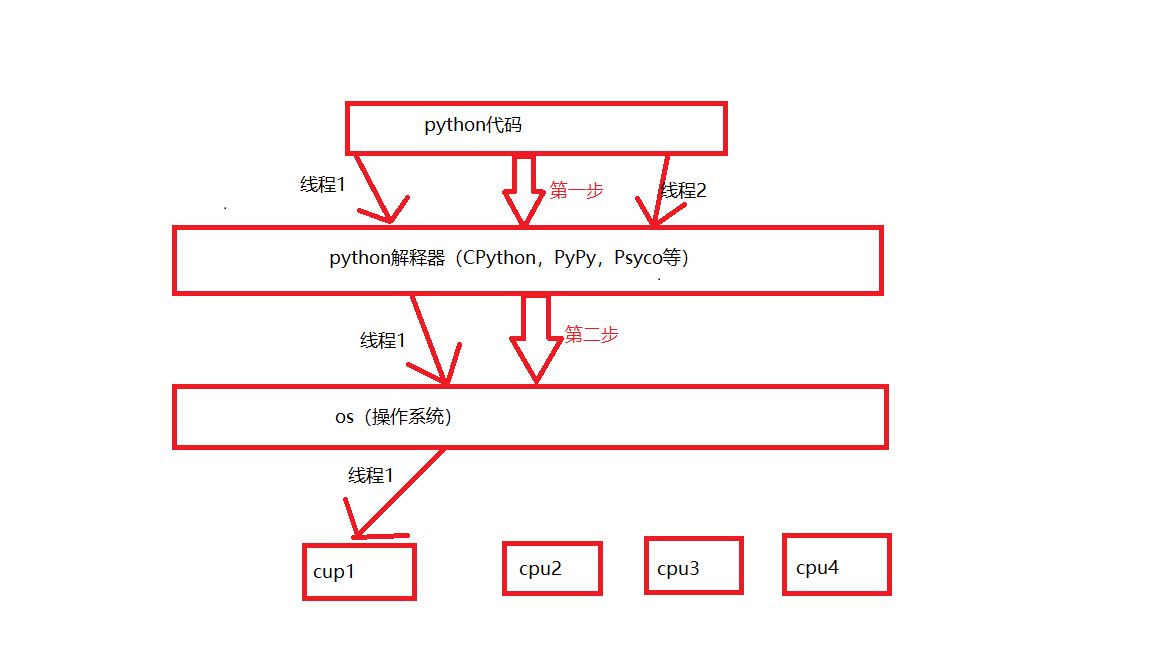
python代码执行流程图
python中的threading模块实现了Thread类
简单实现:
方式一:
# -*- coding: utf-8 -*- #__author:jiangjing #date:2018/2/3 import threading import time def func(index): time.sleep(1) print('Thread %d' % index) for i in range(10): t = threading.Thread(target=func, args=(i,)) t.start()
方式二:
# -*- coding: utf-8 -*- #__author:jiangjing #date:2018/2/3 import threading class MyThreading(threading.Thread): def __init__(self,func,arg): super(MyThreading,self).__init__() self.func = func self.arg = arg def run(self): self.func(self.arg) def func(index): print('Threading %d' % index) for i in range(10): obj = MyThreading(func, i) obj.start()
3.协程拥有独立的栈和共享的堆,由程序员在代码中自己调度,通过2的讲解,知道了在CPython解释器中每一时刻只会有一个线程在跑,利用不了多核cpu,但是还存在多线程切换的消耗,所以就出了协程,协程是在一个线程上跑,把一个线程分解成多个“微线程”,实现类似多线程的效果,并且节省了多线程时线程切换的时间。
第三方模块greenlet和gevent实现协程
greenlet实现:
# -*- coding: utf-8 -*-
#__author:jiangjing
#date:2018/2/3
def test1(): print(12) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() 输出为: 12 56 34 78
gevent实现:
# -*- coding: utf-8 -*- #__author:jiangjing #date:2018/2/3 from gevent import monkey monkey.patch_all() #windows下提升io阻塞敏感度,碰到io阻塞快速切换 import gevent import requests import time def func(url): print('url: %s' % url) resp = requests.get(url) data = resp.text print('%d bytes received from %s.' % (len(data), url)) start_time = time.time() gevent.joinall([ gevent.spawn(func, 'http://www.cnblogs.com/jiangjing/'), gevent.spawn(func, 'https://www.cnblogs.com/'), gevent.spawn(func, 'https://www.cnblogs.com/f-ck-need-u/p/8409723.html'), gevent.spawn(func, 'http://www.cnblogs.com/f-ck-need-u/p/7048359.html'), gevent.spawn(func, 'https://www.python.org/'), ]) end_time = time.time() print('consume time is %d' % (end_time - start_time)) 输出为: url: http://www.cnblogs.com/jiangjing/ url: https://www.cnblogs.com/ url: https://www.cnblogs.com/f-ck-need-u/p/8409723.html url: http://www.cnblogs.com/f-ck-need-u/p/7048359.html url: https://www.python.org/ 11658 bytes received from http://www.cnblogs.com/jiangjing/. 40828 bytes received from https://www.cnblogs.com/. 30753 bytes received from https://www.cnblogs.com/f-ck-need-u/p/8409723.html. 33181 bytes received from http://www.cnblogs.com/f-ck-need-u/p/7048359.html. 48890 bytes received from https://www.python.org/. consume time is 1
不使用协程,使用单线程串行执行对比:
# -*- coding: utf-8 -*- #__author:jiangjing #date:2018/2/3 from gevent import monkey monkey.patch_all() #windows下提升io阻塞敏感度,碰到io阻塞快速切换 import gevent import requests import time def func(url): print('url: %s' % url) resp = requests.get(url) data = resp.text print('%d bytes received from %s.' % (len(data), url)) start_time = time.time() urls = ['http://www.cnblogs.com/jiangjing/', 'https://www.cnblogs.com/', 'https://www.cnblogs.com/f-ck-need-u/p/8409723.html', 'http://www.cnblogs.com/f-ck-need-u/p/7048359.html', 'https://www.python.org/'] for url in urls: func(url) end_time = time.time() print('consume time is %d' % (end_time - start_time)) 输出为: url: http://www.cnblogs.com/jiangjing/ 11658 bytes received from http://www.cnblogs.com/jiangjing/. url: https://www.cnblogs.com/ 40822 bytes received from https://www.cnblogs.com/. url: https://www.cnblogs.com/f-ck-need-u/p/8409723.html 30753 bytes received from https://www.cnblogs.com/f-ck-need-u/p/8409723.html. url: http://www.cnblogs.com/f-ck-need-u/p/7048359.html 33181 bytes received from http://www.cnblogs.com/f-ck-need-u/p/7048359.html. url: https://www.python.org/ 48890 bytes received from https://www.python.org/. consume time is 2
结论:使用协程执行速度更快
posted on 2018-02-03 16:23 后端bug开发工程师 阅读(205) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号